







一、即时编译
1、逃逸分析
JVM将执行状态分成了5个层次:
- 0层,解释执行(Interpreter) 【也就是将字节码解释成机器码的过程】
- 1层,使用C1即时编译器编译执行(不带profiling)
- 2层,使用C1即时编译器编译执行(带基本的profiling)
- 3层,使用C1即时编译器编译执行(带完全的profiling)
- 4层,使用C2即时编译器编译执行

- 如果在第0层的时候,重复将同一个字节码解释成机器码,那即时编译器就会将字节码编译成机器码,然后存入Code Cache,下次遇到相同的代码,就会执行,无需再次编译
- 这是即时编译器的好处,解释器遇到重复的字节码,还是会执行重复的解释
- 如果profiling统计某个方法调用次数过多,那么会上升到C2即时编译器,来进行更全面的优化
- 解释器是将字节码解释成所有平台都通用的机器码
- JIT即时编译器是会根据平台类型,生成平台特定的机器码
总结:
总之就是发现热点代码,然后提高将其编译成机器码来提高效率

2、方法内联
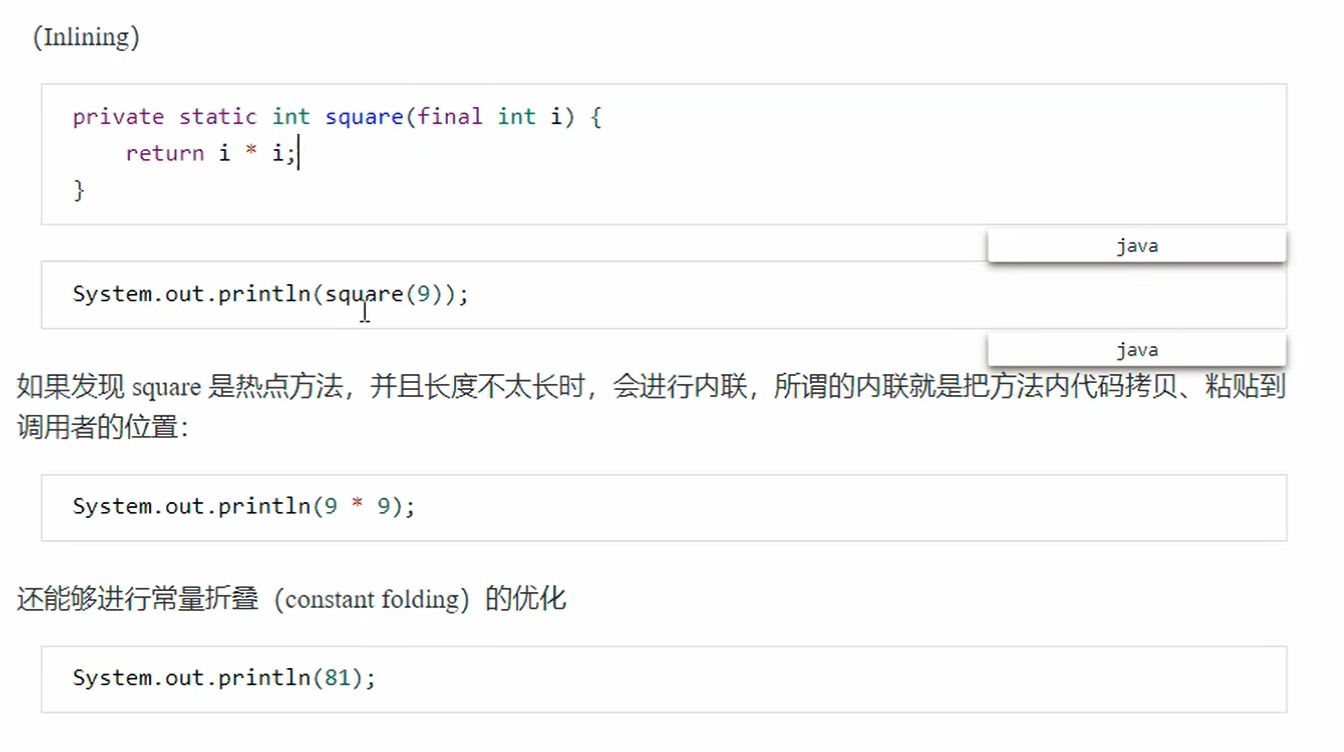
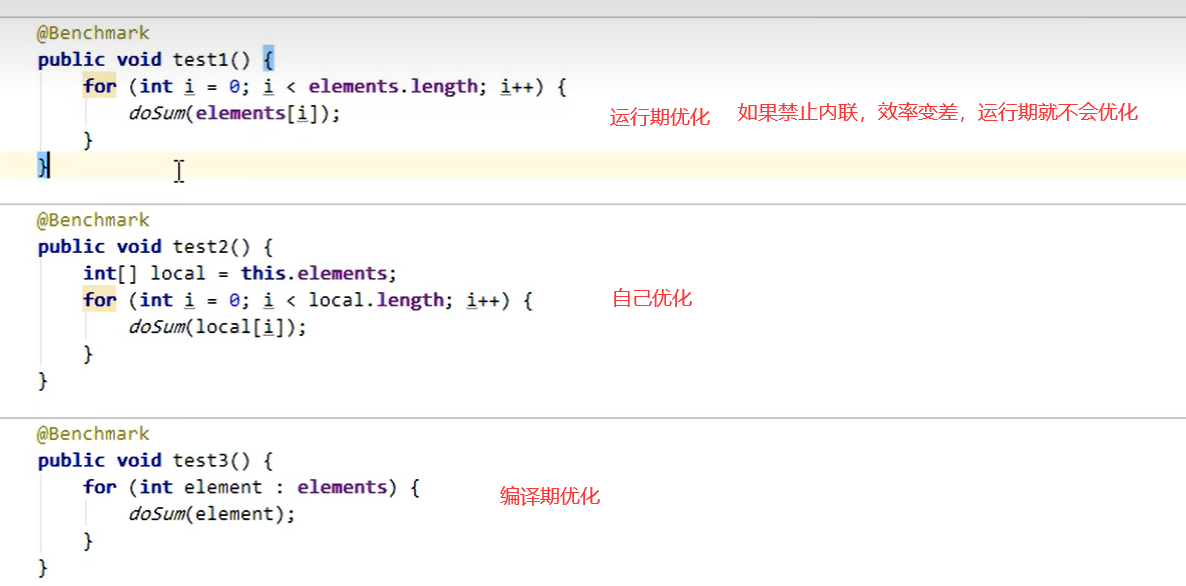
3、字段优化
机器码级别处理缓存
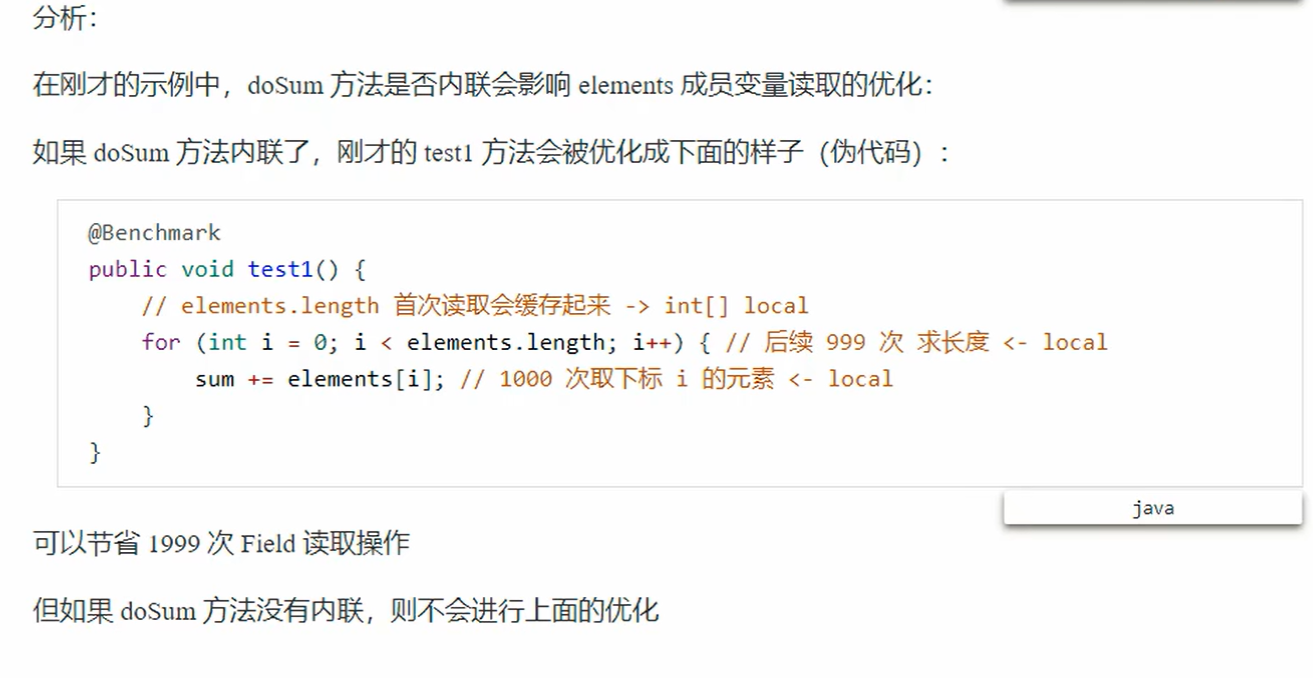
节省1900去查找成员变量的操作。
二、反射优化

一开始调用的是native本地的反射invoke方法,然后执行了15次达到一个阈值之后,会将本地的反射实现类修改成GenerateMethodAccessor1的新的反射实现类,这个实现类会在内部将反射调用转化成类名.方法名的方式调用,提高效率
阈值15是可以通过参数设定的。

















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











