






1、加载文档
本文以pdf文档作为示例演示
首先要进行依赖下载
pip install pypdf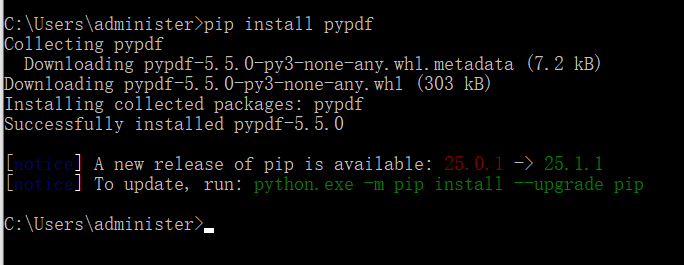
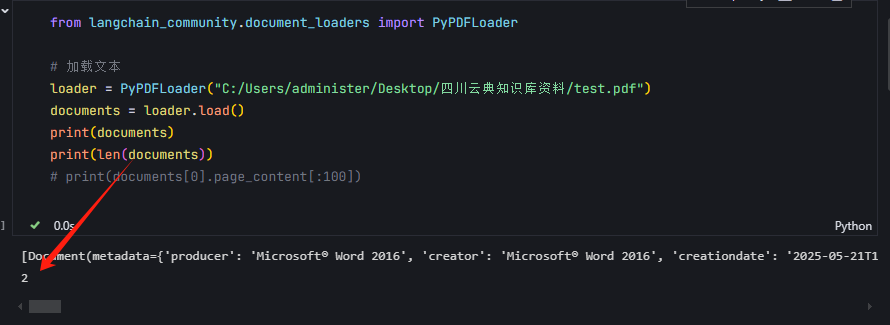
from langchain_community.document_loaders import PyPDFLoader
# 加载文本
loader = PyPDFLoader("C:/Users/administer/Desktop/四川云典知识库资料/test.pdf")
documents = loader.load()
print(documents)
print(documents[0].page_content[:100])执行代码看是否输出打印结果
2、分块
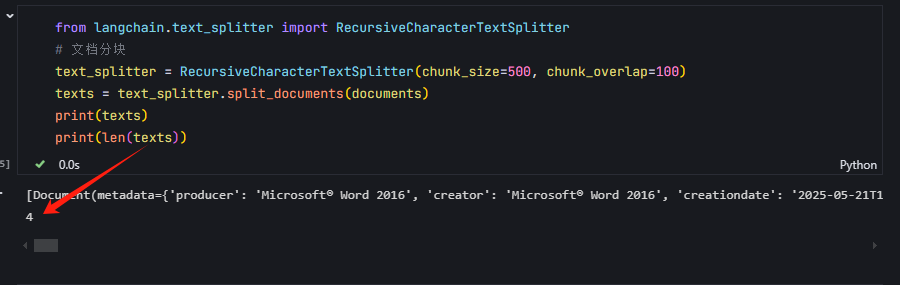
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
print(texts)
from langchain.text_splitter import CharacterTextSplitter
# 文档分块
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10, separator="\n")
texts = text_splitter.split_documents(documents)
print(texts)
两个分类的使用区别分块执行结果,可以看到文档个数变多了
这里补充说明一下分块的的两个类说明:
RecursiveCharacterTextSplitter:采用递归方式分割文本,基于用户定义的分隔符列表进行多次分割,直到每个文本块的大小满足预设的chunk_size。它更加智能地处理文本,能够更好地保持文本的语义结构和连贯性。此外,它还支持chunk_overlap参数,允许相邻文本块之间有重叠部分,以保留更多的上下文信息。
CharacterTextSplitter:则直接基于指定的字符序列(如换行符、空格等)将文本分割成小块。它的分割方式相对简单直接,不涉及递归处理。虽然它也支持自定义分割大小和重叠部分,但在处理复杂文本结构和保持语义连贯性方面可能不如RecursiveCharacterTextSplitter灵活。
3、向量化存储
这里需要先下载两个依赖
pip install langchain-ollama
pip install chromadb langchain-chroma
我使用的是本地的ollama模型,所以需要在模型里面安装好具体要用到的模型
from langchain_chroma import Chroma
# from langchain_openai import OpenAIEmbeddings # 需要申请api key
# vector_store = Chroma.afrom_documents(documents=texts, embedding=OpenAIEmbeddings(), persist_directory="D:/chroma_db")
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(
base_url= "http://119.6.253.231:3001", # 本地模型地址
model="deepseek-r1:32b"
)
# 本地向量化存储
db = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="D:/chroma_db" # 本地向量库地址
)
print("向量化完成")
print(db)执行成功后,可以看到在对应目录下多了对应的存储文件:

4、简单RAG初体验
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 3})
prompt_template = """
您是一个设计用于査询文档来回答问题的AI助手
上下文:{context}
问题:{question}
"""
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| ChatPromptTemplate.from_template(prompt_template)
| llm # 为上一篇创建的Deepseek模型
)
def get_answer(question):
docs = db.similarity_search(question)
answer = chain.invoke({"input_documents": docs, "question": question})
return answer
# 测试
question = "智慧金农联系人"
answer = get_answer(question)
print(answer)
response = chain.invoke(question)
print(response)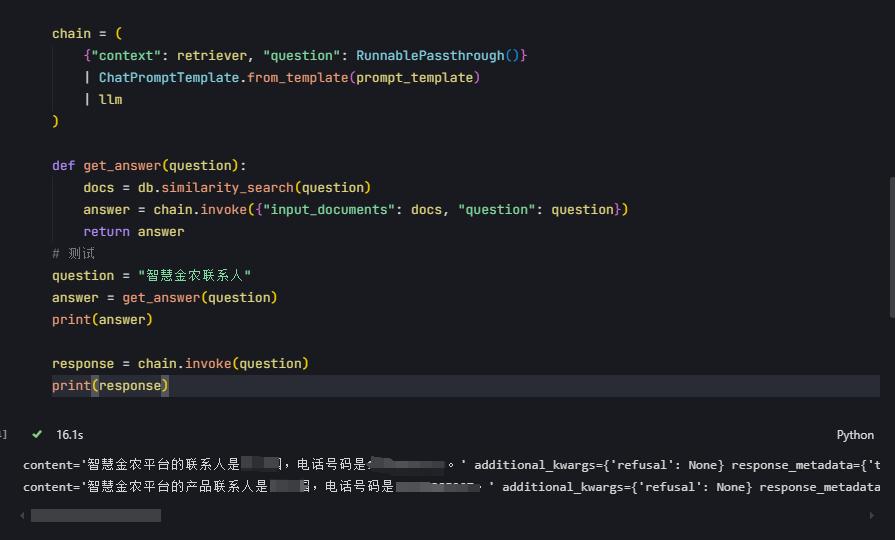
结语
至此,我们简单的RAG就创建成功啦,是不是很简单,原来dify使用本地知识库查询页不过如此!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









