







Python+Selenium实现列表数据的翻页获取
涉及到的定位元素
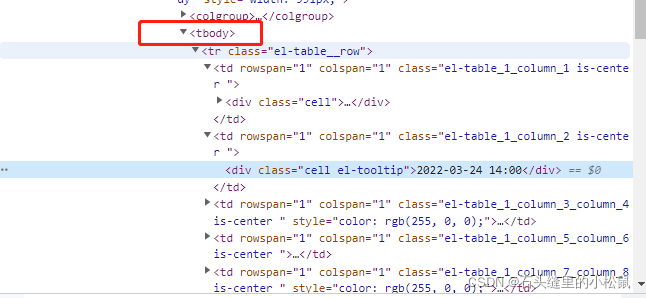
1、列表表格tbody
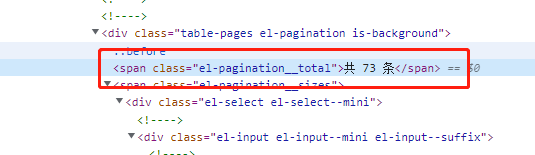
2、列表总数据元素
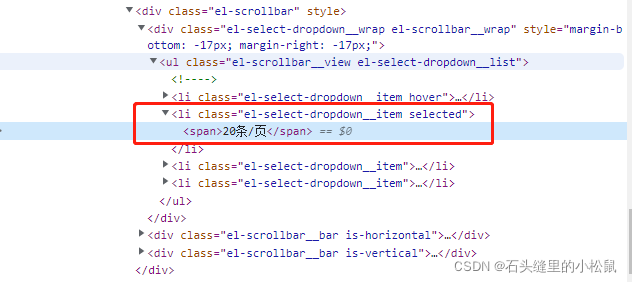
3、分页数据元素
4、下一页图标/按钮元素
# while循环获取列表页面全部数据
def get_list_all_datas(self, table_tbody, total_num_loc, pagination, pagination_selected, next_page, doc=''):
"""
参数说明
:param table_tbody: 列表表格的tbody元素定位
:param total_num_loc: 列表总数据元素定位
:param pagination: 分页框元素定位
:param pagination_selected: 分页数据元素定位(例如:X 页/条)
:param next_page: 下一页图标元素定位
:param doc:
:return:
"""
time.sleep(1)
# 设置初始化列表:空列表存储获取到的数据
list_1 = []
# 定位表格路径
element = self.driver.find_element(By.XPATH, table_tbody)
element_total_num = self.get_element_text(total_num_loc, doc="获取列表总数据")
self.click(pagination, doc="点击分页弹框")
time.sleep(0.5)
element_pagination = self.get_element_text(pagination_selected, doc="获取页码分页")
self.click(pagination, doc="点击分页弹框")
# 正则表达式取字符串中的数字类型数据
# num_1 列表总数据
num_1 = int(re.findall(r"\d+\.?\d*", element_total_num)[0])
# num_2 分页显示数据
num_2 = int(re.findall(r"\d+\.?\d*", element_pagination)[0])
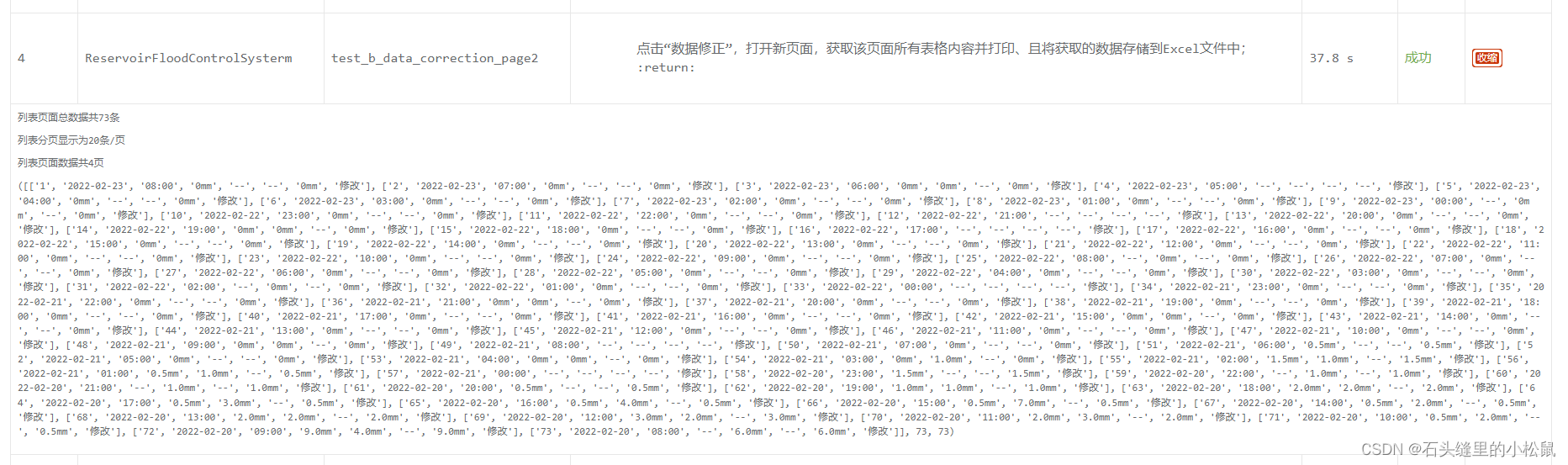
print("列表页面总数据共{}条".format(num_1))
print("列表分页显示为{}条/页".format(num_2))
# 通过计算判断列表页面的页码总数
if num_1 <= num_2:
ret_page = 1
print("列表页面数据共{}页".format(ret_page))
else:
ret_page = (num_1 // num_2) + 1
print("列表页面数据共{}页".format(ret_page))
# while循环翻页获取每页列表的数据
i = 1
while i <= ret_page:
# 获取每一行数据tr
table_tr_list = element.find_elements(By.TAG_NAME, "tr")
# 按行查询表格的数据,取出的数据是一整行
for tr in table_tr_list:
# tr.text获取表格每行的文本内容、切割字符串
# list_2 = (tr.text).split()
list_2 = tr.get_attribute('innerText').replace("\n\t\n", ",").replace("\t\n", " ,")
list_1.append(list_2)
time.sleep(1)
self.click(next_page, doc="点击下一页图标")
time.sleep(1)
i += 1
# 计算获取到的列表长度,方便断言时数据是否与总列表数据一致
# 返回值包含:列表、列表长度、列表页面总数据值
if list_1 != []:
ret_info1 = list_1
ret_info2 = len(list_1)
return ret_info1, ret_info2, num_1
else:
ret_info1 = "列表数据为空,列表数为0"
ret_info2 = 0
return ret_info1, ret_info2, num_1
测试报告显示示例















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









