






 一道蓝桥杯比赛中的C++题目,要求计算输入字符串中不连续子串COW的出现次数。文章分析了错误的解决方案,并提出了一种优化的思路,通过遍历字符串并维护C、O、W的计数来解决问题。
一道蓝桥杯比赛中的C++题目,要求计算输入字符串中不连续子串COW的出现次数。文章分析了错误的解决方案,并提出了一种优化的思路,通过遍历字符串并维护C、O、W的计数来解决问题。
应该不会有很多人来搜这道题,毕竟这题挺普通的,但给我的启发却很大;
(不多废话了)
首先题目描述 :
在她最喜欢的放牧场地中央,贝西偶然发现一个刻在一块大石头上的有趣题词。碑文的文字似乎是一个神秘古老的语言,包括只有三个大字C,O,和W。尽管贝茜无法破译的文字字母,她所欣赏的是,C,O,和W 的顺序形式构成了她最喜欢的一句话。她想知道有多少次COW 出现在文本中。
如果有COW 内有穿插其他字符,只要COW 字符出现在正确的顺序,贝西并不介意。她也不会介意,如果出现不同的COW 共享一些字母。例如,牛在CWOW 出现一次,在CCOW 两次,在CCOOWW八次。
给出碑文的内容,请帮贝西数出现COW 多少次
输入格式
输入的第一行包含一个整数N <= 10 ^ 5。第二行包含字符串的N 个字符,每个字符是一个C,O,或W.
输出格式
输出COW 作为输入字符串的子串出现的次数(不一定是连续的)。
需要注意的是,答案可以是非常大的,所以一定要使用64 位整数(在C++ 中用Long Long,Pascal中用int64)做你的计算
样例
样例 输入 #1
6
COOWWW
样例输出 #1
6
提示
对于50% 的数据,N <= 60。
Let's think about it first
在什么情况下才能连成 COW 呢?
当然是先找到 C 再找到 O 再找到 W 然后次数再加1
那有人就说了:直接for一下找到 W 然后再统计一下当前位置前的 C 和 O,最后一乘不就完事了吗?

很显然是不行的
那我们就要来考虑一种情况了:
OCW
如果用刚才这种思路的话输出结果是 1 , 然而正确答案是 0。所以我们还要考虑单词的顺序
于是便有了这个代码:
#include<bits/stdc++.h>
using namespace std;
int n,c,o;
int tot;
char ad[101];
int main()
{
cin>>n;
for (int i=1;i<=n;i++) cin>>ad[i];
for (int i=1;i<=n;i++)
{
if (ad[i]=='C')
{
c=1;
for (int j=i+1;j<=n;j++)
{
if (ad[j]=='O')
{
o=1;
for (int k=j+1;k<=n;k++)
{
if (ad[k]=='W')
{
tot+=1;
}
}
}
}
}
}
cout<<tot;
return 0;
}
它 RE 了
看了一眼数据规模 N <= 10 ^ 5,是不是数组开小了呢?
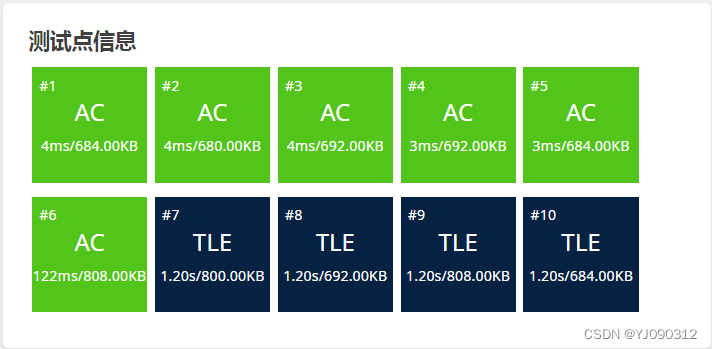
它 T 了
这说明他复杂度太高了,超时了,所以我要重新写这道题(太好了)
那换一种思路:
先循环一遍,如果遇到 C 了 那 C 的次数就 加一,如果遇到 O,那就让 O 加上 C 的次数,表示能连成 CO 的次数,如果再遇到 W,那就让 W 的次数 加上 O 的次数,就可以求出 COW 的次数了。
最后只要输出 W 的次数就行了
#include<bits/stdc++.h>
using namespace std;
int n,c,o;
long long tot;
char ad[100001];
int main()
{
cin>>n;
for (int i=1;i<=n;i++) cin>>ad[i];
for (int i=1;i<=n;i++)
{
if (ad[i]=='C') c++;
if (ad[i]=='O') o+=c;
if (ad[i]=='W')
{
tot+=o;
}
}
cout<<tot;
return 0;
}
(这是本蒟蒻的第二篇文章,觉得还可以的话留下一个赞吧)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









