






1、好处:
我们做的东西,对于使用者来说,使用越简单越好,让用户去pycharm流程不现实,而且还要安装各种环境和库,对于非技术背景的用户非常不友好,于是就做成了exe应用程序的形式,让他们自己也能更加方便的使用。
2、打包工具:
PyInstaller:PyInstaller是一个流行的打包工具,可以将Python应用程序打包成独立的可执行文件,可以在不同的操作系统上运行。它可以将所有依赖项打包到一个文件中,并提供了简单的命令行界面来进行打包。
3、打包方法:
在项目根目录下输入命令 :
pyinstaller -F -w 文件名.py (文件名根据自己项目名字修改)
4、具体打包过程:
参考博客:https://blog.csdn.net/yuuuuu000/article/details/132793036?spm=1001.2014.3001.5502
5、打包过程可能出现的问题:
1、有些库打包不了,会导致程序运行错误:
pytesseract库:
依赖Tesseract OCR,Tesseract OCR是一个开源的OCR(Optical Character Recognition)引擎,能够将图像中的文字进行识别
解决方法:
1、把Tesseract-OCR下载之后放到项目文件夹中
2、在pytesseract中的pytesseract.py(与Tesseract OCR引擎进行交互的接口)修改Tesseract OCR的路径(为当前文件夹下Tesseract OCR的路径)

pdf2image库:
依赖于Poppler工具包(Poppler是一个开源的PDF渲染库,它包含了用于处理PDF文件的一些工具和组件,如渲染引擎、文本提取、页码转换等)
解决方法:
1.安装poppler之后放到项目文件夹中
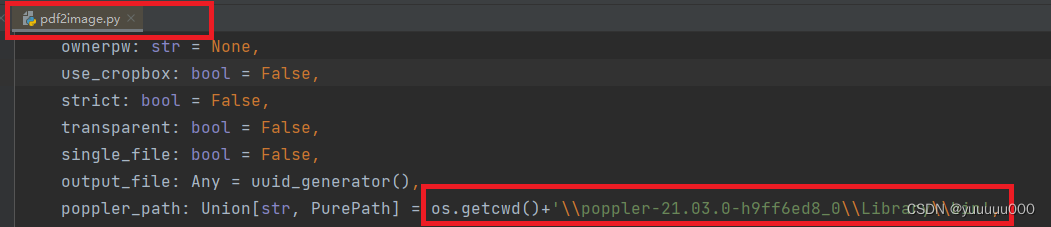
2.设定poppler_path参数:
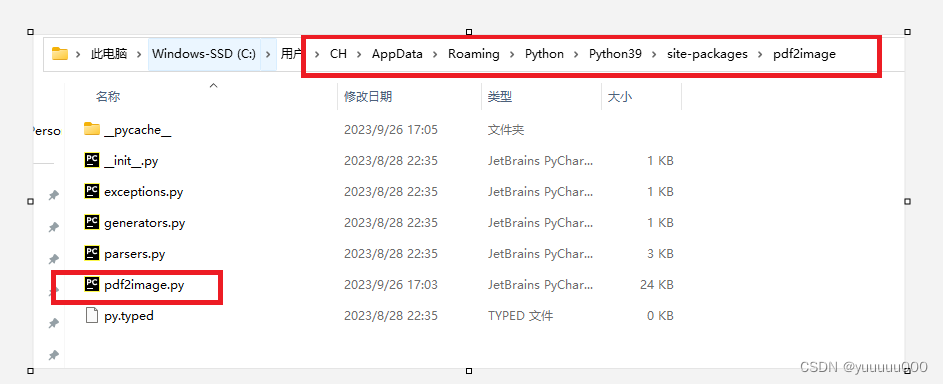
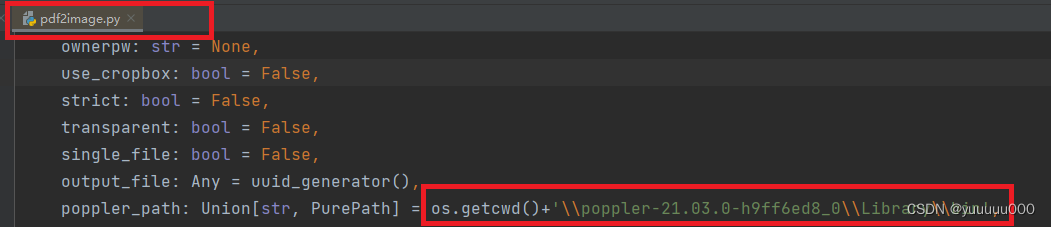
(1)在安装的pdf2image库文件路径下找到pdf2image.py
如何快速找到python库的安装路径:
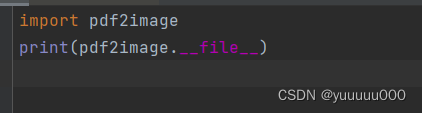
![]()
(2)修改pdf2image.py文件中convert_from_path函数poppler_path参数的值为poppler的安装路径
2、有些文件打包不了:
由于找不到libcurl.dll,无法继续执行代码,重新安装程序可能会解决此问题
pdfinfo.exe-系统错误
1.解决方法:
找到libcurl.dll文件,并将其复制到pdfinfo.exe所在的目录或系统目录中。
在自己电脑搜索libcurl.dll,找到之后复制到pdfinfo.exe所在的目录或系统目录中

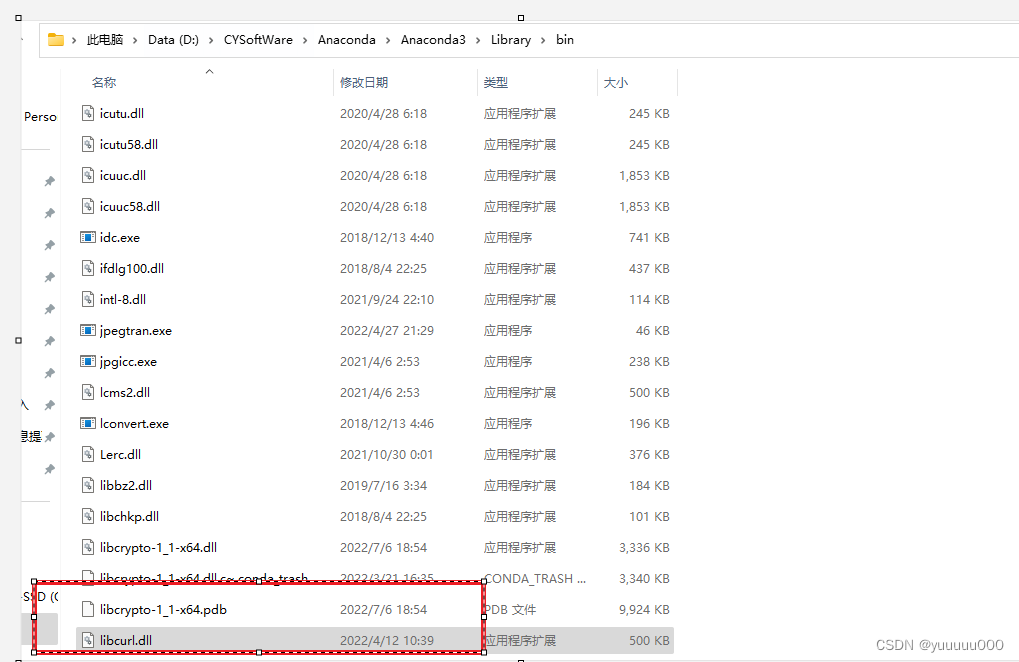
找到之后复制到pdfinfo.exe所在的目录或系统目录中:

类似的问题还有很多:
解决思路:缺什么补什么
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









