




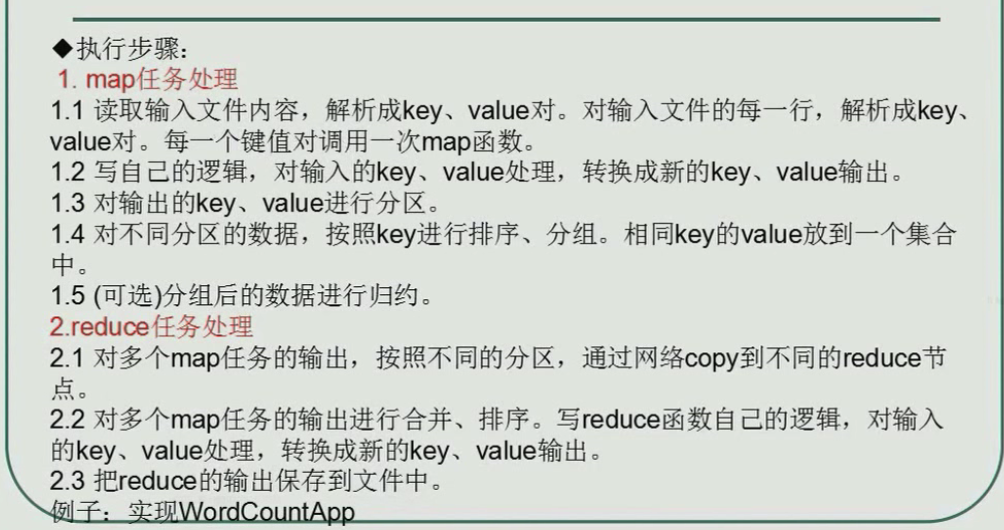
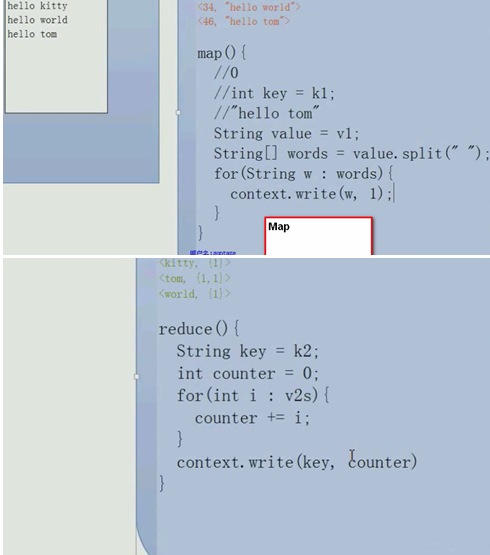
一行数据解析为一个key-value,每个key-value调用一次map方法。
启动HDFS、启动YARM(MapReduce运行在YARM上)
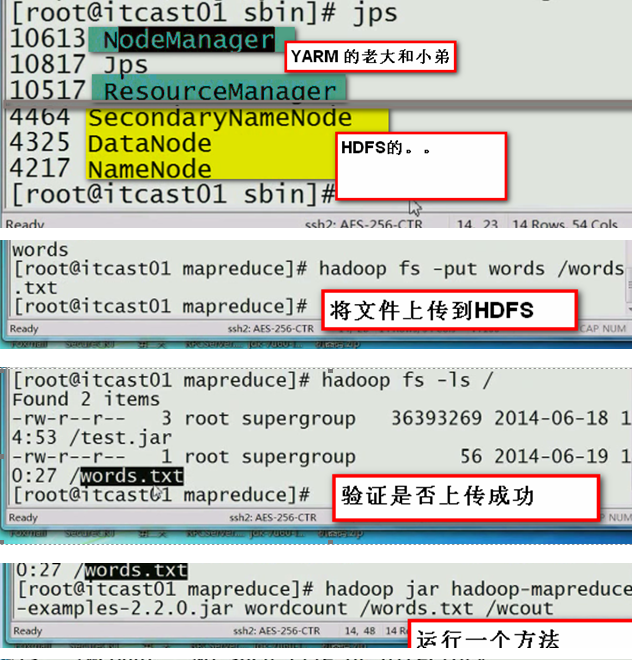
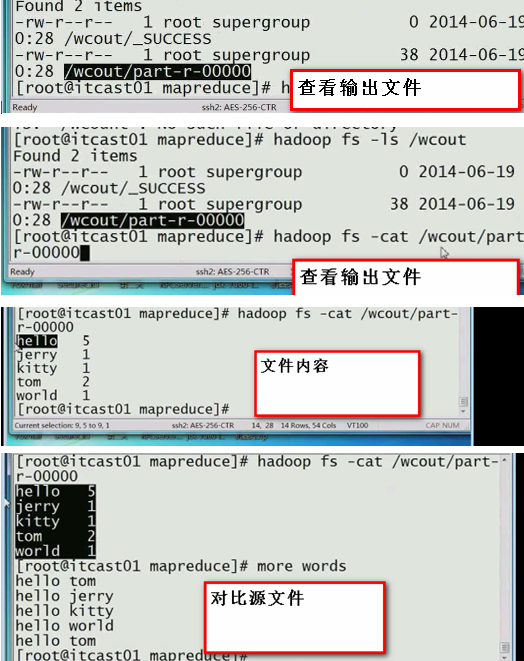
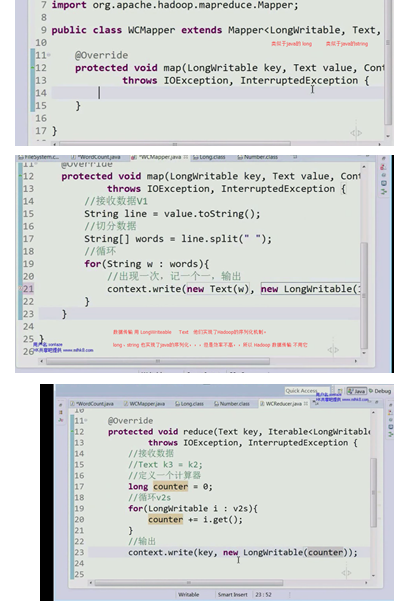
边解析,边运行:
—并不是把文件内容全加载到内存再执行Map,,,是一边加载,,一边Map
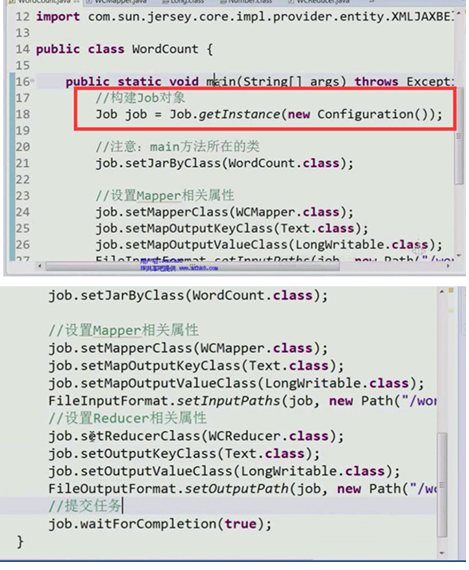

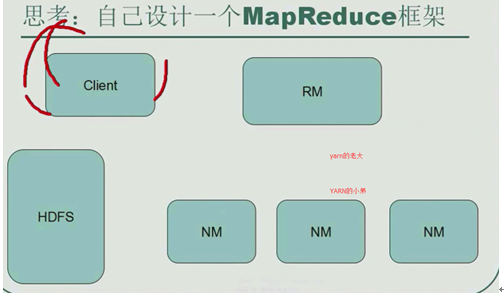
- client向RM发送一个RPC请求(client告诉RM他要提交一个作业)
- RM返回给client一个JobId和一个存放jar包的路径
- client将 路径作为前缀,JobId作为后缀,拼接起来,作为唯一存放这个jar包的路径。
- client持有filesystem对象。将jar包写入到HDFS(由于HDFS是一个分布式文件系统,所以压力不会很大,HDFS将jar存为10份,分布在不同的机器上。程序运行结束会把jar包删除)
- 到此为止。Jar包存放到了HDFS上。Client上有jar包的存放位置的信息。(jobid和路径)
- Client通过RPC将jobid和路径提交给RM。
- RM中保存的是这个作业的描述信息。RM将这个信息放到他的调度器(是一个队列)里面。
- 小弟通过心跳机制来领取任务。心跳机制:小弟每隔一段时间将自己的情况汇报给老大,并且向老大申请任务,老大来决定是不是将这个任务分配给你。如果你很忙了,老大就不会让你干更多的活。如果你不忙,老大将任务给你。
- 小弟领到任务后,来HDFS领取jar,下载好jar之后,NM来启动相应的子进程来运行MR。这个进程独立于NM。这个进程运行Map或Reduce。运行需要读取HDFS中的数据,读取后写回HDFS。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









