







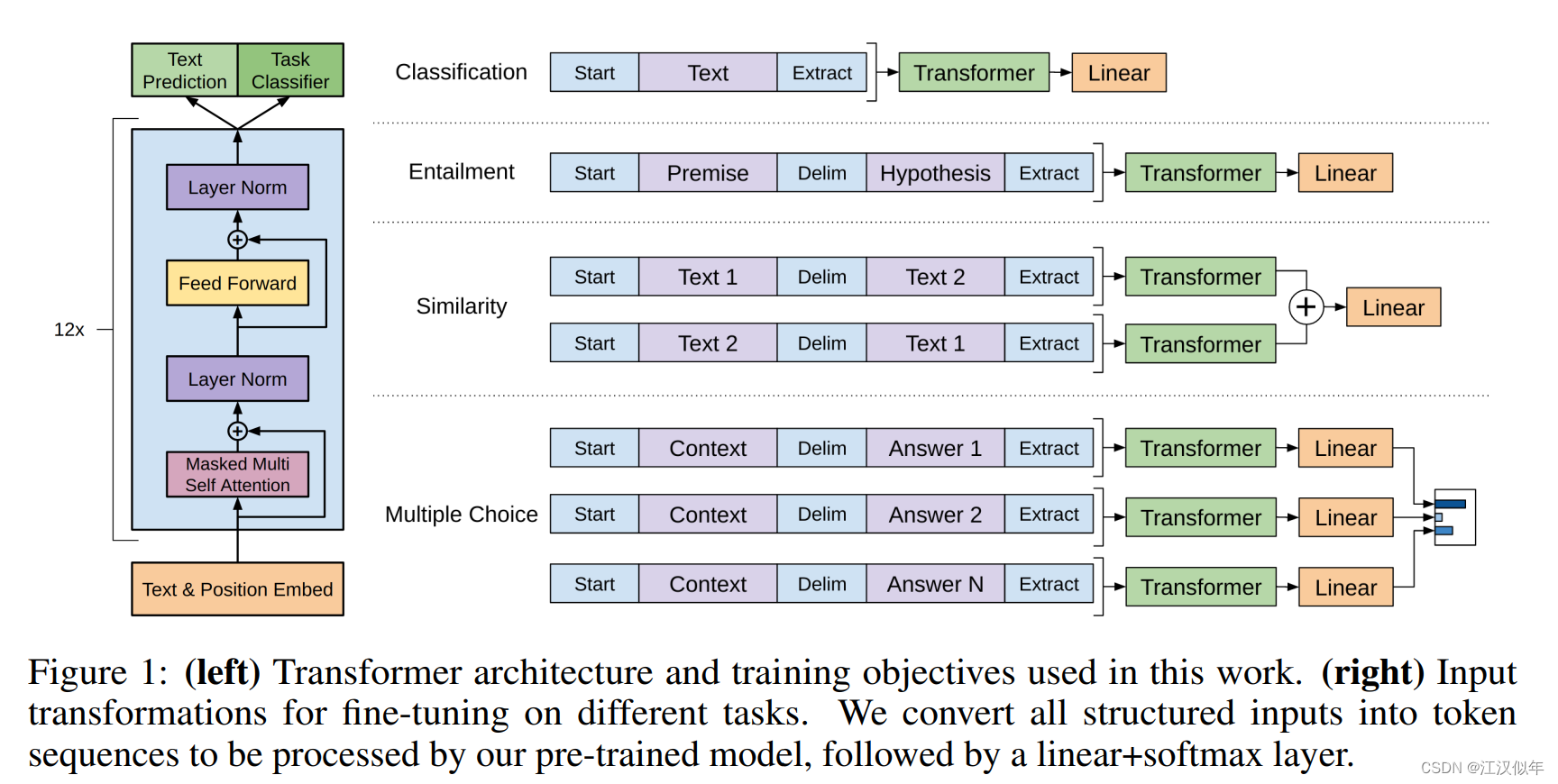
1.GPT1
无监督预训练+有监督的子任务finetuning
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
1.1 Unsupervised pre-training

(1)基于一个transformer decoder,通过一个窗口的输入得到下一个token在目标token上的一个概率分布,其中窗口大小是k
(2)针对一个预料库,不断滑动窗口k,每次最大化下一个token的概率作为loss,相加得到总的loss
1.2 Supervised fine-tuning

(1)将transformer的输出经过一个线性层后,经softmax后得到对目标token的预测结果,最大化预测结果与真值作为loss
(2)同时增加预训练loss作为辅助loss,有助于模型泛化、提升训练速度
2.GPT2
GPT2的主要贡献是:基于GPT1的网络结构,用更大的数据和更多的参数经过无监督预训练的模型在其它下游任务中能得到很好的泛化能力,无需再进行下游任务的finetuning。
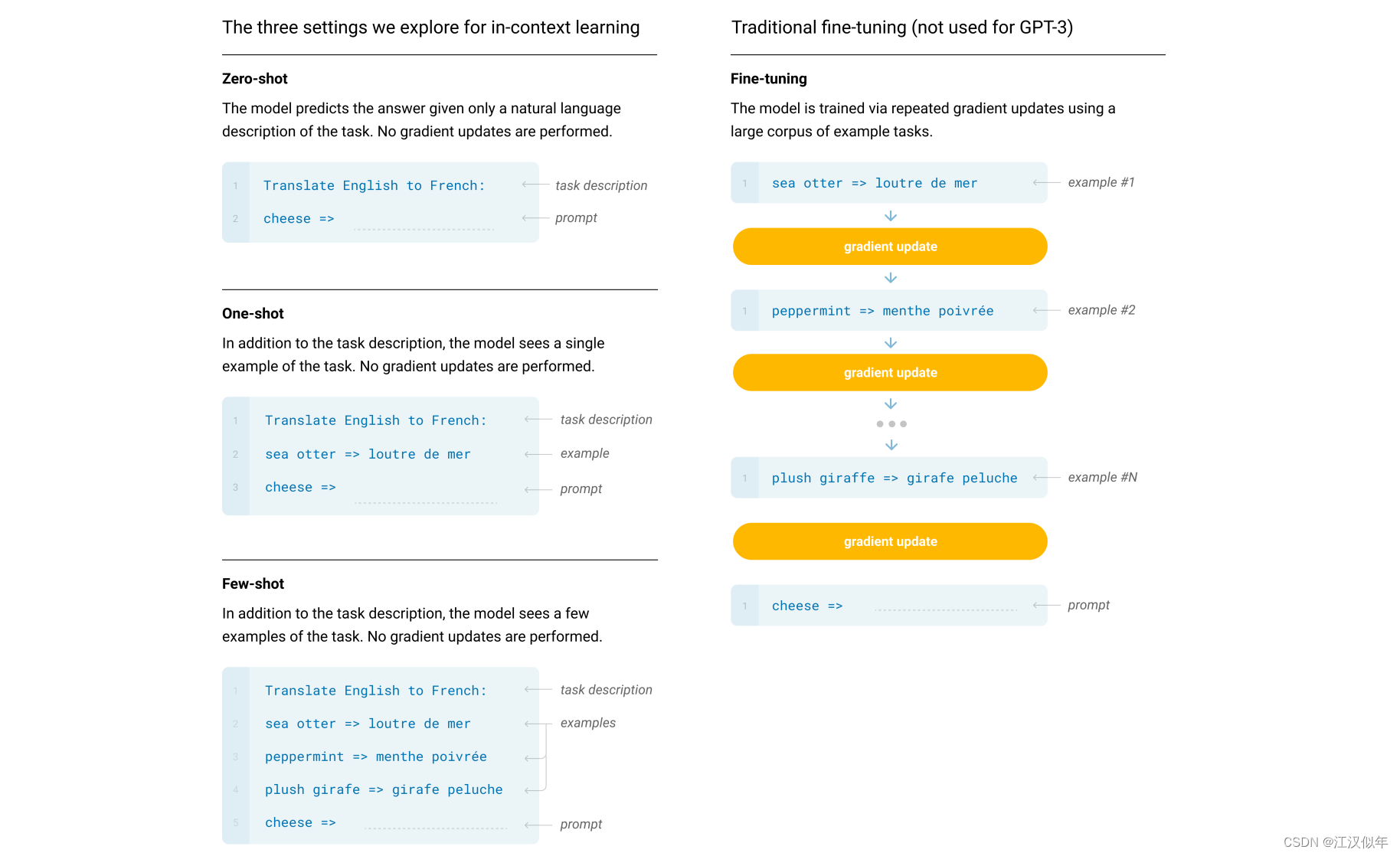
3.GPT3
https://arxiv.org/pdf/2005.14165.pdf
GPT3沿用了GPT2的结构,但是网络容量上做了极大的提升,达到175B的参数:
- GPT-3采用了96层的多头transformer,头的个数为96;
- 词向量的长度是12888 ;
- 上下文划窗的窗口大小提升至2048个token;
- 使用了alternating dense和locally banded sparse attention。
使用不同的promt方法,都不需要改变模型权重

4.InstuctGPT
https://export.arxiv.org/pdf/2203.02155.pdf
指出当前基于互联网数据的LM大模型的objectives与用户需求之前存在misaligned。给出的解决方案是训练的时候增加用户的意图。

FineTuning总共分为三步
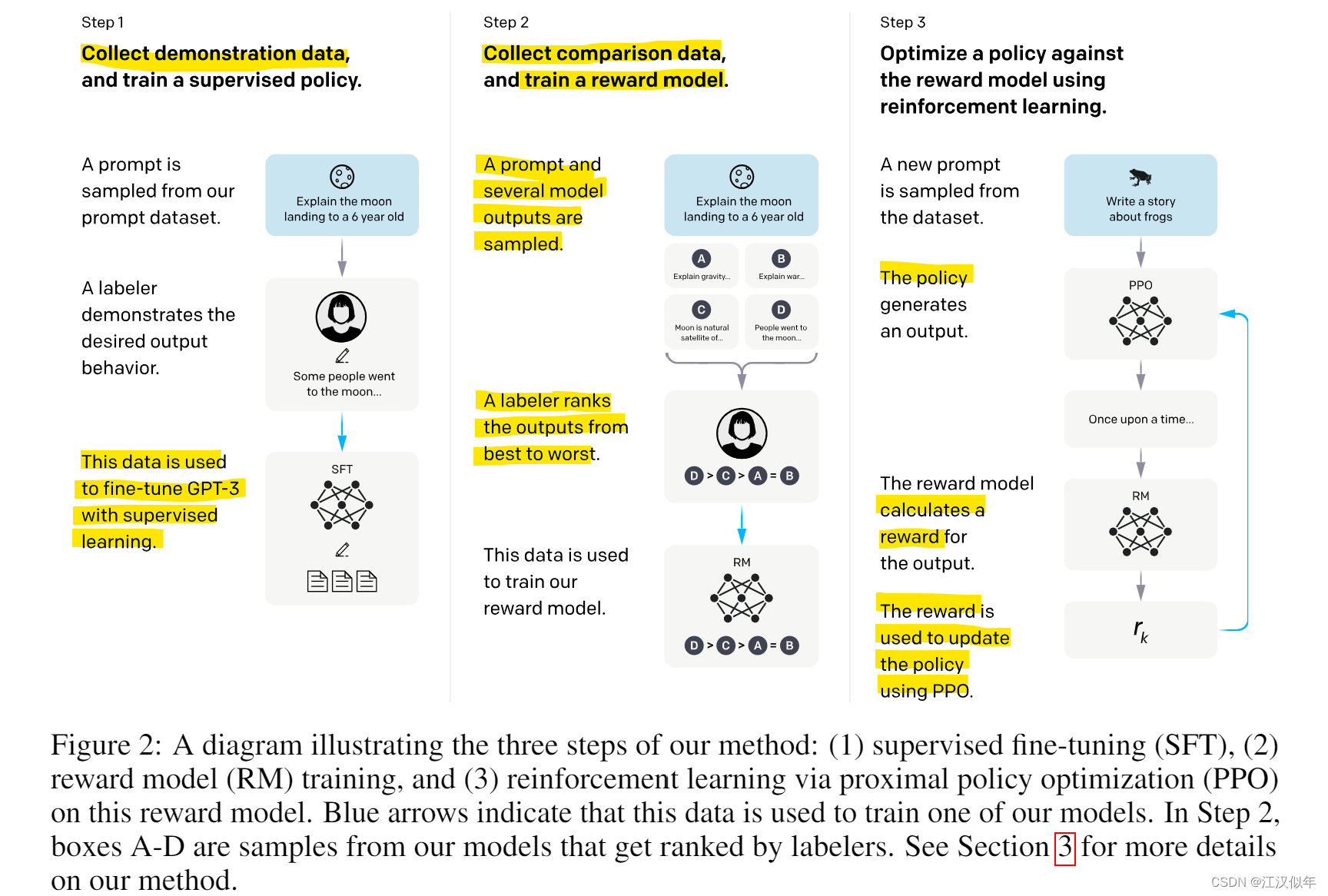
1.第一步:监督学习
从数据集中采样一个prompt,标注员给出对应的标准答案。基于GPT3用这种数据进行有监督的finetune。
2.第二步:训练reward
采样prompt之后,基于第一步的模型获取多个输出结果A\B\C\D。标注员对多个输出进行排序,这个数据用来训练一个reward模型,采用的loss是一个pairwise的ranking loss。细节:
(1)在第一步获得的SFT模型基础上拿掉最后一个umebedding。训练一个模型把prompt和response都作为输入,输出一个标量的reward,这个模型只用了6B大小,太大的化训练不稳定不利于后面RL的步骤。
(2)使用一个交叉熵loss,log概率来表达人类标注员是否更倾向于两个其中的一个。
(3)标注的时候将K个输出中两两组对交给标注员标注哪个更好,这样其实能提高标注效率,因为标注员不需要对K=9的9个答案做全局排序,两两排序更容易,而且可能不容易把顺序标错。(这个其实跟具体标注任务有关,有些任务可能做全局排序更容易)
(4)训练的时候如果把所有标注结果shuffle训练的化会导致over fit,相反这里把一组标注作为一个batch,这样loss就成了一个常用pairwise的ranking loss。

3.第三步,RL finetuning
(1)使用RL来finetune经过step1获得的SFTmodel的参数,方法是PPO
(2)环境设置:随机给定一个prompt后通过SFTmodel得到一个输出,通过step2的reward model可以获得一个reward值,一个episode结束。值函数通过RM来初始化。
(3)将预训练模型的loss与PPOloss用超参加和到一起,可以保留原有SFTmodel在生成任务上的表现,这个loss的计算是在pretrain数据集上完成的。因为第一项RL loss只是是让模型的排序能力更像RW模型,这个排序能力是用人工标注数据训练出来的(其实就是代替传统RL中人工设置的打分规则)。即 PPO-ptx
(4)PPOloss:第一项使得reward最大化,第二项本质是RL与SFT两个模型分布的KL散度,使得两个模型分布尽量接近。

















 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









