







监控部署落地
工单处理完了,我松了一口气,但是事情并没有告一段落。这个故障算是敲响了警钟:不能觉得 NSQ 性能不错就认为消息不会堆积了,必要的监控报警还是得安排上。
因为我司已经存在的基础设施,所以我决定使用 Prometheus 来监控 NSQ 服务。(Prometheus 的相关背景知识就不在这里科普了, 想看的请留言。)
Prometheus 通过 exporter 去采集第三方服务的数据,也就是说 NSQ 必须配置一个 exporter 才能接入 Prometheus。
Prometheus 的官方文档[Exporters and integrations | Prometheus]上对 exporter 有推荐,我顺着链接找到了官方推荐的 NSQ exporter[https://github.com/lovoo/nsq_exporter]。NSQ exporter 这个项目年久失修,最近的一次提交已经在 4 年前。
于是,我把这个项目拿到了本地,做了一些简单的改造, 使它支持 go mod。(PR 在这里[https://github.com/lovoo/nsq_exporter/pull/29])
NSQ exporter 部署完成后,接下来的问题是哪些指标需要监控?
参考官网[NSQ Docs 1.2.1 - nsqadmin]我认为这些指标需要重点关注:
-
Depth:当前 NSQ 堆积的消息。NSQ 在内存中默认只保存 8000 消息,超过的消息会持久化到磁盘中。
-
Requeued:消息 requeue 的次数。
-
Timed Out:处理超时的消息。
Prometheus 建议配置 Grafana 更加直观地查看指标的变动情况,我配置大体的效果如下:
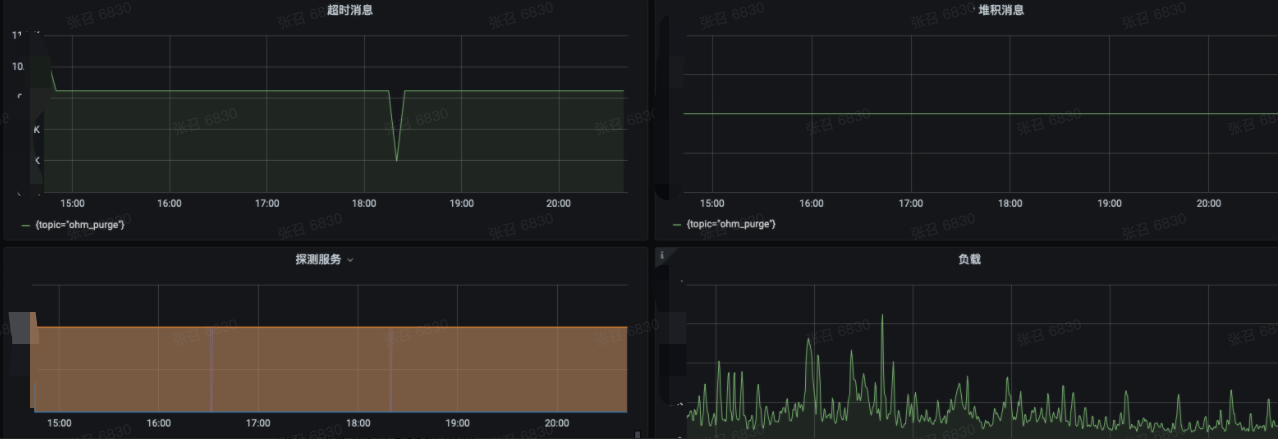
超时消息对应着 Timed Out 指标
-
堆积消息对应着 Depth 指标
-
负载是根据公式 sum(irate(NSQ_topic_message_count{}[5m])) 生成的。
-
探测服务是探测 NSQ exporter 服务是否正常。 因为该服务经常会因为 NSQ 压力过来导致 exporter 自身服务不可用。
自从 NSQ 配置监控服务后,我们能迅速感知 NSQ 当前状况,在报警发出后及时人工处理跟进。相关业务的稳定性有明显提升,此类问题引起的工单变少了;此外监控收集到的相关数据,让我们在接下来的性能优化工作中的思路更加清晰,方向更加明显。














 5235
5235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









