






1. 需求分析
现如今互联网无时无刻不在传输海量的数据,但这其中很多数据是冗余的,有非常多重复的字节(字符),如果设计一个转化表,将二进制数 01 代表一个 1 字节的字符,那么传输效率将大大提升。将二进制数替代本身字符有如下几点要求:
- 因为需要解压,所以编码不能有异议性,也就是说任意字符对应的二进制数不能“包含其它字符对应的二进制数”
- 需要尽可能地缩短编码的平均长度,可以让出现频率高的字符对应较短的字节,出现频率较低的字符对应较长的字节
2. 总体设计
根据以上需求,可以采用哈夫曼编码(Huffman Coding),哈夫曼编码是一种可变长编码,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字。
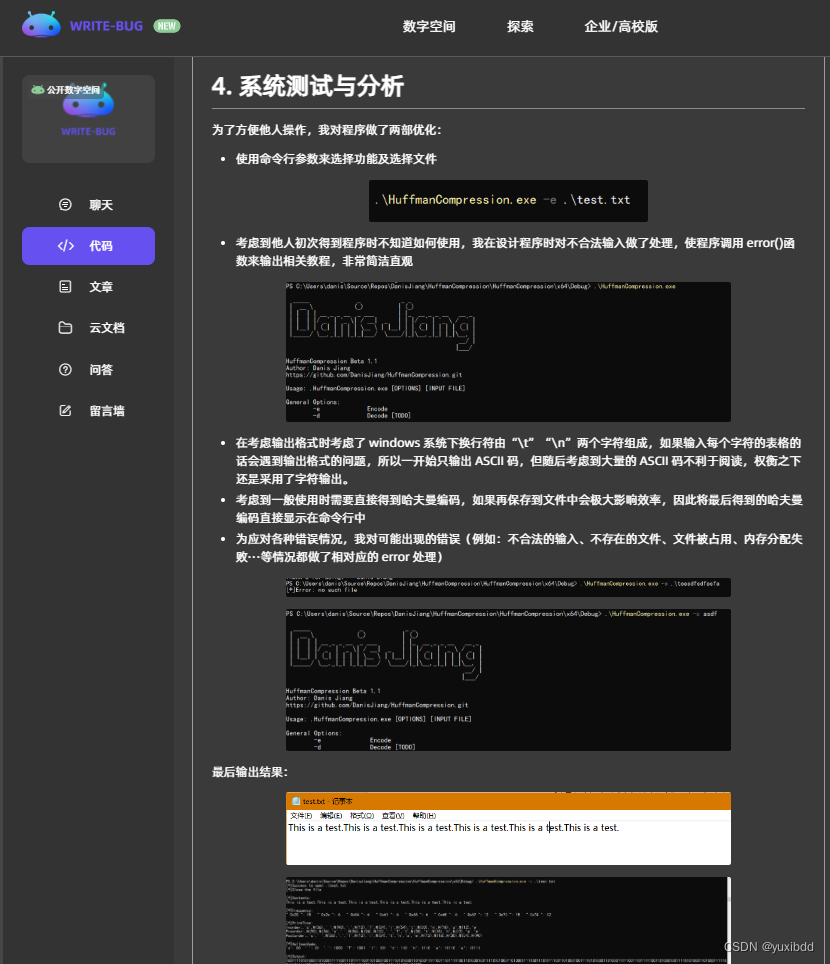
考虑需要压缩的内容一般都非常长,不利于在命令行中输入及粘贴,所以考虑从文本文件(txt)中读取内容,压缩后输出在命令行中。
源码和文档都托管在了【WRITE-BUG数字空间】上面了,有需要的可自取~















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









