







这周的课程内容涵盖了从经典的卷积神经网络(如AlexNet、VGG-16)的原理与结构,到计算机视觉中常用的基准数据集,再到图像分类、语义分割等主流视觉应用的具体实践和评价方法。希望通过本文的介绍,能为读者构建一个清晰、实用的知识框架。
卷积层尺寸计算
假设输入大小为
(
H
,
W
)
(H,W)
(H,W),卷积核(滤波器)大小为
(
F
H
,
F
W
)
(FH,FW)
(FH,FW),输出大小为
(
O
H
,
O
W
)
(OH,OW)
(OH,OW),填充为
P
P
P,步幅为
S
S
S。此时,输出大小可通过下列式子进行计算。
O
H
=
H
+
2
P
−
F
H
S
+
1
OH=\frac{H+2P-FH}{S}+1
OH=SH+2P−FH+1
O
W
=
W
+
2
P
−
F
W
S
+
1
OW=\frac{W+2P-FW}{S}+1
OW=SW+2P−FW+1
源自《深度学习入门》
VGG-16
VGGNet由牛津大学的视觉几何组(Visual Geometry Group, VGG)和Google DeepMind的研究员在2014年提出。VGGNet在ILSVRC 2014的定位和分类任务中均取得了优异成绩。VGG系列网络(主要是VGG-16和VGG-19)以其简洁和统一的结构著称。
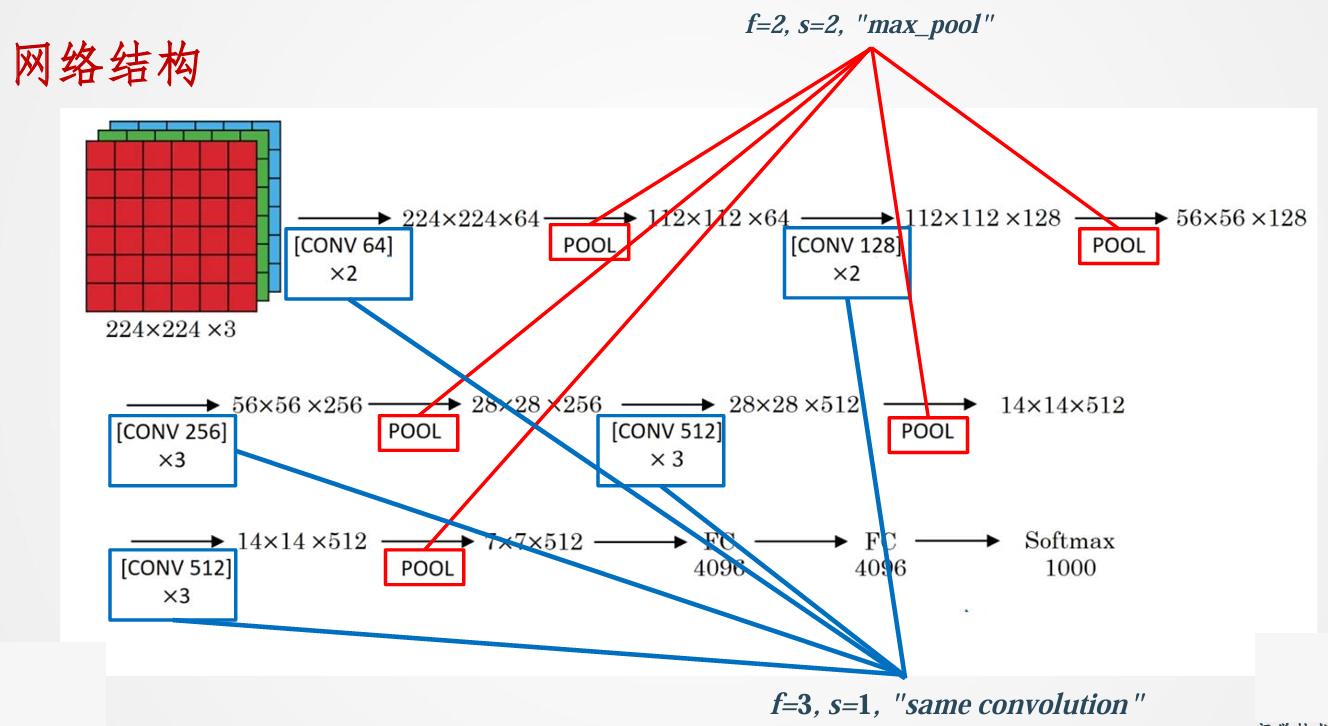
网络结构
VGG-16的“16”指的是网络中包含16个可学习的权重层(13个卷积层和3个全连接层)。其结构如下图所示:
VGG-16的核心思想是采用非常小的(3x3)卷积核,并通过堆叠多个这样的小卷积核来增加网络的深度,从而在有效控制参数数量的同时,提升网络的表达能力。其主要结构特点如下:
- 输入层:接收224x224x3的彩色图像。
- 卷积层:全部使用3x3大小的卷积核,步长为1,padding为1(same padding,保持卷积前后特征图尺寸不变)。
- Block 1: 2个卷积层,64个卷积核。输出特征图大小 224x224x64。
- Block 2: 2个卷积层,128个卷积核。输出特征图大小 112x112x128。
- Block 3: 3个卷积层,256个卷积核。输出特征图大小 56x56x256。
- Block 4: 3个卷积层,512个卷积核。输出特征图大小 28x28x512。
- Block 5: 3个卷积层,512个卷积核。输出特征图大小 14x14x512。
- 池化层:在每个卷积块之后都接一个2x2的最大池化层,步长为2,使得特征图的尺寸减半。
- 全连接层:
- 将最后一个池化层输出的7x7x512特征图展平,连接到一个包含4096个神经元的全连接层。
- 接着连接到另一个包含4096个神经元的全连接层。
- 最后连接到一个包含1000个神经元的全连接层(对应ImageNet的1000个类别),并使用Softmax激活函数输出概率分布。
- 激活函数:所有隐藏层均使用ReLU激活函数。
主要创新点与特点
- 小卷积核的堆叠:VGGNet最大的特点是大量使用3x3的小卷积核。两个串联的3x3卷积层(无padding)的感受野等效于一个5x5的卷积层,而三个串联的3x3卷积层的感受野等效于一个7x7的卷积层。这样做的好处是:
- 增加非线性:相比于使用一个大的卷积核,使用多个小的卷积核可以在参数量相似的情况下引入更多的非线性激活函数,从而增强网络的判别能力。
- 减少参数数量:例如,一个7x7的卷积核(假设输入输出通道数均为C)的参数量是 C × ( 7 × 7 × C ) = 49 C 2 C \times (7 \times 7 \times C) = 49C^2 C×(7×7×C)=49C2。而三个3x3的卷积核的参数量是 3 × C × ( 3 × 3 × C ) = 27 C 2 3 \times C \times (3 \times 3 \times C) = 27C^2 3×C×(3×3×C)=27C2,参数量更少。
- 网络深度:VGGNet通过堆叠小卷积核成功地构建了更深的网络(16层或19层),证明了网络深度对于提升性能的重要性。
- 结构规整统一:VGGNet的结构非常规整,卷积层都采用相同的3x3卷积核和2x2的池化核,使得网络易于理解和实现。这种模块化的设计思想对后续网络的设计产生了深远影响。
- 参数量较大:尽管使用了小卷积核,但由于网络较深且全连接层神经元数量较多,VGG-16的参数量依然很大,约为1.38亿,主要集中在全连接层。这也是VGGNet的一个缺点,导致其计算量和存储开销较大。
- 不使用LRN:与AlexNet不同,VGGNet的研究者发现局部响应归一化(LRN)对性能提升不大,甚至可能带来负面影响,因此在VGGNet中没有使用LRN层。
VGG系列
除了VGG-16,VGG系列还包括VGG-19(16个卷积层和3个全连接层)等不同深度的配置。实验表明,网络深度增加到一定程度后,性能提升会饱和甚至下降(这催生了后续ResNet等解决深度网络训练问题的架构)。
总的来说,VGGNet通过其简洁、统一且深度的设计,进一步推动了卷积神经网络的发展,并为后续更复杂的网络结构奠定了基础。
常用计算机视觉数据集
计算机视觉的进步离不开大规模、高质量的数据集。以下是一些在学术研究和工业应用中广泛使用的经典数据集:
1. MNIST (Modified National Institute of Standards and Technology database)
- 组成与类别:MNIST 数据集包含0到9的手写数字图片及其对应的标签。共有10个类别。
- 规模:包含60,000个训练样本和10,000个测试样本。
- 图像特点:每张图片都是28x28像素的灰度图像。
- 应用场景:常用于入门级的图像分类任务、模型测试和基准比较。由于其简单性和广泛性,是学习和验证新算法的理想选择。
2. Fashion-MNIST
- 提出背景:作为MNIST手写数字数据集的直接替代品,由Zalando的研究部门提供,旨在提供一个比MNIST更具挑战性的基准。
- 组成与类别:包含10个类别的时尚商品正面图片,如T恤/上衣、裤子、套衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包、踝靴。
- 规模与图像特点:与MNIST完全一致,拥有60,000个训练样本和10,000个测试样本,每张图片也是28x28像素的灰度图像。
- 应用场景:同样用于图像分类任务,但比MNIST更难,可以更好地评估机器学习和深度学习算法的性能。
3. CIFAR-10
- 组成与类别:CIFAR-10 数据集包含10个类别的共60,000张32x32像素的彩色图像。每个类别有6,000张图像。
- 类别包括:飞机 (airplane), 汽车 (automobile), 鸟 (bird), 猫 (cat), 鹿 (deer), 狗 (dog), 青蛙 (frog), 马 (horse), 船 (ship), 卡车 (truck)。
- 规模:50,000张训练图像和10,000张测试图像。数据集分为五个训练批次和一个测试批次,每个批次有10,000张图像。
- 应用场景:广泛用于图像分类任务,是评估小型图像识别模型的常用基准。
4. PASCAL VOC (Visual Object Classes)
- 全称:Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes。
- 历史:PASCAL VOC挑战赛从2005年开始,到2012年结束。PASCAL VOC 2007和PASCAL VOC 2012是常用的版本。
- 组成与类别:包含20个对象类别,例如:
- 人 (person)
- 动物 (bird, cat, cow, dog, horse, sheep)
- 交通工具 (aeroplane, bicycle, boat, bus, car, motorbike, train)
- 室内物品 (bottle, chair, dining table, potted plant, sofa, tv/monitor)
- 任务:支持多种计算机视觉任务,包括图像分类、目标检测、图像分割(包括语义分割和实例分割)。
- 标注格式:每张图像对应一个XML文件,详细描述了图像中物体的类别、边界框(bounding box)、姿态、是否被遮挡等信息。
- 应用场景:是目标检测、图像分割等领域的核心基准数据集之一。
5. MS COCO (Microsoft Common Objects in Context)
- 提出背景:由微软于2014年出资标注,旨在推动场景理解的研究。
- 特点:图像主要从复杂的日常场景中截取,包含大量上下文信息,目标物体通常较小且有遮挡。
- 组成与类别:提供80个对象类别的标注,拥有超过33万张图片,其中20万张有标注,个体实例数量超过150万。
- 类别涵盖广泛,如人、交通工具、公路常见物体、动物、携带物品、运动器材、厨房餐具、水果食品、家庭用品等。
- 任务:支持目标检测、图像分割(语义分割、实例分割、全景分割)、图像描述生成、关键点检测等多种任务。
- 影响力:在ImageNet竞赛停办后,COCO竞赛已成为当前目标识别、检测等领域最权威和最重要的标杆之一。
- 官网:http://cocodataset.org
6. ImageNet
- 历史与规模:始于2009年,由李飞飞教授团队创建。是一个大规模的层级式图像数据库。总共包含超过1400万张图像,覆盖超过2万个类别。其中,带有边界框标注的图像超过100万张。
- ILSVRC (ImageNet Large Scale Visual Recognition Challenge):基于ImageNet数据集举办的年度竞赛,极大地推动了深度学习在计算机视觉领域的发展。竞赛通常使用ImageNet的一个子集,包含1000个类别,约120万张训练图像,5万张验证图像和10万张测试图像。
- ImageNet-21K Pretraining:指使用ImageNet完整数据集中约1400万张图片和21,000个类别进行预训练。
- 应用场景:是图像分类、目标检测、迁移学习等任务中最重要的基准数据集和预训练数据源之一。在ImageNet上预训练的模型通常作为许多其他视觉任务的骨干网络。
7. JFT-300M
- 来源:谷歌内部使用的一个大规模图像数据集,用于训练图像分类模型。
- 规模:包含约3亿张图像,产生了超过10亿个标签(一张图像可以有多个标签)。其中约3.75亿个标签是通过算法选择以最大化标签精度。
- 特点:规模巨大,标签可能存在噪声,但其庞大的数据量对于训练超大规模模型和探索弱监督学习、自监督学习等前沿方向具有重要意义。
- 应用场景:主要用于谷歌内部的研究和模型训练,推动了超大规模视觉模型的进展。
这些数据集各有侧重,覆盖了从简单的数字识别到复杂的场景理解等多种视觉任务,为计算机视觉算法的开发和评估提供了宝贵的资源。
深度学习视觉应用概述
深度学习在计算机视觉领域取得了巨大成功,催生了众多影响深远的应用。这些应用旨在让计算机能够像人类一样“看懂”图像和视频,并从中提取有用的信息。以下是一些主流的视觉应用方向(不包括YOLO和传统意义上的目标检测):
1. 图像分类 (Image Classification)
图像分类是最基础也是最核心的计算机视觉任务之一。其目标是根据图像的内容,将其分配给一个或多个预定义的类别。
- 定义:给定一张输入图像,图像分类模型输出该图像属于各个类别的概率。通常选择概率最高的类别作为最终的分类结果。
- 典型网络:如前所述的AlexNet、VGGNet,以及后续的GoogLeNet, ResNet, DenseNet, MobileNet, EfficientNet等都是为图像分类任务设计的经典网络结构。
- 应用场景:
- 物体识别:识别图像中的主要物体是什么,例如猫、狗、汽车、飞机等。
- 场景识别:判断图像所描绘的场景类型,如海滩、森林、街道、室内等。
- 图像内容检索:根据图像内容对大规模图像库进行分类和索引,方便用户检索相似图像。
- 医学影像分析:辅助医生对医学影像(如X光片、CT扫描)进行分类,判断是否存在病变。
- 产品分类:在电商领域,自动对商品图片进行分类。
2. 语义分割 (Semantic Segmentation)
语义分割的目标是对图像中的每个像素进行分类,将其分配给其所属的物体类别。与图像分类不同,语义分割不仅要知道图像中有什么,还要知道它们在图像中的精确位置(像素级别)。
- 定义:为图像中的每个像素分配一个类别标签。输出结果通常是一张与原图同样大小的分割图,其中不同颜色代表不同的物体类别。
- 关键挑战:如何在保持高层语义信息的同时,恢复像素级别的空间细节。
- 典型网络与方法:
- 全卷积网络 (Fully Convolutional Network, FCN):FCN是语义分割领域的开创性工作。它将传统CNN末尾的全连接层替换为卷积层,使得网络可以接受任意尺寸的输入图像,并输出与输入同样大小的像素级预测图。FCN通过上采样(如反卷积或双线性插值)来恢复特征图的分辨率。
- U-Net:U-Net及其变种在医学图像分割领域取得了巨大成功。其特点是拥有一个对称的编码器-解码器结构,编码器用于提取特征,解码器用于逐步恢复空间分辨率。编码器和解码器之间通过跳跃连接(skip connections)来融合不同层级的特征,有助于保留细节信息。
- DeepLab系列 (如 DeepLab v3, DeepLab v3+):DeepLab系列引入了空洞卷积(Atrous Convolution / Dilated Convolution)来扩大感受野而不增加参数量或降低分辨率,并结合了条件随机场(CRF)或空洞空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)来捕获多尺度上下文信息,是目前广泛使用的语义分割方法。
- 应用场景:
- 自动驾驶:识别道路、车辆、行人、交通标志等,为车辆提供环境感知。
- 医学影像分析:精确分割器官、肿瘤、病变区域,辅助诊断和手术规划。
- 遥感图像分析:土地覆盖分类、建筑物提取、道路提取等。
- 机器人视觉:帮助机器人理解场景,进行导航和交互。
- 图像编辑:例如背景替换、虚拟试衣等。
3. 实例分割 (Instance Segmentation)
实例分割比语义分割更进一步,它不仅需要对每个像素进行分类,还需要区分同一类别的不同实例。
- 定义:在语义分割的基础上,区分开图像中同一物体的不同个体。例如,如果图像中有三只猫,实例分割需要将这三只猫分别标记出来。
- 典型网络与方法:
- Mask R-CNN:是实例分割领域的代表性工作,它在Faster R-CNN目标检测框架的基础上,增加了一个并行的分支来预测每个候选区域(Region of Interest, RoI)的分割掩码(mask)。
- 应用场景:
- 自动驾驶:更精细地识别和跟踪每个独立的车辆和行人。
- 机器人抓取:精确识别和定位需要抓取的物体实例。
- 生物医学图像分析:例如细胞计数和形态分析。
4. 关键点检测 (Keypoint Detection) / 人体姿态估计 (Human Pose Estimation)
关键点检测的目标是定位图像中物体的特定关键点,例如人脸的眼睛、鼻子、嘴巴角点,或者人体的关节点(如头部、肩膀、肘部、手腕等)。
- 定义:预测图像中预定义关键点的二维坐标(有时也包括三维坐标和可见性)。
- 典型网络与方法:
- Hourglass Network:采用堆叠的沙漏形模块,通过反复的下采样和上采样来捕获多尺度特征,并进行端到端的关键点预测。
- OpenPose:一个流行的开源实时多人姿态估计库,它使用部分亲和字段(Part Affinity Fields, PAFs)来关联检测到的身体部位,从而形成完整的人体姿态。
- HRNet (High-Resolution Network):在整个过程中保持高分辨率特征图,并通过并行连接多分辨率子网并进行特征融合,从而获得精确的关键点定位。
- 应用场景:
- 人机交互:通过姿态识别理解用户意图。
- 运动分析:分析运动员的动作姿态,进行技术改进。
- 虚拟现实/增强现实 (VR/AR):驱动虚拟角色的动作,增强沉浸感。
- 安防监控:异常行为检测。
- 动画与游戏:角色动作捕捉。
评价指标回顾
在评估这些视觉应用模型的性能时,会用到一些常见的评价指标,如之前在数据集中提到的:
- 精确率 (Precision):在所有被模型预测为正例的样本中,真正为正例的比例。公式为: P = T P / ( T P + F P ) P = TP / (TP + FP) P=TP/(TP+FP)。
- 召回率 (Recall):在所有实际为正例的样本中,被模型成功预测为正例的比例。公式为: R = T P / ( T P + F N ) R = TP / (TP + FN) R=TP/(TP+FN)。
- 准确率 (Accuracy):被正确分类的样本数占总样本数的比例。公式为: A c c u r a c y = ( T P + T N ) / ( T P + F P + T N + F N ) Accuracy = (TP + TN) / (TP + FP + TN + FN) Accuracy=(TP+TN)/(TP+FP+TN+FN)。
- P-R曲线 (Precision-Recall Curve):以召回率为横轴,精确率为纵轴绘制的曲线,用于综合评估模型在不同阈值下的性能。
- 平均精度 (Average Precision, AP):P-R曲线下的面积,是衡量单一类别检测或分割性能的常用指标。
- 平均精度均值 (mean Average Precision, mAP):对所有类别的AP值取平均,是衡量多类别检测或分割模型整体性能的核心指标。
这些视觉应用方向相互关联,并且随着深度学习技术的发展不断涌现出新的方法和应用场景。它们共同构成了现代计算机视觉的核心内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









