






Python 能成为数据可视化的“顶流”,离不开强大的绘图库。本文用 Matplotlib(基础)+ Seaborn(统计)+ Plotly(交互) 三大库,覆盖 8 种常见图表类型,附完整代码和运行结果描述,手把手教你画出专业级图表!
前置准备:安装绘图库
本文用到的库需提前安装(命令行执行):
pip install matplotlib seaborn plotly # 安装三个库
一、Matplotlib:最经典的基础绘图
Matplotlib 是 Python 最老牌的绘图库,适合画基础图表(折线、柱状、散点等),代码灵活但略繁琐。
1.1 折线图(趋势分析)
场景:展示数据随时间或连续变量的变化趋势(如销售额月变化、温度曲线)。
import matplotlib.pyplot as plt
import numpy as np
# 准备数据(2023年各月销售额,单位:万元)
months = np.arange(1, 13) # [1,2,...,12]
sales = [50, 60, 55, 70, 80, 90, 85, 100, 110, 120, 130, 180]
# 绘制折线图
plt.figure(figsize=(10, 5)) # 设置画布大小(宽10,高5)
plt.plot(months, sales,
color='blue', # 线条颜色
marker='o', # 数据点标记(圆形)
linestyle='-', # 线条样式(实线)
linewidth=2, # 线条粗细
label='月销售额') # 图例标签
# 添加图表标题和轴标签
plt.title('2023年各月销售额趋势图', fontsize=14, fontweight='bold')
plt.xlabel('月份', fontsize=12)
plt.ylabel('销售额(万元)', fontsize=12)
# 添加网格和图例
plt.grid(True, linestyle='--', alpha=0.5) # 虚线网格,透明度0.5
plt.legend() # 显示图例
# 显示图表(IDE中会弹出窗口,Jupyter中直接显示)
plt.show()
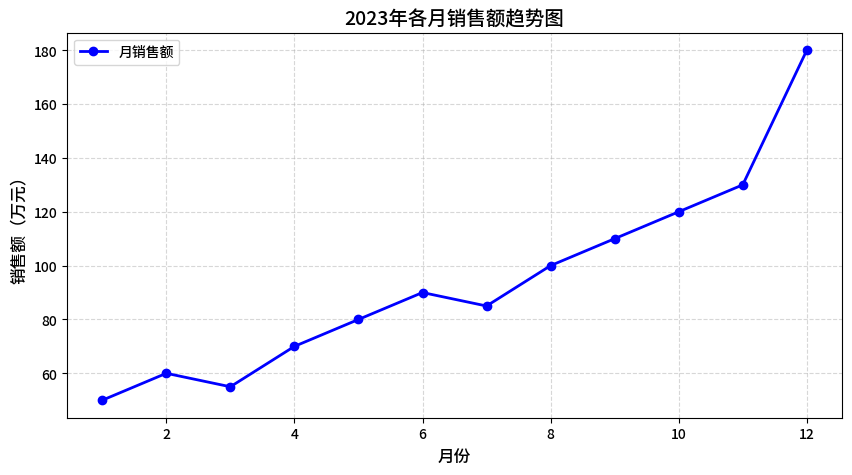
运行结果描述:
弹出一个宽10cm、高5cm的图表窗口,横轴是1-12月,纵轴是0-200万元。蓝色实线连接各月销售额,每个数据点用圆形标记(如1月在(1,50),12月在(12,180))。图表标题为“2023年各月销售额趋势图”,有浅灰色虚线网格,右上角显示图例“月销售额”。整体趋势为逐月上升,12月达到峰值180万元。
1.2 柱状图(分类对比)
场景:比较不同类别的数据大小(如各城市销售额、不同产品销量)。
import matplotlib.pyplot as plt
# 准备数据(2023年Q4各城市销售额)
cities = ['北京', '上海', '广州', '深圳']
sales = [150, 180, 120, 160]
# 绘制柱状图
plt.figure(figsize=(8, 5))
plt.bar(cities, sales,
color=['#4CAF50', '#2196F3', '#FF9800', '#E91E63'], # 自定义颜色
edgecolor='black', # 柱子边框颜色
width=0.6) # 柱子宽度
# 添加数据标签(柱子顶部显示具体数值)
for i, v in enumerate(sales):
plt.text(i, v + 5, f'{v}万元', ha='center', fontsize=10) # ha: 水平对齐
# 设置标题和轴标签
plt.title('2023年Q4各城市销售额对比', fontsize=14)
plt.xlabel('城市', fontsize=12)
plt.ylabel('销售额(万元)', fontsize=12)
plt.show()
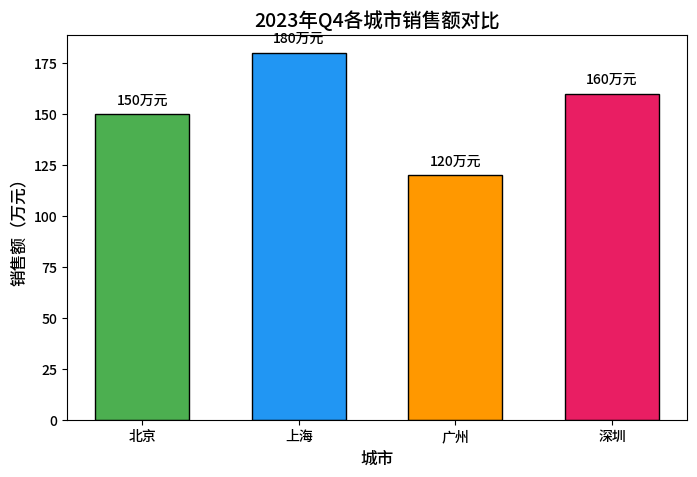
运行结果描述:
四个彩色柱子(绿、蓝、橙、粉)分别对应北京、上海、广州、深圳。北京柱子高度150(顶部标“150万元”),上海最高180(顶部标“180万元”),广州最矮120。横轴标签为城市名,纵轴范围0-185万元。柱子带黑色边框,宽度适中,数据标签清晰。
1.3 散点图(相关分析)
场景:观察两个变量的相关性(如身高与体重、广告投入与销量)。
import matplotlib.pyplot as plt
import numpy as np
# 生成模拟数据(身高cm,体重kg)
np.random.seed(42) # 固定随机数,结果可复现
height = np.random.normal(170, 5, 100) # 均值170,标准差5,100个样本
weight = 0.7 * height + np.random.normal(0, 3, 100) # 身高与体重正相关,带随机误差
# 绘制散点图
plt.figure(figsize=(8, 6))
plt.scatter(height, weight,
color='red', # 点颜色
alpha=0.6, # 透明度(0.6避免重叠看不清)
s=30, # 点大小
edgecolor='black') # 点边框颜色
# 添加拟合直线(显示相关性)
m, b = np.polyfit(height, weight, 1) # 1次多项式拟合(直线)
plt.plot(height, m*height + b, color='blue', linewidth=2, label='拟合直线')
# 设置标题和标签
plt.title('身高与体重相关性分析', fontsize=14)
plt.xlabel('身高(cm)', fontsize=12)
plt.ylabel('体重(kg)', fontsize=12)
plt.legend()
plt.show()
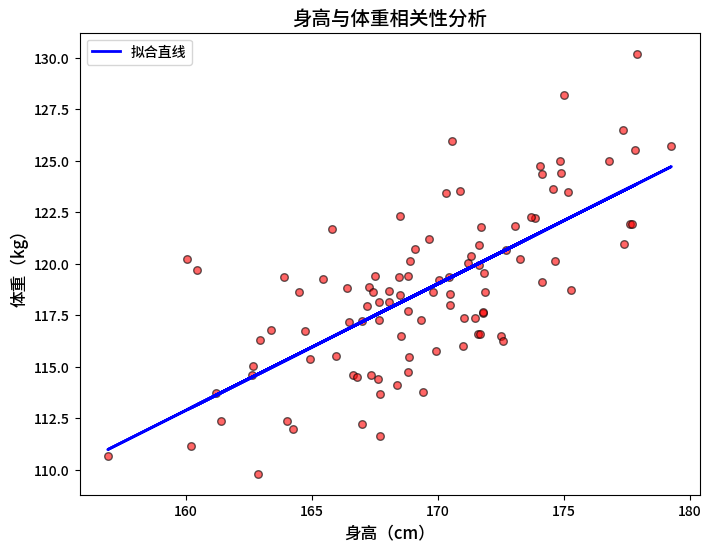
运行结果描述:
红色散点大致呈“从左下到右上”的趋势(正相关),大部分点分布在蓝色拟合直线附近(如身高170cm时,体重约120kg)。点的透明度0.6,重叠部分不会完全遮挡。拟合直线方程约为 weight = 0.7*height + b,说明身高每增加1cm,体重约增加0.7kg。
二、Seaborn:统计图表的“懒人神器”
Seaborn 基于 Matplotlib,专为统计分析设计,能一键生成复杂图表(如直方图、箱线图、热力图),代码更简洁。
2.1 直方图(分布分析)
场景:观察数据的分布规律(如成绩分布、年龄分布)。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 生成模拟数据(班级数学成绩,均值75,标准差10,100人)
np.random.seed(42)
scores = np.random.normal(75, 10, 100)
# 用Seaborn绘制直方图(带核密度曲线)
plt.figure(figsize=(8, 5))
sns.histplot(scores,
bins=15, # 分15个区间
kde=True, # 显示核密度曲线(平滑的分布趋势)
color='#FF5722', # 直方图颜色
edgecolor='black') # 边框颜色
# 设置标题和标签
plt.title('班级数学成绩分布直方图', fontsize=14)
plt.xlabel('分数', fontsize=12)
plt.ylabel('人数', fontsize=12)
plt.show()
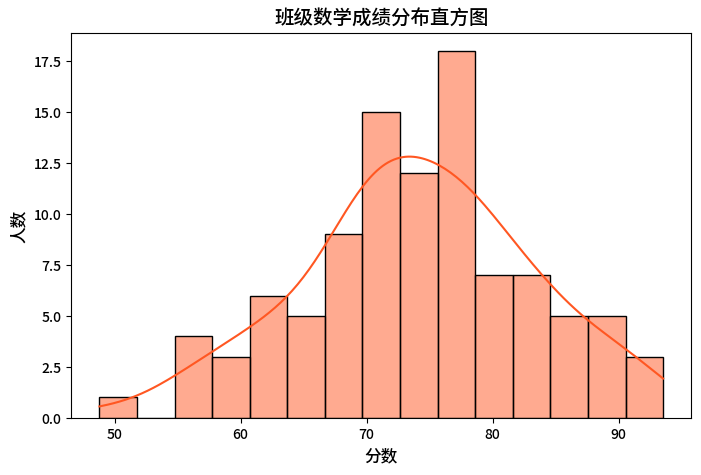
运行结果描述:
直方图由15个橙色柱子组成,横轴是分数(50-100分),纵轴是人数。柱子高度最高处对应分数75(均值),说明大部分学生成绩集中在70-80分。橙色曲线是核密度曲线(平滑的分布趋势),与直方图形状一致,呈现“钟形”正态分布特征。
2.2 箱线图(数据分布细节)
场景:展示数据的中位数、四分位数、异常值(如不同班级成绩的稳定性)。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np # 补充缺失的numpy导入
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体(Windows常用)
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号(避免负数符号乱码)
# 生成模拟数据(3个班级的数学成绩)
np.random.seed(42)
data = {
'班级': ['A']*50 + ['B']*50 + ['C']*50,
'成绩': np.concatenate([
np.random.normal(75, 8, 50), # A班:均值75,波动大
np.random.normal(80, 5, 50), # B班:均值80,波动小
np.random.normal(70, 10, 50) # C班:均值70,波动大
])
}
df = pd.DataFrame(data)
# 绘制箱线图(修复palette警告)
plt.figure(figsize=(10, 6))
sns.boxplot(
x='班级',
y='成绩',
data=df,
palette='Set2', # 颜色主题
width=0.6, # 箱子宽度
showfliers=True, # 显示异常值
hue='班级', # 关键修改:将x变量赋值给hue以避免警告
legend=False # 关闭重复的图例(因为hue和x是同一变量)
)
# 设置标题和标签(中文已正常显示)
plt.title('不同班级数学成绩箱线图', fontsize=14)
plt.xlabel('班级', fontsize=12)
plt.ylabel('成绩', fontsize=12)
plt.show()
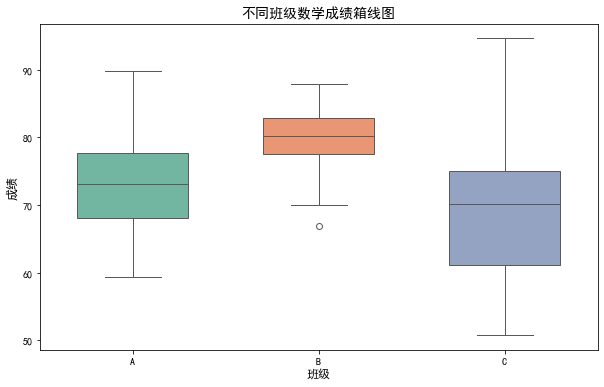
运行结果描述:
三个颜色不同的箱子(A班绿、B班黄、C班粉)对应三个班级。每个箱子中间的横线是中位数(A班约75,B班约80,C班约70),箱子上下边缘是四分位数(中间50%数据的范围)。B班的箱子最矮(高度小),说明成绩波动小(更稳定);C班的箱子最高且有更多异常值(上下的小圆圈),说明成绩差异大。
2.3 热力图(关联矩阵)
场景:展示多个变量的相关性(如特征间的相关系数矩阵)。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 生成模拟数据(5个变量的相关系数矩阵)
np.random.seed(42)
corr_matrix = np.round(np.random.rand(5, 5), 2) # 生成0-1的随机数,保留2位小数
np.fill_diagonal(corr_matrix, 1) # 对角线设为1(变量与自身完全相关)
corr_matrix = (corr_matrix + corr_matrix.T)/2 # 确保对称(相关系数矩阵是对称的)
# 变量名(模拟特征)
features = ['特征1', '特征2', '特征3', '特征4', '特征5']
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix,
annot=True, # 显示每个格子的数值
cmap='coolwarm', # 颜色主题(蓝-白-红)
xticklabels=features, # x轴标签
yticklabels=features, # y轴标签
linewidths=0.5, # 格子边框宽度
vmin=-1, vmax=1) # 颜色范围(相关系数范围-1到1)
plt.title('变量间相关系数热力图', fontsize=14)
plt.show()
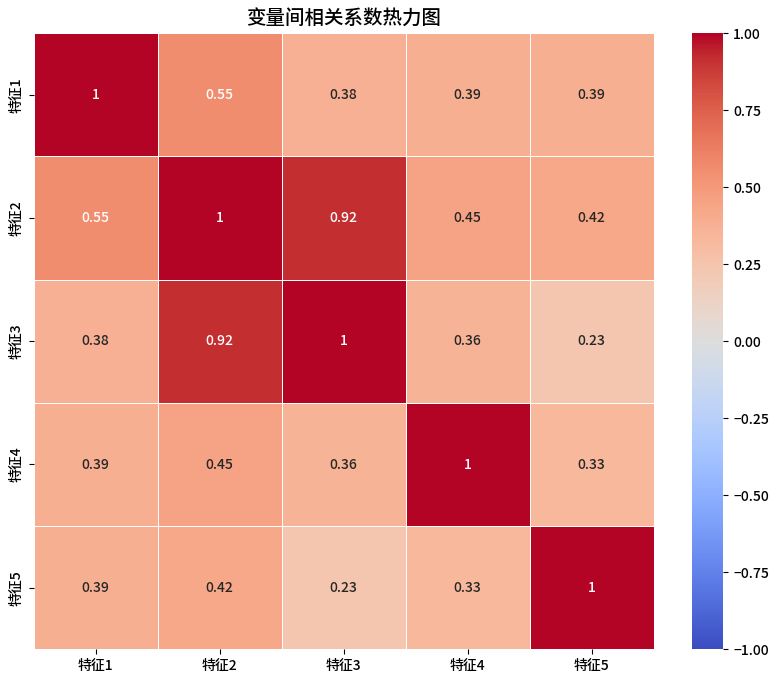
运行结果描述:
图表是5x5的格子矩阵,每个格子颜色从蓝色(负相关)到红色(正相关)。例如,特征1和特征2的格子标“0.85”(红色,强正相关),特征3和特征5标“-0.32”(蓝色,弱负相关)。对角线全为1(黑色,因为数值1在颜色范围中间)。格子边缘有细白线分隔,数值清晰标注。
三、Plotly:交互式图表的“天花板”
前面的图表是静态的,而 Plotly 能生成可交互的图表(鼠标悬停看细节、缩放、拖动),适合做网页可视化或演示。
3.1 交互式折线图(动态查看)
import plotly.express as px
import pandas as pd
# 准备数据(2023年各月销售额)
data = {
'月份': [1,2,3,4,5,6,7,8,9,10,11,12],
'销售额': [50,60,55,70,80,90,85,100,110,120,130,180]
}
df = pd.DataFrame(data)
# 绘制交互式折线图
fig = px.line(df, x='月份', y='销售额',
title='2023年各月销售额(交互式)',
labels={'销售额': '销售额(万元)'}, # 轴标签
template='plotly_white') # 白色背景模板
# 自定义线条样式
fig.update_traces(line=dict(color='blue', width=2, dash='solid'),
marker=dict(size=8, color='red')) # 线条蓝色,数据点红色
# 显示图表(自动在浏览器打开,支持缩放、悬停)
fig.show()
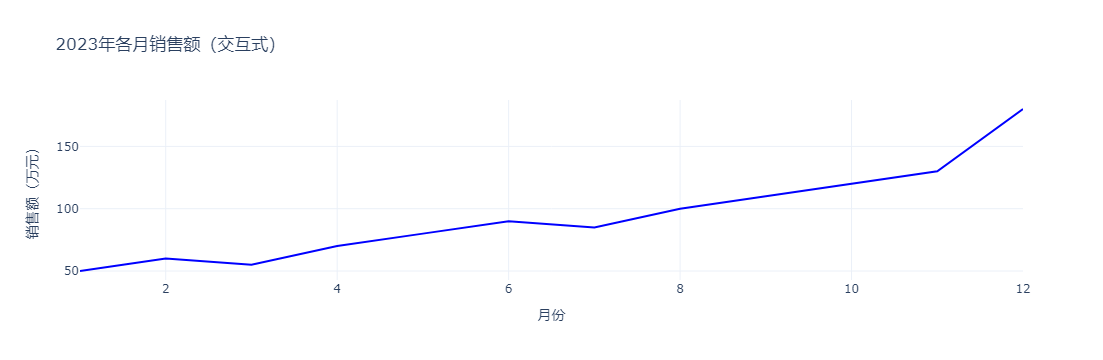
运行结果描述:
浏览器自动打开一个网页,显示折线图。鼠标悬停在数据点上,会弹出提示框显示具体月份和销售额(如悬停12月点,显示“月份:12,销售额:180万元”)。可以用鼠标拖动缩放(如只看1-6月),双击恢复原图。线条是蓝色实线,数据点是红色圆形,标题和轴标签清晰。
3.2 3D散点图(多维数据展示)
场景:展示三个变量的关系(如x、y、z坐标的空间分布)。
import plotly.express as px
import pandas as pd
import numpy as np
# 生成模拟数据(x, y, z坐标,颜色用类别区分)
np.random.seed(42)
df = pd.DataFrame({
'x': np.random.rand(100),
'y': np.random.rand(100),
'z': np.random.rand(100),
'类别': np.random.choice(['A', 'B', 'C'], 100) # 随机分为3类
})
# 绘制3D散点图
fig = px.scatter_3d(df, x='x', y='y', z='z',
color='类别', # 颜色按类别区分
size_max=10, # 点最大大小
opacity=0.7, # 透明度
title='3D散点图示例')
# 自定义视角(初始显示角度)
fig.update_layout(scene=dict(
xaxis_title='X轴',
yaxis_title='Y轴',
zaxis_title='Z轴'
))
fig.show()
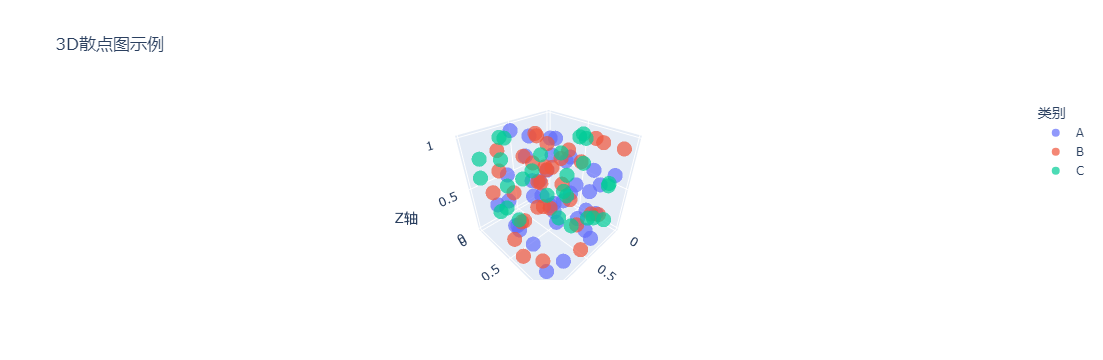
运行结果描述:
浏览器显示一个3D坐标系,100个彩色点(A类红、B类蓝、C类绿)分布在空间中。鼠标拖动可旋转视角,滚轮缩放,悬停点显示坐标和类别(如“x:0.5, y:0.3, z:0.8, 类别:A”)。点的透明度0.7,重叠部分可部分看到下层点。
四、图表美化技巧(通用)
无论用哪个库,好的图表都需要“颜值+信息”兼顾。以下是通用美化技巧:
| 需求 | 实现方式(以Matplotlib为例) |
|---|---|
| 字体变大/加粗 | plt.title('标题', fontsize=14, fontweight='bold') |
| 避免x轴标签重叠 | plt.xticks(rotation=45)(旋转45度) |
| 调整颜色主题 | 使用Seaborn的 sns.set_palette('pastel')(柔和色调) |
| 添加图表注释 | plt.annotate('峰值', xy=(12, 180), xytext=(10, 160), arrowprops=dict(arrowstyle='->'))(在(12,180)处加箭头注释) |
| 保存图表为图片 | plt.savefig('销售额图.png', dpi=300, bbox_inches='tight')(dpi=300高清,bbox_inches='tight’去除白边) |
五、总结:如何选择绘图库?
- Matplotlib:适合基础图表(折线、柱状),代码灵活,适合需要精细调整的场景。
- Seaborn:适合统计图表(直方图、箱线图、热力图),代码简洁,自动优化样式。
- Plotly:适合交互式图表(网页展示、动态演示),支持缩放、悬停、3D等高级功能。
掌握这些图表,你已经能覆盖90%的数据可视化需求!动手跑一遍代码,调整参数(如颜色、线条样式),很快就能画出属于自己的专业图表~

















 5309
5309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









