









源码地址github,里面有详细注释:https://github.com/15160200501/scrapy-
可以直接运行,不能运行的话,接口应该是换了
工具:pycharm、python37、mongodb数据库、数据库可视化工具robo3t
知乎:
思路:1、选定候选人
2、获取粉丝和关注列表
3、获取列表用户信息
4、获取每位用户粉丝和关注
先创建一个Scrapy项目:
先在settings:不遵循robots协议,在HEADERS里面添加头部信息user-agent,不添加头信息会报状态码
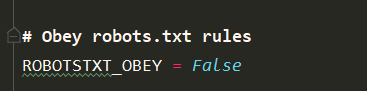

执行scrapy crawl zhihu,看是否返回该url的源码(个人信息的api口)

执行scrapy crawl zhihu,看是否返回该url的源码(关注列表的api接口)

执行scrapy crawl zhihu,看到都能返回该url的json文本
在UserItem中编写item,需要爬取的信息,根据抓包中的json看到

执行scrapy crawl zhihu,能看到返回第一个作者信息和关注列表的信息,有下一页,进行自己的回调。

爬取第一个作者的个人信息的关注列表后,再爬取关注列表里的关注的人,层层递归爬取关注的人

再添加粉丝的列表,也进行跟关注一样的操作,层层递归爬取粉丝列表的粉丝个人信息
要存储到mongodb数据库中,可以看到scrapy的官方文档https://doc.scrapy.org/en/latest/topics/item-pipeline.html,复制粘贴到pipeline管道文件中,而后再进行修改
 ,
,
再settings中再进行一些改动

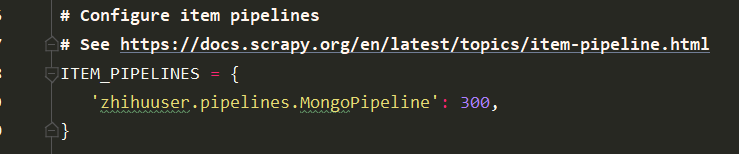
完成这些,已经完成知乎全部用户信息的代码编写呢,之后就是在命令行执行scrapy crawl zhihu

由于爬取的太多,按了ctrl+c暂停了爬取,之后在mongodb数据库的可视化工具robo3t进行知乎用户的信息查看,可以看到右上角500,说明共爬取了10页,一页爬取50个个人信息,爬取了将近500个个人的信息

















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









