







环境信息
OS: Windows10
Elasticsearch: 6.5.1
Logstash: 6.5.1
MySQL: 5.7.24
依赖文件:mysql-connector-java-xxx.jar
在进行以下操作前,假设你对elasticsearch,logstash已经有了基本的了解和使用。
约定:下文中使用es或ES代指elasticsearch.
环境搭建
es下载地址:https://www.elastic.co/downloads/elasticsearch/elasticsearch-6.5.1.zip
Logstash下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-6.5.1.zip
Logstash下载好后,需要安装logstash-input-jdbc插件:
在logstash的bin目录下,执行命令logstash-plugin.bat install logstash-input-jdbc 安装。

下载完后解压,es正常启动即可,logstash需要先编写配置文件,xxx.conf,注意该文件不能直接通过windows下的新建文本文档来新建,该文件的编码需要为utf8,否则启动加载该配置文件时会出错,可使用notepad++等工具创建。
配置文件的基本格式如下:
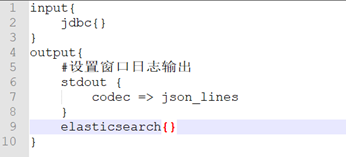
单数据源同步
单数据源同步是指,数据只写入一个index下(注意:6.x版本下,一个index下只能有一个type),jdbc块和elasticsearch块也是一一对应的关系,具体看下同步conf的配置(示例配置文件名称:sync.conf):
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.91.149:3306/test"
jdbc_user => "root"
jdbc_password => "root"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
jdbc_driver_library => "sync-conf/mysql-connector-java-6.0.6.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
statement_filepath => "sync-conf/userSync.sql"
type => "user"
}
}
output {
#设置窗口日志输出
stdout {
codec => json_lines
}
elasticsearch {
hosts => ["127.0.0.1:9200"]
#注意index的值不支持大写字母
index => "user"
#document_type自行设置,不设置时,默认为doc
#document_type => ""
#此处的值来自查询sql中的列名称,根据需要自行配置
document_id => "%{id}"
}
}
至于userSync.sql的内容就是你的业务sql,只能有一条,且末尾不要加分号,否则出错!
执行logstash.bat -f sync-conf/sync.conf 启动同步,同步的内容会输出到屏幕上。执行完成后可在es中查看数据。
多数据源同步
多数据源同步是指,需要同步多种类型的数据到es中,input的配置添加相应的jdbc模块,output中根据type类型判断添加对应的elasticsearch模块,如下图所示。
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.91.149:3306/test"
jdbc_user => "root"
jdbc_password => "root"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
jdbc_driver_library => "sync-conf/mysql-connector-java-6.0.6.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
statement_filepath => "sync-conf/userSync.sql"
type => "user"
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.91.149:3306/test"
jdbc_user => "root"
jdbc_password => "root"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
jdbc_driver_library => "sync-conf/mysql-connector-java-6.0.6.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#此处的路径最好是绝对路径,行对路径取决与允许命令的目录
statement_filepath => "sync-conf/userAddressSync.sql"
type => "user_address"
}
}
output {
#设置窗口日志输出
stdout {
codec => json_lines
}
if[type] == "user" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
#注意index的值不支持大写字母
index => "user"
#document_type自行设置,不设置时,默认为doc
#document_type => ""
#此处的值来自查询sql中的列名称,根据需要自行配置
document_id => "%{id}"
}
}
if[type] == "user_address" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
#注意index的值不支持大写字母
index => "user_address"
#document_type自行设置,不设置时,默认为doc
#document_type => ""
#此处的值来自查询sql中的列名称,根据需要自行配置
document_id => "%{id}"
}
}
}

全量同步
以上的单数据源/多数据源同步都是全量同步,即没有任何条件地进行同步。
增量同步
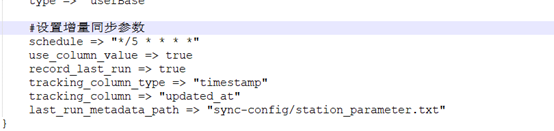
增量同步需要在jdbc模块添加相应的增量配置,下图是增量的配置参数
Schedule是cron格式的同步周期,其它几个都是用来记录同步增量指标的,
Tracking_column是数据库中的增量指标字段名
Tracking_columu_type 目前只支持两种numeric,timestamp,
Last_run_metadata_path是保存上次同步的增量指标值。
问题记录
TypeError: can’t dup Fixnum
可能原因是增量标记的类型不匹配,删除last_run_metadata_path文件中的内容,再次同步。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









