







数仓学习——DolphinScheduler任务调度工具
前言
在数仓项目中,掌握一种任务调度工具是十分重要的,常用的调度工具有Azkaban和oozie,这里学习一种国产的调度工具,DolphinScheduler,综合了两种调度工具的特点而产生的。
一、DolphinScheduler简介
1.DolphinScheduler概述
DolphinScheduler是一个分布式、易扩展的可视化DAG工作流调度平台,致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
2.DolphinScheduler组件
DolphinScheduler主要包含以下几个部分:
1)MasterServer:
采用分布式无中心设计理念。
MasterServer主要负责DAG(工作流)任务切分、任务提交(提交给WorkerServer并分配任务给WorkerServer)、任务监控,并同时监听其它的MasterServer和WorkerServer的健康状态(为了做高可用,容错机制。假如有一个WorkerServer挂掉了,要把它的工作分配给别的WorkerServer;假如有一个MasterServer挂掉了,那么这个MasterServer负责的工作就要交给别的MasterServer去负责,哪个MasterServer抢到它就负责)。
2)WorkerServer:
也采用分布式无中心设计理念。
WorkerServer主要负责任务的执行和提供日志服务。
3)Zookeeeper:
系统中的MasterServer和WorkerServer节点都通过Zookeeper来进行集群管理和容错,zookeeper负责协调整个集群。
4)Alert:
Alert服务,提供告警相关服务(电话、邮件等等)。
5)API接口:
API接口层,主要负责处理前端UI的请求,比如前端要看有哪些任务再执行,执行的进度如何,都要通过API接口调用。
6)UI:
UI是整个系统的前端页面,提供系统的各种可视化操作界面。
3.DolphinScheduler核心架构
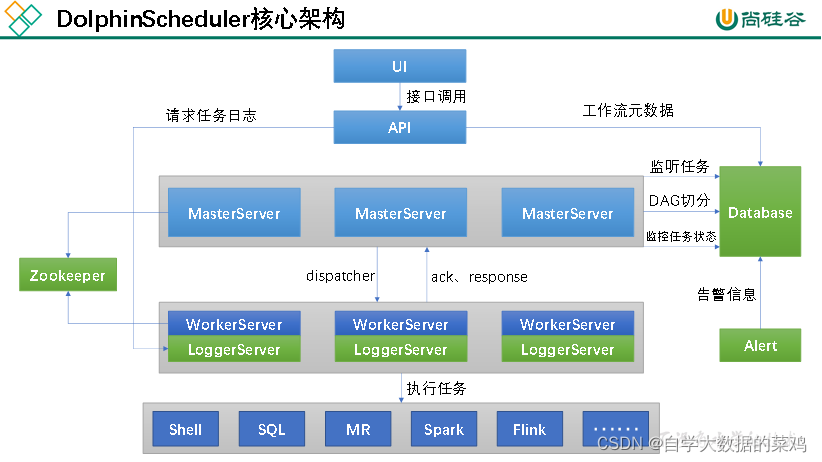
整个流程如下:
1)定义工作流:用户访问UI界面,定义工作流。
2)保存工作流到数据库:定义工作流后要将工作流保存到数据库中,UI无法直接访问数据库,通过调用API接口,将工作流元数据保存到数据库中。
3)工作流切分:保存到数据库后,MasterServer要对工作流进行切分,多个MasterServer之间的地位是平等的,都可以去切分工作流(谁抢到谁去切分),工作流是非共享资源,抢到后需要枷锁,防止别的MasterServer再去抢,这里的锁是分布式锁,靠zookeeper实现。
4)分发任务(工作单元):工作流被切分为任务(工作单元)后,MasterServer将工作单元(任务)分发给WorkerServer(将多个任务分发给多个WorkerServer,WorkerServer间可以并行执行)。WorkerServer在接收到任务后,返回给MasterServer确认信息ack和response,表示已经接收到任务了。
5)执行任务:WorkerServer发送完确认信息后,开始执行任务。
6)执行进度的返回:WorkerServer一边执行任务,一边将执行任务的执行进度返回给MasterServer,MasterServer会把相应任务的执行状态写入到数据库,所以UI界面才可以看到每个任务的执行状况。
组件说明:
1)LoggerServer用来做日志服务,它会把日志信息保存到本地,同时提供一个接口,API Server则可以通过整个接口来查看日志,那么UI可以通过API接口来查看日志。
2)当工作流执行中出现错误时,Alter Server会触发相应的报警通知(打电话、发短信、发邮件(v1.0支持)、企业微信(v1.0支持)…)
二、DolphinScheduler部署说明
1.软硬件环境要求
1.1 操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
1.2 服务器硬件要求
| CPU | 内存 | 网络 |
|---|---|---|
| 4核+ | 8GB+ | 千兆网卡 |
当然,硬件不满足也可以使用,就是运行的时候可能会出现错误。
2.部署模式
DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(Pseudo-Cluster)、集群模式(Cluster)等。
2.1单机模式
单机模式下,所有的服务都集中于一个StandaloneServer进程中,并且在其中内置了注册中心Zookeeper和数据库H2,只需要配置JDK环境,就可以一键启动DolphinScheduler。
一般用于快速体验功能。
2.2 伪集群模式
伪集群模式是在单台机器上部署DolphinScheduler各项服务,该模式下master、worker、api server、logger server等服务都只在同一台机器上。Zookeeper和数据库需单独安装并进行相应配置。
适用于公司中正式上线前的测试集群。
2.3 集群模式
集群模式与伪集群模式的区别就是在多台机器上部署DolohinScheduler各项服务,并且可以配置多个Master及多个Worker。
在这里学习按集群模式学习,调度的时候按单机模式调度,因为配置不够,跑起来容易失败~~~
三、DolphinScheduler集群模式部署
1.集群规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master(不过可能存在单点故障问题),三个Worker,集群规划如下:
| 主机名 | 配置 |
|---|---|
| hadoop102 | master、worker |
| hadoop103 | worker |
| hadoop104 | worker |
2.前置准备工作
1)三个节点均需部署JDK(1.8+),并配置相关环境变量
2)需部署数据库,支持MySQL(5.7+),或者PostgreSQL(8.2.15+)
3)需部署Zookeeper(3.4.6+)
4)三个节点军需安装进程管理工具包psmisc:sudo yum install -y psmisc
3.解压DolphinScheduler安装包
1)上传DolphinScheduler安装包到hadoop102节点的/opt/software目录
2)解压安装包到当前目录(解压目录并非最终的安装目录)
tar -zxvf apache-dolphinscheduler-1.3.9-bin.tar.gz
4.初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
1)创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
2)创建用户
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIF 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









