







字符编码
字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
ASCII
ASCII,American Standard Code for Information Interchange,中文名称美国信息交互标准代码。是由美国相关机构定义的用来表示英文符号(比如A)和一些其他特殊符号(比如$)以及控制符(比如\n,换行符)。这些字符编码用一个字节进行表示,其中只用到了前七位,这7位数据中对应的字符集中包含了26个小写英文字母、26个大写英文字母、10个数字、32个符号、33个控制符、1个空格总计127个代码。
另外多说一些,在早起的ASCII数据传输的时候,剩余没用的那个高位。在标准的ASCII中用来做奇偶校验位。奇偶校验位主要用来进行一定长度上的数据传输正确性的校验
奇偶校验:一般分为两种即奇校验和偶校验。奇校验规定数据中对应的二进制值中的1的数量必须为奇数,如果不是奇数则在最高位添1让整个数据的1的数量为奇数;偶校验同理
ANSI
当信息技术因为互联网的发展,从美国本土走向世界的时候。为了在计算机上显示不同国家当地的文字,方便不同国家的使用。这个时候,上面讨论的ASCII编码就不满足需求了。因为比如中文中光常用字就3500个,这个集合远远大于一个字节可以存储的范围。因此,需要一个更大的字符集来进行表示。
更大的字符集就意味着,每个码值的存储空间需要扩展(这里面先不考虑编码存储的事情)。这个时候考虑到对于ASCII的兼容,依旧使用0x00~0x7F的范围来表示ASCII字符集内的字符。超过这个范围外的字符,用两个字节来表示。这两个字节的范围都是0x80~0xFF。
ANSI码仅在前126个与ASCII码相同。
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在英文Windows操作系统中,ANSI 编码代表 ASCII编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。
GBK和GB2312
GB2312,由中华人民共和国政府制定的,简体汉字编码规范,大陆所有计算机中的简体中文,都使用此种编码格式。与此对应的还有BIG5,是中华民国政府制定的,繁体汉字的编码规范,一般应用于海外计算机的繁体中文显示。所谓的繁体中文Windows,简体中文Windows,指的就是采用BIG5和GB2312编码格式的操作系统。这两种编码方式不兼容,如果使用一种编码的文本阅读器来读另一种编码的文本,就会出现乱码。比如在简体中文Windows上读BIG5编码的文件,就是乱码,反之亦然。使用简体浏览器浏览的时候,到了繁体中文网站,如果不改变码制,也是乱码。
GBK,又称GBK大字符集,简而言之就是将所有亚洲文字的双字节字符,包括简体中文,繁体中文,日语,韩语等,都使用一种格式编码,兼容所有平台的上的语言。GBK大字符集包含的汉字数量比GB2312和BIG5多,使得汉字兼容足够使用。
Unicode
ANSI其实就是ASCII码表加本地化的编码表,本地化的编码表跟区域地点不同编码表不同。比如中国和日本的本地化编码表就是不同的,在进行编码解析的时候,超出ASCII编码表范围的部分,需要采用对应的本地化编码表进行编码。也就是说在进行数据解码的时候,需要用正确的编码表进行解码
这就面临一个问题,两个本地化编码表不同的系统,无法对对方的编码进行有效的解码。这就造成了不同的本地化系统之间进行数据交互的时候比较困难,容易出现乱码的情况
为了解决不同本地化编码表的问题,就引入了Unicode编码。
Unicode码称为万国码、单一码,是将世界上所有国家的字符编码进行统一的编码。Unicode是一个字符集,给所有的字符分配一个码值。这里面只是分配码值,而不是最后的编码实现,编码的实现有很多不同的方式如utf-8、utf-16、utf-32。
在对所有的语言和字符进行一个统一的编码之后,这样不同的本地化字符集之间也可以进行畅通的沟通。目前我们使用的标准ucs-2的unicode的形式进行定义,该形式采用两个字节来存储一个字符,两个字节一共可以存储2^16=65536,65536个字符,可以涵盖大多数语言,也是常用的存储方式(这就是现在绝大多数系统采用16位长度宽wchar数组来对unicode字符串进行存储)。
为了留下其他特别不常用的偏门的字符编码问题,还有一个ucs-4的形式,这种形式是采用4个字节进行存储
上面的unicode在具体的软件内存中,常规情况下是采用2个字节的宽字符来存储unicode来进行存储的。下面我们讨论一下wchar的相关细节
宽字节
在操作系统或者是标准库中,一定看见过或者是用过wchar这个类型(或者是包含这个关键字的类型,在标准库中对应的是std::wstring)。
这个类型是用来存储unicode码的,通过宽字符来直接存储unicode的值。采用这样的存储方式有下面两个问题:
- 由于直接存储的码值,所以在进行解码的时候不需要分析字符流,可以进行解码,这样效率较高
- 直接存储同时也带来了另外一个问题,就是内存空间占用大。比如ascii的码值本来可以使用一个字节进行存储,在这里依然需要采用两个字节进行存储。所以在一些在意数据大小的场景下,一般不采用这种存储方式,采用比如
utf-8的编码实现来进行网路数据传输,这样可以节省网络流量。但是在应用程序本地进行界面显示,可以直接采用unicode进行存储
在C++标准中,并没有规定wchar这个类型的长度,这个长度是由编译器的具体实现。一般情况下编译器的实现都是2个字节的版本,采用的ucs-16的标准。
这里采用2字节进行存储,就可以满足目前的需求,并且使用两字节进行一个字符的存储,可以保证以0为结尾的字符规则依然有效。也就是两个字节对应的值是0的时候判定为字符串的结尾,这样可以兼容以前的窄字节的字符串的相关算法
UTF
UTF,Unicode Transformation Format,中文含义unicode转换格式。从中文名称能看出来,utf就是unicode的一种编码实现。目前
主要有utf-8、utf-16和utf-32这三种,下面我们就对这三种进行探讨。
UTF-8
UTF-8采用可变字节的形式进行编码,使用1到4个字节进行存储。最下编码单元是1个字节,所以对空间的利用高,比较适合网路传输。广泛应用于网络传输比如web采用的就是utf-8对数据进行编码传输
下面,我们看一下utf-8字符编码是如何对unicode的码值进行编码的。如下图所示,UTF-8按照码值的存储大小分为单字节符号存储和多字节存储。
单字节存储,即采用一个字节代表一个码点,采用最高位为0来进行标识。当字符流中,字节的最高位为0的时候,可以代表这个字节中存储了一个码点,后边剩余的7位存储这这个码点对应的码值。单字节符号的存储是兼容ASCII字符集的,这也是utf-8的优点
多字节存储,超出ASCII字符集之外的。需要采用多个字节进行存储。如上图的下半部分所示。在utf-8中可以采用2到4个字节进行码值的存储。以上图中的两个字节存储为例,高位字节的(大端序为例)的高两位存储两个1用来代表这是一个两字节存储,后边跟着一个0用来和后边的数据进行隔开。后边跟着的另外一个低位的字节,前两位以1和0进行开头,用来标识这是后续字节,并且最高位固定为1也可以和单字节存储区分开(单字节存储最高位固定为0)
注意:
使用了unicode编码后,又有新的问题出现。因为unicode编码是用两个字节来存储字符,如果一篇文章中,大部分都是英文,使用unicode编码就会造成空间的浪费,对英文部分使用ASCII码只需要一个字节就可以了。这时候,utf-8解决了这个问题。utf-8是一种可变长的字符编码,当存储英文时只使用一个字节,节省了一半的空间,而存储中文字符时,长度还是不变。utf-8虽然压缩了存储空间,但是如果在内存中存储,使用utf-8却由于它的长度不固定,带来了很大的不便,使得在内存处理字符变得复杂。应对这个问题的解决策略是:在内存中存储字符时还是使用unicode编码,因为unicode编码的长度固定,处理起来很方便。而在文件的存储中,则使用utf-8编码,可以压缩内存,节省空间。这里一般有个自动转换的机制,即从文件中读取utf-8编码到内存时,会自动转换为unicode编码,而从内存中将字符保存到文件时,则自动转换为utf-8编码。
总结:
1.ASCII是ANSI与Unicode的编码基础。
2.ANSI是根据ASCII增加扩展位进行本地化编码的字符集,各个国家和地区有自己的一套编码规则,并不通用。
3.Unicode是为了解决各个地区编码不统一导致乱码的问题,它将世界上所有国家的字符编码进行了统一编码。
tips:
查看本地txt文件内容的编码格式
1.用记事本打开文件,选择另存为
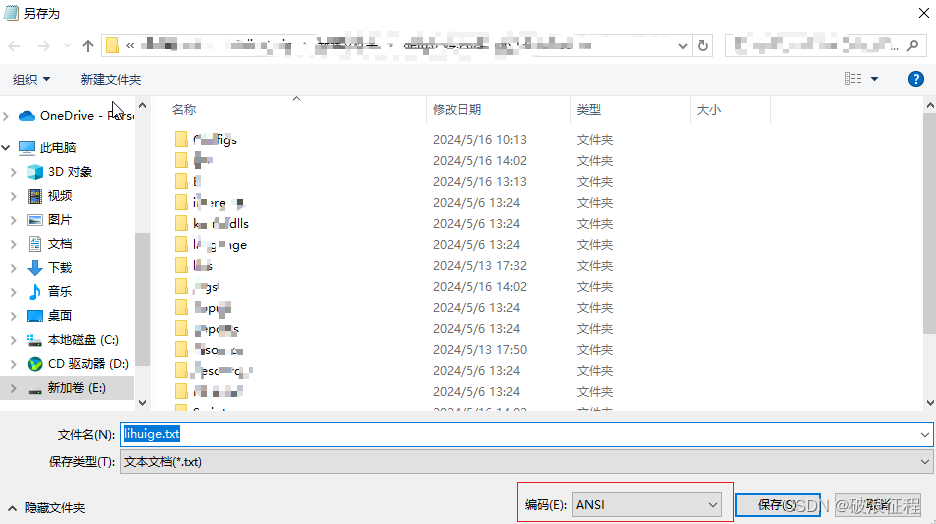
2.在右下角可看到文件的编码格式为ANSI
文章参考:
一篇搞懂Unicode ANSI UTF8等字符编码 - 知乎 (zhihu.com)ANSI和ASCII、GBK和GB2312、Unicode和UTF-8的区别-腾讯云开发者社区-腾讯云 (tencent.com)
















 1252
1252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











