









大家好,我是东哥。
在信贷的风控模型中最常用、最经典的可能要属评分卡了,所谓评分卡就是给信贷客户进行打分,按照不同业务场景可为贷前、贷中、贷后和反欺诈,一般叫做ABCF卡。模型得到分数,通过设置cutoff阈值给出评估结果,结果可直接用于通过或拒绝,或者用于策略应用。
区别于xgb等机器学习模型,评分卡使用逻辑回归,之所是还在使用时因为它属于广义线性回归,在特征的解释性上非常的强。
本次和大家分享一个开源的评分卡神器toad。从数据探索、特征分箱、特征筛选、特征WOE变换、建模、模型评估、转换分数,都做了完美的包装,可以说是一条龙的服务啊,极大的简化了建模人员的门槛。
并且东哥也仔细看过源码,基本都是通过numpy来实现的,并且部分过程还使用了多线程提速,所以在速度上也是有一定保障的。
链接:https://github.com/amphibian-dev/toad
下面就介绍如何使用toad建立评分卡的整个流程。安装就不说了,标准的方法,自行pip安装。
一、读取数据、划分样本集
首先通过read_csv读取数据,看看数据概况。
data = pd.read_csv('train.csv')
print('Shape:',data.shape)
data.head(10)
Shape: (108940, 167)
这个测试数据有10万条数据,167个特征。
print('month:',data.month.unique())
month: ['2019-03' '2019-04' '2019-05' '2019-06' '2019-07']
通过观察时间变量,我们发现数据的时间跨度为2019年5月到7月。为了真正测试模型效果,我们将用3月和4月数据用于训练样本,5月、6月、7月数据作为时间外样本,也叫作OOT的跨期样本。
train = data.loc[data.month.isin(['2019-03','2019-04'])==True,:]
OOT = data.loc[data.month.isin(['2019-03','2019-04'])==False,:]
#train = data.loc[data.month.isin(['Mar-19','Apr-19'])==True,:]
#OOT = data.loc[data.month.isin(['Mar-19','Apr-19'])==False,:]
print('train size:',train.shape,'\nOOT size:',OOT.shape)
train size: (43576, 167)
OOT size: (65364, 167)
其实,这部分属于模型设计的阶段,是非常关键的环节。实际工作中会考虑很多因素,要结合业务场景,根据样本量、可回溯特征、时间窗口等因素制定合适的观察期、表现期、以及样本,并且还要定义合适的Y标签。本次主要介绍toad的用法,上面的设计阶段先忽略掉。
二、EDA相关功能
1. toad.detect
EDA也叫数据探索分析,主要用于检测数据情况。toad输出每列特征的统计性特征和其他信息,主要的信息包括:缺失值、unique values、数值变量的平均值、离散值变量的众数等。
toad.detect(train)[:10]

2. toad.quality
这个功能主要用于帮助我们进行变量的筛选,可以直接计算各种评估指标,如iv值、gini指数,entropy熵,以及unique values,结果以iv值排序。target为目标列,iv_only决定是否只输出iv值。
to_drop = ['APP_ID_C','month'] # 去掉ID列和month列
toad.quality(data.drop(to_drop,axis=1),'target',iv_only=True)[:15]

注意:1. 对于数据量大或高维度数据,建议使用iv_only=True 2. 要去掉主键,日期等高unique values且不用于建模的特征
但是,这一步只是计算指标而已,呈现结果让我们分析,还并没有真的完成筛选的动作。
三、特征筛选
toad.selection.select
前面通过EDA检查过数据质量后,我们会有选择的筛选一些样本和变量,比如缺失值比例过高的、IV值过低的、相关性太强的等等。
-
empyt=0.9: 缺失值大于0.9的变量被删除 -
iv=0.02: iv值小于0.02的变量被删除 -
corr=0.7: 两个变量相关性高于0.7时,iv值低的变量被删除 -
return_drop=False: 若为True,function将返回被删去的变量列 -
exclude=None: 明确不被删去的列名,输入为list格式
用法很简单,只要通过设置以下几个参数阈值即可实现,如下:
train_selected, dropped = toad.selection.select(train,target = 'target', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True, exclude=['APP_ID_C','month'])
print(dropped)
print(train_selected.shape)
经过上面的筛选,165个变量最终保留了32个变量。并且返回筛选过后的dataframe和被删掉的变量列表。
当然了,上面都是一些常规筛选变量的方法,可能有些特殊的变量比如从业务角度很有用是需要保留的,但不满足筛选要求,这时候可以用exclude排除掉。这个功能对于变量初筛非常有用,各种指标直接计算并展示出来。
四、分箱
在做变量的WOE变换之前需要做变量的分箱,分箱的好坏直接影响WOE的结果,以及变换后的单调性。toad将常用的分箱方法都集成了,包括等频分箱、等距分箱、卡方分箱、决策树分箱、最优分箱等。
并且,toad的分箱功能支持数值型数据和离散型分箱。 这部分东哥看过源码,toad首先判断变量类型,如果为数值型就按数值型分箱处理,如果为非数值型,那么会判断变量唯一值的个数,如果大于10个或者超过变量总数的50%,那么也按照数值型处理。
另外,toad还支持将空值单独分箱处理。
toad.transform.Combiner 分箱步骤如下:
- 初始化:c =
toad.transform.Combiner() - 训练分箱:
c.fit(dataframe, y = 'target', method = 'chi', min_samples = None, n_bins = None, empty_separate = False)- y: 目标列
- method: 分箱方法,支持chi(卡方分箱), dt(决策树分箱), kmean, quantile, step(等步长分箱)
- min_samples: 每箱至少包含样本量,可以是数字或者占比
- n_bins: 箱数,若无法分出这么多箱数,则会分出最多的箱数
- empty_separate: 是否将空箱单独分开
- 查看分箱节点:
c.export() - 手动调整分箱:
c.load(dict) - apply分箱结果:
c.transform(dataframe, labels=False):
labels: 是否将分箱结果转化成箱标签。False时输出0,1,2…(离散变量根据占比高低排序),True输出(-inf, 0], (0,10], (10, inf)。
注意:做筛选时要删去不需要分箱的列,特别是ID列和时间列。
# initialise
c = toad.transform.Combiner()
# 使用特征筛选后的数据进行训练:使用稳定的卡方分箱,规定每箱至少有5%数据, 空值将自动被归到最佳箱。
c.fit(train_selected.drop(to_drop, axis=1), y = 'target', method = 'chi', min_samples = 0.05) #empty_separate = False
# 为了演示,仅展示部分分箱
print('var_d2:',c.export()['var_d2'])
print('var_d5:',c.export()['var_d5'])
print('var_d6:',c.export()['var_d6'])
结果输出:
var_d2: [747.0, 782.0, 820.0]
var_d5: [['O', 'nan', 'F'], ['M']]
var_d6: [['PUBLIC LTD COMPANIES', 'NON-RESIDENT INDIAN', 'PRIVATE LTD COMPANIES', 'PARTNERSHIP FIRM', 'nan'], ['RESIDENT INDIAN', 'TRUST', 'TRUST-CLUBS/ASSN/SOC/SEC-25 CO.', 'HINDU UNDIVIDED FAMILY', 'CO-OPERATIVE SOCIETIES', 'LIMITED LIABILITY PARTNERSHIP', 'ASSOCIATION', 'OVERSEAS CITIZEN OF INDIA', 'TRUST-NGO']]
观察分箱并调整
因为自动分箱也不可能满足所有需要,很多情况下还是要手动分箱。toad除了上面自动分箱以外,还提供了可视化分箱的功能,帮助调整分箱节点,比如观察变量的单调性。有两种功能:
1. 时间内观察
toad.plot.bin_plot(dataframe, x = None, target = target) 也就是不考虑时间的因素,单纯的比较各个分箱里的bad_rate,观察单调性。
# 看'var_d5'在时间内的分箱
col = 'var_d5'
#观察单个变量分箱结果时,建议设置'labels = True'
bin_plot(c.transform(train_selected[[col,'target']], labels=True), x=col, target='target')

上图中,bar代表了样本量占比,红线代表了坏客户占比。通过观察发现分箱有些不合理,还有调整优化的空间,比如将F和M单独一箱,0和空值分为一箱。因此,使用c.set_rules(dict)对这个分箱进行调整。
# iv值较低,假设我们要 'F' 淡出分出一组来提高iv
#设置分组
rule = {'var_d5':[['O', 'nan'],['F'], ['M']]}
#调整分箱
c.set_rules(rule)
#查看手动分箱稳定性
bin_plot(c.transform(train_selected[['var_d5','target']], labels=True), x='var_d5', target='target')
badrate_plot(c.transform(OOT[['var_d5','target','month']], labels=True), target='target', x='month', by='var_d5')

2. 跨时间观察
toad.plot.badrate_plot:考虑时间因素,输出不同时间段中每箱的正样本占比,观察分箱随时间变量的稳定性。
-
target: 目标列
-
x: 时间列, string格式(要预先分好并设成string,不支持timestampe)
-
by: 需要观察的特征
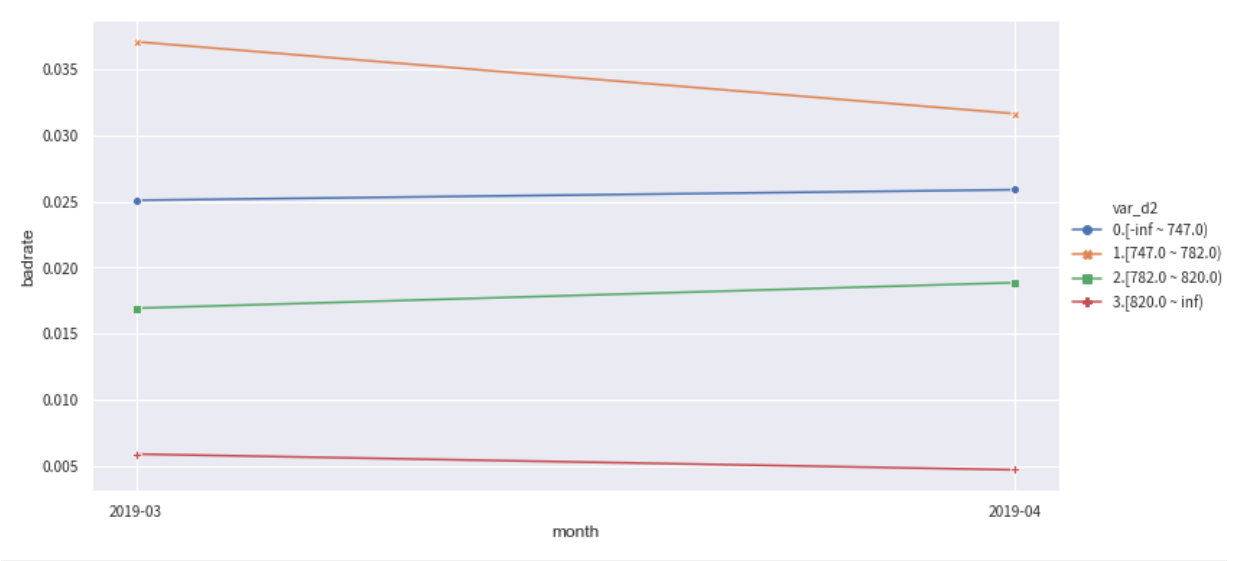
下面分别观察变量var_d2在训练集和OOT测试集中随时间month变化的稳定性。正常情况下,每个分箱的bad_rate应该都有所区别,并且随时间保持稳定不交叉。如果折现有所交叉,说明分箱不稳定,需要重新调整。
from toad.plot import badrate_plot
col = 'var_d2'
# 观察 'var_d2' 分别在时间内和OOT中的稳定性
badrate_plot(c.transform(train[[col,'target','month']], labels=True), target='target', x='month', by=col)
badrate_plot(c.transform(OOT[[col,'target','month']], labels=True), target='target', x='month', by=col)
'''
敞口随时间变化而增大为优,代表了变量在更新的时间区分度更强。线之前没有交叉为优,代表分箱稳定。
'''

五、WOE转化
WOE转化在分箱调整好之后进行,步骤如下:
-
用上面调整好的
Combiner(c)转化数据:c.transform,只会转化被分箱的变量。 -
初始化woe transer:
transer = toad.transform.WOETransformer() -
训练转化woe:
transer.fit_transform
训练并输出woe转化的数据,用于转化train/时间内数据- target:目标列数据(非列名)
- exclude: 不需要被WOE转化的列。注意:会转化所有列,包括未被分箱transform的列,通过
exclude删去不要WOE转化的列,特别是target列。
-
根据训练好的transer,转化test/OOT数据:
transer.transform
根据训练好的transer输出woe转化的数据,用于转化test/OOT数据。
# 初始化
transer = toad.transform.WOETransformer()
# combiner.transform() & transer.fit_transform() 转化训练数据,并去掉target列
train_woe = transer.fit_transform(c.transform(train_selected), train_selected['target'], exclude=to_drop+['target'])
OOT_woe = transer.transform(c.transform(OOT))
print(train_woe.head(3))
结果输出:
APP_ID_C target var_d2 var_d3 var_d5 var_d6 var_d7 \
0 app_1 0 -0.178286 0.046126 0.090613 0.047145 0.365305
1 app_2 0 -1.410248 0.046126 -0.271655 0.047145 -0.734699
2 app_3 0 -0.178286 0.046126 0.090613 0.047145 0.365305
var_d11 var_b3 var_b9 ... var_l_60 var_l_64 var_l_68 var_l_71 \
0 -0.152228 -0.141182 -0.237656 ... 0.132170 0.080656 0.091919 0.150975
1 -0.152228 0.199186 0.199186 ... 0.132170 0.080656 0.091919 0.150975
2 -0.152228 -0.141182 0.388957 ... -0.926987 -0.235316 -0.883896 -0.385976
var_l_89 var_l_91 var_l_107 var_l_119 var_l_123 month
0 0.091901 0.086402 -0.034434 0.027322 0.087378 2019-03
1 0.091901 0.086402 -0.034434 0.027322 0.087378 2019-03
2 0.091901 -0.620829 -0.034434 -0.806599 -0.731941 2019-03
[3 rows x 34 columns]
六、逐步回归
toad.selection.stepwise
逐步回归特征筛选,支持向前,向后和双向。 逐步回归属于包裹式的特征筛选方法,这部分通过使用sklearn的REF实现。
-
estimator: 用于拟合的模型,支持’ols’, ‘lr’, ‘lasso’, ‘ridge’
-
direction: 逐步回归的方向,支持’forward’, ‘backward’, ‘both’ (推荐)
-
criterion: 评判标准,支持’aic’, ‘bic’, ‘ks’, ‘auc’
-
max_iter: 最大循环次数
-
return_drop: 是否返回被剔除的列名
-
exclude: 不需要被训练的列名,比如ID列和时间列
根据多次验证,一般来讲 direction = 'both'效果最好。estimator = 'ols'以及criterion = 'aic'运行速度快且结果对逻辑回归建模有较好的代表性。
# 将woe转化后的数据做逐步回归
final_data = toad.selection.stepwise(train_woe,target = 'target', estimator='ols', direction = 'both', criterion = 'aic', exclude = to_drop)
# 将选出的变量应用于test/OOT数据
final_OOT = OOT_woe[final_data.columns]
print(final_data.shape) # 逐步回归从31个变量中选出了10个
结果输出:
(43576, 13)
最后筛选后,再次确定建模要用的变量。
col = list(final_data.drop(to_drop+['target'],axis=1).columns)
七、建模和模型评估
首先,使用逻辑回归建模,通过sklearn实现。模型参数比如正则化、样本权重等不在这里详解。
# 用逻辑回归建模
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(final_data[col], final_data['target'])
# 预测训练和隔月的OOT
pred_train = lr.predict_proba(final_data[col])[:,1]
pred_OOT_may =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-05',col])[:,1]
pred_OOT_june =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-06',col])[:,1]
pred_OOT_july =lr.predict_proba(final_OOT.loc[final_OOT.month == '2019-07',col])[:,1]
然后,计算模型预测结果。风控模型常用的评价指标有: KS、AUC、PSI等。下面展示如果通过toad快速实现完成。
KS 和 AUC
from toad.metrics import KS, AUC
print('train KS',KS(pred_train, final_data['target']))
print('train AUC',AUC(pred_train, final_data['target']))
print('OOT结果')
print('5月 KS',KS(pred_OOT_may, final_OOT.loc[final_OOT.month == '2019-05','target']))
print('6月 KS',KS(pred_OOT_june, final_OOT.loc[final_OOT.month == '2019-06','target']))
print('7月 KS',KS(pred_OOT_july, final_OOT.loc[final_OOT.month == '2019-07','target']))
结果输出:
train KS 0.3707986228750539
train AUC 0.75060723924743
OOT结果
5月 KS 0.3686687175756087
6月 KS 0.3495273403486497
7月 KS 0.3796914199845523
PSI
PSI分为两种,一个是变量的PSI,一个是模型的PSI。
下面是变量PSI的计算,比较训练集和OOT的变量分布之间的差异。
toad.metrics.PSI(final_data[col], final_OOT[col])
结果输出:
var_d2 0.000254
var_d5 0.000012
var_d7 0.000079
var_d11 0.000191
var_b10 0.000209
var_b18 0.000026
var_b19 0.000049
var_b23 0.000037
var_l_20 0.000115
var_l_68 0.000213
dtype: float64
模型PSI的计算,分别计算训练集和OOT模型预测结果的差异,下面细分为三个月份比较。
print(toad.metrics.PSI(pred_train,pred_OOT_may))
print(toad.metrics.PSI(pred_train,pred_OOT_june))
print(toad.metrics.PSI(pred_train,pred_OOT_june))
另外,toad还提供了整个评价指标的汇总,输出模型预测分箱后评判信息,包括每组的分数区间,样本量,坏账率,KS等。
toad.metrics.KS_bucket
-
bucket:分箱的数量
-
method:分箱方法,建议用quantile(等人数),或step (等分数步长)
bad\_rate为每组坏账率:
-
组之间的坏账率差距越大越好
-
可以用于观察是否有跳点
-
可以用与找最佳切点
-
可以对比
# 将预测等频分箱,观测每组的区别
toad.metrics.KS_bucket(pred_train, final_data['target'], bucket=10, method = 'quantile')

八、转换评分
toad.ScoreCard
最后一步就是将逻辑回归模型转标准评分卡,支持传入逻辑回归参数,进行调参。
-
combiner: 传入训练好的toad.Combiner对象 -
transer: 传入先前训练的toad.WOETransformer对象 -
pdo、rate、base_odds、base_score:
e.g. pdo=60, rate=2, base_odds=20, base_score=750
实际意义为当比率为1/20,输出基准评分750,当比率为基准比率2倍时,基准分下降60分 -
card: 支持传入专家评分卡 -
**kwargs: 支持传入逻辑回归参数(参数详见sklearn.linear_model.LogisticRegression)
card = toad.ScoreCard(
combiner = c,
transer = transer,
#class_weight = 'balanced',
#C=0.1,
#base_score = 600,
#base_odds = 35 ,
#pdo = 60,
#rate = 2
)
card.fit(final_data[col], final_data['target'])
结果输出:
ScoreCard(base_odds=35, base_score=750, card=None,
combiner=<toad.transform.Combiner object at 0x1a2434fdd8>, pdo=60,
rate=2,
transer=<toad.transform.WOETransformer object at 0x1a235a5358>)
注:评分卡在 fit 时使用 WOE 转换后的数据来计算最终的分数,分数一旦计算完成,便无需 WOE 值,可以直接使用 原始数据 进行评分。
# 直接使用原始数据进行评分
card.predict(train)
#输出标准评分卡
card.export()
结果输出:
{'var_d2': {'[-inf ~ 747.0)': 65.54,
'[747.0 ~ 782.0)': 45.72,
'[782.0 ~ 820.0)': 88.88,
'[820.0 ~ inf)': 168.3},
'var_d5': {'O,nan': 185.9, 'F': 103.26, 'M': 68.76},
'var_d7': {'LARGE FLEET OPERATOR,COMPANY,STRATEGIC TRANSPRTER,SALARIED,HOUSEWIFE': 120.82,
'DOCTOR-SELF EMPLOYED,nan,SAL(RETIRAL AGE 60),SERVICES,SAL(RETIRAL AGE 58),OTHERS,DOCTOR-SALARIED,AGENT,CONSULTANT,DIRECTOR,MEDIUM FLEETOPERATOR,TRADER,RETAIL TRANSPORTER,MANUFACTURING,FIRST TIME USERS,STUDENT,PENSIONER': 81.32,
'PROPRIETOR,TRADING,STRATEGIC CAPTIVE,SELF-EMPLOYED,SERV-PRIVATE SECTOR,SMALL RD TRANS.OPR,BUSINESSMAN,CARETAKER,RETAIL,AGRICULTURIST,RETIRED PERSONNEL,MANAGER,CONTRACTOR,ACCOUNTANT,BANKS SERVICE,GOVERNMENT SERVICE,ADVISOR,STRATEGIC S1,SCHOOLS,TEACHER,GENARAL RETAILER,RESTAURANT KEEPER,OFFICER,POLICEMAN,SERV-PUBLIC SECTOR,BARRISTER,Salaried,SALESMAN,RETAIL CAPTIVE,Defence (NCO),STRATEGIC S2,OTHERS NOT DEFINED,JEWELLER,SECRETARY,SUP STRAT TRANSPORT,LECTURER,ATTORNEY AT LAW,TAILOR,TECHNICIAN,CLERK,PLANTER,DRIVER,PRIEST,PROGRAMMER,EXECUTIVE ASSISTANT,PROOF READER,STOCKBROKER(S)-COMMD,TYPIST,ADMINSTRATOR,INDUSTRY,PHARMACIST,Trading,TAXI DRIVER,STRATEGIC BUS OP,CHAIRMAN,CARPENTER,DISPENSER,HELPER,STRATEGIC S3,RETAIL BUS OPERATOR,GARAGIST,PRIVATE TAILOR,NURSE': 55.79},
'var_d11': {'N': 88.69, 'U': 23.72},
'var_b10': {'[-inf ~ -8888.0)': 67.76,
'[-8888.0 ~ 0.548229531)': 97.51,
'[0.548229531 ~ inf)': 36.22},
'var_b18': {'[-inf ~ 2)': 83.72, '[2 ~ inf)': 39.23},
'var_b19': {'[-inf ~ -9999)': 70.78, '[-9999 ~ 4)': 97.51, '[4 ~ inf)': 42.2},
'var_b23': {'[-inf ~ -8888)': 64.51, '[-8888 ~ inf)': 102.69},
'var_l_20': {'[-inf ~ 0.000404297)': 78.55,
'[0.000404297 ~ 0.003092244)': 103.85,
'[0.003092244 ~ inf)': 36.21},
'var_l_68': {'[-inf ~ 0.000255689)': 70.63,
'[0.000255689 ~ 0.002045513)': 24.56,
'[0.002045513 ~ 0.007414983000000002)': 66.63,
'[0.007414983000000002 ~ 0.019943748)': 99.55,
'[0.019943748 ~ inf)': 142.36}}
九、其他功能
toad.transform.GBDTTransformer
toad还支持用gbdt编码,用于gbdt + lr建模的前置。这种融合的方式来自facebook,即先使用gbdt训练输出,再将输出结果作为lr的输入训练,以此达到更好的学习效果。
gbdt_transer = toad.transform.GBDTTransformer()
gbdt_transer.fit(final_data[col+['target']], 'target', n_estimators = 10, max_depth = 2)
gbdt_vars = gbdt_transer.transform(final_data[col])
gbdt_vars.shape
(43576, 40)
好了,以上就是toad的基本用法,真的很方便、简单。在时间比较紧的时候可以使用它进行快速分析。当然,里面还有一些细节需要完善的地方,大家可以去fork然后去优化。如果自己已经写过一套分析流程的也可参考一下源码。
原创不易,欢迎点赞、在看和分享。
参考:https://toad.readthedocs.io/en/latest/tutorial_chinese.html
原创文章持续更新,可以微信搜一搜「 Python数据科学」第一时间阅读。















 3510
3510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









