









我是跟着崔大神的视频进行学习的,这是他的一个案例,一步一步敲,代码肯定是没有问题的,肯定能学到一点东西,注释不想加了,下面自己一步一步完成的。(代码注释的部分,是为了测试,时常打印一下信息,看有没有问题)
流程框架:
- 爬取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果
- 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息
- 下载图片并保存数据库
- 开启循环及多线程:对多网页内容遍历,开启多线程提高抓取速度
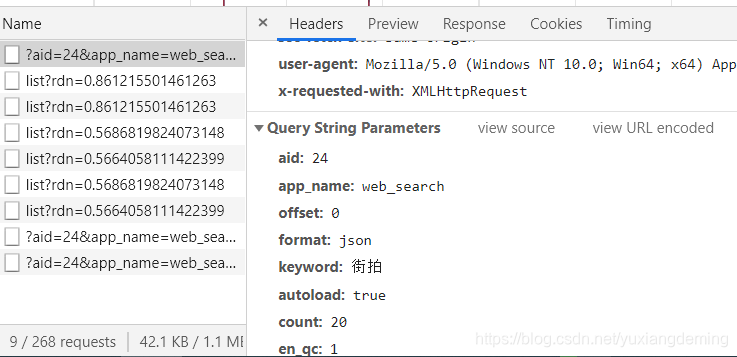
1、在网址www.toutiao.com,在搜索框输入“街拍”,打开开发者选项,发现返回的没有我们想要的数据,判断该网页是通过Ajax加载,JS渲染
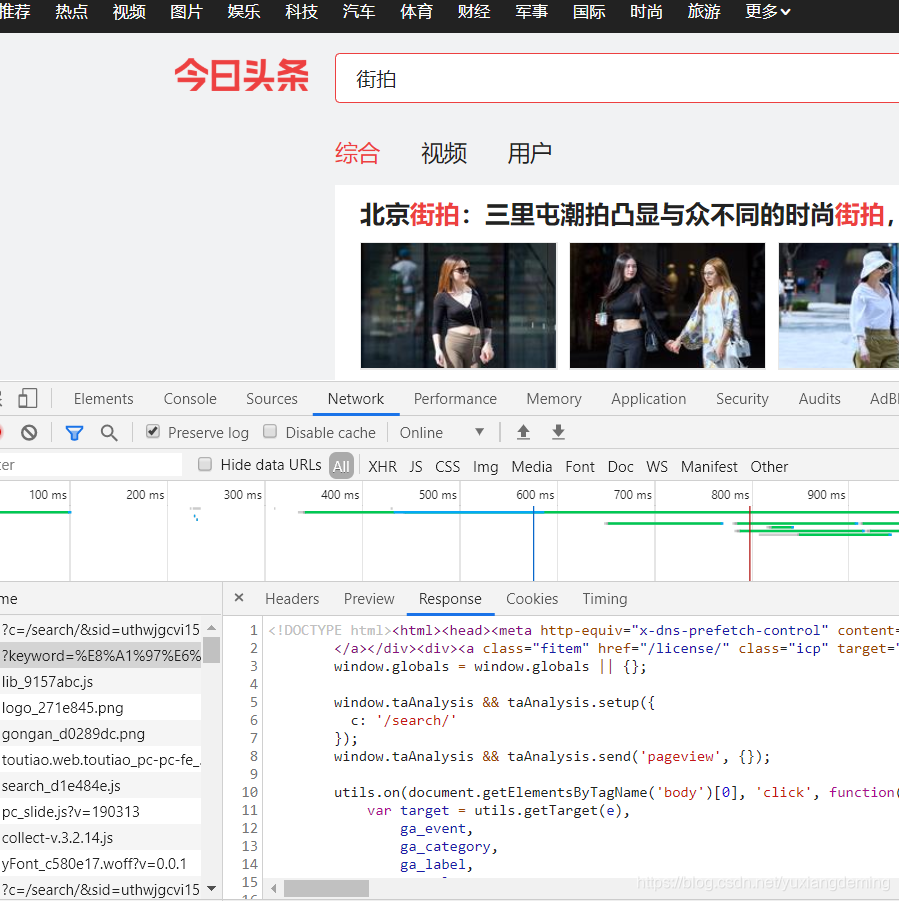
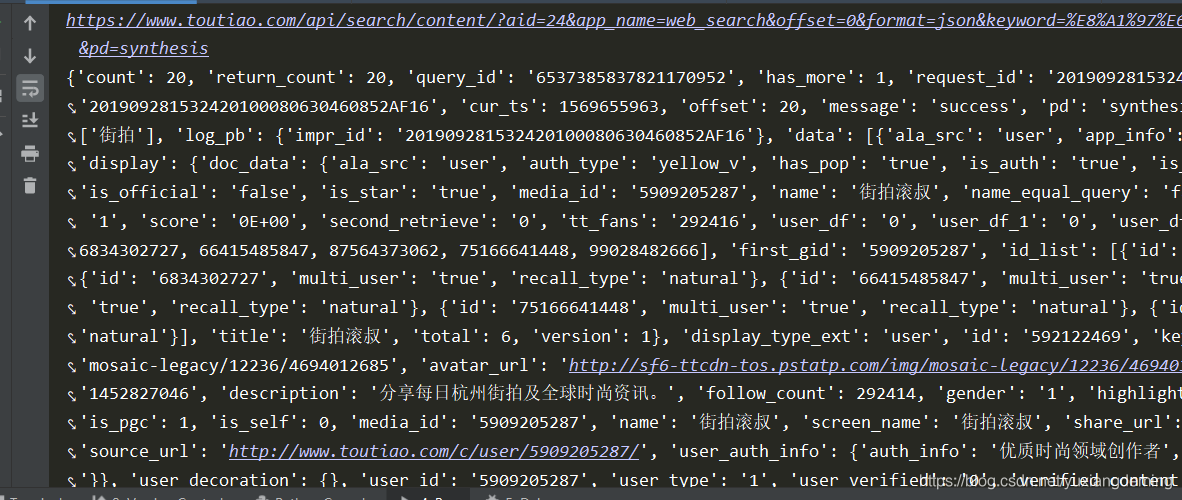
2、点击XHR,点击第一个URL,看返回的json格式的数据,由于看的不方便,将它复制粘贴到json格式化阅读器中,可以看到title与头条里的title是一样的,说明数据是正确的

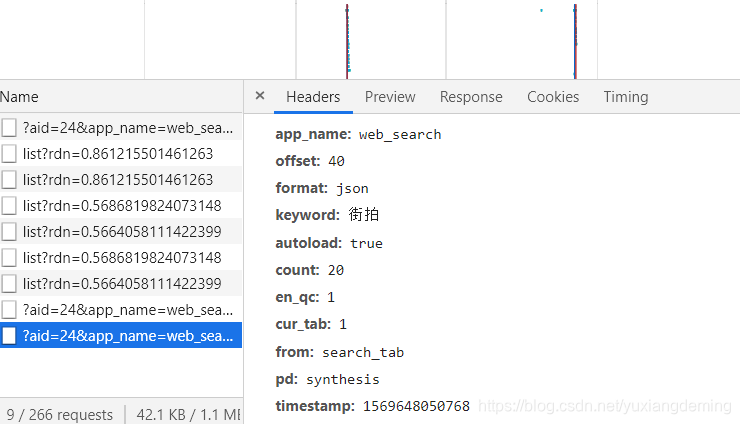
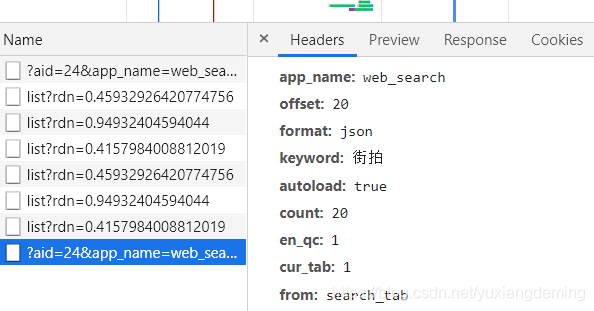
滚轮一直向下滑动,一次加载20个,发现offset在变化,count一直是20
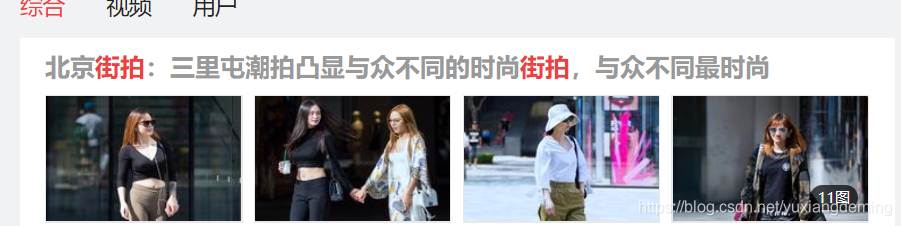
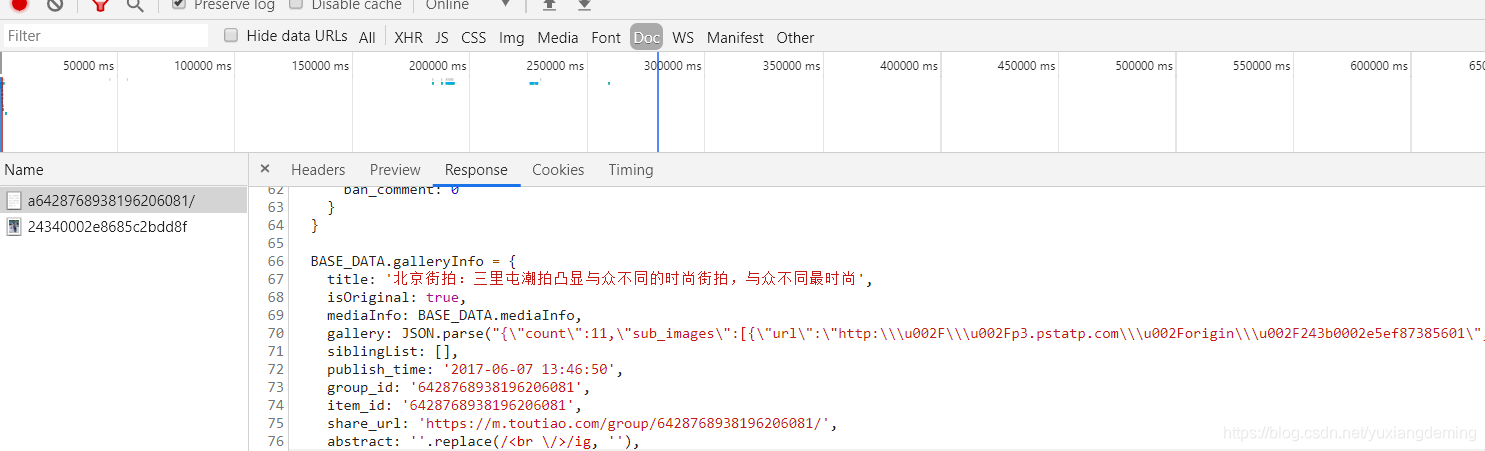
3、点击第一个内容,进行跳转,在开发者选项里能不能找到图片的url,结果发现在Doc中的gallery中,有图片的地址。可以自己尝试,点击图片右键,查看图片的地址,进行对应。数了一下是11个图片的地址,不过这些需要正则匹配一下。


4、至此已经分析完页面,打开pycharm,创建一个项目,首先测试打印json返回的数据,发现能打印出来,一定要加headers,不然是打印不出东西来的。后面就需要我们进行解析
import requests
from urllib.parse import urlencode
def get_page_index(offset):
headers = {
'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'cookie': 'tt_webid=6741580036883301901; WEATHER_CITY=%E5%8C%97%E4%BA%AC; __tasessionId=uthwjgcvi1569646429442; tt_webid=6741580036883301901; csrftoken=22882f942604650099034bfe8636766a; s_v_web_id=3fa020c7425a1ebabcf947ef5b12327e',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params)
print(url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except requests.ConnectionError:
return None
def main():
html = get_page_index(0)
print(html)
if __name__ == '__main__':
main()
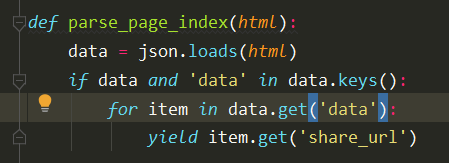
5、增加解析索引页的图片的url,将它们打印出来
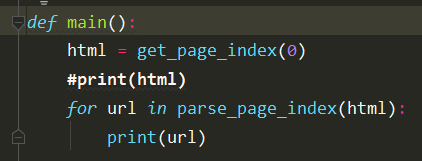
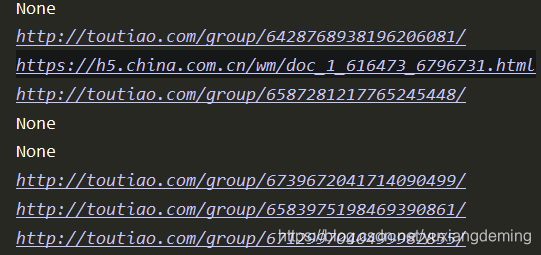
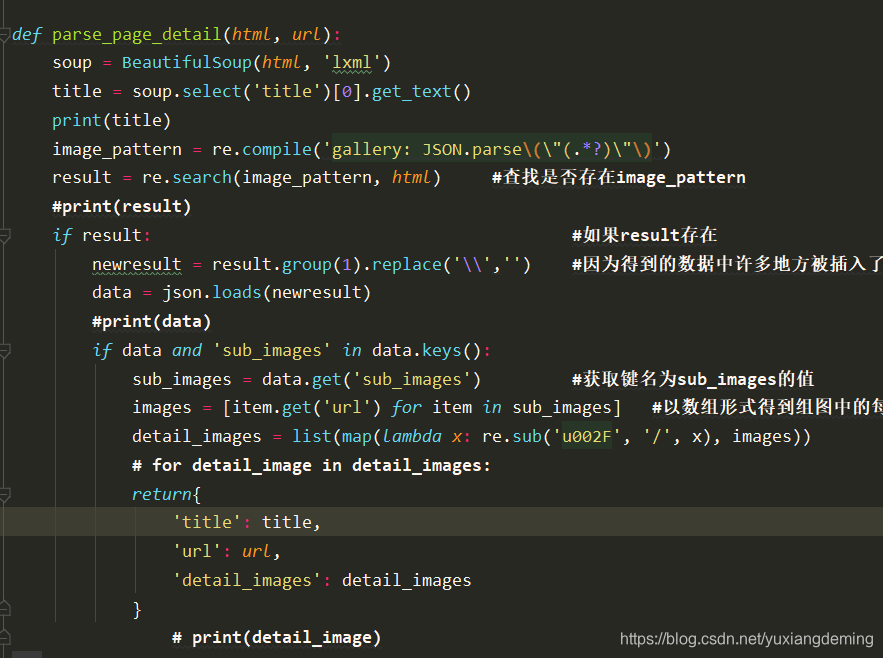
6、再添加详情页的爬取以及解析,能看见真正需要的图片的url信息打印出来(这里需要注意详情页图片的url随时都是会变的,需要自己分析图片url的规律),到这里基本结束,需要的信息都解析出来呢,之后将这些数据存到MongoDB中
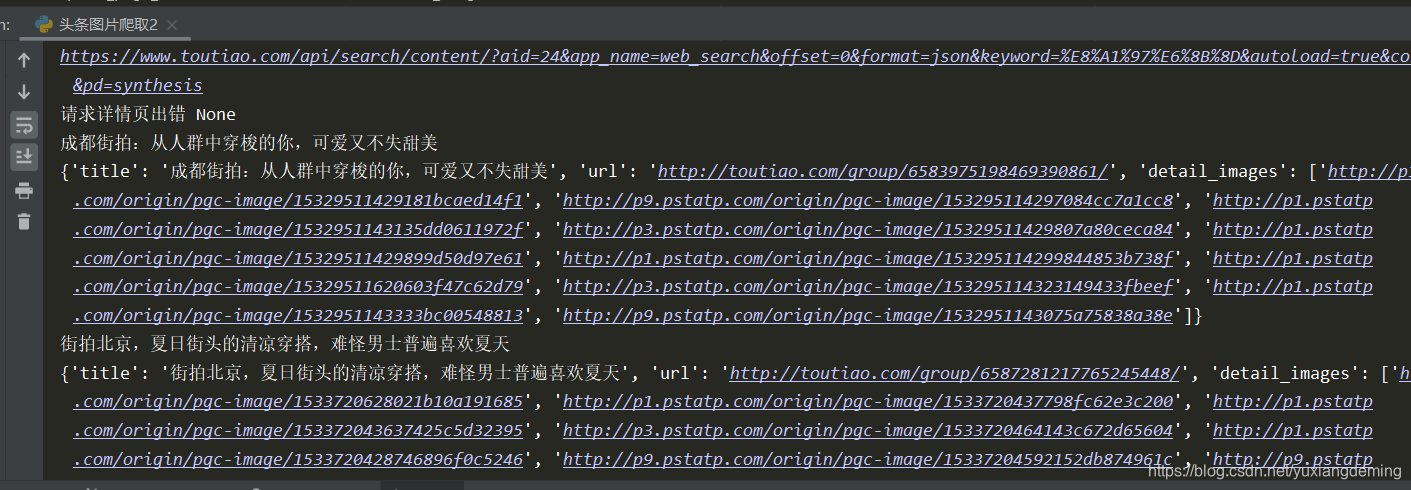
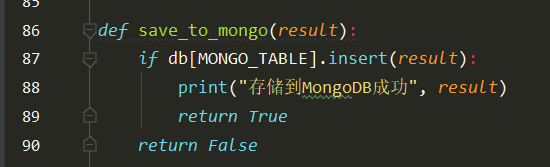
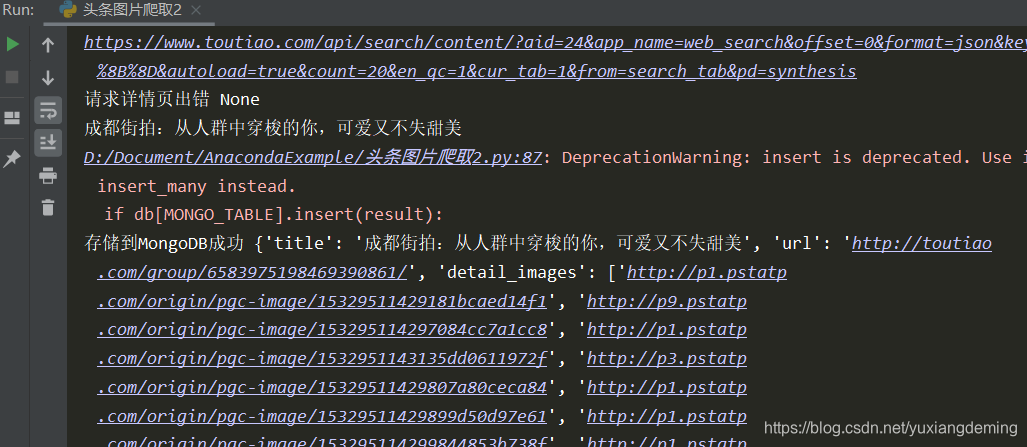
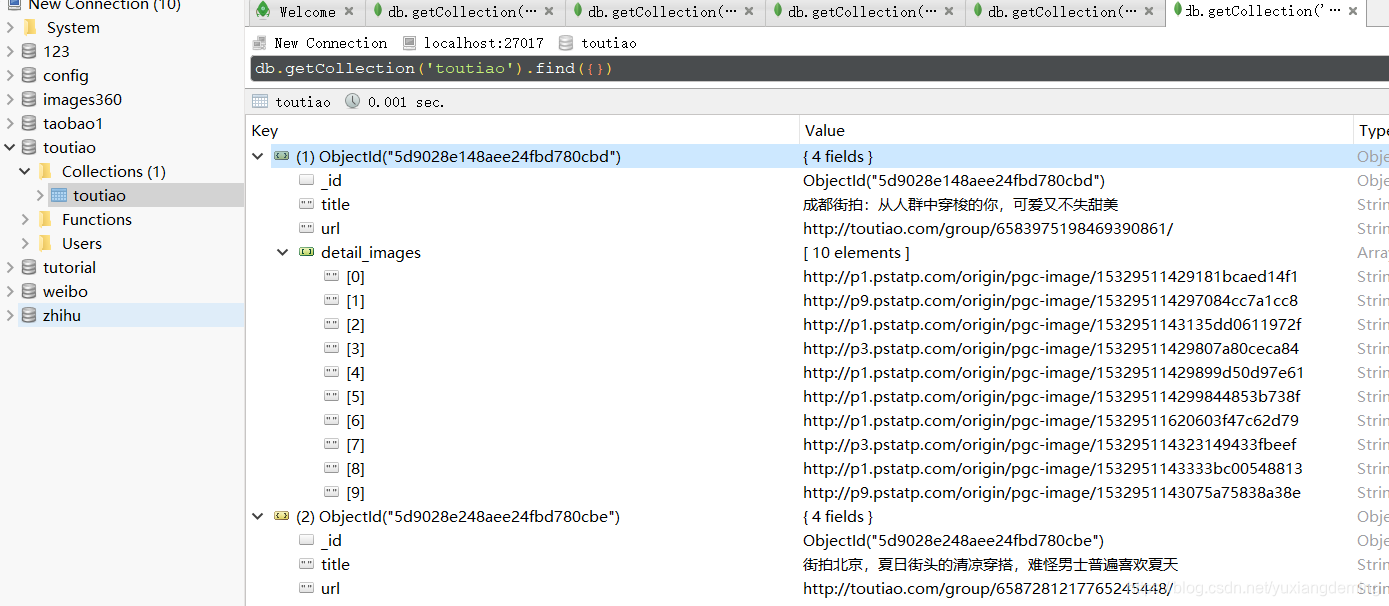
7、将数据存储到MongoDB中,用robo3T可视化工具查看下载出来的数据,可以看到这里只存储了图片的url,还需要将图片下载下来。

8、下载图片到本地
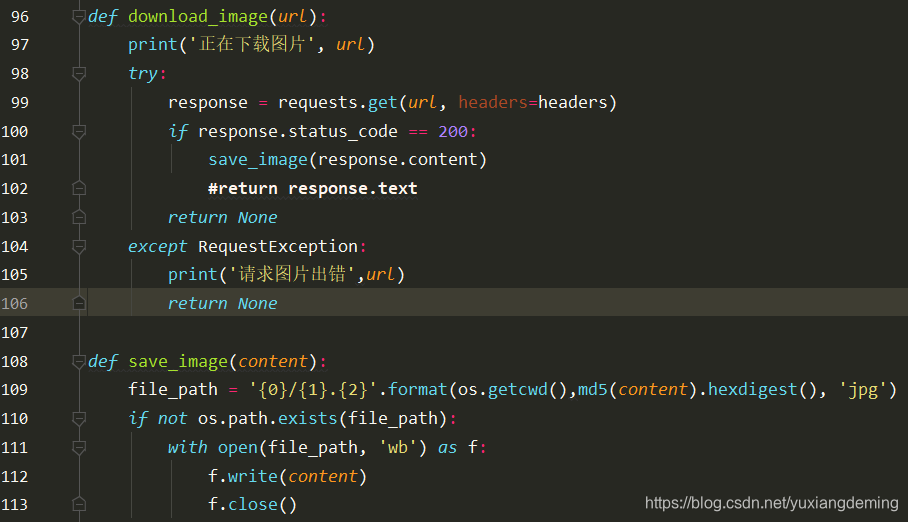

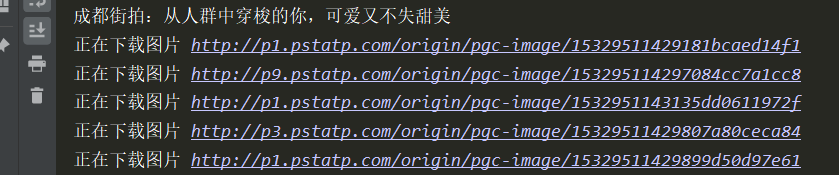


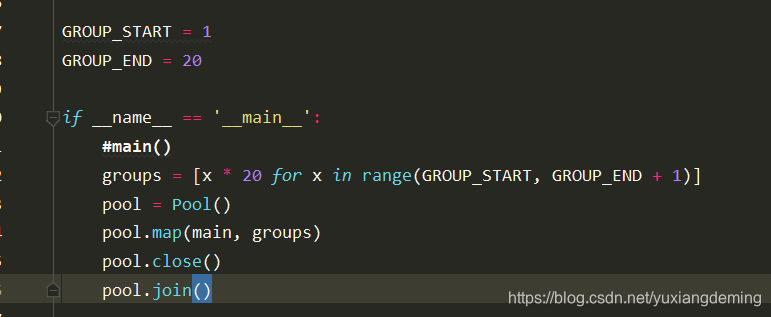
9、下一步,因为目前只是抓取第一个索引页,下拉索引页可以看到offset20递增,改变offset值就可以爬取街拍所有的索引页以及详情页的图片(这里有一点错误,不是按照顺序爬取,爬取一点出现错误,但是上面是对的,就是这里爬取所有索引页有一点问题)
源代码GitHub:https://github.com/15160200501/TouTiao


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









