






Neural Networks Learning
Visualizing the data
这次试用的数据和上次是一样的数据。5000个training example,每一个代表一个数字的图像,图像是20x20的灰度图,400个像素的每个位置的灰度值组成了一个training example。
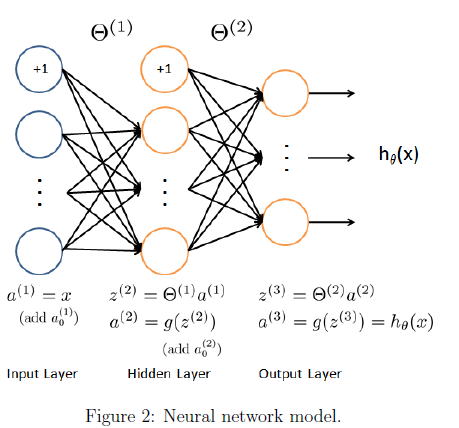
Model representation
这里我们使用如下的模型,共3层,其中第一层input有400个feature,另外还有bias unit。
这个练习中实现训练了一些theta,通过如下的代码把theta1和theta2读取出来
% Load saved matrices from file
load('ex4weights.mat');
% The matrices Theta1 and Theta2 will now be in your workspace
% Theta1 has size 25 x 401
% Theta2 has size 10 x 26Feedforward and cost function
现在我们需要计算cost function和gradient
这里是没有regularization的情况下的cost function公式,m表示m个training example,k表示k个output,这里我们有10个output,分别代表1-10
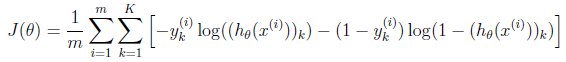
y的值需要从数字形式转化为向量形式,如下,下面的例子中第一列表示1,第二列表示2
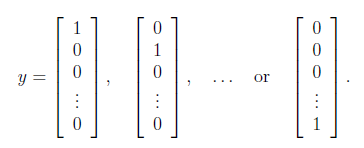
Regularized cost function
下面是regularized cost function,其实就是在普通的cost function后面加上每个theta的平方,当然不要忘了系数。不过这里并不是所有的theta,所有跟bias unit相关的theta都要排除。
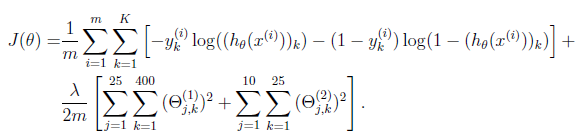
我们现在这里写的程序,指针对3层网络,但是对于由于每层unit数量不一样出现的不同的网络,我们这里也要兼容
function [J grad] = nnCostFunction(nn_params, ...
input_layer_size, ...
hidden_layer_size, ...
num_labels, ...
X, y, lambda)
%NNCOSTFUNCTION Implements the neural network cost function for a two layer
%neural network which performs classification
% [J grad] = NNCOSTFUNCTON(nn_params, hidden_layer_size, num_labels, ...
% X, y, lambda) computes the cost and gradient of the neural network. The
% parameters for the neural network are "unrolled" into the vector
% nn_params and need to be converted back into the weight matrices.
%
% The returned parameter grad should be a "unrolled" vector of the
% partial derivatives of the neural network.
%
% Reshape nn_params back into the parameters Theta1 and Theta2, the weight matrices
% for our 2 layer neural network
Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ...
hidden_layer_size, (input_layer_size + 1));
Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ...
num_labels, (hidden_layer_size + 1));
% Setup some useful variables
m = size(X, 1);
% You need to return the following variables correctly
J = 0;
Theta1_grad = zeros(size(Theta1));
Theta2_grad = zeros(size(Theta2));
% ====================== YOUR CODE HERE ======================
% Instructions: You should complete the code by working through the
% following parts.
%
% Part 1: Feedforward the neural network and return the cost in the
% variable J. After implementing Part 1, you can verify that your
% cost function computation is correct by verifying the cost
% computed in ex4.m
%
% Part 2: Implement the backpropagation algorithm to compute the gradients
% Theta1_grad and Theta2_grad. You should return the partial derivatives of
% the cost function with respect to Theta1 and Theta2 in Theta1_grad and
% Theta2_grad, respectively. After implementing Part 2, you can check
% that your implementation is correct by running checkNNGradients
%
% Note: The vector y passed into the function is a vector of labels
% containing values from 1..K. You need to map this vector into a
% binary vector of 1's and 0's to be used with the neural network
% cost function.
%
% Hint: We recommend implementing backpropagation using a for-loop
% over the training examples if you are implementing it for the
% first time.
%
% Part 3: Implement regularization with the cost function and gradients.
%
% Hint: You can implement this around the code for
% backpropagation. That is, you can compute the gradients for
% the regularization separately and then add them to Theta1_grad
% and Theta2_grad from Part 2.
%
#计算每层的结果,记得要把bias unit加上,第一次写把a1 写成了 [ones(m,1); X];
a1 = [ones(m,1) X];
z2 = Theta1 * a1';
a2 = sigmoid(z2);
a2 = [ones(1,m); a2]; #这里 a2 和 a1 的格式已经不一样了,a1是行排列,a2是列排列
z3 = Theta2 * a2;
a3 = sigmoid(z3);
# 首先把原先label表示的y变成向量模式的output,下面用了循环
y_vect = zeros(num_labels, m);
for i = 1:m,
y_vect(y(i),i) = 1;
end;
#每一training example的cost function是使用的向量计算,然后for loop累加所有m个training example
#的cost function
for i=1:m,
J += sum(-1*y_vect(:,i).*log(a3(:,i))-(1-y_vect(:,i)).*log(1-a3(:,i)));
end;
J = J/m;
#增加regularization,一开始只写了一个sum,但其实theta1 2 分别都是矩阵,一个sum只能按列累加,bias unit的theta不参与regularization
J = J + lambda*(sum(sum(Theta1(:,2:end).^2))+sum(sum(Theta2(:,2:end).^2)))/2/m;
#backward propagation
#Δ的元素个数应该和对应的theta中的元素的个数相同
Delta1 = zeros(size(Theta1));
Delta2 = zeros(size(Theta2));
for i=1:m,
delta3 = a3(:,i) - y_vect(:,i);
#注意这里的δ是不包含bias unit的delta的,毕竟bias unit永远是1,
#不需要计算delta, 下面的2:end,: 过滤掉了bias unit相关值
delta2 = (Theta2'*delta3)(2:end,:).*sigmoidGradient(z2(:,i));
#移除bias unit上的delta2,但是由于上面sigmoidGradient式子中
#的z,本身不包含bias unit,所以下面的过滤不必要,注释掉。
#delta2 = delta2(2:end);
Delta2 += delta3 * a2(:,i)';
#第一层的input是一行一行的,和后面的结构不一样,后面是一列作为一个example
Delta1 += delta2 * a1(i,:);
end;
#总结一下,δ不包含bias unit的偏差值,Δ对跟θ对应的,用来计算每个θ
#后面的偏导数的,所以Δ包含bias unit的θ
Theta2_grad = Delta2/m;
Theta1_grad = Delta1/m;
#regularization gradient
Theta2_grad(:,2:end) = Theta2_grad(:,2:end) .+ lambda * Theta2(:,2:end) / m;
Theta1_grad(:,2:end) = Theta1_grad(:,2:end) .+ lambda * Theta1(:,2:end) / m;
% -------------------------------------------------------------
% =========================================================================
% Unroll gradients
grad = [Theta1_grad(:) ; Theta2_grad(:)];
end
Backpropagation
Sigmoid gradient
sigmoid gradient反向传播计算gradient的公式的一部分
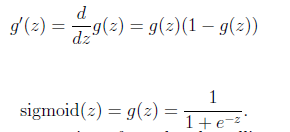
function g = sigmoidGradient(z)
%SIGMOIDGRADIENT returns the gradient of the sigmoid function
%evaluated at z
% g = SIGMOIDGRADIENT(z) computes the gradient of the sigmoid function
% evaluated at z. This should work regardless if z is a matrix or a
% vector. In particular, if z is a vector or matrix, you should return
% the gradient for each element.
g = zeros(size(z));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the gradient of the sigmoid function evaluated at
% each value of z (z can be a matrix, vector or scalar).
g = sigmoid(z).*(1-sigmoid(z));
% =============================================================
endRandom initialization
为了打破symmetry breaking,我们要在选取初始theta的时候,每次选择某一层的theta,然后让每个这一层的theta都随机选取,范围 [-ξ,ξ]
有如下经验公式可用来选择合适的theta范围
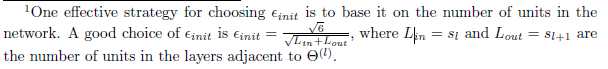
确定了范围之后,下面是随机选择的过程
% Randomly initialize the weights to small values
epsilon init = 0.12;
W = rand(L out, 1 + L in) * 2 * epsilon init − epsilon init;Backpropagation
在反向传播过程中,我们要计算除了input layer之外的每层的小 delta,也就是δ。参考下图,
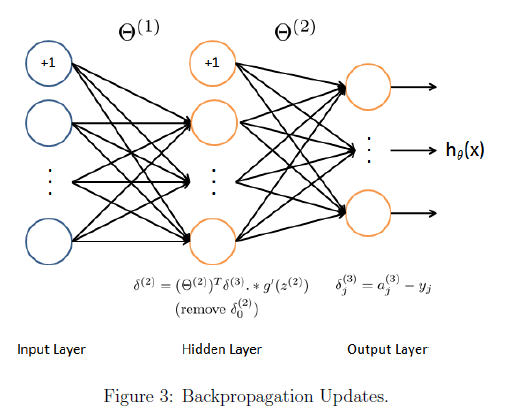
计算过程分为下面5步,每个training example都循环进行1-4:
1 forward propagation计算每一层的函数z,和每一层的activation,不要忘记途中增加bias unit
2 计算第三层的δ,
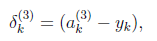
3 计算第二层的δ,
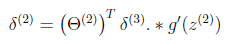
4计算每一层的Δ,这里要搞清楚,δ代表当前层的所有unit个数,如果是hidden layer的话,还包括了bias unit。Δ的最终结果是当前层的theta的偏导数,和当前层的theta维数一致,通过δ计算Δ的时候,由于后层的δ中的bias unit并不是有当前层的theta计算到的,反向计算theta的偏导数,Δ的时候则要把其中的bias unit去掉
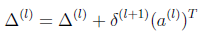
5 上面m个training example都循环计算完成之后,计算最后的偏导数
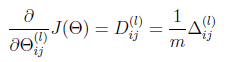
实际上这里的第一步,可以一次性使用矩阵操作计算完成所有m个训练数据的结果,但是后面的几步,还是要循环计算每个训练数据的结果
Gradient checking
这里主要是对我们上面编写的计算偏导数的函数进行验证的一个方法,通过比较上面计算结果和这里计算的估计结果的关系来判断,我们的code是否正确。

这里我们选择ε= 10^−4, 最终我们会看到我们计算的偏导数和估计的偏导数差值应该是 1e-9的数量级。
当然这里计算的时候可以使用比较少的unit的网络,因为这里估计值的计算计算量很大。
function numgrad = computeNumericalGradient(J, theta)
%COMPUTENUMERICALGRADIENT Computes the gradient using "finite differences"
%and gives us a numerical estimate of the gradient.
% numgrad = COMPUTENUMERICALGRADIENT(J, theta) computes the numerical
% gradient of the function J around theta. Calling y = J(theta) should
% return the function value at theta.
% Notes: The following code implements numerical gradient checking, and
% returns the numerical gradient.It sets numgrad(i) to (a numerical
% approximation of) the partial derivative of J with respect to the
% i-th input argument, evaluated at theta. (i.e., numgrad(i) should
% be the (approximately) the partial derivative of J with respect
% to theta(i).)
%
numgrad = zeros(size(theta));
perturb = zeros(size(theta));
e = 1e-4;
for p = 1:numel(theta)
% Set perturbation vector
perturb(p) = e;
loss1 = J(theta - perturb);
loss2 = J(theta + perturb);
% Compute Numerical Gradient
numgrad(p) = (loss2 - loss1) / (2*e);
perturb(p) = 0;
end
endRegularized Neural Networks
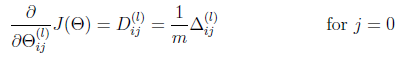

计算的时候,所有和bias项对应的theta都不需要做regularization
Learning parameters using fmincg
略
Visualizing the hidden layer
这里很有意思,我们的input是400个像素点的灰度值,而theta1的每一行都是一个401的vector,去掉第一个,同样得到一个400的vector,然后我们把它可视化出来,可以大概看到我们做了什么

change lambda
不同的λ,会得到不同的结果,怎么选取lambda呢?
%% Machine Learning Online Class - Exercise 4 Neural Network Learning
% Instructions
% ------------
%
% This file contains code that helps you get started on the
% linear exercise. You will need to complete the following functions
% in this exericse:
%
% sigmoidGradient.m
% randInitializeWeights.m
% nnCostFunction.m
%
% For this exercise, you will not need to change any code in this file,
% or any other files other than those mentioned above.
%
%% Initialization
clear ; close all; clc
%% Setup the parameters you will use for this exercise
input_layer_size = 400; % 20x20 Input Images of Digits
hidden_layer_size = 25; % 25 hidden units
num_labels = 10; % 10 labels, from 1 to 10
% (note that we have mapped "0" to label 10)
%% =========== Part 1: Loading and Visualizing Data =============
% We start the exercise by first loading and visualizing the dataset.
% You will be working with a dataset that contains handwritten digits.
%
% Load Training Data
fprintf('Loading and Visualizing Data ...\n')
load('ex4data1.mat');
m = size(X, 1);
% Randomly select 100 data points to display
sel = randperm(size(X, 1));
sel = sel(1:100);
displayData(X(sel, :));
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ================ Part 2: Loading Parameters ================
% In this part of the exercise, we load some pre-initialized
% neural network parameters.
fprintf('\nLoading Saved Neural Network Parameters ...\n')
% Load the weights into variables Theta1 and Theta2
load('ex4weights.mat');
% Unroll parameters
nn_params = [Theta1(:) ; Theta2(:)];
%% ================ Part 3: Compute Cost (Feedforward) ================
% To the neural network, you should first start by implementing the
% feedforward part of the neural network that returns the cost only. You
% should complete the code in nnCostFunction.m to return cost. After
% implementing the feedforward to compute the cost, you can verify that
% your implementation is correct by verifying that you get the same cost
% as us for the fixed debugging parameters.
%
% We suggest implementing the feedforward cost *without* regularization
% first so that it will be easier for you to debug. Later, in part 4, you
% will get to implement the regularized cost.
%
fprintf('\nFeedforward Using Neural Network ...\n')
% Weight regularization parameter (we set this to 0 here).
lambda = 0;
J = nnCostFunction(nn_params, input_layer_size, hidden_layer_size, ...
num_labels, X, y, lambda);
fprintf(['Cost at parameters (loaded from ex4weights): %f '...
'\n(this value should be about 0.287629)\n'], J);
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% =============== Part 4: Implement Regularization ===============
% Once your cost function implementation is correct, you should now
% continue to implement the regularization with the cost.
%
fprintf('\nChecking Cost Function (w/ Regularization) ... \n')
% Weight regularization parameter (we set this to 1 here).
lambda = 1;
J = nnCostFunction(nn_params, input_layer_size, hidden_layer_size, ...
num_labels, X, y, lambda);
fprintf(['Cost at parameters (loaded from ex4weights): %f '...
'\n(this value should be about 0.383770)\n'], J);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ================ Part 5: Sigmoid Gradient ================
% Before you start implementing the neural network, you will first
% implement the gradient for the sigmoid function. You should complete the
% code in the sigmoidGradient.m file.
%
fprintf('\nEvaluating sigmoid gradient...\n')
g = sigmoidGradient([1 -0.5 0 0.5 1]);
fprintf('Sigmoid gradient evaluated at [1 -0.5 0 0.5 1]:\n ');
fprintf('%f ', g);
fprintf('\n\n');
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ================ Part 6: Initializing Pameters ================
% In this part of the exercise, you will be starting to implment a two
% layer neural network that classifies digits. You will start by
% implementing a function to initialize the weights of the neural network
% (randInitializeWeights.m)
fprintf('\nInitializing Neural Network Parameters ...\n')
initial_Theta1 = randInitializeWeights(input_layer_size, hidden_layer_size);
initial_Theta2 = randInitializeWeights(hidden_layer_size, num_labels);
% Unroll parameters
initial_nn_params = [initial_Theta1(:) ; initial_Theta2(:)];
%% =============== Part 7: Implement Backpropagation ===============
% Once your cost matches up with ours, you should proceed to implement the
% backpropagation algorithm for the neural network. You should add to the
% code you've written in nnCostFunction.m to return the partial
% derivatives of the parameters.
%
fprintf('\nChecking Backpropagation... \n');
% Check gradients by running checkNNGradients
checkNNGradients;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% =============== Part 8: Implement Regularization ===============
% Once your backpropagation implementation is correct, you should now
% continue to implement the regularization with the cost and gradient.
%
fprintf('\nChecking Backpropagation (w/ Regularization) ... \n')
% Check gradients by running checkNNGradients
lambda = 3;
checkNNGradients(lambda);
% Also output the costFunction debugging values
debug_J = nnCostFunction(nn_params, input_layer_size, ...
hidden_layer_size, num_labels, X, y, lambda);
fprintf(['\n\nCost at (fixed) debugging parameters (w/ lambda = 10): %f ' ...
'\n(this value should be about 0.576051)\n\n'], debug_J);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =================== Part 8: Training NN ===================
% You have now implemented all the code necessary to train a neural
% network. To train your neural network, we will now use "fmincg", which
% is a function which works similarly to "fminunc". Recall that these
% advanced optimizers are able to train our cost functions efficiently as
% long as we provide them with the gradient computations.
%
fprintf('\nTraining Neural Network... \n')
% After you have completed the assignment, change the MaxIter to a larger
% value to see how more training helps.
options = optimset('MaxIter', 50);
% You should also try different values of lambda
lambda = 1;
% Create "short hand" for the cost function to be minimized
costFunction = @(p) nnCostFunction(p, ...
input_layer_size, ...
hidden_layer_size, ...
num_labels, X, y, lambda);
% Now, costFunction is a function that takes in only one argument (the
% neural network parameters)
[nn_params, cost] = fmincg(costFunction, initial_nn_params, options);
% Obtain Theta1 and Theta2 back from nn_params
Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ...
hidden_layer_size, (input_layer_size + 1));
Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ...
num_labels, (hidden_layer_size + 1));
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ================= Part 9: Visualize Weights =================
% You can now "visualize" what the neural network is learning by
% displaying the hidden units to see what features they are capturing in
% the data.
fprintf('\nVisualizing Neural Network... \n')
displayData(Theta1(:, 2:end));
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% ================= Part 10: Implement Predict =================
% After training the neural network, we would like to use it to predict
% the labels. You will now implement the "predict" function to use the
% neural network to predict the labels of the training set. This lets
% you compute the training set accuracy.
pred = predict(Theta1, Theta2, X);
fprintf('\nTraining Set Accuracy: %f\n', mean(double(pred == y)) * 100);















 2011
2011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









