







🔥 Hi,我是小余。 本文已收录到 GitHub · Androider-Planet 中。这里有 Android 进阶成长知识体系,关注公众号 [小余的自习室] ,在成功的路上不迷路!
前言
你是不是工作了很多年了,一直没搞清楚计算机中的各种编码规则,虽然平时都会使用,但是内部机制原理一直都是之其然而不知其所以然,开发中也会经常涉及到这块内容,但都没有太多重视,这可能会让有吃一些亏(出项目bug了),本着追本溯源的精神或是为了让自己在少出血bug,小余今天就来聊聊这块内容。
目录
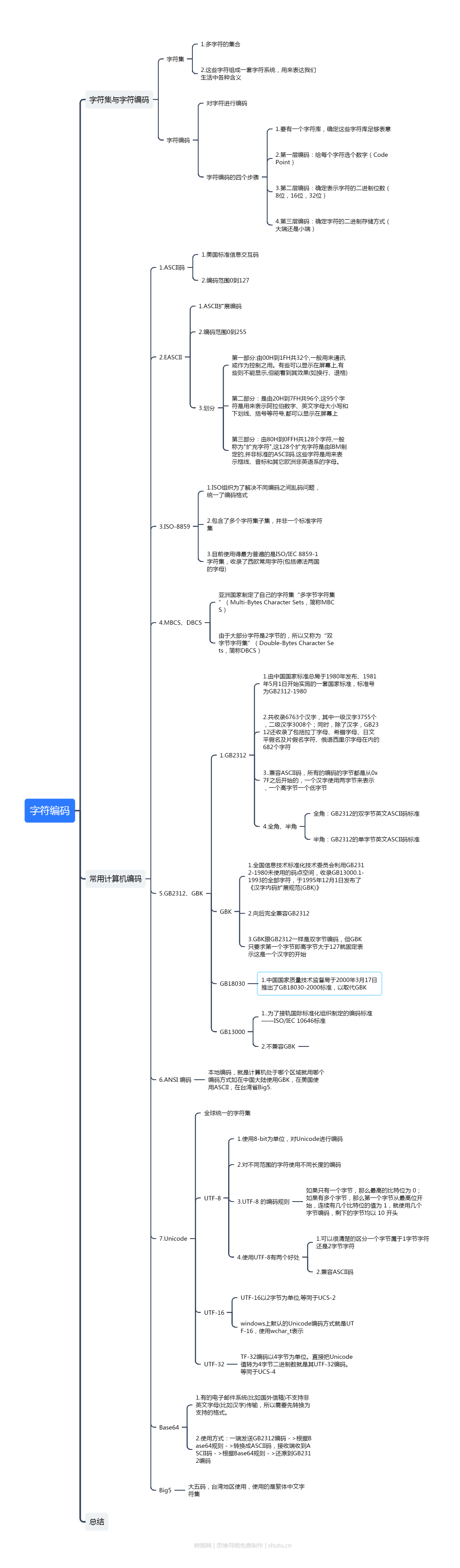
1.字符集与字符编码
首先要明确两概念,字符集(charset)和字符编码(encoding)。
字符集
字符集顾名思义:很多字符的集合。这些字符组成一套字符系统,用来表达我们生活中各种含义,
比如0~9以及各种加减法等符号的集合,可以表示生活中的“数字集合”,不然1+1是什么计算机可不知道? 26个大小写英文字母加上标点符号就组成了“英文字符集“,这些字符集在英美人看来就组成了一套符号系统,看到”I Love you“就知道什么意思了。 再比如我们新华字典中的所有汉字加上标点符号就组成了“中文字符集”,这个字符集就组成了中文文字系统。看到“我爱你”也就知道什么意思了,可以对于不懂中文的老外来,因为没有中文字符集,看到“我爱你”可就一脸懵逼了。
字符编码
字符编码:言外之意就是对字符进行编码,那为什么要对字符编码,其实字符编码最终目的就是为了存储或者传输。我们的计算机最早是用来提供算术功能的,和算盘功能类似,但是后来发现计算机可以做很多事情。 其中就包括存储机制,如何存储呢?假设“LOVE”这个单词,我们使用数字1代表L,数字2代表O,数字3代表V,数字4代表E,将1234存储在某个区域,这样就可以知道这4个数字代表了“LOVE”,当然实际LOVE有自己的字符表示,这里使用1234作为例讲解。
字符编码的四个步骤
要在计算机中建立一个“字符编码模型”,需要四个步骤:
- 1.要有一个字符库,确定这些字符库足够表意。比如ASCII字符集,已经足够表示英文系统,但是不能表达中文,于是有了GB2312字符集。
- 2.第一层编码:给每个字符选个数字(Code Point),比如ASCII码中,用65表示“A”,97表示“a”。
- 3.第二层编码:确定表示字符的二进制位数(8位,16位,32位)。ASCII码使用7位来表示,因为当时制定者觉得7位以及够用了,DBCS(双字节字符集)使用了16位。
- 4.第三层编码: 确定字符的二进制存储方式(大端还是小端)。比如X86机器使用小端。
一个字符一般只有一种编码格式,当字符集中的字符不够用时,会增加一些新的字符,使用新的字符编码格式,形成新的字符集。所以有时候字符集和字符编码的概念是很模糊的,并不严格区分。比如ASCII码既可以成为一段“字符集”,也可以称为一种“编码格式”。
也有一些字符集有多种编码格式:如Unicode,其中UTF-8和UTF-16等都是其编码格式,这个后面是详细讲解。
2.常用计算机编码
1.ASCII码
ASCII码全称“American Standard Code for Information Interchange”,美国标准信息交互码,由美国标准委员会(American Standards Association,简称ASA)制定,后来该协会改组为“美国国家标准学会”(American National Standard Institute , 简称ANSI ),所以很多资料上说ASCII码是由ANSI指定的。
ASCII码是从电报码发展过来的,最早使用在7-bits电传打印机上。1960年,ASA将ASCII标准化,于1963年发布第一版,1967年再发布一次大的版本,这个标准版本,也是一个7-bit码,包含33个非打印字符(现在许多已经废弃了),95个打印字符(包含空格符),编码范围为0~127。
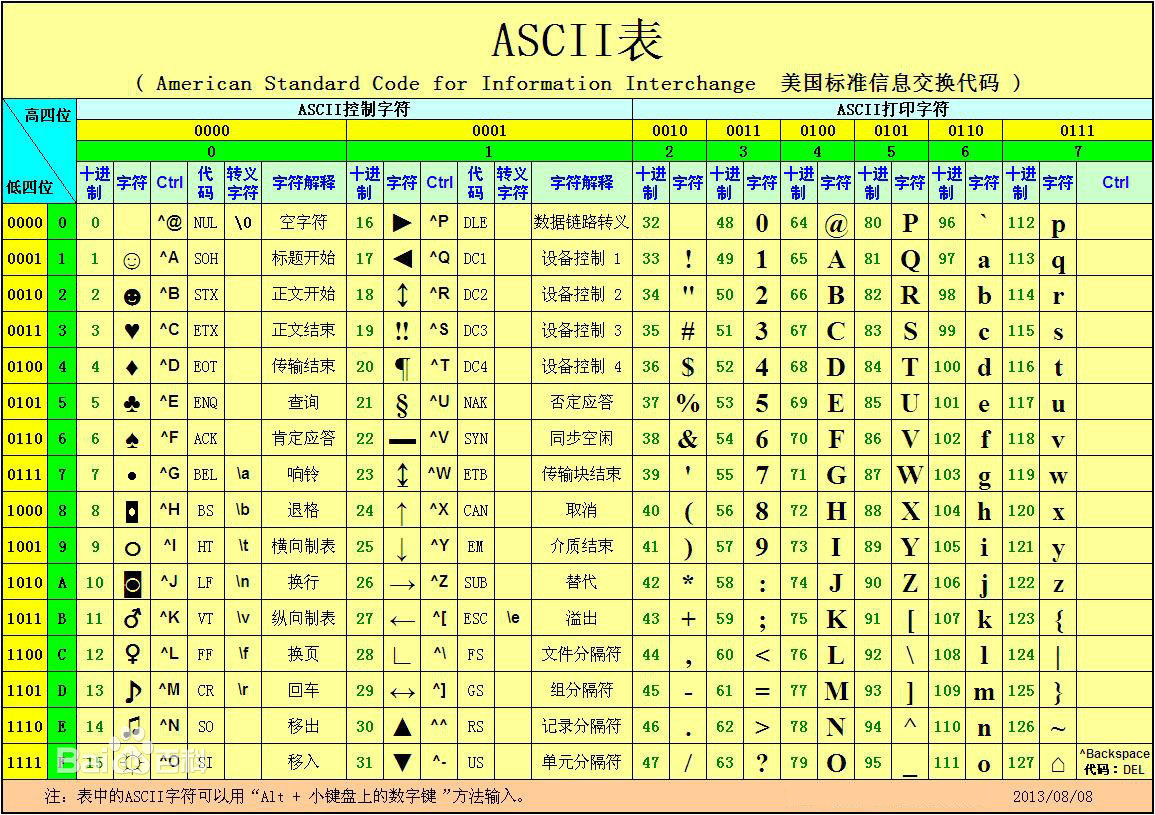
然而ASCII码只是美国的标准,对于其他国家,如中文,日文,韩文等大多使用的是象形文字,127个字符远远无法表达中国的汉字文化,于是各国在ASCII的基础上制定了自己的字符集,但是本质上都兼容ASCII,如中国大陆的GK2312,台湾省的(Big5)小日子的JIS等编码规范。
2.EASCII
其实标准的ASCII就是7-bit的编码(8字节,但是最高位没有编码),后来使用过程中发现127个字符有点不够用,于是将ASCII进行了扩展,叫做EASCII或者high-ASCII,8位的,能表示256个字符。
由于不同的应用场景,有不同的编码,有IBM的Extend ASCII和ANSI的Extend ASCII。 去wikipedia上会发现有好多种ASCII的标准,大类就是IBM和ANSI(Windows的,微软很强势,ANSI的东西感觉就是给他们家用的)两种,其实都是为了给自家系统用的,随着IBM操作系统的坠落,IBM的扩展ASCII也根本上淡出视野。
扩展的ASCII的产生
搭载Windows系统的计算机进入欧洲之后,发现标准的ASCII并不能满足欧洲这些拉丁语族国家的语言表意,决定对其进行扩展。同为印欧语系,发现扩展起来也没那么难,总共256个值就包括所有了。只需要将原来的7-bit扩展为8-bit,将原来的标准ASCII保留,第一位使用0来表示。将扩展的字符第一位使用1来表示
扩展ASCII的组成
具体来讲,扩展后的ASCII码表可以看成由三部分组成:
- 第一部分:由00H到1FH共32个,一般用来通讯或作为控制之用。有些可以显示在屏幕上,有些则不能显示,但能看到其效果(如换行、退格)
- 第二部分:是由20H到7FH共96个,这95个字符是用来表示阿拉伯数字、英文字母大小写和下划线、括号等符号,都可以显示在屏幕上.
- 第三部分:由80H到0FFH共128个字符,一般称为"扩充字符",这128个扩充字符是由IBM制定的,并非标准的ASCII码.这些字符是用来表示框线、音标和其它欧洲非英语系的字母。

3.ISO-8859
由于每个国家以及公司对编码的各自定制化,导致同一个字符在不同电脑之间由于编码的不一致,显示的结果也不一样,现象就是乱码。 那为了解决这个问题,ISO组织统一了一套标准的字符集。
与ASCII、EASCII字符编码方案只包括单个独立的字符集不同,ISO/IEC 8859字符编码方案包括了一组字符集, 或者说ISO/IEC 8859相当于是一组字符集的总称,其内共包含了15个字符集, 即ISO/IEC 8859-n,n=1、2、3…15、16,其中12未定义,所以实际上共15个。
这15个字符集,大致上包括了欧洲各国所使用到的字符(甚至还包括一些外来语字符),而且每一个字符集的补充扩展部分(即除了兼容ASCII字符之外的部分),都只实际使用了0xA00xFF(十进制为160255)这96个编码,而0x800x9F(十进制为128159)这32个编码并未实际定义字符。
其中,目前使用得最为普遍的是ISO/IEC 8859-1字符集,收录了西欧常用字符(包括德法两国的字母)。
ISO/IEC 8859-1往往简称为ISO 8859-1,而且还有一个称之为Latin-1(也写作Latin1)的别名,即:ISO/IEC 8859-1 = ISO 8859-1 = Latin-1 = Latin1。
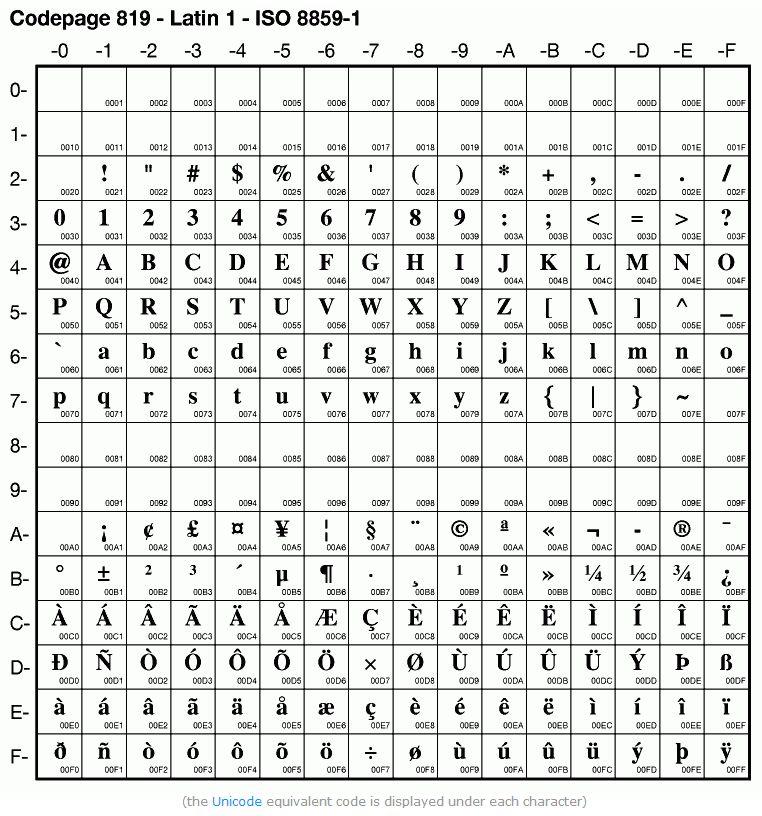
从ISO 8859-1到ISO 8859-16各自所收录的字符分别如下:
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
4.MBCS、DBCS
前面说的ASCII,EASCII,ISO-8859中的每个字符使用的是8-bits表示的,所以称为“单字节字符集”(Single-Byte Character Set,简称SBCS)。
但是到了亚洲,如中,日,韩等国家每个文字就是一个字符,对于单字节的字符集来,远远放不下了,于是亚洲国家制定了自己的字符集“多字节字符集” (Multi-Bytes Character Sets,简称MBCS)
windows 系统中,本地字符集就是MBCS,不过由于大部分字符是2字节的,所以又称为“双字节字符集”(Double-Bytes Character Sets,简称DBCS),所以有的时候看到MBCS、DBCS,都是一回事。MBCS是完全兼容标准ASCII码的。
5.GB2312、GBK、
当计算机被引入中国后,相关部门设计了GB系列规范(GB为国家的拼音缩写)。按照GB系列编码方案,在一段文本中,如果一个字节是0~127,那么这个字节的含义与ASCII编码相同,否则,这个字节和下一个字节共同组成汉字(或是GB编码定义的其他字符)。因此,GB系列编码方案向下完全直接兼容ASCII编码方案。也就是说,如果当前文本中使用的字符全是ASCII中的字符,则其GB编码和ASCII编码是完成一样的。
GB2312是最早的GB编码格式,收入了不足一万个汉字,基本能满足日常需求,但是中国文件可是博大精深,区区一万字肯定无法满足,于是又在GB2312基础上进行了扩展,扩展后的编码方案称之为GBK(K是扩的拼音缩写),后来又在GBK的基础上扩了GB18030编码方案,增加了一些少数名族的文字,一些生僻字被编到4个字节。
GB2312,GBK,GB18030(不包括GB13000)每次扩展都会完全兼容前一个版本。这里要指出,虽然都用多个字节表示一个字符,但是GB类的汉字编码与后文的Unicode编码方案的UTF-8、UTF-16、UTF-32等字符编码方式是毫无关系的
不过,也正因为不得不使用多个字节来表示一个字符,相较于只使用单个字节的ASCII编码方案,GB系列编码方案与后面要介绍的Unicode编码方案一样,无疑导致了更高的复杂度(包括时间复杂度、空间复杂度等)。
比如,当多字节字符与原先的ASCII字符混用时:
- 1)要么将原先的ASCII字符重新编码为多个字节表示,以便与其他多字节字符统一起来(UTF-16、UTF-32等采用的就是这种方法);
- 2)要么保持ASCII字符为单个字节编码不变,但将其他多字节字符编码中的各个字节的最高位(即首位)设为1,以避免与字节最高位为0的ASCII编码相冲突(GB、UTF-8等采用的就是这种方法) 。
前者具有更高的空间复杂度,因为原先只需要单个字节表示的ASCII字符,现在也必须用多个字节来表示,显然更为耗费存储空间;后者则具有更高的时间复杂度,因为为了避免冲突以及其他种种考虑(比如扩展性、容错性等),使用了更为复杂的编码算法(Encoding Algorithm),无疑更为耗费计算时间。
GB2312
GB2312编码方案,即《信息交换用汉字编码字符集——基本集》,是由中国国家标准总局于1980年发布、1981年5月1日开始实施的一套国家标准,标准号为GB2312-1980。
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。
GB2312编码为了兼容ASCII码,所有的编码的字节都是从0x7F之后开始的,一个汉字使用两字节来表示,一个高字节一个低字节,如果一个字节的小余0x7F的值,则表示的是一个ASCII码值。

虽然GB2312完全兼容ASCII码,但是其并不兼容其他扩码,如EASCII。
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,除了汉字,GB2312还收录了包括拉丁字母、希腊字母、日文平假名及片假名字符、俄语西里尔字母在内的682个字符。
可能是处于美观的考虑,除了汉字外的682个字符中,包括ASCII里本来就有的数字、标点、字母等字符,又再次编写了两字长的GB2312版本。 这682个双字节编码字符就是常说的“全角”字符,而这些字符所对应的单字节编码的ASCII字符就被称之为“半角”字符。
全角、半角
全角字符是中文显示及双字节中文编码的历史遗留问题。
早期的点阵显示器上由于像素有限,原先ASCII西文字符的显示宽度(比如8像素的宽度)用来显示汉字有些捉襟见肘(实际上早期的针式打印机在打印输出时也存在这个问题),因此就采用了两倍于ASCII字符的显示宽度(比如16像素的宽度)来显示汉字。
这样一来,ASCII西文字符在显示时其宽度为汉字的一半。或许是为了在西文字符与汉字混合排版时,让西文字符能与汉字对齐等视觉美观上的考虑,于是就设计了让西文字母、数字和标点等特殊字符在外观视觉上也占用一个汉字的视觉空间(主要是宽度),并且在内部存储上也同汉字一样使用2个字节进行存储的方案。这些与汉字在显示宽度上一样的西文字符就被称之为全角字符。
而原来ASCII中的西文字符由于在外观视觉上仅占用半个汉字的视觉空间(主要是宽度),并且在内部存储上使用1个字节进行存储,相对于全角字符,因而被称之为半角字符。
后来,其中的一些全角字符因为比较有用,就得到了广泛应用(比如全角的逗号“,”、问号“?”、感叹号“!”、空格“ ”等,这些字符在输入法中文输入状态下的半角与全角是一样的,英文输入状态下全角跟中文输入状态一样,但半角大约为全角的二分之一宽),专用于中日韩文本,成为了标准的中日韩标点字符。而其它的许多全角字符则逐渐失去了价值(现在很少需要让纯文本的中文和西文字符对齐了),就很少再用了。
现在全球字符编码的事实标准是Unicode字符集及基于此的UTF-8、UTF-16等编码实现方式。Unicode吸纳了许多遗留(legacy)编码,并且为了兼容性而保留了所有字符。因此中文编码方案中的这些全角字符也保留下来了,而国家标准也仍要求字体和软件都支持这些全角字符。
不过,半角和全角字符的关系在UTF-8、UTF-16等中不再是简单的1字节和2字节的关系了。具体参见后文。
GBK
GB2312-1980共收录6763个汉字,覆盖了中国大陆99.75%的使用频率,基本满足了汉字的计算机处理需要。
但对于人名、古汉语等方面出现的罕用字、生僻字,GB2312不能处理,如部分在GB2312-1980推出以后才简化的汉字(如“啰”)、部分人名用字(如歌手陶喆的“喆”字)、台湾及香港使用的繁体字、日语及朝鲜语汉字等,并未收录在内。
于是全国信息技术标准化技术委员会利用GB2312-1980未使用的码点空间,收录GB13000.1-1993的全部字符,于1995年12月1日发布了《汉字内码扩展规范(GBK)》(Guo-Biao Kuozhan国家标准扩展码,是根据GB13000.1-1993(GB13000下文有详细介绍),对GB2312-1980的扩展;英文全称Chinese Internal Code Specification)
虽然GBK跟GB2312一样是双字节编码,但GBK只要求第一个字节即高字节大于127就固定表示这是一个汉字的开始(即GBK编码高字节的首位必须是1;0~127当然表示的还是ASCII字符),不再像GB2312一样要求第二个字节即低字节也必须大于127(即GBK编码低字节首位既可以是0,也可以是1)。
正因为如此,作为同样是双字节编码的GBK才可以收录比GB2312更多的字符。
GBK字符集向后完全兼容GB2312,同时还支持GB2312-1980不支持的部分中文简体、中文繁体、日文(不过该字符集不支持韩国文字,也是其在实际使用中与Unicode字符集相比欠缺的部分),共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一体。
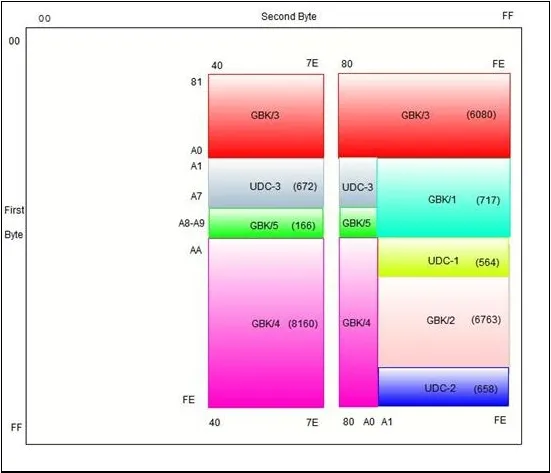
GBK的编码框架(Code Scheme):其中GBK/1收录除GB2312字符外的其他增补字符,GBK/2收录GB2312字符,GBK/3收录CJK字符,GBK/4收录CJK字符和增补字符,GBK/5为非中文字符,UDC为用户自定义字符
GB18030
中国国家质量技术监督局于2000年3月17日推出了GB18030-2000标准,以取代GBK。GB18030-2000除保留全部GBK编码汉字之外,在第二字节再度进行扩展,增加了大约一百个汉字及四位元组编码空间。
GB18030《信息交换用汉字编码字符集基本集的补充》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
2005年,GB18030编码方案在GB18030-2000的基础上又进行了扩充,于是又有了GB18030-2005《信息技术中文编码字符集》。
如前所述,GB18030-2000是GBK的升级版本,它的主要特点是在GBK基础上增加了CJK中日韩统一表意文字扩充A的汉字;而GB18030-2005的主要特点是在GB18030-2000基础上又增加了CJK中日韩统一表意文字扩充B的汉字。
微软也为GB18030定义了专门的代码页:CP54936,但是这个代码页实际上并没有真正使用(在Windows 7的“控制面板”-“区域和语言”-“管理”-“非Unicode程序的语言”中没有提供选项;在Windows cmd命令行中可通过命令chcp 54936更改,之后在cmd中可显示中文,但却不支持中文输入)。
GB13000
在所有的GB编码方案中,除了逐步扩展并保持向下兼容的GB2312、GBK、GB18030等GB系列编码方案,还有一个与GB2312、GBK、GB18030等GB系列编码方案不兼容的、特殊的GB编码方案——GB13000编码方案。(注意,虽然GBK的制定,主要目的就是为了收录GB13000中的所有字符,但GBK的编码方式与GB13000是完全不同的。因此,习惯上所称的GB系列编码方案一般并不包括GB13000在内。)
为了对世界各个国家和地区的所有字符进行统一编码,以实现对世界上所有字符在计算机上的统一处理,国际标准化组织制定了新的编码标准——ISO/IEC 10646标准(即Universal Character Set通用字符集,简称UCS,与统一联盟制定的Unicode标准兼容,两者的关系详见后文)。
为了与国际标准接轨,中国于是制定了与ISO/IEC 10646.1:1993标准相对应的中国国家标准——GB13000.1-1993《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
2010年又发布了其替代标准——GB13000-2010《信息技术通用多八位编码字符集(UCS)》,此标准等同于国际标准ISO/IEC 10646:2003《信息技术通用多八位编码字符集(UCS)》。
GB13000与国际标准ISO/IEC10646及Unicode标准目前在基本平面(即BMP,详见后文)上基本保持一致。 
各汉字(中文字符)编码方案之间的关系(Big5为繁体汉字编码方案,主要通行于港澳台地区,本文不作详细介绍)
6.ANSI 编码
ANSI原意是指美国国家标准协会,但是在windows系统中,ANSI编码意思却代表“本地编码”。 。也就是说,在中国代表GBK,在台湾代表Big5,在日本代表JIS,所以windows编程中常说的ANSI字符串,就是指本地编码的字符串,在中国,就是一种DBCS,用1个和2个字节表示一个字符的编码。
这也就是我们使用Notepad++进行文件编写的时候,会默认给我们提供ANSI的编码格式,其实就是GBK编码啦。
事实上并没有ANSI编码,ANSI是什么,是American National Standards Institute美国国家标准协会,协会,机构而已。ANSI也有自己的ASCII标准。但是我们看到的这个ANSI并不是特指ANSI的ASCII标准,这个应该指所有的本地化编码。
这个是微软的锅。一开始只有英文操作系统,用ANSI表示ANSI的Extend ASCII编码。但是到了欧洲就是ISO-8859-1编码,到中国应该是GBK编码,日本应该是JIS编码等等,为了把实际编码的差异隐藏起来,用所谓的ANSI编码来表示所有Windows系统上的地区化编码,然后操作系统自己做转换,不同的国家地区,就会对应不同的编码规范。ANSI应该叫地区化编码,只出现在Windows系统中,就好像一种工厂模式,被Windows系统用来统一地区化编码的叫法。
7.Unicode、UCS
以上的编码都是本地化编码,一国之内还没有问题,但是要跨国,就不行了。比如汉字,在只有ISO-8859系列字符集的电脑上显示就只能是乱码了,要显示汉字,电脑上必须装GB2312或GBK的字符集。有没有一个字符集,能够包含全球所有的字符呢?这就是Unicode和UCS
1988年,Joe Becker 发布了一个草案,提出了“Unicode”的概念,他解释说“‘Unicode’是一种唯一的、统一的、全球的编码”。后来,RLG、Sun、Microsoft、NeXT(乔布斯被赶出苹果后创建的公司)的人也都逐渐加入到Unicode工作组里。1991年1月3日,Unicode联盟组织成立,同年发布了Unicode1.0.
同时,ISO组织也在做同样的事情,创造一个全球统一的字符集(Universal Coded Character Set,简称UCS),1993年发布了标准ISO 10646-1。
后来,两个组织认识到,世界不需要两个不兼容的字符集,于是,开始合作。从Unicode2.0开始,开始采用和UCS相同的字库和字码。这样,两个项目仍都存在,并独立地公布各自的标准。但双方都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。所以,现在说到UCS字符集,跟Unicode可以看成一回事。
Unicode编码包含两个层次:第一层定义字符的数值和第二层定义数值的实现方式。Unicode用数字 0x0~0x10FFFF 表示所有字符,所以最多可以容纳 1114112 个字符。数值的编码方式,也就是实现方式包括 UTF-8,UTF-16,UTF-32 三种。
有人会说,Unicode不是两个字节表示字符的码?为什么数值可以到0x10FFFF,这不21位,两个半字节还多了吗?其实,这是混淆了Unicode的数值定义和实现,这根本就是两个概念,Unicode到底用几个字节表示,取决于其实现方式是UTF-8,UTF-16,还是UTF-32.
比如,“汉字”对应的Unicode值是0x6c49和0x5b57,而编码实现是:
char data_utf8[]= {0xE6,0xB1,0x89,0xE5,0xAD,0x97}; //UTF-8编码 char16_t data_utf16[]= {0x6C49,0x5B57}; //UTF-16编码 char32_t data_utf32[]= {0x00006C49,0x00005B57}; //UTF-32编码
UTF-8
UTF,全称“Unicode Transformation Formats”。是Unicode的编码格式。
UTF-8是使用8-bit为单位,对Unicode进行编码的。特点是,对不同范围的字符使用不同长度的编码。
| Unicode编码(十六进制) | UTF-8 字节流(二进制) |
|---|---|
| 00000000 - 0000007F | 0xxxxxxx |
| 00000080 - 000007FF | 110xxxxx 10xxxxxx |
| 00000800 - 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 - 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000 - 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000 - 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8 的编码规则很简单: 如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。具体的表现形式为(xxx 就用来存储 Unicode 中的字符编号):
0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
110xxxxx 10xxxxxx:双字节编码形式;
1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式;
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式。
下面是一些字符的编码实例(绿色部分表示本来的 Unicode 编号):
| 字符 | N | æ | 齐 |
|---|---|---|---|
| Unicode 编号(二进制) | 01001110 | 11100110 | 00101110 11101100 |
| Unicode 编号(十六进制) | 4E | E6 | 2E EC |
| UTF-8 编码(二进制) | 01001110 | 11000011 10100110 | 11100010 10111011 10101100 |
| UTF-8 编码(十六进制) | 4E | C3 A6 | E2 BB AC |
UTF-8编码的最大长度是6个字节。
- 对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同,用1个字节表示,首位为0。
- 对于0x80-0x7FF之间的字符,用2个字节表示,第一个字节前三位“110”为标志位,第二个字节前两位“10”为标志位。剩下的11位用来表示Unicode值(7FF最多11位)。
- 同样,UTF-8的3个字节,可以表示0x800-0xFFFF的Unicode(最多16位)。
- UTF-8的4个字节,可以表示0x10000-0x001FFFFF的Unicode(最多21位)。 4个字节以内,已经包含了Unicode所有字符。
- 5、6个字节表示的已经是非Unicode编码范围,属于UCS-4 编码。早期UTF-8规范也可以达到6字节序列,不过2003年11月UTF-8 被 RFC 3629 重新规范,只能使用原来Unicode定义的区域, U+0000到U+10FFFF。根据规范,这些字节值将无法出现在合法 UTF-8序列中。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
UTF-8有两个好处:
-
- 1字节字符、2字节字符、3字节字符……的首字节标志位不同,这样可以很清楚的区分一个字节属于1字节字符还是2字节字符,如果一个字节流传输中出现错误,也不会错位,只影响部分字符,根据标志位,很容易找到下个正确字符。
-
- 兼容ASCII码, 英美字符用UTF-8可以一个字节表示,所以,www组织选用UTF-8作为推荐编码格式。2007年,在互联网上,UTF-8格式已经超过了ASCII码。
UTF-16
UTF-16以2字节为单位,等同于UCS-2.
| Unicode编码(十六进制) | UTF-16 字节流(二进制) |
|---|---|
| 00000000 - 0000FFFF | xxxxxxxx xxxxxxxx |
| 00010000 - 0010FFFF | 110110yyyyyyyyyy 110111xxxxxxxxxx |
Unicode值小于等于0xFFFF的,直接用两个字节表示,超过0xFFFF的,无法用两个字节表示。使用下面公式编码:
-
1.计算 U’= U – 0x10000 2. 将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx 3. 加上标志位,1101 10yy yyyy yyyy 1101 11xx xxxx xxxx:高位代理值为D800,低位代理值为DC00可见,这是4个字节表示,2个6位标志位,20位有效位。因为U最大是0x10FFFF,所以U’最大是0xFFFFF,20位足够表示。
案例1:
U+0020,这个值的范围在第一部分,即经过UTF-16编码后,结果仍然为U+0020,在内存中的顺序为00 20。案例2:
U+12345, 这个值的范围在第二部分,因此需要先减去0x10000,得到0x02345,拆分成高10位00 0000 1000和低10位11 0100 0101。根据上面规则加上特定值后,高位代理值为D808,低位代理值为DF45,最终内存中的顺序为D8 08 DF 45。
BOM的含义
BOM即Byte Order Mark字节序标记。BOM是为UTF-16和UTF-32准备的,用户标记字节序(byte order)。拿UTF-16来举例,其是以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流"594E",那么这是“奎”还是“乙”?
我们先来来看下UTF-16-Big Endian文件格式:

可以看到此时“文件”二字的unicode编码并没有超过0xFFFF,所以使用两个字节来保存:
而最早的“fe ff”即为Bom标签。
我们再来看下UTF-16-Little Endian文件格式:

使用的Bom标签居然变为了fffe。
Unicode规范中推荐的标记字节顺序的方法是BOM:在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"(零宽度无间断空间)的字符,它的编码是FEFF。而FEFF在UCS中是不不能再的字符(即不可见),所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者接收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称为BOM。
windows上默认的Unicode编码方式就是UTF-16,使用wchar_t表示。
UTF-32
UTF-32编码以4字节为单位。直接把Unicode值转为4字节二进制数就是其UTF-32编码。等同于UCS-4.
8.Base64
有的电子邮件系统(比如国外信箱)不支持非英文字母(比如汉字)传输,这是历史原因造成的(认为只有美国会使用电子邮件?)。因为一个英文字母使用ASCII编码来存储,占存储器的1个字节(8位),实际上只用了7位2进制来存储,第一位并没有使用,设置为0,所以,这样的系统认为凡是第一位是1的字节都是错误的。而有的编码方案(比如GB2312)不但使用多个字节编码一个字符,并且第一位经常是1,于是邮件系统就把1换成0,这样收到邮件的人就会发现邮件乱码。
为了能让邮件系统正常的收发信件,就需要把由其他编码存储的符号转换成ASCII码来传输。比如,在一端发送GB2312编码->根据Base64规则->转换成ASCII码,接收端收到ASCII码->根据Base64规则->还原到GB2312编码。
9.Big5
在台湾、香港与澳门地区,使用的是繁体中文字符集。而1980年发布的GB2312面向简体中文字符集,并不支持繁体汉字。在这些使用繁体中文字符集的地区,一度出现过很多不同厂商提出的字符集编码,这些编码彼此互不兼容,造成了信息交流的困难。为统一繁体字符集编码,1984年,台湾五大厂商宏碁、神通、佳佳、零壹以及大众一同制定了一种繁体中文编码方案,因其来源被称为五大码,英文写作Big5,后来按英文翻译回汉字后,普遍被称为大五码。 大五码是一种繁体中文汉字字符集,其中繁体汉字13053个,808个标点符号、希腊字母及特殊符号。大五码的编码码表直接针对存储而设计,每个字符统一使用两个字节存储表示。第1字节范围81H-FEH,避开了同ASCII码的冲突,第2字节范围是40H-7EH和A1H-FEH。因为Big5的字符编码范围同GB2312字符的存储码范围存在冲突,所以在同一正文不能对两种字符集的字符同时支持。 Big5编码的分布如表1-5所示,Big5字符主要部分集中在三个段内:标点符号、希腊字母及特殊符号;常用汉字;非常用汉字。其余部分保留给其他厂商支持。
Big5编码推出后,得到了繁体中文软件厂商的广泛支持,在使用繁体汉字的地区迅速普及使用。目前,Big5编码在台湾、香港、澳门及其他海外华人中普遍使用,成为了繁体中文编码的事实标准。在互联网中检索繁体中文网站,所打开的网页中,大多都是通过Big5编码产生的文档。
总结各种字符编码之间的关系
上面关于字符集和编码讲了许多概念,其实归类一下可以这么理解: 首先是单字节字符集:
- 1、最初美国ANSI发明了自己的编码ASCII,7-bit足够,这是标准ASCII。
- 2、标准ASCII码没有西欧国家拉丁文、英镑等字符,各公司、国家开始扩展,形成自己的扩展ASCII码字符集,各方混战,不过8-bit也就足够。
- 3、天下分久必合,ISO统一了8-bit字符集,叫做ISO 8859.
但是亚洲国家字符更多,一个字节远远不够,于是用多个字节表示,扩展形成本国字符集,中国GB系列,台湾Big5,日本JIS……,这些叫做多字节字符集(MBCS),windows中用双字节表示,也叫做(DBCS)。
以上字符都是群雄割据,各自为政,windows为了迎合大家需求,在哪个国家,默认编码就用那个国家的,不过后来不知怎么被误传位ANSI编码,其实ANSI怎么可能定义世界各国编码,不过可以理解成各编码都是在ANSI*础上扩展的,因为都兼容ANSI的标准ASCII码。
这时,ISO再次出手,和Unicode联盟携手打造了Unicode(UCS),意图一统江湖。Unicode确实包罗万象,涵盖了各国字符,于是流行世界。Unicode自身只定义了每个字符的数值,真正二进制编码格式却是UTF-8,UTF-16(UCS-2),UTF-32(UCS-4)。
至此,天下一统,但愿程序员的太平盛世到来了!我是小余,我们下期见。
参考
刨根究底字符编码之五——简体汉字编码方案(GB2312、GBK等)以及全角、半角、CJK
https://en.wikibooks.org/wiki/Unicode/Character_reference/D000-DFFF


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









