







1️⃣ 简介
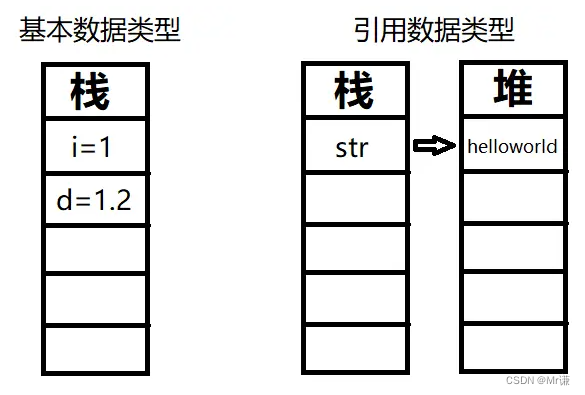
数据类型分为两类:基本类型(Primitive Type) 和引用类型(Reference Type)。
| 名称 | 含义 | 数据分配 |
|---|---|---|
| 基本类型 | 基本类型包括boolean类型和数值类型。数值类型有整数类型和浮点类型。整数类型包括 byte、short、int、long、char,浮点类型包括float和double。 | 原始数据类型变量的“变量分配”与“数据分配”是在一起的(都在方法区或栈内存或堆内存) |
| 引用类型 | 引用类型包括类、接口和数组类型,还有一种特殊的null类型。引用数据类型就是对一个对象的引用,对象包括实例和数组两种。实际上,引用类型变量相当于一个指针,但引用类型只能赋值运算。 | 引用数据类型变量的“变量分配”与“数据分配”不一定是在一起的,只要是引用数据类型变量,其具体内容都是存放在堆中的,而栈中存放的是其具体内容所在内存的地址 |
public class Main{
public static void main(String[] args){
//基本数据类型
int i=1;
double d=1.2;
//引用数据类型
String str="helloworld";
}
}
2️⃣ 基本数据类型
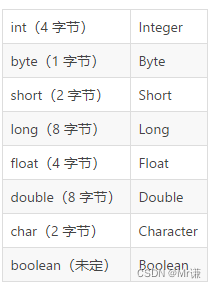
一个字节等于 8 位。一位(one bite)在计算机里只有 0 或 1 两个值。所以位数就决定了基本数据类型的表数范围。 值得注意的是字符串不是基本数据类型,字符串是一个类,也就是引用数据类型。
| 名称 | 类型 | 所占字节 | 取值范围 | 默认值 |
|---|---|---|---|---|
| 布尔型 | boolean | 没有给出精确的定义(1或4) | true或false | false |
| 字节型 | byte | 1 | -128——127 | 0 |
| 整型 | int | 4 | -231——231-1 | 0 |
| 短整型 | short | 2 | -215——215-1 | 0 |
| 长整型 | long | 8 | -263——263-1 | 0 |
| 字符型 | char | 2 | – | \u0000 |
| 单精度浮点型 | float | 4 | -2128——2128 | 0.0F |
| 双精度浮点型 | double | 8 | -21024——21024 | 0.0D |
3️⃣ 基本类型的类型转换
🔹 1、自动类型转换
- byte–>short–>int–>long–>float–>double ,小精度可转大精度,不会失去精度。
🔹 2、强制类型转化
- byte<–shor<t–int<–long<–float<–double ,大转小会失去精度
🔹 3、表达式类型的自动提升
- 也就是小精度和大精度相互运算时,结果会默认转为大精度的,如:整形可以和浮点型一起运算,结果会转换为浮点型。
//定义一个short类型变量
short sValue = 5;
//表达式中的sValue将自动提升到int类型,则右边的表达式结果类型为int
//将一个int类型赋给short类型的变量将发生错误。
sValue = sValue - 2;
4️⃣ 基本类型的拆箱和装箱
🔹 1、装箱过程
- 装箱就是自动将基本数据类型转换为包装类型,装箱过程是通过调用包装器的valueOf方法实现的;
| 名称 | 装箱过程 |
|---|---|
| Integer、Short、Byte、Character、Long | 即通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,会返回常量池(如IntegerCache.cache)中事先已经创建好的对象;否则创建一个新的Integer对象。注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的 |
| Double、Float | 而Double类的valueOf方法采用了与Integer类的valueOf方法不同的实现。因为在某个范围内的整型数值的个数是有限的,而浮点数却不是。。Double、Float的valueOf方法的实现是类似的。 |
| Boolean | Boolean类的valueOf直接返回事先创建好的对象。Boolean 中定义了 2 个静态成员属性 public static final Boolean TRUE = new Boolean(true); public static final Boolean FALSE = new Boolean(false); |
🔹 2、拆箱过程
- 拆箱就是自动将包装类型转换为基本数据类型,拆箱过程是通过调用包装器的xxxValue方法实现的。
🔹 3、谈谈Integer i = new Integer(xxx)和Integer i =xxx;
- 第一种方式不会触发自动装箱的过程;而第二种方式会触发;另外,如果数值在[-128,127]之间,第二种方式是不会创建新对象的。
🔹 4、特别注意
- 需要注意的是:当 "=="运算符的两个操作数都是包装器类型的引用,则是比较指向的是否是同一个对象。
- 而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。
- 对于包装器类型,equals方法并不会进行类型转换(即数值相同的Long型和Integer型,通过equals比较,必定返回false)。
5️⃣ 值传递和引用传递
- 值传递: 传递对象的一个副本,即使副本被改变,也不会影响源对象,因为值传递的时候,实际上是将实参的值复制一份给形参。
- 引用传递:传递的并不是实际的对象,而是对象的引用,外部对引用对象的改变也会反映到源对象上,因为引用传递的时候,实际上是将实参的地址值复制一份给形参。
- 说明:对象传递(数组、类、接口)是引用传递,原始类型数据(整形、浮点型、字符型、布尔型)传递是值传递。
🔹 1、值传递和引用传递的区别
/**
* 基本数据类型是值传递
**/
public void add1(int x, double y) {
x = 10000;
y = 10000.0;
}
/**
* 基本数据包装类型和String类型是引用传递,
* 但是由于他们的value都是final修饰的,
* 数据一旦写入就无法更改,
* 所以给人的感觉就像值传递
**/
public void add2(Integer x, Double y, String s) {
x = 10000;
y = 10000.0;
s = s + "add";
}
/**
* 自定义数据类型属于引用传递,
* 引用指向的值被修改
**/
public void add3(Point newPoint) {
newPoint.setMember_int(10000);
}
/**
* 自定义数据类型属于引用传递,
* 但是这里引用指向的地址变了,
* 所以值不变
**/
public void add4(Point newPoint) {
newPoint = new Point();
newPoint.setMember_int(10000);
}
}
package com.study.notes.threads.safe.variable;
/**
* 值传递:
* 传递对象的一个副本,
* 即使副本被改变,
* 也不会影响源对象,
* 因为值传递的时候,
* 实际上是将实参的值复制一份给形参。
*
* 引用传递:
* 传递的并不是实际的对象,
* 而是对象的引用,
* 外部对引用对象的改变也会反映到源对象上,
* 因为引用传递的时候,
* 实际上是将实参的地址值复制一份给形参。
* 说明:对象传递(数组、类、接口)是引用传递,原始类型数据(整形、浮点型、字符型、布尔型)传递是值传递。
*
* @author: lzq
* @create: 2023-07-20 09:42
*/
public class MainDemo {
public static void main(String[] args) {
MyRun myRun = new MyRun();
Point point1 = new Point();
Point point2 = new Point();
int intX = 1;
double doubleY = 1.0;
Integer integerX = 1;
Double doubleEY = 1.0;
String str = "1";
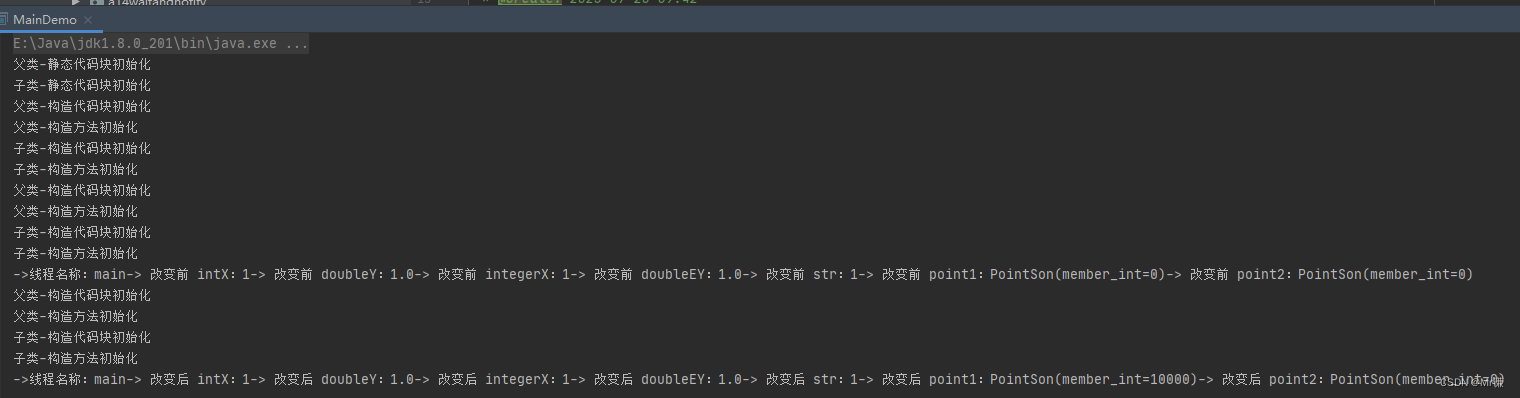
System.out.println("->线程名称:" + Thread.currentThread().getName() +
"-> 改变前 intX:" + intX +
"-> 改变前 doubleY:" + doubleY +
"-> 改变前 integerX:" + integerX +
"-> 改变前 doubleEY:" + doubleEY +
"-> 改变前 str:" + str +
"-> 改变前 point1:" + point1 +
"-> 改变前 point2:" + point2);
myRun.add1(intX,doubleY);
myRun.add2(integerX,doubleEY,str);
myRun.add3(point1);
myRun.add4(point2);
System.out.println("->线程名称:" + Thread.currentThread().getName() +
"-> 改变后 intX:" + intX +
"-> 改变后 doubleY:" + doubleY +
"-> 改变后 integerX:" + integerX +
"-> 改变后 doubleEY:" + doubleEY +
"-> 改变后 str:" + str +
"-> 改变后 point1:" + point1 +
"-> 改变后 point2:" + point2);
}
}
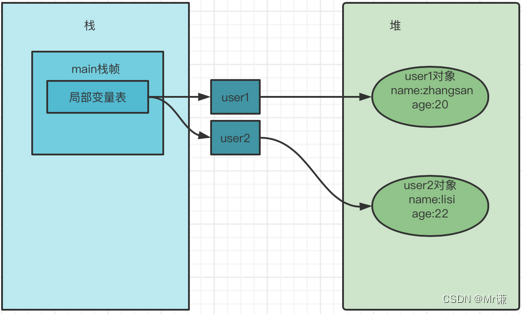
🔹 2、方法里面的引用是方法私有的,引用之间的赋值,只是地址传递
方法里面的引用是方法私有的,引用之间的赋值,只是地址传递,只改变地址,可以不会对堆里面的对象有何影响
public static void main(String[] args) {
User user1 = new User("zhangsan",20);
User user2 = new User("lisi",22);
System.out.println("交换前user1:" + user1 + "-》 user2:" + user2);
swap(user1,user2);
System.out.println("交换后user1:" + user1 + "-》 user2:" + user2);
}
private static void swap(User user1, User user2) {
User tmp = v;
user1 = user2;
user2 = tmp;
}
-
结果:
-
交换前
user1:name:zhangsan age:20-》 user2:name:lisi age:22 -
交换后
user1:name:zhangsan age:20-》 user2:name:lisi age:22
-
-
结果分析:
-
执行
swap方法:
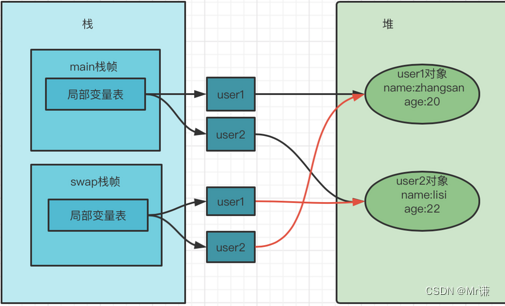
-
swap方法结束后,临时副本user1和user2被回收
6️⃣ 特殊的String
🔹 1、String
- String作为参数的传递方式是引用传递,但是String又有值传递的效果。这是因为String是常量,不能更改,所以如果在函数里更改的话,其实是生成了另外一个String,但是原来的String还在,函数外的String还是原来的String。函数里的String指向另外一个新生成的String,给人一种值传递的假象
String a = "aaa"; //==> a----->new String("aaa")
String b = a; //==> b----->a, 传引用
b = "bbb"; //==> b----->new String("bbb"), 传引用,b指向了一个新的字符串,a并没有变。
public static void changeStr(String str) {
str = "welcome";
}
public static void main(String[] args) {
String str = new String("1234"); //使用String str = "1234";是一样的效果
changeStr(str);
System.out.println(str);
}
// 最终会输出1234
-
String是不可改变类(记:基本类型的包装类都是不可改变的)的典型代表,也是Immutable设计模式的典型应用。
Immutable模式的实现主要有以下两个要点: 1. 除了构造函数之外,不应该有其它任何函数(至少是任何public函数)修改任何成员变量。 2. 任何使成员变量获得新值的函数都应该将新的值保存在新的对象中,而保持原来的对象不被修改。 -
String被修饰为final,所以是不可继承的。String变量一旦初始化后就不能更改,禁止改变对象的状态,从而增加共享对象的坚固性、减少对象访问的错误,同时还避免了在多线程共享时进行同步的需要。因此用“+”进行字符串拼接的时候,实际上新建了一个字符串对象。String的不可变性导致字符串变量使用+号的代价很大。
-
String类是跨应用程序域的,可以在不同的应用程序域中访问到同一String对象
🔹 2、String s = "abc" 和 String s = new String("abc")
📝 a、String s = “abc”
JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。
- 先在栈中创建一个对String类的对象引用变量s,
- 然后去查找"abc"是否被保存在字符串常量池中,如果没有,则在栈中创建三个char型的值’a’、‘b’、‘c’
- 然后在堆中创建一个String对象object,它的值是刚才在栈中创建的三个char型值组成的数组{‘a’、‘b’、‘c’},
- 接着这个String对象object被存放进字符串常量池,最后将s指向这个对象的地址,
- 如果"abc"已经被保存在字符串常量池中,则在字符串常量池中找到值为"abc"的对象object,
- 然后将s指向这个对象的地址。
📝 b、String s = new String(object)
一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象。
- 相当于String object = “abc”; String s = new String(object);
- 第一步参考第一种创建方式,而第二步由于"abc"已经被创建并保存到字符串常量池中,因此jvm只会在堆中新创建一个String对象,它的值共享栈中已有的三个char型值。
📝 c、两种方式区别
- 以“”方式给出的字符串对象,在字符串常量池中存储,而且相同内容只会在其中存储一份。
- 通过构造器new对象,每new一次都会产生一个新对象,放在堆内存中,不会放入常量池。
🔹 3、String中==与equals的区别
因为java所有类都继承于Object基类,而Object中equals用==来实现,所以equals和==是一样的,都是比较对象地址,java api里的类大部分都重写了equals方法,包括基本数据类型的封装类、String类等。对于String类==用于比较两个String对象的地址,equals则用于比较两个String对象的内容(值)。
String s0 =new String ("abc");
String s1 =new String ("abc");
System.out.println(s0==s1); //false 可以看出用new的方式是生成不同的对象
System.out.println(s0.equals(s1)); //true 可以看出equals比较的是两个String对象的内容(值)
🔹 4、字符串常量池的使用
字符串常量池(String Pool)保存所欲字符串字面量(literal strings),这些字面量在编译时期就确定,不仅如此,还可以使用String的intern()方法在运行时添加到常量池中。
常量池的使用主要有两种方法: 直接使用双引号声明出来的String对象会直接存储到常量池中。 使用String提供的intern()方法时,会查询字符串常量池中是否存在当前字符,如果不存在则将当前字符串放入常量池中。
String s0 = "abc";
String s1 = "abc";
System.out.println(s0==s1); //true 可以看出s0和s1是指向同一个对象的。
-
1.new String在堆上创建字符串对象。
-
2.通过字面量赋值创建字符串(如:String str=”1”)时,会先在常量池中查找是否存在相同的字符串,若存在,则将栈中的引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将栈中的引用指向该字符串。
-
3.常量字符串的+“”操作,编译阶段直接会合成为一个字符串。如String str=”JA”+”VA”,在编译阶段会直接合并成语句String str=”JAVA”,于是会去常量池中查找是否存在”JAVA”,从而进行创建或引用。
🔹 5、编译期确定
分析:因为例子中的 s0和s1中的"helloworld”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而"hello”和"world”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中"helloworld”的一个引用。所以我们得出s0==s1==s2;
String s0="helloworld";
String s1="helloworld";
String s2="hello" + "word";
System.out.println( s0==s1 ); //true 可以看出s0跟s1是同一个对象
System.out.println( s0==s2 ); //true 可以看出s0跟s2是同一个对象
分析:s1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量 池中或嵌入到它的字节码流中。所以此时的"a" + s1和"a" + "b"效果是一样的。
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println((s0 == s2)); //result = true
🔹 6、编译期无法确定
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。s0还是常量池中"helloworld”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象"helloworld”的引用,s2因为有后半部分new String(”world”)所以也无法在编译期确定,所以也是一个新创建对象"helloworld”的引用;
String s0="helloworld";
String s1=new String("helloworld");
String s2="hello" + new String("world");
System.out.println( s0==s1 ); //false
System.out.println( s0==s2 ); //false
System.out.println( s1==s2 ); //false
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
String s0 = "ab";
String s1 = "b";
String s2 = "a" + s1;
System.out.println((s0 == s2)); //result = false
🔹 7、String的不可变性导致字符串变量使用+号的代价
📘 字符串连接优化
📖 字面量连接
- 当我们使用
+对字面量字符串进行连接时,编译器会在编译期间进行优化。 - 🧪 举例说明:
- 当代码是这样写的:
String s = "a" + "b" + "c"; - 编译器在编译期间将其优化为:
String s = "abc"; - 这种优化是因为所有的字面量值在编译时都已知,编译器可以立即合并它们。
- 当代码是这样写的:
🛠️ 变量连接
-
当涉及到变量的字符串连接时,情况会变得复杂,因为变量的值可能在运行时改变。
-
编译器在这里会生成使用
StringBuilder的代码,以便在运行时进行字符串拼接。 -
🧪 例如,考虑以下代码:
String s1 = "a"; // 创建了1个字符串对象 "a"。 String s2 = "b"; // 创建了1个字符串对象 "b"。 String s3 = "c"; // 创建了1个字符串对象 "c"。 String s4 = s1 + s2 + s3; // 可能创建了0个或1个新的字符串对象。 -
对于上述代码,这里有几点需要注意:
-
字面量
"a","b","c"在编译期间会被加入到字符串常量池中,如果它们还未存在于池中的话。这里分别为s1,s2,s3创建了三个字符串对象。 -
对于
s4的赋值,如果没有其他优化,编译器会创建一个StringBuilder对象,然后调用append方法三次(一次对于s1,s2, 和s3),最后通过toString方法创建一个新的String对象。所以这一行会创建一个新的字符串对象。new StringBuilder(s1).append(s2).append(s3).toString();这个过程中,StringBuilder是一个新的对象,然后最终的toString()调用会创建一个新的字符串对象s4。- 对于
s4的赋值,编译器不会直接合并字符串,因为它们是变量。
StringBuilder sb = new StringBuilder(); sb.append(s1); sb.append(s2); sb.append(s3); String s4 = sb.toString(); -
但是,编译器可能对
String拼接做了进一步优化,特别是从 Java 6 更新 20 版本开始,引入了String拼接的新优化。如果s1,s2, 和s3从未改变过,那么编译器可能直接使用它们的值进行拼接,不会创建一个新的String对象。这取决于编译器的实现和具体的 JVM 版本。 -
这样做的原因是
s1、s2和s3的值可能会在运行时变化,编译器不能预知它们具体的值,因此无法在编译期间进行优化。
-
⚠️ 注意:
- 上面提到的使用
StringBuilder的优化发生在Java编译器层面,对于开发者来说,这个过程是透明的。 - 如果开发者明确知道会有多次的字符串拼接操作,尤其是在循环中,推荐直接使用
StringBuilder,以减少不必要的对象创建和提高性能。
🏃♂️ 性能测试
-
使用字符串直接相加:
- ⏱️ 第一段代码中:
String str = "Hello"; String str2 = "World"; long start = System.currentTimeMillis(); for (int i = 0; i < 99999; i++) { str = str + str2; } long end = System.currentTimeMillis(); System.out.println("使用string的时间是:" + (end - start) + "毫秒!"); // 结果为:使用string的时间是:14529毫秒! - 🔄 每次循环都会创建新的
String对象,导致效率低下。
- ⏱️ 第一段代码中:
-
使用变量和常量相加:
- ⚖️ 第二段代码可能会被编译器优化:
String str1 = "Hello"; String str2 = "World"; start = System.currentTimeMillis(); for (int i = 0; i < 99999; i++) { str = str1 + str2; } end = System.currentTimeMillis(); System.out.println("使用string的时间是:" + (end - start) + "毫秒!"); // 结果为:使用string的时间是:8毫秒! - ⚠️ 注意:提供的执行时间 “8毫秒” 可能会不准确,实际性能取决于JVM实现和运行时情况。
- ⚖️ 第二段代码可能会被编译器优化:
🛠️ 推荐的字符串连接方法
- 使用
StringBuilder来提高性能:- 📌 在循环中进行大量字符串连接时应使用
StringBuilder。 - 🛠️ 代码示例:
StringBuilder sb = new StringBuilder(); start = System.currentTimeMillis(); for (int i = 0; i < 99999; i++) { sb.append("World"); } str = sb.toString(); end = System.currentTimeMillis(); System.out.println("使用StringBuilder的时间是:" + (end - start) + "毫秒!"); - 🚀 这种方法避免了在每次迭代中创建新的
String对象,极大提升性能。
- 📌 在循环中进行大量字符串连接时应使用
🔹 8、String、StringBuffer、StringBuilder
因为相对StringBuffer,StringBuilder没有在方法上使用 synchronized 关键字。Synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
| 名称 | 是否可变 | 效率 | 线程安全 | 使用场景 |
|---|---|---|---|---|
| String | 不可变字符串 | 在字符串内容不经常发生变化的业务场景优先使用String类。例如:常量声明、少量的字符串拼接操作等。 | ||
| StringBuffer | 可变的字符序列 | 效率低 | 线程安全 | 在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在多线程环境下,建议使用StringBuffer,例如XML解析、HTTP参数解析与封装 |
| StringBuilder | 可变的字符序列 | 效率高 | 线程不安全 | 在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在单线程环境下,建议使用StringBuilder,例如SQL语句拼装、JSON封装等。 |
7️⃣ 常量池(String并不孤单)
🔹 1、Java 常量池
常量池是Java虚拟机(JVM)中的特殊存储区域,用于存储特定的常量数据,如:
- 基本数据类型:
byte、short、int、float、long、double、char、boolean - 部分包装类:
Byte,Short,Integer,Long,Character,Boolean(⚠️ 注意:浮点数类型的包装类如Float和Double并未使用常量池) - 对象型:例如
String和数组 - 符号引用:以文本形式出现的符号引用
特别的,整型包装类 Byte, Short, Integer, Long, Character 只在对应的值小于或等于 127 时使用对象池。即,大于 127 的这些类的对象不会被放在常量池中。
🔹 2、Java 字符串存储过程
在Java中,字符串常量池(String Constant Pool)是一个特殊的存储区域:
-
字符串字面量:如
String s = "xyz";时:- JVM检查字符串常量池中是否存在内容为 “xyz” 的对象。
- 存在,则
s指向该对象。 - 不存在,JVM在常量池创建 “xyz” 对象,
s指向新对象。
-
使用
new关键字:如String s = new String("xyz");时:- JVM在堆上创建 “xyz” 的新对象。
- 字符串字面量 “xyz” 若未在常量池中,也会被加入。
s指向堆上的新对象,常量池中的 “xyz” 不变。
-
因此,堆中的String对象可能与常量池中的String对象有如下关系:
- 完全独立的String对象(通过
new String("Literal")创建) - 直接引用常量池中的String对象(通过字面量方式创建)
- 完全独立的String对象(通过
⚠️ 注意:Java 7及之后的版本将字符串常量池从方法区移动到了Java堆内。
🔹 3、Java 集合类存储过程
Java中的集合类存储过程涉及栈和堆内存:
-
栈内存:存放集合的引用,如
List<String> list = new ArrayList<>();中的list。 -
堆内存:存放实际的集合对象和元素,如上述
ArrayList对象和其包含的String对象。-
栈内存(Stack):
- 当你声明一个集合变量时,例如
List<String> list = new ArrayList<>();,变量list本身是一个引用,这个引用存放在栈内存上。 - 对于
Map<String, String> map = new HashMap<>();,同样map是一个引用,存放在栈内存上。
- 当你声明一个集合变量时,例如
-
堆内存(Heap):
- 实际的
ArrayList或HashMap对象是在堆内存中创建的。这意味着所有的对象数据,包括里面存储的元素,都存放在堆内存中。 - 对于
List<String>,它存储的是字符串对象的引用。字符串对象本身存放在堆内存中,如果是字符串字面量,还会在字符串常量池中有一个引用。 - 对于
Map<String, String>,同样是存储键和值对象的引用。如果键和值是字符串字面量,它们同样会被存放在堆内存,并在字符串常量池中维护引用。
- 实际的
-
⚠️ 注意:基本数据类型被用作集合元素时,会被自动装箱为对应的包装类对象。
🔹 4、String 在常量池中的示例
String a = "abc";- 常量池中创建 “abc” 对象,
a指向该对象。
- 常量池中创建 “abc” 对象,
String b = "abc";b指向常量池中已存在的 “abc” 对象。
String c = new String("xyz");- “xyz” 加入常量池(若未存在),
c指向堆上的新对象。
- “xyz” 加入常量池(若未存在),
String s1 = new String("xyz");s1指向堆上的新对象,常量池中的 “xyz” 对象不变。
String s2 = new String("xyz");s2指向堆上另一个新对象,常量池中的 “xyz” 对象不变。
String s3 = "xyz";s3指向常量池中的 “xyz” 对象。
String s4 = "xyz";s4也指向常量池中的 “xyz” 对象。
⚠️ 注意:使用 new 关键字创建的字符串对象总是在堆上创建,而字面量方式创建的字符串对象会首先查询常量池。
















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











