









关于MapReduce
气象数据集例子
使用hadoop分析数据
Map和Reduce阶段
Map阶段的输入是原始气象数据,输入格式为文本格式,Map函数的键值对,键为所在行相对于文件起始位置的偏移量,值则为该行文本内容。
这个例子的Map函数的任务是提取每行文本中的年份和气温信息。Map函数的输出经MapReduce框架处理后送至Reduce函数。处理过程需要根据键对键值对进行排序和分组。
Reduce函数负责遍历整个列表找出最大数,即为该年最高气温。
整个数据流如下图:

Java程序的实现代码见博文气象数据集例子Java程序代码
数据流
MapReduce作业是客户端需要执行的一个工作单元,包括:输入数据,MapReduce程序以及配置信息。
hadoop将作业分为若干个小任务(task),包括两类:Map任务和Reduce任务。
有两类节点控制作业执行过程:一个jobtracker和若干个tasktracker,jobtracker通过调度tasktracker上运行的任务来协调所有运行在系统上的作业,tasktracker在运行任务的同时向jobtracker汇报任务进度,jobtracker由此记录作业的整体进度情况,如果其中一个任务失败,jobtracker会在另一个可用tasktracker上重新调度任务。
hadoop将输入数据分片,为每个分片构建一个Map任务,并由该任务运行用户自定义的Map函数来处理分片中的记录。一个合理的分片大小趋向于HDFS中的块大小,默认为64MB.
Map任务将输出写入本地磁盘,因为输出为中间结果,需要处理后送至Reduce任务。
下图为拥有一个Reduce任务的MapReduce数据流图
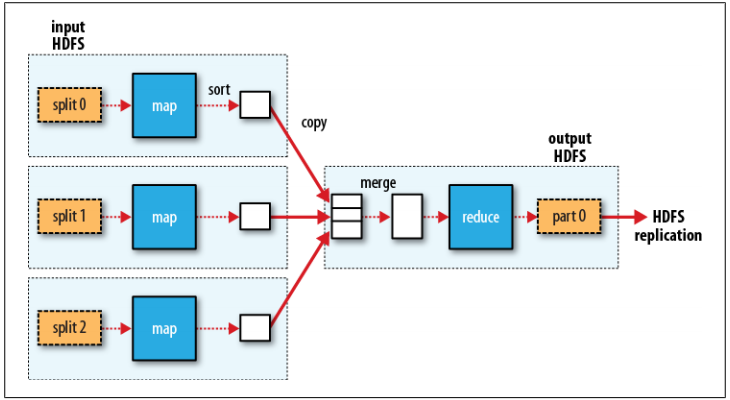
也可以改变Reduce任务的数量,如果有多个Reduce任务,那么Map任务会对其输出进行分区,分区由用户定义的分区函数控制,通常使用默认的分区器使用哈希函数分区。
下图为多个Reduce任务的MapReduce数据流
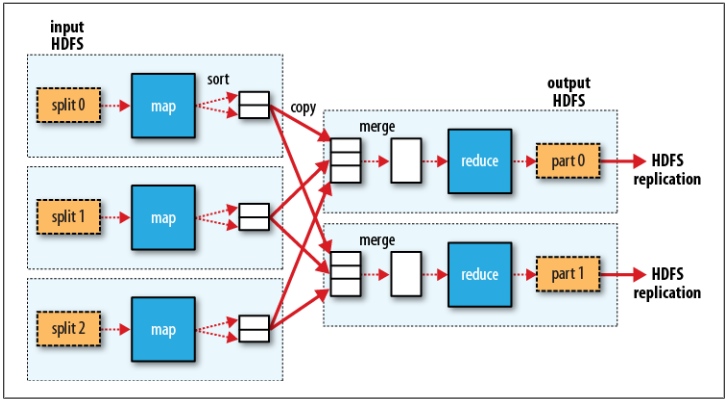
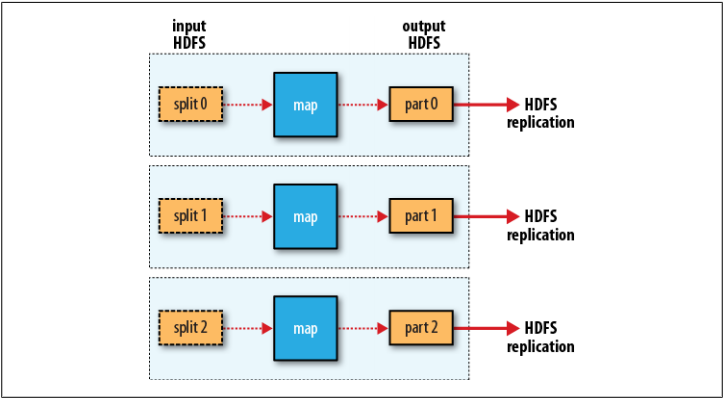
当然也可以没有Reduce任务,如下图:















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









