







性能指标的资源都来自于:
/proc 文件系统
一、性能指标是什么?
高并发”和“响应快”一定是最先出现在你脑海里的两个词,而它们也正对应着性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,从系统资源的视角出发的指标,比如资源使用率、饱和度等。
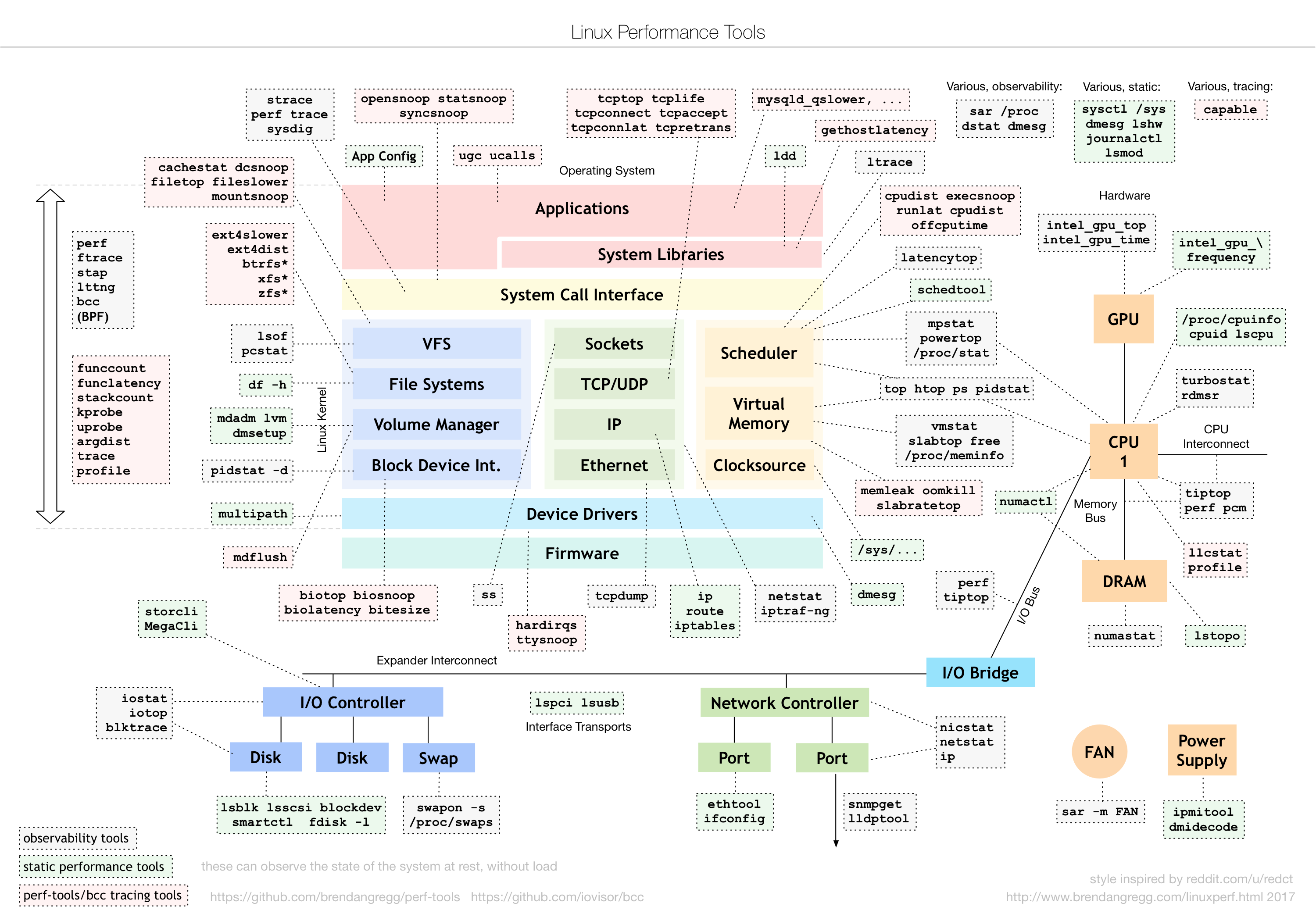
图片地址:
http://www.brendangregg.com/Perf/linux_perf_tools_full.png


1.01、我遇到性能瓶颈的排查思路

二、平均负载
1.top 或者 uptime 命令,来了解系统的负载情况。
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
这里每列输出的含义
02:34:03 // 当前时间
up 2 days, 20:14 // 系统运行时间
1 user // 正在登录用户数
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系
2.2、平均负载为多少时合理
查看CPU核数
grep 'model name' /proc/cpuinfo |wc -l
查看此时的平均负载:
uptime

平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数
并用 iostat、mpstat、pidstat 等工具,找平均负载高的根源
预先安装 stress 和 sysstat 包,
yum install -y epel-release yum install stress -y
yum install sysstat -y

模拟一个 CPU 使用率 100% 的场景
stress --cpu 1 --timeout 600

# -d 参数表示高亮显示变化的区域
watch -d uptime

# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
mpstat -P ALL 5
# 间隔 5 秒后输出一组数据

到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询
pidstat -u 5 1
stress的进程的CPU使用率为1


$ stress -i 1 --timeout 600
$ watch -d uptime
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
$ mpstat -P ALL 5 1
$ pidstat -u 5 1
可以发现,还是 stress 进程导致的



















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}