






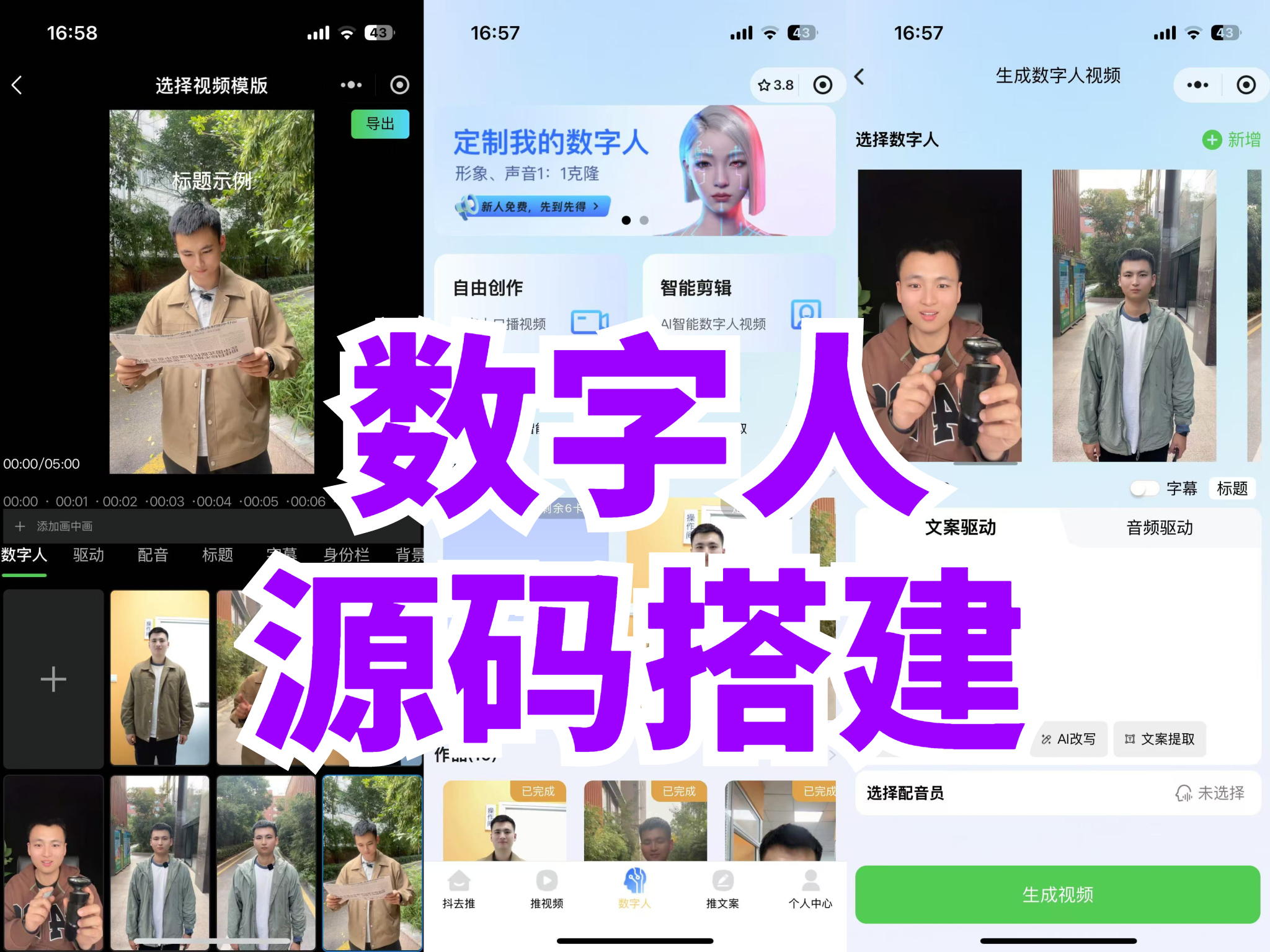
近年来,数字人技术逐渐成为人工智能领域的热点。本文将手把手教你如何搭建一个基础版数字人分身系统的客户端程序,涵盖语音交互、形象渲染、通信模块等核心技术实现。文章提供可复现的代码片段及技术方案。
技术栈与工具准备
-
开发语言: Python 3.8+
-
核心框架: PyQt5(界面)、PyTorch(AI推理)
-
依赖工具:
-
语音处理:VITS(语音合成)、Baidu ASR(语音识别)
-
形象渲染:OpenCV、GStreamer
-
通信协议:WebSocket、HTTP/2
-
-
环境要求:
-
GPU支持(推荐NVIDIA RTX 3060+)
-
CUDA 11.7+ / cuDNN 8.0+
-
环境搭建步骤
1. 安装Python依赖
bash
复制
下载
pip install PyQt5 torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117 pip install opencv-python gstreamer-python python-sounddevice
2. 部署语音合成模型(VITS)
克隆开源仓库并配置:
bash
复制
下载
git clone https://github.com/jaywalnut310/vits.git cd vits && python setup.py install
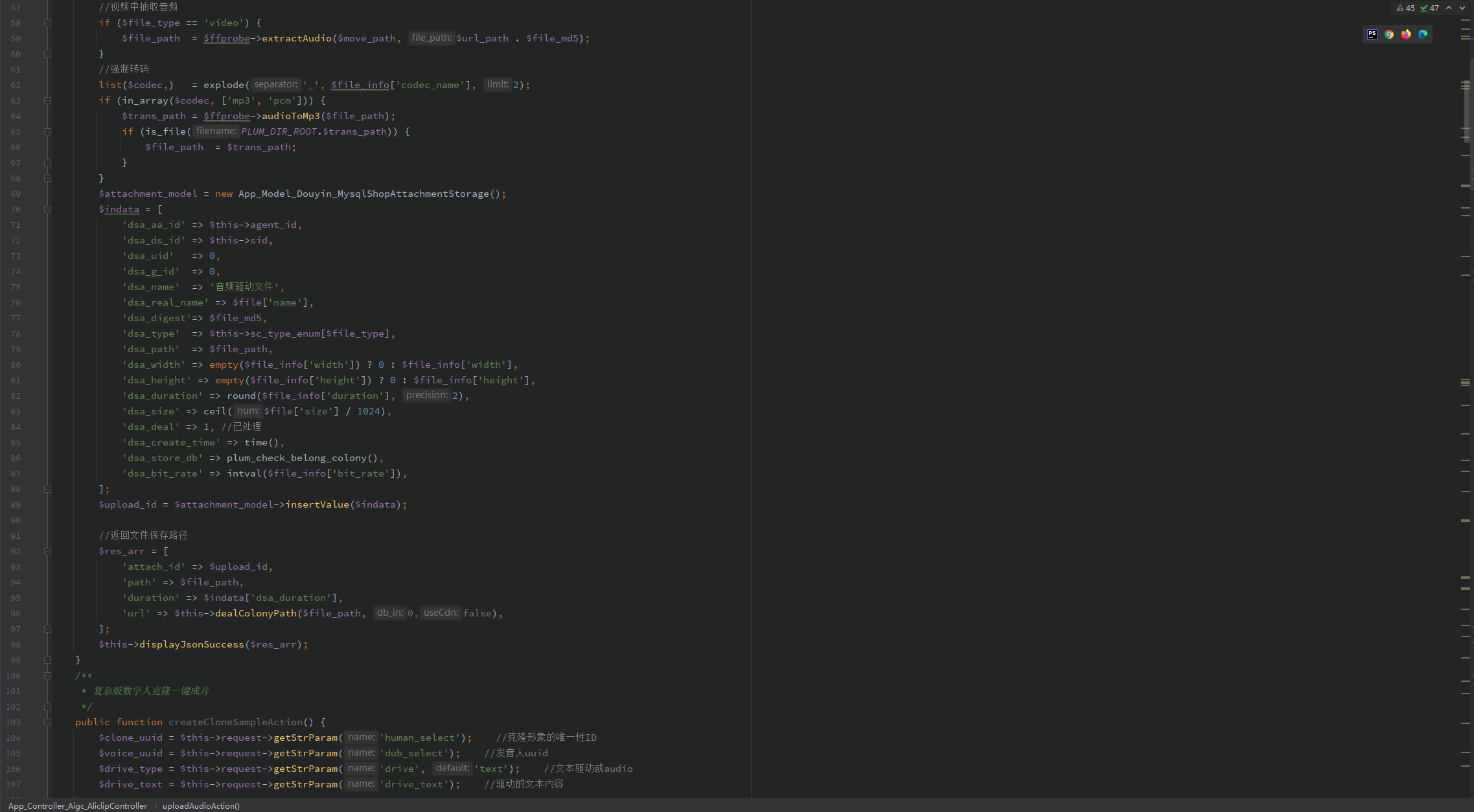
核心模块代码实现
1. 客户端界面(PyQt5)
python
复制
下载
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel
class DigitalHumanUI(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle("数字人分身系统 v1.0")
self.setGeometry(300, 300, 800, 600)
# 视频显示区域
self.video_label = QLabel(self)
self.video_label.setGeometry(50, 50, 704, 396)
# 状态栏
self.statusBar().showMessage('系统就绪')
2. 语音交互模块
python
复制
下载
import sounddevice as sd
import requests
class VoiceInterface:
def __init__(self, api_key):
self.asr_url = "https://vop.baidu.com/pro_api"
self.api_key = api_key
def record_audio(self, duration=5):
# 录制音频
fs = 16000
recording = sd.rec(int(duration * fs), samplerate=fs, channels=1)
sd.wait()
return recording
def speech_to_text(self, audio_data):
# 调用百度语音识别API
headers = {'Content-Type': 'audio/pcm;rate=16000'}
response = requests.post(self.asr_url, data=audio_data.tobytes(), headers=headers)
return response.json()['result'][0]
3. 数字人渲染引擎
python
复制
下载
import cv2
import gstreamer as gs
class AvatarRenderer:
def __init__(self, model_path):
self.pipeline = gs.Pipeline(
f"filesrc location={model_path} ! qtdemux ! h264parse ! nvv4l2decoder ! \
nvvidconv ! video/x-raw,format=BGRx ! videoconvert ! appsink"
)
def update_animation(self, text):
# 驱动口型同步(示例伪代码)
visemes = self.phoenix_model.predict(text)
self.lip_sync(visemes)
def render_frame(self):
success, frame = self.pipeline.read()
if success:
return cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
通信模块集成
python
复制
下载
import websockets
import asyncio
class ClientProtocol:
async def connect_server(self, uri):
self.websocket = await websockets.connect(uri)
async def send_command(self, cmd_type, data):
packet = {
"type": cmd_type,
"data": data,
"timestamp": time.time()
}
await self.websocket.send(json.dumps(packet))
系统整合与测试
python
复制
下载
if __name__ == "__main__":
app = QApplication(sys.argv)
# 初始化模块
ui = DigitalHumanUI()
tts_engine = VITSWrapper("models/ljspeech.pth")
renderer = AvatarRenderer("avatar/rigged_model.fbx")
# 显示界面
ui.show()
# 启动事件循环
sys.exit(app.exec_())
性能优化技巧
-
多线程处理: 使用QThread分离UI渲染与AI推理
-
模型量化: 将PyTorch模型转换为TorchScript格式提升推理速度
-
缓存机制: 对常用语音片段预生成动画序列
常见问题排查
-
CUDA内存不足: 减小批处理大小或使用
torch.cuda.empty_cache() -
音频延迟: 检查GStreamer管道缓冲设置(
latency=0) -
通信断连: 实现WebSocket心跳包机制
结语
本文实现了数字人系统的核心功能模块,开发者可在此基础上扩展以下功能:
-
增加3D模型支持(Unity/Unreal引擎集成)
-
集成情感识别模块
-
实现多模态交互(手势/表情控制)
完整项目源码已上传至GitHub仓库(替换为实际地址),欢迎Star支持!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









