







文章目录
- - - -JVM内存/GC/类加载- - -
- 1 JVM内存区域
- 2 垃圾收集
- 3 调优案例分析
- 4 类加载机制
- - - -高效并发- - -
- 1 Java内存模型与线程
- 2 线程安全与锁优化
- 3 unsafe
- 4 JUC
- 5 AQS及其实现
- 6 并发数据结构
- 7 线程池
如下图,JVM知识拓扑。

如下图,高效并发拓扑。

- - -JVM内存/GC/类加载- - -
1 JVM内存区域
1.1 内存区域分类
JVM内存可分为堆、虚拟机栈、本地方法栈、元空间、程序计数器,各区域存储内容见下表。其中,程序计数器不会抛出“内存溢出”异常。
| 内存分类 | 属性 | 存储内容&说明 |
|---|---|---|
| 堆 | 公有 | 对象实例,可通过-Xmx、-Xms参数设定 |
| 虚拟机栈 | 私有 | Java方法 |
| 本地方法栈 | 私有 | native方法,该类方法可与操作系统交互,可理解为C/C++/汇编实现的方法 |
| 元空间 | 公有 | 类型信息(类有效名、直接父类有效名、权限修饰符、是否有实现类等) |
| 程序计数器 | 私有 | 行号指示器 |
1.2 内存区域图解
JVM内存可分为堆、虚拟机栈、本地方法栈、元空间、程序计数器,其结构如下图,包括元空间、方法区演化过程。其中堆划分为新生代和老年代,新生代:老年代的默认比值为1:2。新生代划分为Eden、From Survivor(S0)、To Survivor(S1),Eden:S0:S1的默认比值为8:1:1,各区域比值均可人为设定。
直接内存不属于JVM内存,但JDK1.4之后,引入了NIO类,使用该类会涉及到直接内存。

1.3 对象的内存布局
在HotSpot虚拟机中,对象布局可分为三个部分:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。对象头中有两类信息,一类是运行时数据(如哈希码、GC分代年龄、线程持有的锁、偏向线程ID和偏向时间戳),也称Mark Word,另一类是类型指针(即指向类型信息的指针),通过类型指针可获得该对象是哪个类的实例。
2 垃圾收集
2.1 对象已死判定
1. 引用计数法
被引用增加一次,计数加1,
被引用减少一次,计数减1,
判定计数为0的对象已死,可回收,
该方法存在循环引用问题,
该方法基本不使用。
2. 可达性分析法
定义根对象(GC Roots)作为起始节点,
根据引用关系向下搜索,搜索路径为引用链,
判定不在引用链的对象已死,可回收,
Java、C#语言均使用该方法,不同的垃圾收集器定义的GC Roots不同。
3. 引用分类
强引用、软引用、弱引用、虚引用。
2.2 垃圾收集算法
1. 分代收集理论
按对象已死判定方法区分,垃圾收集算法可分为引用计数式垃圾收集算法和追踪式垃圾收集算法,目前主流虚拟机均使用追踪式垃圾收集,以下介绍的均属于追踪式垃圾收集算法。
垃圾收集器只管理堆内存,堆内存区域划分,分为新生代和老年代,参考1.2章节,堆内存区域划分后,垃圾收集器设计了3种垃圾回收策略:Minor GC、Major GC和Full GC,其功能分别为:清理年轻代,清理老年代,清理年轻代和老年代。
新生代中对象朝生夕死,存活率低,采用Minor GC策略,采用标记复制算法,老年代中存在长期存活对象和大对象,采用Major GC策略和Full GC策略,采用标记清除和标记整理算法。
2. 标记清除算法
标记被引用的对象,
删除未被标记的对象,
内存碎片化问题。
3. 标记复制算法
内存分两块,
从当前内存复制正在使用的对象到另一内存,
空间消耗高。
4. 标记整理算法
标记被引用的对象,
排列未被标记的对象到堆的一侧,
删除未被标记的对象。
5. 三种算法图解
标记-清除、复制、标记-整理三种GC算法图解如下:

2.3 内存分配与回收策略
1. 内存分配回收策略
对象优先在Eden区分配,
大对象直接进入老年代,
长期存活的对象将进入老年代,
动态对象年龄判定,大于等于某个年龄的对象超过了survivor空间一半,则大于等于某个年龄的对象直接进入老年代。
2. 对象生命周期
① 绝大多数对象分配在Eden区,其中大多数对象很快消亡;
② 最初一次,当Eden区满时,执行Minor GC,清理消亡的对象,复制剩余的对象到Survivor0(此时Survivor1空白,两个Survivor有一个空白);
③ 下一次Eden区满了,执行Minor GC,清理消亡的对象,复制存活的对象到Survivor1中,清空Eden区;
④ 同时,清理Survivor0中消亡的对象,将可以晋级的对象晋级到Old区,将存活的对象也复制到Survivor1区,清空Survivor0区;
⑤ 经过一次GC,对象年龄加1,对象切换多次后,仍然存活的对象,将被复制到老年代。
3. 空间分配担保
① 执行Minor GC时,若老年代连续可用空间不可容纳新生代对象,且虚拟机设置不可冒险,则执行Full GC;
② 执行Minor GC时,若老年代连续可用空间不可容纳新生代对象,且虚拟机设置可冒险,则检查连续可用空间是否大于历史晋升到老年代的对象平均大小,成立则执行Minor GC;
③ 执行Minor GC时,若老年代连续可用空间可容纳新生代的对象,则执行Minor GC。
4. 对象生命周期小记
我是Java对象,
出生在Eden区,
长大 进入Survivor的“From”区,
自此 在“From”区和“To”区漂泊,
年满15入老年代,该年龄可配置,
再活20生命结束。
3 调优案例分析
1. 案例1
某在线文档网站,由于内存较小,用户体验欠佳,于是升级硬件,升级后网站不定期出现长时间失去响应的现象。原因:由于代码问题,业务中存在大量大对象,扩充内存后,老年代中存在的大对象比扩充内存之前更多,一次Full GC处理的大对象太多 ,导致业务停顿。
2. 案例2
某业务系统Eden区、Survivor区、老年代均运行稳定,但经常出现内存溢出。原因为:该系统使用了NIO类,使用NIO则涉及到直接内存,但虚拟机不会对直接内存进行自主回收,而是老年代回收垃圾时,顺便清理直接内存,而该系统中老年代很稳定,很少发生Full GC,因此不会清理直接内存,导致直接内存区域溢出。
3. 案例3
某业务系统,其响应速度很慢,但大量计算机资源并不是被该业务占用。原因为:业务请求使用了外部shell脚本,一次请求则会创建一个外部shell进程,多次请求过后导致系统消耗过大。
4. 案例4
某业务系统,其响应速度很慢,并出现虚拟机进程自动关闭。原因为:该系统需要和外部系统交互,而外部系统响应速度极慢,随着业务量增多,处于等待的线程和socket连接越来越多,进而导致虚拟机崩溃。
5. 案例5
某业务系统,其响应速度很慢。原因为:该系统新生代中有百万个键值对,而这些数据不是朝生夕死的,导致垃圾回收时,在两个Survivor区域内移动消耗时间较多。
4 类加载机制
4.1 类加载时机
1. 类加载定义
虚拟机将类数据从Class文件加载到内存,并对数据进行校验、转换、解析、初始化,形成可以被虚拟机使用的Java类型,这个过程称为类加载,类加载、连接、初始化是程序运行期间完成的。
2. 类生命周期
一个类型,从被加载到虚拟机内存到卸载,其整个生命周期分为7个阶段,如下图所示,其中验证、准备、解析三个部分统称为连接。

3. 类加载时机
类的“加载”时机,由虚拟机自由把握。类的“初始化”时机,在一下6种情况,如果类型未初始化,需触发其初始化,分别为:
① 遇到new、get static、put static、invoke static四种指令;
② 使用java.lang.reflect包的方法对类型进行反射调用;
③ 初始化某个类,如果其父类未初始化,则需要触发其父类初始化;
④ 虚拟机启动时,用户指定执行的主类(包括main方法的类),虚拟机会先初始化该类;
⑤ 使用JDK7的动态语言中某种特殊情况;
⑥ 使用JDK8的某种特殊情况。
4.2 类加载过程
1. 加载
① 通过全限定类名获取类的二进制字节流;
② 将字节流所代表的静态存储结构转化为方法区的运行时数据结构;
③ 在内存中生成该类的java.lang.Class对象,作为方法区该类的访问入口。
2. 验证
① 文件格式验证,检验字节流是否符合Class文件格式的规范;
② 元数据验证,对字节码描述的信息进行语义分析,保证其符合《Java语言规范》;
③ 字节码验证,通过数据流分析和控制流分析,确定程序语义的合法性和逻辑性;
④ 符号引用验证,检验该类是否缺少依赖的外部类、方法和字段等资源。
3. 准备
① 给类中的静态变量分配内存;
② 设置类中成员变量初始值。
4. 解析
① 将常量池内的符号引用替换为直接引用,符号引用是一种描述引用目标的符号,符号可以为任何形式的字面量,直接引用是指向目标的指针、指向目标的相对偏移量、或者是能定位到目标的句柄;
② 类或接口解析,将类中类或者接口的符号引用解析为直接引用;
③ 字段解析,将类中字段的符号引用解析为直接引用;
④ 方法解析,将类中方法的符号引用解析为的直接引用;
⑤ 接口方法解析,将类中接口方法的符号引用解析为的直接引用。
5. 初始化
加载、验证、准备和解析4个阶段,均为虚拟机控制,初始化阶段才执行Java代码,该阶段执行类的构造器方法,即方法,方法是编译生成的。
4.3 类加载器
1. 类与类加载器
① 实现“通过全限定类名获取类二进制字节流”功能的代码即为“类加载器”;
② 对于任意类,由类本身和类加载器确定该类在虚拟机中的唯一性,来源于不同类的实例,类得eauals()、isInstance()等方法不能返回正确结果;
③ 从虚拟机角度看,类加载器分为两种,一为虚拟机自带的启动类加载器,C++实现,二为其他类加载器,Java实现,这种类加载器继承java.lang.ClassLoader;
④ 从开发角度看,JDK1.2以后类加载器分为三种,分别为启动类加载器、扩展类加载器和应用程序类加载器。
2. 双亲委派模型
双亲委派模型,其工作过程为:如果一个类加载器收到类加载请求,首先会把请求委派给父类加载器完成,父类加载器无法完成加载请求时,子类加载器完成加载,因此所有加载请求均会到达启动类加载器。双亲委派模型如下图所示。
双亲委派模型能较好地适配Java中子类、父类的关系,如java.lang.Object是所有类的父类,无论哪个子类加载Object,都是由启动类加载器完成加载,因此可保证不同类加载的Object类是同一个Object类。

3. 类加载过程图解
如下图,类的加载过程。

- - -高效并发- - -
1 Java内存模型与线程
1.1 CPU多级缓存架构
存储设备运算慢,1s执行约106条指令,处理器运算速度快,1s执行约109条指令,引入高速缓存,可提高CPU效率,处理器、高速缓存和主内存关系如下图。
多线程并发时,存在数据一致性问题(缓存一致性协议)。

1.2 Java内存模型
1.2.1 必要性
CPU多级缓存模型是一个规范,基于该规范的实现有很多种。JDK设计了一个JAVA内存模型,可以屏蔽不同操作系统、厂商之间的差异性,实现Java程序跨平台运行(一次编译,到处运行)。
1.2.2 主内存和工作内存
Java内存模型的主要目的是定义程序中各种变量的访问规则,即在虚拟机中把变量存储到内存和从内存中取变量。此处变量定义与Java编码有所区别,它包括实例字段、静态字段和数组对象,但不包括线程私有的局部变量和方法参数。
如下图,在Java内存模型中
① 变量存储在主内存(虚拟机内存的一部分);
② 线程有私有工作内存,工作内存中保存了线程所属变量的主内存副本;
③ 线程在工作内存中读写所属变量;
④ 工作内存中变量私有,线程间传递变量值需通过主内存完成。
此处Java内存模型中工作内存、主内存和Java内存结构中堆、栈、元空间属于不同层次上的划分,两种划分没有联系。若需对应,主内存属于堆中实例数据,工作内存属于虚拟机栈中。

1.2.3 内存操作
关于主内存和工作内存数据交互,Java内存模型定义8种原子操作,分别为:
① lock\锁定,锁定主内存变量;
② unlock\解锁,解锁占有的主内存变量;
③ read\读取,读取主内存变量并传至工作内存;
④ load\载入,将读取到的主内存变量写入工作内存;
⑤ use\使用,虚拟机使用工作内存变量;
⑥ assign\赋值,虚拟机对工作内存变量赋值;
⑦ store\存储,读取工作内存变量并传至主内存;
⑧ write\写入,将读取到的工作内存变量写入主内存。
注意,read、load操作需按顺序执行,但不要求连续执行,store、write操作相同。
对于上述8种操作,Java内存模型中定义8中规则:
① 不允许read和load、store和write单独出现;
② 不允许线程丢弃最近的assign操作,即变量变化后需从工作内存同步到主内存;
③ 不允许线程无原因(无assign)同步工作内存变量到主内存;
④ 新变量在主内存中诞生,不允许在工作内存中使用未初始化(load和assign)的变量;
⑤ 一个变量同一时刻只能被一个线程lock,但可被lock多次,执行相同次数unlock变量才能解锁;
⑥ lock某变量,则工作内存中该变量清空,未load或assign不可use;
⑦ 若变量为lock,则不能unlock;
⑧ unlock变量之前,需将变量同步到主内存。
鉴于8种操作过于复杂,JDK将8种简化为read、write、lock、unlock四种。
1.2.4 原子性、可见性和有序性
1. 原子性
原子性为操作不可分割。Java内存模型保证read、load、use、assign、store、write六种操作的原子性,基本数据类型读写操作具有原子性(long和double除外)。更大范围的原子性可以用lock、unlock实现,这两个操作对应synchronized关键字。
2. 可见性
某线程修改共享变量的值,其他线程能够立即获得,通过volatile、synchronized实现可见性,final也可以。
3. 有序性
有序性可理解为:在线程内观察,所有操作是有序的,即线程内表现为串行,在线程之间观察,所有操作是无序的,即“指令重排序”和“工作内存和主内存同步延迟”。
1.2.5 MESI缓存一致性协议
1. 定义
为解决缓存一致性问题,需设计一种机制,当CPU0修改了共享变量,需通知到CPU1,该机制即为MESI协议,也称缓存一致性协议。根据这套规范,不同计算机厂商具有不同的实现方式。
多核CPU缓存架构通过MESI协议来达到数据一致性,Java内存模型建立在多核CPU高速缓存之上,JAVA内存模型也是通过MESI协议来达到数据一致性。
2. 数据状态
Modified/M: 修改状态,只有一个CPU能独占该状态,当一个CPU的高速缓存数据处于修改状态时,其它CPU均不能操作该数据对应的共享数据,此时高速缓存中的数据发生了更新,需要被刷入主内存中。
Exclusive/E: 独占状态,其权限与修改状态相同。
Share/S:共享状态,当CPU的高速缓存中数据处于共享状态时,其他CPU可对该数据的共享变量进行并发操作。
Invalid/I:无效状态,当高速缓存中数据处于无效状态时,代表该数据不能使用。
3. 编程体现
在编程方面,需使用volatile、synchronized、cas、锁等技术来实现数据一致性。
1.2.6 long、double数据类型非原子协定
Java内存模型中lock、unlock、read、load、assign、use、store、write八种操作具有原子性,但是对于64位数据类型(long和double)有较为宽松的规定,允许虚拟机将未被volatile修饰的64位数据类型分两次进行读写,即允许虚拟机决定是否支持64位数据类型read、load、store、write操作是否具有原子性。
1.2.7 先行发生原则
1. 先行发生定义
先行发生是Java内存模型中定义的两项操作之间的偏序关系,比如操作A先行发生于操作B,则 操作B发生前,操作A的所有影响可被操作B看到,影响包括修改共享变量的值、发送的消息和调用方法。
2. Java内存模型中存在的先行发生
① 程序次序规则,线程内,按照控制流,前面的操作先行发生于后面的操作;
② 管程锁定规则,一个unlock操作先行发生于后面对一个锁的lock操作;
③ volatile变量规则,对volatile变量的写操作先行发生于后面对该变量的读操作;
④ 线程启动规则,Thread对象的start方法先行发生于线程的每一个动作;
⑤ 线程终止规则,线程所有操作先行发生于该线程的终止检测,通过Thread::join()方法是否结束、Thread::isAlive()方法返回值可判断线程是否终止;
⑥ 线程中断规则,线程的interrupt()方法调用先行发生于检测到中断事件的发生,通过Thread::interrupted()方法检测中断发生;
⑦ 对象终结规则,对象初始化结束(构造函数结束)先行发生于finalize()方法开始;
⑧ 传递性,若操作A先行发生于操作B,操作B先行发生于操作C,则操作A先行发生于操作C。
1.3 Java与线程
1.3.1 线程实现
1. 线程概述
① 进程具有独立功能的程序关于数据的运行过程,是资源分配和调度的基本单位。
② 线程是比进程更轻量级的调度执行单位,是CPU调度基本单位,线程引入,可把进程的资源分配和执行调度分开。
③ 线程实现由3种方式,内核线程实现(1:1实现)、用户线程实现(1:N实现)、用户线程加轻量级进程混合实现(N:M实现)。
2. 内核线程实现
内核线程(Kernel-Level Thread,KLT)是由操作系统内核(Kernel)支持的线程,内核通过调度器(Schedule)调度线程,并将线程任务映射到CPU。应用程序一般不直接使用内核线程,而是使用内核线程的高级接口-轻量级进程(Light Weight Process,LWP),LWP即通常意义上讲的线程,LWP与内核线程数量比值为一对一,如下图所示。
LWP局限性,首先,LPR由内核线程实现,其线程创建、同步、销毁和调度需进行系统调用,系统调用需要在用户态(User Mode)和内核态(Kennel Mode)相互切换,调用代价较高。其次,单个LWP需要一个内核线程支撑,因此LWP消耗内核资源,因此内核支撑的LWP数量有限。

3. 用户线程实现
狭义的用户线程(User Thread,UT)指在用户空间线程库上建立的线程,系统内核不能感知这类线程的生命,用户线程创建、同步、销毁和调度不需要进行系统调用,若线程功能得当,则无需进入内核态,其进程与线程数量比值为1:N,如下图所示。
由于操作系统只CPU资源分配到进程,用户线程调度需要应用程序处理,因此存在线程阻塞、多核处理器线程映射等难题。

4. 混合实现
除内核线程实现、用户线程实现之外,将内核线程和用户线程混合使用也可实现线程。线程创建、同步和销毁在用户态完成,通过轻量级进程作为桥梁,使用内核的线程调度和处理器映射,可减少线程阻塞问题。该模式中,用户线程和轻量级进程之间数量比值为N:M,如下图。

5. Java线程实现
主流的Java虚拟机线程模型为基于操作系统的原生线程模型,即1:1线程模型。
1.3.2 线程调度
线程调度,指系统为线程分配处理器使用权的过程。调度方式有两种,分别为协同式和抢占式,Java虚拟机使用抢占式调度方式。协同式方式中,线程执行和线程切换由线程本身控制,其线程执行时间不可控制,单一线程故障可能阻塞进程。抢占式方式中,线程执行和线程切换由系统决定,单一线程故障不会阻塞进程。
线程优先级,Java语言给线程设置了10个级别的优先级,两个处于等待状态得线程,优先级越高越容易被系统执行。但是,线程优先级不是稳定的调节手段,因为Java的线程优先级和各类操作系统的线程优先级并不能一一对应。
1.3.3 状态转换
Java语言定义了6种线程状态,分别是:
① 新建(New):创建后尚未启动的线程属于该状态;
② 运行(Runnable):操作系统中Running和Ready状态的线程属于该状态,即该状态的线程为执行状态或则等待被分配CPU执行时间;
③ 无限期等待(Waiting):该状态的线程不会被分配CPU执行时间,等待被其他线程显式唤醒;
④ 限期等待(Time Waiting):该状态的线程不会被分配CPU执行时间,一定时间后由系统自动唤醒;
⑤ 阻塞(Blocked):线程阻塞,等待获取排它锁,
⑥ 结束(Terminated):线程终止,结束执行。
以上六种状态在特定事件发生时可以互相转换,转换关系如下图:

1.4 Java与协程
内核线程局限性;
协程复苏。
2 线程安全与锁优化
2.1 线程安全
2.1.1 Java中线程安全
线程“安全程度”由强到弱排序,分别为:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立。
1. 不可变
不可变对象一定是线程安全的,例如final关键字修饰的对象。
2. 绝对线程安全
一个类,不管运行时环境如何,调用者都不需要任何同步措施,则该类绝对线程安全,Vector不是绝对线程安全。
3. 相对线程安全
相对线程安全,即为通常意义上的线程安全,若能保证对象单次操作是线程安全的,则调用的时候不需要采取同步手段,对于特定顺序地连续调用,需要在调用端采取同步手段,Vector、HashTable属于该类型。
4. 线程兼容
线程兼容指对象本身不是线程安全的,在调用端采取同步手段可以保证对象在并发环境中安全使用,即通常意义上的线程不安全,ArrayList、HashMap属于该类型。
5. 线程对立
线程对立指不管在调用是否采取同步手段,对象都不能在多线程环境中并发使用,该类型对象很少,。
2.1.2 线程安全实现方法
1. 互斥同步
互斥同步(Mutual Exclusion&Synchronization)是最常见、最主要的并发同步保障手段,互斥是方法,同步是目的。同步指同一时刻只有单一线程访问共享数据,互斥是实现同步的手段,临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore)是常见的互斥实现方式。
synchronized关键字是一种常见的互斥同步手段,JDK5之后提供的Java.util.concurrent.Lock接口也是一种互斥同步手段,重入锁(ReentrantLock)是该接口的一种实现。相比synchronized而言,ReentrantLock具有三个高级功能,分别为:等待可中断、公平锁和锁绑定多个条件。
2. 非阻塞同步
互斥同步是一种阻塞同步,涉及线程阻塞和唤醒,有性能开销。从解决问题方式上看,不管共享数据是否存在竞争,互斥同步都会加锁,存在无效性能开销,是一种悲观并发策略。
随着硬件指令集发展,基于冲突检测的乐观并发策略可以实现线程安全。其原则为:先操作,无冲突则操作成功,有冲突则采取补偿措施,这种同步手段即为非阻塞同步。基于硬件指令的发展,操作+冲突检测也具有原子性,乐观并发同步策略发展起来,这类指令包括:
① 测试并设置(Test-and-Set);
② 获取并增加(Fetch-and-Increment);
③ 交换(Swap);
④ 比较并交换(Compare-and-Swap,简称CAS);
⑤ 加载链接/条件存储(Load-Linked/Store-Conditional,简称LL/SC)。
3. 无同步方案
若某个类,在多线程之间没有共享数据竞争,则不需要采取同步手段。具有这种特征的应用包括:可重入代码、线程本地存储和基于消费队列(生产者:消费者)架构的应用。
2.2 内存屏障
2.2.1 概述
1. 定义
内存屏障是一种特殊指令,这种指令具有屏障作用,可理解为类似关卡,具有隔离的作用。volatile、synchronized均使用内存屏障来实现数据一致性的。
2. 分类
① 一类是强制读取/刷新主内存的内存屏障,分别为Load屏障和Store屏障;
② 另一类是禁止指令重排序的内存屏障,分别为LoadLoad屏障、StoreStore屏障、LoadStore屏障、StoreLoad屏障。
2.2.2 强制读取/刷新主内存的屏障
Load屏障:读取数据前,强制从主内存读取最新的值;
Store屏障:修改数据后,强制刷新回主内存。
2.2.3 禁止指令重排序的屏障
1. LoadLoad屏障
序列:load1指令 LoadLoad屏障 load2指令
作用:在load1和load2之间加上 LoadLoad屏障,则load1和load2不能重排序。
2. StoreStore屏障
序列:store1指令 StoreStore屏障 store2指令
作用:在store1和store2之间加上StoreStore屏障,则store1和store2不能重排序。
3. LoadStore屏障
序列:load1指令 LoadStore屏障 store2指令
作用:在load1和store2之间加上LoadStore屏障,则load1和store2不能重排序。
4. StoreLoad屏障
序列:store1指令 StoreLoad屏障 load2指令/store2指令
作用:在store1和load2之间加上StoreLoad屏障,则store1和load2/store2指令不能重排序。
2.3 volatile
2.3.1 特性
volatile是虚拟机中轻量级同步机制,使用频率不及synchronized。当变量被定义成volatile后,该变量具有两个特性。
① 可见性,即某线程修改该变量的值,其他线程可立即得知,但volatile型变量不是线程安全的;
② 有序性,禁止重排序优化,普通变量仅能保证在方法的执行中所依赖赋值结果的地方能获取到正确结果,不能保证变量的赋值操作和代码中执行顺序一致;
③ 由于volatile仅能保证可见性,在不符合以下两条规则时,需通过加锁(synchronized关键字)保证原子性,规则1为运算结果不依赖当前变量值或者只有单一线程修改变量值,规则2为变量不需要其他状态变量共同参与不变约束。
2.3.2 原理
1. volatile之可见性
volatile修饰的共享变量,线程使用之前会从主内存中重新读取;若共享变量被修改,线程需将修改刷新到主内存。其实现方式为:在读/load操作之前加Load屏障,强制从主内存读取最新的数据,在assign/赋值后加上Store屏障,强制将数据刷新到主内存。
2. volatile之有序性
示例如下,由于指令重排序,线程A先执行initOK = true,httpClient和dataSource未完成,因此线程B提前跳出while循环,使用dataSource.getData时dataSource未完成初始化。若volatile修饰initOK后,底层使用了禁止重排序指令。
线程A的执行代码:
dataSource = initDataSource();
httpClient = initHttpClient();
initOK = true;
线程B的执行代码:
while(!initOK) {}
Object data = dataSource.getData();
httpClient.request(data);
修改线程A的执行代码:
dataSource = initDataSource();
httpClient = initHttpClient();
StoreStore屏障
initOK = true;
StoreLoad 屏障
3. volatile无原子性
若两个线程并发到同一时刻修改变量,则存在数据不一致问题,故无原子性。若需要原子性,落实到底层需进行加锁,在任意时刻只能有一个线程能修改变量。
2.4 synchronized
1. 定义
通过synchronized锁定的代码块或者方法同一时间只能由一个线程去执行。
2. 用法
① 修饰对象方法,如下,锁住的是SyncDemo的实例对象。
public class SynDemo {
int x = 0;
public synchronized void testSync() {
x++;
}
}
② 修饰静态方法,如下,锁的是这个类对应的类对象,也就是SyncDemo.class对象。
public class SynDemo {
static int value = 0;
public synchronized static void testStaticSync() {
value++;
}
}
③ 修饰代码块,如下,锁住的是lockObj对象。
public class SynDemo {
int x = 0;
Object lockObj = new Object();
public void testInnerSync() {
synchronized(lockObj) {
x++;
}
}
}
3. 注意事项
synchronized是对一个对象上锁,使用时需注意对同一个对象上锁。如下所示,threadA和threadB不能互斥,因为threadA锁住的是lock1对象,然而thread锁住的是lock2对象。
public class SynDemo {
int x = 0;
// 争抢对象SyncDemo的锁
public synchronized void testSync() {
x++;
}
static class TestThread extends Thread {
SynDemo lock;
TestThread(SynDemo lock) {
this.lock = lock;
}
@Override
public void run() {
lock.testSync();
}
}
public static void main(String[] args) {
// 锁对象lock1
SynDemo lock1 = new SynDemo();
// 锁对象lock2
SynDemo lock2 = new SynDemo();
TestThread threadA = new TestThread(lock1);
TestThread threadB = new TestThread(lock2);
threadA.start();
threadB.start();
}
}
public static void main(String[] args) {
// 只有一个锁对象lock1
SynDemo lock1 = new SynDemo();
// 两个线程对同一个对象锁进行争抢
TestThread threadA = new TestThread(lock1);
TestThread threadB = new TestThread(lock1);
threadA.start();
threadB.start();
}
2.5 synchronized底层原理
2.5.1 对象布局
对象布局分为三个部分,分别为对象头、实例数据、对齐填充,对象头由Mark Word和一个指向一个类对象的指针组成,实例数据存放实例的属性信息,比如值、对象内存地址等,对齐填充用于补齐,比如JVM对象大小是8字节整数倍,可参考虚拟机章节。
public class Test {
private int a = 8;
private ArrayList list = new ArrayList();
}

2.5.2 Mark Word
Mark Word的结构和各比特位的作用如下图,从图中可知,在重量级锁模式下,对象头中存储了monitor监视器的地址,synchronized加锁基于monitor监视器实现的。

2.5.3 monitor监视器
1. 结构
monitor对象监视器,JVM中每个java对象都有对应的monitor对象,其底层使用C++实现的,monitor是ObjectMonitor类的实例,ObjectMonitor的结构如下,包括:
① _count字段值表示是否加锁;
② _owner字段表示锁拥有者;
③ _WaitSet字段存储调用wait()方法释放锁而挂起的线程;
④ _EntryList字段存储等待加锁的线程;
⑤ _SpinFreq和_SpinClock字段表示自旋功能。
ObjectMonitor() {
_header = NULL;
_count = 0; //锁计数器,_count=0表示未加锁,_count>0表示加锁次数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL; //指向加锁成功的线程 _owner=null表示未加锁
_WaitSet = NULL; //wait线程的集合,在synchorized代码块中调用wait()方法的线程会加入该集合,等待唤醒
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ; //多线程竞争锁进入时的单向链表
_cxq = NULL ;
FreeNext = NULL ; //_owner从该双向循环链表中唤醒线程结点,_EntryList是第一个节点
_EntryList = NULL ; //等待队列,加锁失败的线程会加入该等待队列,等待再次加锁
_SpinFreq = 0 ; //获取锁之前的自旋的次数
_SpinClock = 0 ; //获取之前每次锁自旋的时间
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
2. monitor加锁原理
进入synchronized代码块之前,执行monitorenter指令获取monitor监视器,申请成功则相当于获取到锁,若其他线程持有monitor则等待,执行完执行monitorexit指令释放monitor监视器。

若某个线程获取某个对象的锁,其对象头、Mark Word 和 monitor之间的关系如下图。

3. 自旋优化
① 线程挂起、唤醒代价大,涉及到上下文切换,涉及用户态和内核态的切换;
② 线程A持有锁,线程B获取锁失败时可自旋,有限自旋次数内,若线程A释放锁则线程B获取锁成功,否则挂起。
4. wait和notify
① wait():获取锁之后,挂起线程并释放锁;
② notify():唤醒waitset中一个线程;
③ notifyAll():唤醒waitset中所有线程。
5. wait和sleep
wait()释放锁,Thread.sleep()不释放锁。
2.6 synchronized锁优化
1. 锁重入
持有锁的线程可再次加锁,不会出现锁死现象。
2. 锁消除
不存在竞争的同步代码块,JVM会自动消除该锁,例如内部类。
3. 锁升级
对不同的变量竞争情况,JVM会采取不同的锁,原则为花费最小代价达到并发安全。根据Mark Word中锁标志位,可判断锁类型。
4. 偏向锁
同步代码块第一次被进入(设为线程A),当前为无锁状态,则加指向线程A的偏向锁,同步代码块第N次被进入(设为线程A),若当前为指向线程A的偏向锁状态,则不加锁,直接执行。
5. 偏向锁之重偏向
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A已挂起或者已执行完,则将代码块加指向线程B的偏向锁,偏向锁不释放。
6. 偏向锁升级轻量级锁
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A正在执行,则偏向锁升级为轻量级锁。换言之,偏向锁不具有线程互斥性,同步代码块存在竞争时,偏向锁状态升级为轻量级锁状态。
7. 轻量级锁
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A正在执行,则将线程A暂停,给线程A创建锁记录,复制Mark Word数据到锁记录,将锁记录放入线程A的虚拟机栈中,将锁记录指针存入Mark Word前30位,唤醒线程A,至此偏向锁升级为轻量级锁,线程A持有该同步代码段的轻量级锁。
轻量级锁释放,恢复Mark Word前30位,若恢复成功,即解锁成功。
8. 轻量级锁升级为重量级锁&自旋
线程A持有轻量级锁,线程B自旋等待加锁,若线程B自旋结束未获取到锁,或者线程C加入获取锁,则轻量级锁升级为重量级锁。
9. 重量级锁
线程A持有重量级锁,其他线程加锁则阻塞,线程A解锁后唤醒其他线程竞争锁,重量级锁基于monitor实现,monitor具体细节参考6.3.2章节。
10. synchronized锁优化总结
① synchronized锁升级原则是为了花费最小的代价能达到加锁的目的。
② 无竞争时使用偏向锁,首次执行CAS操作获取偏向锁之后,后面进入同步代码块不重复加锁。
③ 存在线程竞争时偏向锁升级为轻量级锁,轻量级锁的加锁、解锁都需要执行CAS操作,对比偏向锁来说性能低一点,但还是比较轻量级的。为提升线程获取锁的机会,避免线程陷入获取锁失败则阻塞(线程阻塞后再唤醒涉及上下文切换,用户态内核态切换,费时间),故设计自旋等待,线程自旋之后重试获取锁。
④ 当竞争非常激烈,并发很高,或者同步代码块执行耗时较长,则大量线程都在自旋,由于自旋是空耗费CPU资源,自旋一定次数之后,线程挂起,升级为重量级锁。
2.7 synchronized的可见性、有序性、原子性
① 加锁后同一时刻只有一个线程能执行操作,天然具有原子性;
② 可见性是基于屏障指令实现,monitorenter指令、monitorexit指令具有屏障的作用;
③ 有序性同可见性。
3 unsafe
3.1 unsafe概述
1. 概述
unsafe是JDK提供的工具类,包含大量native方法,可调用操作系统底层功能。比如:
① 让操作系统直接分配内存、释放内存;
② 突破java语法限制,从内存中获取对象数据;
③ 调用操作系统的CAS指令;
④ 操作系统层次线程挂起和恢复;
⑤ 提供操作系统级别的内存屏障,读取数据强制走主存,修改数据直接刷新到主存。
2. 内存分配及释放
// 分配bytes大小的堆外内存
public native long allocateMemory(long bytes);
// 从address处开始分配bytes大小的堆外内存
public native long reallocateMemory(long address, long bytes);
// 释放内存块
public native void freeMemory(long address);
// 对指定对象的给定offset偏移量内存块赋值
public native void setMemory(Object o, long offset, long bytes, byte value);
// 对指定内存地址的内存赋值
public native void putLong(long address, long x);
// 获取指定内存地址的long值
public native long getLong(long address);
// 获取指定内存地址的byte值
public native byte getByte(long address);
// 对指定内存adderess地址后面的1个字节赋值
public native void putByte(long address, byte x);
3. 基于CAS的相关操作
public final native boolean compareAndSwapObject( Object o,
long offset,
Object expected,
Object x);
public final native boolean compareAndSwapInt(Object o,
long offset,
int expected,
int x);
public final native boolean compareAndSwapLong( Object o,
long offset,
long expected,
long x);
4. 线程挂起与恢复
//线程挂起
public native void park(boolean isAbsolute, long time);
//线程恢复
public native void unpark(Object thread);
//工具类
public class LockSupport {
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
// 调用park方法将线程挂起
UNSAFE.park(false, 0L);
setBlocker(t, null);
}
public static void unpark(Thread thread) {
if (thread != null)
// 调用unpark方法将线程唤醒
UNSAFE.unpark(thread);
}
}
5. 内存屏障
// 在该方法之前的所有读操作,一定在load屏障之前执行完成
public native void loadFence();
// 在该方法之前的所有写操作,一定在store屏障之前执行完成
public native void storeFence();
// 在该方法之前的所有读写操作,一定在full屏障之前执行完成,这个内存屏障相当于上面两个的合体功能
public native void fullFence();
3.2 CAS的原子性
1. CAS机制
① CAS机制中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B;
② 更新变量时,当变量预期值A和内存地址V中实际值相同时,将内存地址V对应的值修改为B。
2. CAS原理
CAS操作是根据"o对象地址+offset偏移量地址",定位成员变量在内存中的位置,然后操作内存修改数据。CPU不直接读写主存,CAS底层操作,使用锁实现原子性(使用总线技术协调多个CPU加解锁),但是该锁是比较轻量级,不会导致线程挂起。

3. CAS的问题
CAS操作具有原子性,但存在三大问题,分别为:ABA问题、循环时间长开销大、只能保证一个共享变量的原子操作。
3.3 CAS的ABA问题
问题描述:
① 线程1要执行CAS操作前,读取value最新值为A;
② 线程2在这期间将内存value数据修改成B,然后又修改回A;
③ 线程A执行CAS操作时发现值还是A,以为没人修改过value值,执行CAS操作成功。
解决方案:避免ABA问题,可以增加一个维度,比如版本号,每次修改数据版本号则递增1,执行CAS操作时对版本号判断。

4 JUC
4.1 Atomic原子类体系概览
1. 概览
java.util.concurrent提供的原子类底层的实现原理都类似,都是基于volatile和CAS操作来保证线程安全的。

2. AtomicInteger、AtomicLong整型的原子类
Integer、Long是非线程安全的,AtomicInteger、AtomicLong是线程安全的。在统计、计数等场景中有广泛的应用,比如每秒访问的流量、注册中心每秒接收到注册的次数、心跳的次数。
3. AtomicBoolean 布尔类型的原子类
boolean、Boolean是非线程安全的,AtomicBoolean是线程安全的。通常使用在状态标识参数,比如初始化标识、系统关闭标识、逻辑状态判断标识、状态开关等。
此外AtomicBoolean可作为轻量级的锁,比如RocketMQ使用AtomicBoolean封装了自旋锁,具有较高的并发性能。
4. AtomicReference、AtomicStampReference可以封装对象的原子类
AtomicInteger、AtomicLong、AtomicBoolean等是基本类型对应的原子类,对于多个线程共享对象,可使用AtomicReference进行包装,执行CAS修改对象,可达到线程安全。
AtomicStampReference是AtomicReference的升级版本,提供版本号机制,解决CAS中经典的ABA问题。
5. LongAdder原子类
AtomicLong原子类在并发竞争非常激烈时,可能导致大量线程CAS失败而不断自旋。LongAdder采用分段锁的思想,在并发竞争非常激烈的时候使得不同的线程去竞争不同的锁,减少对同一个锁的竞争,优化了并发的性能。
4.2 AtomicInteger&AtomicBoolean
1. AtomicInteger底层原理
AtomicInteger成员变量包括:volatile int value、unsafe类和偏移地址,并发时,volatile变量具有可见性和有序性,基于unsafe类实现的成员方法具有原子性,进而保证线程安全。
public class AtomicInteger extends Number implements java.io.Serializable {
// unsafe对象,可以直接根据内存地址操作数据,可以突破java语法的限制
private static final Unsafe unsafe = Unsafe.getUnsafe();
// 存储实际的值
private volatile int value;
// 存储value属性在AtomicInteger类实例内部的偏移地址
private static final long valueOffset;
static {
try {
// 在类初始化的时候就获取到了value变量在对象内部的偏移地址
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
}
2. AtomicBoolean底层原理
AtomicBoolean采用int变量实现boolean,内部成员变量与AtomicInteger完全一致,其线程安全保障与AtomicInteger相同。
public class AtomicBoolean implements java.io.Serializable {
// unsafe对象,可以直接根据内存地址操作数据,可以突破java语法的限制
private static final Unsafe unsafe = Unsafe.getUnsafe();
// 存储实际的值
private volatile int value;
// 存储value属性在AtomicInteger类实例内部的偏移地址
private static final long valueOffset;
static {
try {
// 在类初始化的时候就获取到了value变量在对象内部的偏移地址
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
}
4.3 AtomicReference&AtomicStampReference
1. 修改多个变量的原子性
如果操作多个变量,且保证该操作具有原子性,单独使用AtomicInteger、AtomicBoolean是不行的。可以使用AtomicReference将多个变量封装为对象,更新对象即为更新多个变量,具有原子性。
2. AtomicReference底层原理
AtomicReference成员变量包括:volatile V value(泛型对象)、unsafe类和偏移地址,并发时,volatile变量具有可见性和有序性,基于unsafe类实现的成员方法具有原子性,通过修改单个对象达到修改多个变量,进而保证线程安全。
public class AtomicReference<V> implements java.io.Serializable {
// unsafe对象
private static final Unsafe unsafe = Unsafe.getUnsafe();
// 一个泛型对象
private volatile V value;
// value对象在AtomicReference内部的偏移量
private static final long valueOffset;
static {
try {
// 获取value相对AtomicReference的内部偏移量
valueOffset = unsafe.objectFieldOffset
(AtomicReference.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
}
3. AtomicStampReference底层原理
与AtomicReference相比,AtomicStampedReference内部增加了成员变量Stamped,就是版本号,也称邮戳。比较的时候同时比较对象的引用和版本号,避免ABA问题。
public class AtomicStampedReference<V> {
// 将当前对象引用和修改的版本号绑定成一个pair对
private static class Pair<T> {
// 对象引用
final T reference;
// 版本号
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
}
4.4 LongAdder
1. 分段锁


如图所示,将锁拆成多段,每个窗口为一段锁,只有被派到同一个窗口的用户存在竞争,使用分段锁大大减少了竞争,提升了并发性能。
2. LongAdder属性
CAS操作,在并发激烈时会产生大量自旋,空耗CPU。LongAdder采用分段锁思想,将热点数据base分离成多个cell,cell独自维护,当前对象实际值为cell值累加,提高了并发性能。其中,LongAdder继承Strimped64。
在低并发时,LongAdder是直接操作base,和AtomicLong性能基本保持一致,高并发时,LongAdder将热点数据分离,统计时如果有并发更新,可能导致统计数据有误差。

4.5 Strimped64
由于LongAdder继承Strimped64,关于Strimped64不做描述。
5 AQS及其实现
5.1 AQS
5.1.1 概述
AQS/AbstractQueuedSynchronizer,也称抽象队列同步器,一种并发工具类的底层框架,实现了同步器功能。
5.1.2 功能
如下图所示一个并发过程,其过程为:
① 线程1去同步器获取资源,即获取锁,获取锁成功直接执行业务方法;
② 线程2获取锁,获取锁失败,进入等待队列,阻塞等待;
③ 当线程1释放锁,唤醒等待锁的线程2,线程2苏醒后继续去获取锁。
其中,红色部分为并发工具同步器应该具有的功能,包括资源、获取失败进行等待队列、释放资源唤醒等待队列线程、线程苏醒重新竞争锁。

获取锁和释放锁由具体的实现类完成,比如:ReentrantLock、CountDownLatch、Semaphore等使用了AQS框架,实现了获取锁、释放锁的具体逻辑,形成了不同的同步器/并发工具。

5.1.3 底层原理
1. 内部结构
① 定义资源,volatile int state表示资源;
② 声明获取独占资源方法acquire()、释放独占资源方法release();
③ 声明获取共享资源方法acquireShared()、释放共享资源方法releaseShared();
④ 定义Node,存储线程信息,多个Node形成双向链表的等待队列,链表存储获取锁失败的线程;
⑤ 封装线程获取资源失败进入等待队列、释放资源后唤醒等待队列中线程再次竞争资源的机制;
⑥ 注:AQS内部,使用volatile定义资源,使用CAS操作来操作等待队列,保证线程安全。

2. 资源定义
同步工具内存在一个线程访问的资源,通过资源状态可以控制多线程并发时的行为(比如通过是否获取锁控制线程的行为),AQS中,volatile int state即为该资源。实现类中state的使用规则由子类决定。比如:
① ReentrantLock中,state表示互斥锁状态,state=0表示未被加锁,state>0表示已被加锁;
② Semaphore中,state表示信号量个数,state>0表示有信号量,线程可获取,state=0表示无信号量,获取信号量需等待。

3. 获取资源&释放资源入口规定
① accquire(int arg):获取独占锁入口;
② acquireInterruptibly(int arg):获取独占锁入口,允许中断,线程中断后抛出异常;
③ release(int arg):释放独占锁的入口。

① acquireShare(int arg):获取共享锁入口;
② acquireShareInterruptibly(int arg) :获取共享锁的入口,允许中断的,线程中断后抛出异常;
③ releaseShare(int arg):释放共享锁入口。

子类若要实现独占锁,需继承AQS并重写tryAcquire()、tryRelease(),若要实现共享锁,需继承AQS并重写tryAcquireShared()、tryReleaseShared(),acquire()、release()、acquireShared()、releaseShared()作为入口提供外层调用。

4. 加锁模板流程
acquire()、acquireShared()源码如下,可以发现,AQS采用模板方法的设计模式,定义一套模板流程,所有调用都走同一流程。而在不同的并发工具中,获取资源由子类实现,分别为tryAcquire方法和acquireShared方法。
public final void acquire(int arg) {
if (!tryAcquire(arg) && // 1.调用子类的tryAcquire方法实际上争抢资源
// 2.如果争抢资源失败则执行addWait方法
// 3.如果争抢资源失败则执行acquireQueue方法
acquireQueued(
addWaiter(Node.EXCLUSIVE), arg)
)
selfInterrupt();
}
public final void acquireShared(int arg) {
// 1.调用子类的tryAcquireShared方法去获取共享锁
if (tryAcquireShared(arg) < 0)
// 2.获取失败则走到模板方法的第二个流程
doAcquireShared(arg);
}
5. 加锁失败机制
① AQS定义了两个数据结构,分别为Node节点和等待队列,等待队列为Node构成的双向列表;
② AQS规定了一套机制,当线程获取锁失败后,将线程信息封装在Node节点中,Node节点信息包含线程信息、锁信息、线程当前状态等;
③ 将Node节点放入等待队列尾部,让线程等待;
④ 对于等待队列设计了一套机制,规定了等待队列中那个节点可以重试获取锁,以及共享锁在等待队列中传播等。
6. Node节点
static final class Node {
// 共享锁模式,表示这个节点的线程要获取的是共享锁
static final Node SHARED = new Node();
// 共享锁模式,表示这个节点的线程要获取的是共享锁
static final Node EXCLUSIVE = null;
// 节点状态,CANCELLED表示被取消
static final int CANCELLED = 1;
// SINGAL节点,表示下一个节点等待自己唤醒
static final int SIGNAL = -1;
// 处于CONDTION模式
static final int CONDITION = -2;
// 处于共享锁的传播模式
static final int PROPAGATE = -3;
volatile int waitStatus;
// 前一个等待节点
volatile Node prev;
// 后一个等待节点
volatile Node next;
// 表示当前节点的线程
volatile Thread thread;
// 表示下一个在等待Condition条件的节点
Node nextWaiter;
}
其中,waitStatus节点表示等待状态,其状态值包括以下4种,可知,waitStatus<0表示该节点处于有效状态,waitStatus>0 表示该节点处于无效状态。
① CANCELLED(1):表示当前节点的线程加锁超时或者中断,处于该状态的节点不再获取锁;
② SIGNAL(-1):表示后继节点需要当前节点唤醒;
③ CONDITION(-2):表示当前节点正在等待一个Condition条件;
④ PROPAGATE(-3):表示当前为传播模式,在获取共享锁时,如果资源有剩余需唤醒后续节点。
7. 等待队列
等待队列的结构如下:

结合acquire()、tryAcquire()和等待队列,基于AQS实现的同步器获取锁失败流程如下图。其过程为:
① 线程根据AQS提供的acquire()获取独占锁;
② acquire()调用子类的tryAcquire()获取锁,获取锁成功直接返回;
③ 获取锁失败,则将当前线程封装成Node节点,放入等待队列中等待。
④ 注意,AQS规定,头结点必须是一个不需要等待锁的节点,可为空节点。

8. Condition沉睡唤醒机制
AQS提供了类似wait、notify的机制,该机制通过Condition来实现的。condition的await()类似Object对象wait(),让线程沉睡等待;condition的singal()类似Object对象notify(),随机唤醒一个等待的线程,singalAll()类似于notifyAll(),唤醒所有等待的线程。

5.2 AQS互斥锁
5.2.1 获取锁
互斥锁获取包括以下方法:acquire()、tryAcquire()、addWaiter()、enq()、acquireQueued()、shouldParkAfterFailAcquire()、parkAndCheckInterrupt()、cancelAcquire()等。其中:acquire()为入口,tryAcquire()实际获取锁,addWaiter()将线程封装成Node节点并加入等待队列,acquireQueued()控制线程再次获取锁。
public final void acquire(int arg) {
// 1.调用子类的tryAcquire方法,去获取锁
if (!tryAcquire(arg) &&
// 2.获取资源失败调用addWaiter方法插入等待队列
// 3.然后调用acquireQueued方法在队列实现阻塞或者再去获取锁
acquireQueued(
addWaiter(Node.EXCLUSIVE),
arg)
)
selfInterrupt();
}
5.2.2 释放锁
互斥锁释放锁包括以下方法:release()、tryRelease()、unparkSuccessor()等。其中:release()为入口,tryRelease()实际释放锁,unparkSuccessor()唤醒下一节点。
public final boolean release(int arg) {
// 1. 首先进来直接调用子类的tryRelease方法去释放锁
if (tryRelease(arg)) {
// 2. 如果释放锁成功,去到head头结点,然后去
// 唤醒head节点的下一个节点
Node h = head;
if (h != null && h.waitStatus != 0)
// 这里就是唤醒h节点的下一个节点的实际方法
unparkSuccessor(h);
return true;
}
return false;
}
5.3 AQS共享锁
5.3.1 获取锁
AQS共享锁获取锁包括以下方法源码:acquireShared()、tryAcquireShared()、doAcquireShared()、addWaiter()、setHeadAndPropagate()、shouldParkAfterFailedAcquire()等。其中:acquireShared()为入口,tryAcquireShared()实际获取锁,doAcquireShared()控制线程获取锁失败加入等待队列和再次获取锁、setHeadAndPropagate()用于共享锁传播。
public final void acquireShared(int arg) {
// 1. acquireShared < 0 表示获取共享锁失败
if (tryAcquireShared(arg) < 0)
// 2. 然后进入doAcquireShared方法
doAcquireShared(arg);
}
5.3.2 释放锁
AQS共享锁释放锁包括以下方法源码:releaseShared()、tryReleaseShared()、doReleaseShared()等。其中:releaseShared()为入口,tryReleaseShared()实际释放锁,doReleaseShared()唤醒下一节点并传播共享锁。
public final boolean releaseShared(int arg) {
// 1. 调用子类的tryReleaseShared方法,实际去释放资源
if (tryReleaseShared(arg)) {
// 2. 释放资源之后竟然是调用这个,我们上面刚刚讲过,哈哈
// 3. 这里其实本质上就是传播资源,继续唤醒后面的节点来竞争资源
// 这里刚刚讲解过,理解起来应该是简单了
doReleaseShared();
return true;
}
return false;
}
5.4 ReentrantLock可重入互斥锁
5.4.1 ReentrantLock锁基本原理
1. 概述
① ReentrantLock是基于AQS来实现的可重入互斥锁;
② ReentrantLock实现了Lock接口,实现了锁的语义;
③ ReentrantLock提供两种锁模式,公平锁和非公平锁,默认是非公平锁;
④ ReentrantLock基于AQS的Condition机制,控制线程的沉睡和唤醒。
2. ReentrantLock结构
ReentrantLock有Sync内部类,Sync继承AQS,同时Sync有两子类,分别是NonfairSync非公平锁、FairSync公平锁。ReentrantLock其实是基于公平锁和非公平锁之做了封装。

3. 公平锁FairSync之获取锁
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 这里的acquire方法其实就是AQS的acquire方法
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 判断资源是否有人加锁,c == 0 没人加锁,c > 0 表示有人加锁了
int c = getState();
// c == 0 表示没人加锁
if (c == 0) {
// hasQueuedPrecessors这里时判断AQS的等待队列是否有人在等待
// 其实公平锁和非公平锁实现的精髓就在这里,
// 公平锁如果发现AQS中等待队列有人在等待,那么直接去排队,即时资源时空的也不争抢
if (!hasQueuedPredecessors() &&
// 如果AQS队列没线程在排队,则CAS开始争抢锁
compareAndSetState(0, acquires)) {
// 争抢成功则设置加锁的线程时自己
setExclusiveOwnerThread(current);
return true;
}
}
// 如果上面 c > 0 说明有人加锁了
// 这里就获取当前加锁的线程是谁,如果加锁的竟然是自己,则直接重入
else if (current == getExclusiveOwnerThread()) {
// 之前加锁的是自己,现在直接重入,修改加锁的次数就好了
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
分析源码可知ReentrantLock公平锁加锁步骤为:
① 调用ReentrantLock公平锁lock(),lock()调用AQS的acquire(),进而调用子类tryAcquire()实际获取锁;
② tryAcquire()逻辑为:判断c==0,若c=0则资源为空,判断等待队列是否有线程,有线程则假如队列尾部等待,没线程则加锁。若c>0则存在线程已加锁,则加锁线程是否为本身,若为本身则修改加锁次数,不是本身则加锁失败。
③ 若tryAcquire加锁失败,调用AQS的addWaiter()进入等待队列,然后调用acquireQueued()自旋并尝试获取锁或者将自己挂起,等待别人唤醒。

4. 公平锁FairSync之释放锁
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
// 1. 这里会调用子类的tryRelease方法,实际去释放锁
if (tryRelease(arg)) {
Node h = head;
// 2. 释放锁成功,唤醒后续AQS等待队列中等待的线程
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
// 直接讲释放锁的次数减少releases次
// 也就是你加锁多少次,就释放多少
// 当state == 0 的时候说明锁已经空闲了,没人持有了
int c = getState() - releases;
// 这里释放之前判断之前是不是自己加锁的
// 如果自己之前没加锁,不能胡乱释放,直接抛出异常
// 谁加的锁,谁才能释放
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 当c == 0 说明锁已经完全释放了
if (c == 0) {
free = true;
// 设置加锁的线程为null,表示没人加锁了
setExclusiveOwnerThread(null);
}
// 设置state = 0,锁空闲了,让别的线程可以加锁
setState(c);
// free = true表示锁释放了,完全空闲了
return free;
}
分析源码可知ReentrantLock公平锁释放锁步骤为:
① 调用到AQS的release(),进而调用子类tryRelease()释放锁;
② tryRelease()释放锁时候判断身份,只有加锁线程有权释放锁。扣减加锁次数,当state加锁次数被扣减为零时,则为完全释放锁,设置加锁线程为null,即无线程加锁。
③ 释放后,调用AQS的unparkSuccessor()唤醒等待队列中等待的线程。

5. 非公平锁NonFairSync之获取锁
final void lock() {
// 这里上来就直接尝试加锁,不管资源是不是空的,不管有没有人在等待
// 这哥们不讲武德啊,上来就抢
if (compareAndSetState(0, 1))
// 抢夺成功之后,设置是自己加锁,然后就完事了
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
final boolean nonfairTryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取资源state的值,state > 0 表示已经有人加锁了
// state = 0表示没人加锁,锁是空闲的
int c = getState();
// 如果c == 0 没人加锁,马上就去竞争锁,不管有没有人在等待
if (c == 0) {
// CAS尝试竞争锁
if (compareAndSetState(0, acquires)) {
// 加锁成功,设置加锁的线程是自己,
// 这里的setExclusiveOwnerThread就是设置时哪个线程加锁的
setExclusiveOwnerThread(current);
return true;
}
}
// 如果上面c != 0 ,说明有人加锁了;这里判断之前加锁的线程是不是自己
// 如果是自己的话,直接就重入,直接把自己加锁的次数增加就可以了
// 如果不是自己加锁,说明是别人加锁了,此时就需要进入AQS的等待队列等待
else if (current == getExclusiveOwnerThread()) {
// 加锁的时自己,直接增加自己加锁的次数就可以
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
分析源码可知ReentrantLock非公平锁加锁步骤为:
① 调用lock(),执行compareAndSetState(0,1)尝试加锁,不管是否已有线程加锁,不管等待队列中是否存在等待线程;
② 加锁失败则调用AQS的acquire();
③ acquire()调用子类tryAcquire(),进而调用NonfairSync的tryAcquire()实际获取锁;
④ tryAcquire()调用到Sync的nonFairTryAcquire();
⑤ 注:非公平锁nonFairTryAcquire()和公平锁tryAcquire()相似。
6. 非公平锁NonFairSync之释放锁
释放锁,公平锁和非公平锁完全一致。
7. 非公平锁和公平锁总结
两种锁的区别在于获取锁的时候判断等待队列有没有线程,公平锁在等待队列有线程时加入等待对垒,非公平锁则直接去加锁。
5.4.2 ReentrantLock的Condition机制
1. 概述
condition中,await()和singal()用来实现线程沉睡和唤醒,控制线程的行为。与synchronized类似,wait()、notify()是在synchronized代码块中使用的,即在获取锁之后才能调用,condition使用是在获取锁之后。
2. await
public final void await() throws InterruptedException {
// 如果线程被中断了,直接抛出中断异常
if (Thread.interrupted())
throw new InterruptedException();
// 当前线程封装成Node节点,加入condition队列里面
// 注意:这里是Condition队列,而不是AQS获取锁的等待队列,注意
Node node = addConditionWaiter();
// 这里是释放锁,完全释放锁资源,将state归于0
int savedState = fullyRelease(node);
int interruptMode = 0;
// 如果Node节点不在AQS获取锁的等待队列,这里一般都不会在
while (!isOnSyncQueue(node)) {
// 直接将线程挂起,让线程沉睡
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// 走到这里说明有别的线程调用Condition.singal方法将你唤醒了
// 这里这里调用AQS的acquireQueue方法,这个方法的作用之前讲过了
// 就是将你放入AQS的等待队列里面,重新等待获取锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
// 这里就是删除一下无效的condition队列节点
unlinkCancelledWaiters();
if (interruptMode != 0)
// 由于等待时间可能太久了,被中断了
reportInterruptAfterWait(interruptMode);
}
分析源码可知await()方法挂起线程的步骤为:
① 调用addConditionWaiter(),将当前线程封装成Node加入Condition队列,注意不是AQS等待锁的等待队列;
② 加入Condition队列后,调用fullyRelease完全释放锁,将state资源置为0;
③ 调用isOnSyncQueue()判断当前线程是否在AQS等待队列,如果当前线程在AQS等待队列,则等待获取锁;
④ 若不在则调用LockSupport.park()挂起线程,等待被singal()或者singalAll()唤醒;
⑤ 唤醒后加入AQS等待队列,排队等待锁。

3. Condition队列
AQS内部有两个队列,一个是AQS等待队列,是双向链表,另一个是Condition队列,是单向链表,用到Condition机制时会创建该队列。

4. addConditionWaiter
private Node addConditionWaiter() {
// 获取Condition队列的尾结点
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
// 如果Condition队列中已经有些节点的线程因为超时或者中断原因被取消了
// 这里的unlinkCancelledWaiters方法就是删除哪些无效的节点
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
// 创建一个Node节点
Node node = new Node(Thread.currentThread(), Node.CONDITION);
// 下面就是把node插入condition队列的尾部了
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
分析addConditionWaiter的过程为:获取Condition队列尾节点,将当前线程封装成Node节点,插入Condtion队列的尾部。结合Condition队列,await()实现线程挂起过程如下图。

5. singal
public final void signal() {
// 首先判断一下自己是不是拥有独占锁
// 没有独占锁,不能调用singal方法,会抛出异常
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
// 获取Condition队列的头结点firstWaiter
Node first = firstWaiter;
if (first != null)
// 调用doSingal方法去唤醒
doSignal(first);
}
private void doSignal(Node first) {
do {
// 这里的逻辑就是从头往后遍历Condition链表
// 找到一个节点不是null的,然后调用唤醒,就那么简单
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
// 这里的实际唤醒逻辑在transferForSingal方法里面
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
从Condition队列里头节点开始唤醒节点,唤醒之前会插入AQS等待队列并等待获取锁,然后调用LockSupport.unpark()唤醒线程。

6. await和singal总结图解

5.5 CountDownLatch门闩
1. 概述
CountDownLatch类似有多道锁的门闩,创建时可指定锁数量。假如某门闩 CountDownLatch latch = new CountDownLatch(2),则该门闩有2道锁,当latch==0则门闩5道锁都解开,门闩打开。
调用await()时,检查l门闩是否打开,若打开则不会被阻塞,否则线程被阻塞。调用countDown()时,会去掉一道锁,比如latch为2时,则需调用2次countDown()才能去掉所有锁,打开门闩。

2. CountDownLatch结构
CountDownLatch有内部类Sync,Sync继承自AQS,重写了tryAcquireShared()、tryReleaseShared(),是一个共享锁,CountDownLatch是基于内部的Sync做了一层封装。

3. 构造函数
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
4. await
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// AQS这里调用子类的tryAcquireShared方法
// 如果返回结果大于0,继续执行业务代码
// 如果返回结果小于0,则调用doAcquireSharedInterruptibly进入AQS等待队列阻塞等待
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
await()逻辑,调用子类tryAcquireShard()获取资源。当state==0表示门闩已打开,继续执行业务代码。当state!=0表示门闩有锁,调用AQS的doAcquireShardInterruptibly()进入AQS等待队列进行等待,门闩打开后线程被唤醒。
5. countDown
public void countDown() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
// 调用子类的tryReleaseShared方法,释放锁
if (tryReleaseShared(arg)) {
// 如果锁完全释放了,就唤醒等待队列中沉睡的线程
doReleaseShared();
return true;
}
return false;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
// 如果state == 0,也就是锁的数量等于0,表示门闩打开了
if (c == 0)
return false;
// 这里就是将state - 1,也就是将门闩上锁的数量减少一道
int nextc = c-1;
// CAS操作重新设置锁的数量
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
调用AQS的releaseShared(1),将state值减少1,表示将锁数量减少一道。当state==0的时候,表示门闩已经打开,调用AQS的doReleaseShared()将等待队列的线程唤醒。

5.6 CyclicBarrier栅栏
1. 概述
CyclicBarrier计数器栅栏,比如CyclicBarrier barrier = new CyclicBarrier(3)表示栅栏有3道锁。调用一次barrier.await()减少一道锁,清除3道锁则栅栏打开,栅栏打开后唤醒等待的线程,放行一次后重新关闭,恢复了3道锁,周而复始。

2. CyclicBarrier内部结构
public class CyclicBarrier {
// 内部类,批次
private static class Generation {
boolean broken = false;
}
// 注意:这里有一个ReentrantLock,说明CyclicBarrier的是基于ReentrantLock实现的
private final ReentrantLock lock = new ReentrantLock();
// 这里有一个condition trip,说明CyclicBarrier的实现依赖Condition
private final Condition trip = lock.newCondition();
// 这里就是栅栏上面有多少道锁,初始化栅栏是多少,这里的parties就是多少
private final int parties;
// 这里有个任务,就是栅栏开启的时候,如果这个任务不是null,则会执行这个任务
private final Runnable barrierCommand;
// 批次,栅栏再次关闭之后会进入下一个批次
private Generation generation = new Generation();
// 栅栏上面还有多少道锁,比如最开始有3道锁,现在只有1到锁,这时count=1
private int count;
}
分析源码可知,CyclicBarrier中包含:
① ReentrantLock,调用await()时获取锁;
② Condition,实现await()和notify();
③ 表示栅栏的锁数量;
④ 表示栅栏的剩余锁数量;
⑤ 栅栏打开后,需换一个批次,重复使用。
3. await
public int await() throws InterruptedException, BrokenBarrierException {
try {
// 这里调用了内部的dowait方法
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
// 看这里,非常关键,进来第一步,首先是获取一个锁
final ReentrantLock lock = this.lock;
// 获取锁,获取成功之后才能往后走
lock.lock();
try {
// 获取当前自己属于哪个批次
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
// 看到这里,就是将剩余锁数量减少1道,即--count
int index = --count;
// 如果锁剩余数量为0,说明栅栏打开了
if (index == 0) { // tripped
boolean ranAction = false;
try {
// 传入的任务是不是null,如果不是运行一下任务
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
// 到这里,就是换一个批次,会唤醒沉睡队列的线程
// 这里会调用condition.singalAll唤醒沉睡队列的线程
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// 走到这里,说明上面的锁剩余数量index > 0
for (;;) {
try {
if (!timed)
// 看这里,发现锁数量大于0,直接调用condition的await方法沉睡了
// 等待栅栏打开的时候调用condition.singalAll将它唤醒
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
// 走到这里,发现自己属于上一个批次,跟当前批次generation不等
// 直接就返回index了
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
// 释放锁
lock.unlock();
}
}
await()逻辑包括:执行ReentrantLock的lock()获取锁,栅栏减少一道锁。栅栏剩余锁数量大于0,说明栅栏没打开,则调用Condition的await(),进入沉睡队列等待。若剩余锁数量为0,则调用nextGeneration()唤醒等待线程,并生成下一批次。


4. nextGeneration
private void nextGeneration() {
// 唤醒上面因为调用condition.await方法而进入沉睡队列的线程1、线程2
trip.signalAll();
// 重新设置栅栏上锁的数量count = parties
count = parties;
// 进入下一个批次了
generation = new Generation();
}
调用trip.singalAll()即Condtion.singalAll()唤醒沉睡队列中的线程,重新设置栅栏锁数量,然后生成下一批次。
5.7 Semaphore信号量
1. 概述
Semaphore信号量,类似高速进站口,用来控制并发中同一时刻执行的线程数量,可以用做限流器或流程控制器。

Semaphore有公平和非公平两种模式,分别为内部类FairSync、内部类NonfairSync,这两类均继承Sync,Sync继承自AQS。Semaphore实现思路和ReentrantLock相似,内部类结构也相同,不同的是Semaphore是共享锁,支持多个线程同时操作,而ReentrantLock是互斥锁,同一时刻只允许一个线程操作。

2. 构造函数
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
// 如果传递fair为true,构造公平模式,否则构造非公平模式
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
3. 公平模式信号量之获取
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
分析源码可知,acquire()用来获取信号量,定义了一个模板流程:
① 调用子类tryAcquireShared()获取共享锁,即获取信号量;
② 如果获取信号量成功,即返回值大于等于0,则直接返回;
③ 如果获取失败,返回值小于0,则调用AQS的doAcquireSharedInterruptibly(),进入AQS等待队列,等待资源释放之后重新获取。
④ acquire()中,除子类tryAcquireShared()为子类实现外,其他均使用AQS模板方法。

protected int tryAcquireShared(int acquires) {
for (;;) {
// 这里作为公平模式,首先判断一下AQS等待队列里面
// 有没有人在等待获取信号量,如果有人排队了,自己就不去获取了
if (hasQueuedPredecessors())
return -1;
// 获取剩余的信号量资源
int available = getState();
// 剩余资源减去我需要的资源,是否小于0
// 如果小于0则说明资源不够了
// 如果大于等于0,说明资源是足够我使用的
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
分析源码可知,tryAcquireShared()用来实际获取信号量,其步骤为:
① 首先判断AQS等待队列中是否有线程,如果有则排队;
② 如果没有线程,则获取当前剩余信号量available,然后减去所需信号量acquires,得到减去后结果remaining;
③ 如果remaining小于0,直接返回remaining,说明资源不够,获取失败,进入AQS等待队列等待;
④ 如果remaining大于等于0,则执行CAS操作compareAndSetState竞争资源,如果成功则说明获取信号量成功,如果失败则进入AQS等待队列。

4. 公平模式信号量之release
public void release() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
// 1. 调用子类的tryReleaseShared释放资源
if (tryReleaseShared(arg)) {
// 释放资源成功,调用doReleaseShared唤醒等待队列中等待资源的线程
doReleaseShared();
return true;
}
return false;
}
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
// 这里就是将释放的信号量资源加回去而已
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
// 尝试CAS设置资源,成功直接返回,失败则进入下一循环重试
if (compareAndSetState(current, next))
return true;
}
}
分析源码可知,release()步骤为:
① 调用子类tryReleaseShared()释放资源,即释放信号量;
② 如果释放成功则调用doReleaseShared唤醒AQS中等待线程,如果释放失败,返回小于等于0,直接返回。

4. 非公平模式信号量
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
// 上面公平模式需要看下等待队列是否有人
// 这里是直接去尝试获取资源啊,根本不管是否有人
int remaining = available - acquires;
if (remaining < 0 ||
// 如果remaining剩余资源 >= 0 则执行CAS操作
compareAndSetState(available, remaining))
return remaining;
}
}
非公平模式NonfairSync跟公平模式唯一区别是tryAcquireShared实现不同,分析源码可知:
① 对比公平模式信号量,需要判断AQS等待队列是否有线程在等待,而非公平模式不关注等待队列;
② 如果剩余可用资源remaining >= 0,则直接CAS去争抢资源,成功则返回,失败则重试。
5.8 ReentrantReadWriteLock可重入读写锁
5.8.1 概述
ReentrantReadwriteLock同时封装读锁和写锁,分别为ReadLock、WriteLock。并发操作时,读读不互斥,读写、写写互斥。读写锁的主要特点是通过读读操作不互斥,来减少锁的冲突,提升并发的性能。
5.8.2 底层原理
1. 内部结构
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
// 读锁
private final ReentrantReadWriteLock.ReadLock readerLock;
// 写锁
private final ReentrantReadWriteLock.WriteLock writerLock;
// 同步器,读锁、写锁都是基于这个同步器来进行封装的
final Sync sync;
}
ReentrantReadWriteLock中有读锁readLock、写锁writeLock和抽象同步器Sync,锁逻辑都是封装在Sync,ReadLock、WriteLock是对Sync进行了封装。内部类和ReentrantLock、Semaphore类似,有公平锁FairSync、非公平锁NonfairSync,并且都是继承自Sync,而Sync又继承了AQS,底层都是基于AQS来实现的。

2. 构造函数
public ReentrantReadWriteLock() {
this(false);
}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
3. int类型的32位数字同时表示写锁和读锁
ReentrantReadWriteLock使用int类型数字同时表示读锁、写锁,int类型数字是4个字节,即32bit,其中高16位表示读锁,低16位表示写锁。

Sync类内部属性如下:
abstract static class Sync extends AbstractQueuedSynchronizer {
// 共享锁(读锁)的偏移量16位
static final int SHARED_SHIFT = 16;
// 共享锁的单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 共享锁的最大个数,2的16次方-1 = 65535
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 独占锁掩码,65535,转化为二进制为 0000 0000 0000 0000 1111 1111 1111 1111
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 这里使用位运算,计算出当前共享锁的个数
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
// 这里使用位运算,计算出当前独占锁的个数
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
}
4. 读锁数量计算
static int sharedCount(int c) {
// 这里的SHARD_SHIFT就是16
// 就是将c进行无服务右移16位,得到读锁个数
return c >>> SHARED_SHIFT;
}
读锁数量计算方式,直接将int类型数字无符号右移16位。使用高16位表示读锁,所以读锁最大数量为:216-1=65535。

5. 写锁数量计算
static int exclusiveCount(int c) {
// 只需要于写锁掩码 0000 0000 0000 0000 1111 1111 1111 1111
// 进行按位 & 运算即可
return c & EXCLUSIVE_MASK;
}
写锁数量计算方式,计算int类型的数字中低16位的结果,即需要保留低16位的值,高16位全部置为0;

5.8.3 写锁底层原理
1. lock
public void lock() {
sync.acquire(1);
}
public final void acquire(int arg) {
// 流程1,进来先调用子类的tryAcquire,这里才是实际上获取资源的实现方法
// 如果返回false表示获取锁失败,true表示获取锁成功
if (!tryAcquire(arg) &&
// 流程2,获取资源失败,则调用addWaiter将当前线程加入AQS的等待队列
// 流程3,调用acquireQueue方法在AQS等待队列中沉睡,或者再次尝试获取锁
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
① 调用子类tryAcquire获取锁,true则获取锁成功,false则获取锁失败;
② 获取资源失败,则调用addWaiter将当前线程加入AQS的等待队列;
③ 调用acquireQueue()在AQS等待队列中沉睡,或者再次尝试获取锁。

2. tryAcquire
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
Thread current = Thread.currentThread();
// 获取当前读写锁的状态state
int c = getState();
// 计算写锁的加锁次数,上一章节讲过此方法,保留低16位的值便是写锁个数
int w = exclusiveCount(c);
// 如果c!=0,说明有别人加了写锁,或者加了读锁
if (c != 0) {
// 1.如果w==0写锁个数为零,说明上面加的锁是读锁,2.当前线程不是获取写锁的线程
// 这里的意思就是,1.有人加了读锁 2.有人加了写锁,但是加锁的人不是自己,读写、写写互斥,那么自己加锁失败
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 走到这里说明w!=0,且current==getExclusiveOwnerThread()说明之前加写锁的人是自己
// 这里只需要进行重复,增加加锁次数就可以了
// 同时判断写锁次数最多可以加锁65535次,是否都用完了
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// 重新设置加锁的次数
setState(c + acquires);
// 加锁成功返回true
return true;
}
// 走到这里,c == 0 说明读锁、写锁都没有人加
// writeShouldBlock这里是有公平锁FairSync、非公平锁NonfairSync两种实现
// 公平锁这里判断AQS等待队列是否有线程在等待,有则不去获取锁,自己也去等待
// 非公屏锁这里直接去尝试获取锁,不管AQS等待队列是否有线程在等待
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
// 走到这里,加锁成功,设置加锁线程为自己
setExclusiveOwnerThread(current);
// 返回加锁成功
return true;
}
公平模式就是判断AQS等待队列是否有等待线程,如果有则不允许加锁,需要加入等待队列;非公平模式不管等待队列是否有线程,直接获取锁。加锁需要执行CAS操作争抢,如果成功则设置加锁线程是自己,设置加锁次数等,失败则直接返回false。


3. unlock
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
// 流程1,直接调用子类的tryRelease方法释放锁
if (tryRelease(arg)) {
Node h = head;
// 流程2,返回true释放成功,唤醒AQS中后一个正在等待的线程
if (h != null && h.waitStatus != 0)
// 唤醒头节点后一个正在等待锁的线程
unparkSuccessor(h);
return true;
}
return false;
}
① 调用子类的tryRelease方法释放锁,返回true释放成功,false失败;
② 如果释放成功,则调用unparkSuccessor唤醒后继节点。
4. tryRelease
protected final boolean tryRelease(int releases) {
// 这里校验一下,持有锁的是否是当前线程
// 只允许持有锁的线程释放锁,否则是非法操作
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
// 这里释放的逻辑就是将加锁的次数减少而已
int nextc = getState() - releases;
// 计算释放后的写锁加锁次数,如果写锁的加锁次数为0了,那么说明完全释放了
boolean free = exclusiveCount(nextc) == 0;
// 如果写锁完全释放了,则设置加锁的线程为null,也就是没人加锁
if (free)
setExclusiveOwnerThread(null);
// 重写设置锁变量
setState(nextc);
return free;
}
① 判断加锁线程是否为当前线程,如果不是自己加锁,则不允许释放,抛出异常;
② 扣减写锁次数,判断扣减之后写锁次数是否为0,为0说明完全释放,则设置一下加锁线程为null;
③ 如果释放锁成功,则调用AQS的unparkSuccessor唤醒后续在等待的节点。

5.8.4 读锁底层原理
1. lock
public void lock() {
//调用sync的acquireShared()方法,也还是进入了AQS的acquireShared方法了
sync.acquireShared(1);
}
public final void acquireShared(int arg) {
// 1.调用子类Sync的tryAcquireShared方法
// 2. 如果获取读锁失败,则调用doAcquireShared进入等待队列等待
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
① 调用子类tryAcquireShard()获取读锁;
② 如果获取读锁成功则直接返回,否则获取失败并调用doAcquireShared()进入等待队列。
2. tryAcquireShred
protected final int tryAcquireShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
// 获取state变量的值
int c = getState();
// 计算写锁的次数,如果写锁次数非0,且加写锁的不是自己
// 说明别人加了写锁,自己这时候获取读锁失败,返回-1
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
// 计算一下读锁的个数
int r = sharedCount(c);
// 调用readerShouldBolck,判断是否是公平锁,是否允许加锁
if (!readerShouldBlock() &&
// 读锁个数r < 65535,说明读锁个数还剩余
r < MAX_COUNT &&
// 执行cas尝试加读锁
compareAndSetState(c, c + SHARED_UNIT)) {
// 如果r == 0,说明自己是第一个加读锁的线程
if (r == 0) {
// 记录一些第一个加读锁线程
firstReader = current;
// 第一个加锁线程加锁次数为1
firstReaderHoldCount = 1;
}
// 如果自己是第一个加读锁的线程,说明之前加锁过了
// 直接修改一下次数即可
else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
// 从ThreadLocal中获取下当前线程加锁的次数
cachedHoldCounter = rh = readHolds.get();
// 如果当前线程第一次加锁,设置一下ThreadLocal
else if (rh.count == 0)
readHolds.set(rh);
// 当前线程加锁次数加1即可
rh.count++;
}
return 1;
}
// 如果上面CAS操作加锁失败了,进入这个兜底方法
return fullTryAcquireShared(current);
}
① 获取锁记录变量state;
② 计算写锁个数,如果写锁个数非零,并且获取写锁不是当前线程,由于读写互斥,获取读锁失败;
③ 如果写锁个数为零,或者当前线程已获取写锁,则继续;
④ 根据锁模式、等待队列情况判断是否允许加锁,不允许则获取锁失败,进入兜底加锁机制;
⑤ 判断读锁加锁次数是否达到上限,达到上限则进入兜底加锁机制,未达上限则执行获取读锁,加锁失败则进入兜底加锁机制;
⑥ 若加锁成功,则获取当前加读锁次数,将加读锁次数加1。

3. fullTryAcquireShared
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
// 在for循环中,不断重试,知道有结果
for (;;) {
// 获取读写锁的变量state
int c = getState();
// 如果有写锁,并且加锁不是自己
// 说明别人加了写锁,读写互斥,直接返回失败
if (exclusiveCount(c) != 0) {
if (getExclusiveOwnerThread() != current)
return -1;
// 根据公平、非公平模式、等待队列等判断是否应该被阻塞
} else if (readerShouldBlock()) {
// 如果被阻塞
// 第一个加读锁的线程是自己,啥也不干
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
} else {
if (rh == null) {
// 自己不是第一个加读锁的线程
// 则获取一下自己加读锁的次数
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) {
rh = readHolds.get();
// 如果加读锁的次数是0,从ThreadLocal从移除
if (rh.count == 0)
readHolds.remove();
}
}
// 加读锁次数是0此,此时有应该阻塞,直接返回加锁失败
if (rh.count == 0)
return -1;
}
}
// 如果读锁次数已达上限,抛出异常
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// cas操作尝试加锁,如果cas加锁成功,进入下面的逻辑
if (compareAndSetState(c, c + SHARED_UNIT)) {
// 如果自己是第一个加锁的线程,设置一下第一个加锁的人是当前线程
if (sharedCount(c) == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
// 第一个加锁的线程是自己,将自己加锁次数+1即可
firstReaderHoldCount++;
} else {
// 这里的操作不外乎就是从ThreadLocal从取出自己加锁的次数,然后将次数+1即可
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
// 加锁成功,返回1
return 1;
}
}
}
① 获取读写锁状态state,如果有其他加写锁,由于读写互斥,则直接加读锁失败;
② 如果没有其他线程加写锁,结合公平锁、非公平所、等待队列判断是否应该被阻塞;
③ 如果应该被阻塞,且自己加读锁次数count == 0,则返回-1,加锁失败;
④ 如果是当前线程是第一个加读锁的线程,则继续尝试获取读锁,进入for循环重试;
⑤ 如果不应该被阻塞,判断加锁次数是否达到上限,如果达到上限,直接抛出异常;
⑥ 如果读锁次数还有剩余,直接CAS操作尝试加锁,加锁失败则进入for循环重试;
⑦ 如果加锁成功,则从ThreadLocal中取出之前加锁次数,然后将加锁次数+1,最后返回1,表示本次操作加锁成功。

4. unlock
public void unlock() {
// 调用的还是Sync同步器的releaseShared方法,也就是AQS的releaseShared方法
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
// 1. 直接调用到子类的tryReleaseShared方法释放共享锁
if (tryReleaseShared(arg)) {
// 2. 如果共享锁释放成功,将共享资源传播,唤醒等待队列的后续节点线程
doReleaseShared();
return true;
}
return false;
}
① 调用tryReleaseShared()实际释放共享锁;
② 如果释放成功,则调用AQS的doReleaseShared()唤醒等待队列中的线程,进行共享锁资源的传播。
5. tryReleaseShared
protected final boolean tryReleaseShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
// 将当前线程加锁次数-1
if (firstReader == current) {
// 如果之前只是加了一次锁,那么就释放锁了
if (firstReaderHoldCount == 1)
firstReader = null;
else
// 如果加了多次锁,锁的次数减少1
firstReaderHoldCount--;
} else {
// 这里的逻辑,就是将ThreadLocal中自己存储的加锁次数减少1而已
// 没啥特殊的地方
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
// 然后这里就是执行CAS减少加锁的次数,直到成功为止
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
// cas修改读写锁变量state,将读锁次数-1
// 注意由于使用高16位表示读锁,所以单位值SHARED_UNIT
if (compareAndSetState(c, nextc))
// 判断读锁的个数是否为0,如果为0说明读锁完全释放了
return nextc == 0;
}
}
① 判断当前线程是否为首个加锁线程,即current==firstReaderHoldCount,首个加读锁线程加锁次数存在firstReaderHoldCount,后续加锁线程加锁次数存在ThreadLocal;
② 如果当前线程为首个加锁线程,扣减firstReaderHolderCount次数,如果扣为零,则将firstReaderHolderCount置为null;
③ 如果不是首个加锁线程,从ThreadLocal中取出加锁次数,然后次数扣减1;如果加锁次数为零,从ThreadLocal中移除,否则还继续保存在ThreadLocal;
④ 执行CAS操作修改state读写锁状态变量,由于是高16位表示读锁,所以读锁每减少1,则state减少65536;
⑤ 重复CAS操作,直到成功为止,判断读锁个数是否为0,则读锁完全释放返回1,否则返回-1。

5.9 并发工具总结
① AQS,AQS资源定义、获取资源入口、释放资源入口,AQS模板机制,竞争资源进入等待队列、释放资源后唤醒等待队列的线程;
② ReentrantLock底层原理,基于AQS实现独占锁,公平锁和非公平锁锁,如何使用Condition的沉睡和唤醒机制,类似wait、notify;
③ CountDownLatch底层原理,基于AQS实现门闩功能;
④ CyclicBarrier底层原理,基于ReentrantLock和Condition实现栅栏功能;
⑤ Semaphore底层原理,基于AQS提供共享锁机制实现信号量限流器功能;
⑥ ReentrantReadWriteLock读写锁底层原理,32位数字如何同时表示读锁和写锁,读锁和写锁个数计算,读锁和写锁,读写、写写互斥、读读共享。
6 并发数据结构
6.1 CopyOnWriteArrayList
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
// 这个互斥可重入锁,用来保证多线程并发修改时候的线程安全
final transient ReentrantLock lock = new ReentrantLock();
// 使用volatile修饰的Object数组,数组是用来保存数据的
// 而volatile可以保证可见性和有序性,一旦array这个引用发生改变,其它线程立即可见
private transient volatile Object[] array;
// 获取保存数据的底层数组引用
final Object[] getArray() {
return array;
}
// 设置保存数据的底层数组
final void setArray(Object[] a) {
array = a;
}
}
由ReentrantLock、Condition、volatile Object[]实现并发安全,有1把锁。
6.2 BlockingQueue
BlockingQueue,阻塞队列,其api比较灵活,在队列满/空时,线程存/取数据时可阻塞,可不阻塞直接返回失败,可在一定时间内阻塞,超时返回失败。JDK中,BlockingQueue的实现类有7种,分别为:
① LinkedBlockingQueue 基于链表的无界阻塞队列(默认无界);
② ArrayBlockingQueue 基于数组的有界阻塞队列;
③ DelayQueue 使用优先级队列实现的延迟无界阻塞队列;
④ SynchronousQueue 不存储元素的阻塞队列;
⑤ PriorityBlockingQueue 支持优先级排序的无界阻塞队列;
⑥ LinkedTransferQueue 由链表结构组成的无界阻塞队列;
⑦ LinkedBlockingDeque 由链表结构组成的双向阻塞队列。

6.3 LinkedBlockingQueue
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private static final long serialVersionUID = -6903933977591709194L;
// 阻塞队列内部是使用链表存储数据的
// 这个Node就是链表的节点
static class Node<E> {
// 节点存储的值
E item;
// 指向的下一个节点
Node<E> next;
// 构造函数
Node(E x) { item = x; }
}
// 阻塞队列的容量,默认不传是Integer.MAX_INTEGER
private final int capacity;
// 阻塞队列内部的元素个数,也就是当前队列的大小
private final AtomicInteger count = new AtomicInteger();
// 阻塞队列的头节点
transient Node<E> head;
// 阻塞队列的尾节点
private transient Node<E> last;
// 阻塞队列内部有两把锁,分别为putLock和takeLock,就是你上面图说的那两把锁
// putLock:将数据放入阻塞队列的时候需要加putLock,这里就是插入锁
private final ReentrantLock takeLock = new ReentrantLock();
// Condition等待条件:notEmpty表示非空条件
// 当阻塞队列为空时,notEmpty非空 条件不满足
// 这个时候从阻塞队列取数据的线程就会被阻塞等待
private final Condition notEmpty = takeLock.newCondition();
// 阻塞队列内部有两把锁,分别为putLock和takeLock
// putLock:将数据放入阻塞队列的时候需要加putLock
private final ReentrantLock putLock = new ReentrantLock();
// Condition 等待条件:notFull表示 “容量未满”条件
// 当阻塞队列容量满了,放不下新的元素,此时notFull条件不满足
// 这个时候将数据放入阻塞队列的线程就会被阻塞住,等待notFull条件满足
private final Condition notFull = putLock.newCondition();
}
由ReentrantLock、Condition、Node链表实现并发安全,有2把锁。

6.4 ArrayBlockingQueue
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private static final long serialVersionUID = -817911632652898426L;
// 队列数组,这里使用数组来存储数据
// 提示:ArrayBlockingQueue使用环形数组来存储数据和取出数据
final Object[] items;
// 这里是当前取到数组的第几个位置,初始化是0
int takeIndex;
// 这里是插入到数组的第几个位置,初始化是0
int putIndex;
// 当前阻塞队列的大小,具有多少个元素
int count;
// 锁,注意这里与LinkedBlockingQueue不同
// 这里只有一把锁,插入的时候和拉取数据的时候都是使用这同一把锁
final ReentrantLock lock;
// 取数据的等待条件,队列非空
private final Condition notEmpty;
// 插入数据的等待条件,队列未满
private final Condition notFull;
}
由ReentrantLock、Condition、Object[]实现并发安全,有1把锁。

6.5 DelayQueue
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {
// 锁,保证并发安全性,结合Condition实现阻塞、唤醒机制
private final transient ReentrantLock lock = new ReentrantLock();
// 优先级队列,这个队列就是存储延迟元素的容器
// 延迟元素E按照延迟时间作为优先级存储在PriorityQueue优先级队列中
// 延迟时间小的存放在队列前面,延迟时间大的存在队列后面
private final PriorityQueue<E> q = new PriorityQueue<E>();
// leader线程(第一个等待获取数据的线程)
private Thread leader = null;
// 等待条件,如果没有可取元素,则会调用available.await方法阻塞等待
private final Condition available = lock.newCondition();
}
① DelayQueue没有容量限制,是一个无界队列,可用作延迟任务调度和定时任务调度;
② 使用PriorityQueue优先级队列存储延迟元素,延迟时间作为优先级,时间越小优先级越高,越排在前面;
③ 使用ReentrantLock互斥锁,获取数据和添加数据需加锁,添加数据后自动排序;
④ 如果PriorityQueue队列最前面的元素,延迟时间大于当前时间,则没有可取元素,需要阻塞等待。

6.6 SynchronousQueue
① SynchronousQueue同步队列,使用场景较少,主要用来做线程间数据同步;
② SynchronousQueue队列没有存储数据的容器,数据传输需手递手传递,即生产者必须亲手传递给消费者;
③ 生产者和消费者必须一一匹配,生产者/消费者传递数据时,若无对应消费者/生产者,则需进入等待队列阻塞等待,并由对方唤醒。
6.7 HashMap
6.7.1 底层原理
JDK1.8之前,HashMap结构为数组+链表,JDK1.8以后,HashMap结构为数组+链表+红黑树,其数据存储过程如下:
① 计算key的hash值,对hash值取模,得到该key在数组中存储位置;
② 如图黄色部分,数组此位置未存储元素,无hash冲突,直接存储在该位置;
③ 如图红色部分,若存在hash冲突,则使用链表解决hash冲突,新元素放在链表末尾;
④ 如图蓝色部分,若hash冲突较多,使用链表查询数据时间复杂度为O(n),当链表节点大于8,为提高查询性能,可将链表转为红黑树,其查询性能为O(logN)。

6.7.2 源码分析
1. 关键属性
// 默认的初始化容量16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
// 负载因子0.75,比如数组的长度是16,当数组里元素的个数打到了数组大小的这个0.75比率,
// 也就是12个的时候,就会进行数组的扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表红黑树化的条件,长度是8
static final int TREEIFY_THRESHOLD = 8;
// 非树化的添加,长度小于等于6
static final int UNTREEIFY_THRESHOLD = 6;
// 数化之前的最小容量必须打到64,否则优先进行扩容而不是进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
// HashMap内部的基础数组,HashMap是使用数组+聊表+红黑树的方式来存储数据
transient Node<K,V>[] table;
2. 构造方法
public HashMap() {
// 默认构造函数,只是初始化了一个负载因子,其它啥都没干
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
// 设置容量的构造方法
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 设置容量和负载因子的构造方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 容量不可超过最大允许值 MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 调用tableSizeFor方法,根据传入的容量再进行一轮计算,算出应该分配的容量多少
this.threshold = tableSizeFor(initialCapacity);
}
3. tableSizeFor
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
取靠近cap的2N的结果,且结果不大于MAXIMUM_CAPACITY,比如cap为7返回8,cap为13返回16。
4. put
public V put(K key, V value) {
// 1. 首先使用hash(key)方法进行hash计算得到一个hash值
// 2. 然后在调用putVal方法插入元素
return putVal(hash(key), key, value, false, true);
}
5. hash
static final int hash(Object key) {
int h;
// 1. 如果key == null直接返回0,这也就是为啥HashMap能使用null作为key的原因
// 2. (h = key.hashCode()) 获取key的hashCode保存在h变量中
// 3. h ^ (h >>> 16) 这个代码的意思是将一个32位的高16位和低16位进行异或运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
函数计算逻辑为,高16位不变,低16位变成高16位和低16位的异或结果,其目的让高16位和低16位都参与hash值运算,减少hash冲突。
6. putValue
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 加入此时table数组是null,获取数组长度是0,说明还没进行初始化,需要先进行数组的初始化
if ((tab = table) == null || (n = tab.length) == 0)
// 进行数组的初始化
n = (tab = resize()).length;
// n 为数组的长度,当n为2的x次方时候(n - 1) & hash 的结果与 hash % n 相等
// 这也就是为什么数组的长度要是2的x次方的原因,使用 & 位运算 代替 % 取模运算提高性能
if ((p = tab[i = (n - 1) & hash]) == null)
// 这里根据(n-1) & hash定位到数组的i位元素
// 如果tab[i] == null,说明之前此下标的数组没存储过元素,直接将k、v存储在此数组位置即可
tab[i] = newNode(hash, key, value, null);
else {
// 当tab[i] != null,走到这里,说明存在hash冲突
Node<K,V> e; K k;
// 判断一下此节点的Key和传入的Key是否一样,如果一样,直接替换value的值即可
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果p节点是一个红黑树,按照红黑树的方式插入或者替换一个节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 走到这里说明p是一个链表,使用链表的方式插入或者替换一个节点
// 这里从链表头结点开始遍历整个链表
for (int binCount = 0; ; ++binCount) {
// 这里是走到链表的尾部,未发现该链表的任何节点的Key与传入的key一致
// 说明需要新插入一个节点
if ((e = p.next) == null) {
// 这里就是新插入一个节点
p.next = newNode(hash, key, value, null);
// 如果插入一个节点后,该链表长度达到了8,需要将链表转化成红黑树,提升搜索性能
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 这里就是遍历链表过程中发现有节点的Key跟传入的Key一直
// 此时直接替换该节点的Value值即可
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
// 获取修改前旧节点的value值,返回旧的值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// modCount记录HashMap修改的次数,每次put方法之后修改次数自增1
++modCount;
// size表示HashMap中元素个数,threshould表示HashMap扩容的阈值
// 插入元素之后size > threshould表示达到扩容阈值了,此时HashMap触发扩容操作
if (++size > threshold)
// 进行扩容
resize();
//
afterNodeInsertion(evict);
return null;
}
① 检查基础数组table是否为空,若为空则初始化数组;
② 根据寻址算法(n-1)&hash,即hash%n,定位到数组位置tab[i],若tab[i]无元素,则将数据存储在tab[i];
③ 若tab[i]!=null,则存在hash冲突,判断tab[i]节点是链表或红黑树;
④ 若为红黑树,则调用putTreeVal遍历红黑树,查找是否有Key与传入Key一致,有则替换该节点Value值,无则插入新节点;
⑤ 若为链表,则遍历链表,查找是否有Key与传入Key一致,有则替换该节点Value,无则在尾部插入新节点;
⑥ 插入新节点后,判断链表长度是否达到8,是则将链表转成红黑树,提高查询效率;
⑦ 插入新节点后,HashMap的size自增1,判断size>threshould是否成立,即判断是否达到扩容阈值,是则调用resize()扩容。

7. resize
final Node<K,V>[] resize() {
// 获取内部的基础数组
Node<K,V>[] oldTab = table;
// 获取旧数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 扩容的阈值
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果当前数组长度已经MAXIMUM_CAPACITY,说明数组长度非常大了
if (oldCap >= MAXIMUM_CAPACITY) {
// 此时再进行扩容,直接就赋予Integer的最大长度
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 扩容一倍之后长度 < MAXIMUM_CAPACITY 且大于初始化长度
// 那么此种情况,基础数组长度扩容一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 走到这里说明oldCap == 0,oldThr > 0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// 走到这里说明oldCap == 0 && oldThr == 0,此时就是设置长度为初始化长度
// 也就是16
newCap = DEFAULT_INITIAL_CAPACITY;
// 新的达到扩容的阈值为 长度 * 负载因子 = 长度 * 0.75
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果扩容阈值为0,需要重新计算
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
// 计算扩容阈值,结合容量限制等情况
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 赋值扩容阈值
threshold = newThr;
// 新创建一个基础数组,长度为上面的新容量长度newCap
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 这里就是数据的移动了,将旧数组移动到扩容后的新数组上去
if (oldTab != null) {
// 遍历整个数组的每个位置
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 获取oldTab[j] 位置元素,赋值给e
if ((e = oldTab[j]) != null) {
// 将旧数组此位置引用置位null,方便进行垃圾回收
oldTab[j] = null;
// 如果e == null,说明此位置是一个单元素,既不是链表也不是红黑树
if (e.next == null)
// 这种情况就好办,直接使用寻址算法移动到新数组上即可
newTab[e.hash & (newCap - 1)] = e;
// 如果是一个红黑树
else if (e instanceof TreeNode)
// 调用split方法将红黑树拆散移动到新数组上
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 如果是一个链表,则执行一下方式进行数据移动
else { // preserve order
// 这里是先生成两个链表
// 链表lo的头节点是loHead,尾节点是loTail
Node<K,V> loHead = null, loTail = null;
// 链表hi的头结点是hiHead,尾节点是hiTail
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 如果旧链表上元素Key.hash & oldCap == 0
// 则将此节点放入到链表lo中
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 如果旧链表上元素Key.hash & oldCap != 0
// 则将次节点放入hi链表中
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 上面就将旧数组tab[j]位置的链表平均拆成了两个聊表lo和hi
// 新数组的newTab[j]位置存放lo链表
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 新数组的newTab[j+oldCap]位置存放链表hi
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
① 计算需要扩容的容量为newCap;
② 创建新数组,数组长度为newCap;
③ 遍历旧数组,迁移数据到新数组;
④ 若旧数组tab[j]是元素,则直接移动到新数组,新数组位置为(newCap-1)&hash;
⑤ 若旧数组tab[j]是链表,则分拆链表为lo链表和hi链表,链表元素hash&oldCap==0则移至lo链表,hash&oldCap=0则移至hi链表;
⑥ lo链表存至新数组newTable[j],hi链表存至newTable[j+oldCap];
⑦ 若旧数组tab[j]是红黑树,则分拆红黑树为两链表,方式与分拆链表相同,判断链表长度是否大于等于8,是则转将链表为红黑树;
⑧ 按照上述方式迁移旧数组每个元素,扩容即完成。

6.8 ConcurrentHashMap
1. 内部关键属性
// 最大容量上限,2的30次方
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的初始化容量16
private static final int DEFAULT_CAPACITY = 16;
// 最大的数组长度上限
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 默认并发能力层级,16
// (默认数组长度是16,每个数组元素都可作为一把锁,所以数组长度是多少默认就有多少把锁)
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 负载因子
private static final float LOAD_FACTOR = 0.75f;
// 红黑树转化条件(链表长度达到8需要转成红黑树,提高查询效率)
static final int TREEIFY_THRESHOLD = 8;
// 非树化条件(红黑树大小小于等于6时候,需要将红黑树转成链表)
static final int UNTREEIFY_THRESHOLD = 6;
// 红黑树化前最小容量(如果当前容量小于64,首先考虑扩容减少hash冲突,而不是进行树化)
static final int MIN_TREEIFY_CAPACITY = 64;
private static final int MIN_TRANSFER_STRIDE = 16;
private static int RESIZE_STAMP_BITS = 16;
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 标志位,说明当前正在扩容操作,该位置数据正在移动,也就是move(移动)的意思
static final int MOVED = -1;
// 标志位,说明改位置的数据正在进行树化
static final int TREEBIN = -2;
// 保留位置
static final int RESERVED = -3;
// 进行hash算法的时候,保留多少位hash结果,这里是保留int类型中的后31位
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// 当前机器的cpu核数
static final int NCPU = Runtime.getRuntime().availableProcessors();
// 保存数据的基础数组,使用volatile修饰,保证多线程之间的可见性
transient volatile Node<K,V>[] table;
// 扩容期间的另外一个数组,ConcurrentHashMap扩容期间两个数组都在使用
private transient volatile Node<K,V>[] nextTable;
// 用作大小统计的基础窗口
// ConcurrentHashMap使用多窗口分段锁机制来进行数量统计,提高并发性能
private transient volatile long baseCount;
// 一个标志位,用作数组初始化或者扩容期间的标识
private transient volatile int sizeCtl;
// 扩容期间,下一个需要进行数组迁移的数组下标
private transient volatile int transferIndex;
private transient volatile int cellsBusy;
// 窗口列表,用多窗口机制来减少锁冲突,提高高并发的计数统计性能
private transient volatile CounterCell[] counterCells;
2. put
public V put(K key, V value) {
// 内部调用putVal方法
return putVal(key, value, false);
}
3. putVal
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 使用spread函数,得出一个新的hash值
// 跟上一章节讲的HashMap的hash函数核心思想一样
// 低16位结果变为高低16位的异或值
int hash = spread(key.hashCode());
int binCount = 0;
// 使用一个无限循环,知道putVal操作成功才退出
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果基础数组为空或者长度为零,说明还未初始化
if (tab == null || (n = tab.length) == 0)
// 首先进行数组的初始化
tab = initTable();
// 走到这里说明table数组已经初始化了,肯定不为空
// 根据寻址算法 (n-1)&hash 找到数组的table[i]位置
// 如果table[i] == null说明该位置之前没存储元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 创建一个新的Node节点,使用cas操作将node设置到table[i]位置
// cas保证原子性,由于table使用volatile关键字修饰,保证可见性、有序性;所以是并发安全的
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
// cas成功则退出循环,否则继续
break;
}
// 如果f=table[i]的hash值被标记为MOVED,说明当前正在进行扩容
else if ((fh = f.hash) == MOVED)
// 则当前线程帮助进行扩容(多线程扩容,缩短扩容时间)
// 扩容完成之后再进行重试
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 注意这里使用的synchronized进行加锁,加锁的元素是f=table[i]
// 加锁的是数组的一个元素,通过寻址算法落到哪个位置,就对哪个位置进行加锁
// 保证并发安全的同时,加锁粒度很小,只要并发操作hash冲突不大,锁冲突就不大
// 这里就是分段锁的思想了,table数组的每个元素都可以作为一把锁
// 并发操作时,hash冲突时候才会存在锁竞争
synchronized (f) {
// tabAt获取table[i]位置元素,二次确认此Node对象是否还是原来哪个,没被修改过
if (tabAt(tab, i) == f) {
// fh=f.hash >= 0 说明未扩容或者红黑树化
// 在扩容或者初始化的时候会把table[i]所在元素的hash改为小于0
// 表示正在进行扩容、移动数据、进行树化等操作
if (fh >= 0) {
binCount = 1;
// 这里就跟之前HashMap一样,就是从头遍历链表
// 一个个查找节点是否Key与传入一样,如果一样则替换value值即可
// 如果不一样,则在链表尾部插入一个新的节点
// 由于使用了synchronized,是并发安全的
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果f节点是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 对红黑树进行遍历,如果有节点Key与传入key一直,则替换value值即可
// 否则需要插入一个新的节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 达到了树化条件,table[i]位置的链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 这里使用并发多窗口分段统计的思想,进行计数统计
addCount(1L, binCount);
return null;
}
① 调用initTable()初始化数组,该方法线程安全;
② helpTransfer()支持多线程扩容,支持并发安全;
③ 加锁粒度是f=table[i], synchronized(f),对具体元素加锁,加锁粒度小;
④ 操作成功后,若新增元素,调用addCount()使用分段锁思想,进行数量统计,减少所冲突,提升性能。

4. initTable
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// 无限循环,直到成功才退出
while ((tab = table) == null || tab.length == 0) {
// sizeCtl初始值是0,使用volatile修饰保证可见性、有序性
// 第一个进行初始化的线程会将sizeCtl使用cas操作设置为-1
// 后面第二、第三个线程发现sizeCtl < 0 发现已经有线程在进行初始化操作了
// 自己就不需要操作了,直接等待初始化完成即可
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 走到这里,发现自己是第一个初始化的人,设置sizeCtl初始化标志位-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 这里就没啥好说的了,就是初始化一个数组出来
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 初始化好数组之后,sc代表下一次扩容的阈值,默认是12
sc = n - (n >>> 2);
}
} finally {
// 由于此时只有一个线程有操作权限,是线程安全的,直接修改即可
// 设置下次扩容的阈值为sc,也就是12
sizeCtl = sc;
}
break;
}
}
return tab;
}
① 首个扩容的线程设置sizeCtl为-1,由于使用volatile修饰,保证可见性;
② 其他线程读取sizeCtl,若为-1,说明正在初始化,等待即可;
③ 初始化操作即为创建一个长度为DEFAULT_CAPACITY的数组。
5. 分段锁
如图所示,将锁拆成多段,每个窗口为一段锁,只有被派到同一个窗口的用户存在竞争,使用分段锁大大减少了竞争,提升了并发性能。
6. addCount
private final void addCount(long x, int check) {
// as就是备用窗口列表
CounterCell[] as; long b, s;
// 如果备用窗口列表不为空,或者在基础窗口竞争失败,则取备用窗口列表操作
if ((as = counterCells) != null ||
// 这里的意思是基础窗口竞争失败
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
// 这里就是从备用窗口列表选一个备用窗口,进行操作了
// 原理跟LongAdder基本一致的,这里就不详细分析了
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 这里就是将基础窗口的数量+所有备用窗口的数量,得到容量总和
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// 这里判断容量 s > sizeCtl,也就是达到了扩容阈值,需要进行扩容操作
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
// 发现sizeCtl说明有线程正在进行扩容
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 进行扩容的方法
// 其它线程走到这里,也会取帮助进行扩容,多线程一起扩容
transfer(tab, nt);
}
// 走到这里说明sizeCtl >= 0,说明自己是第一个执行扩容的线程
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 真正进行扩容的方法
transfer(tab, null);
s = sumCount();
}
}
}
7. sumCount
final long sumCount() {
// counterCells是备用窗口列表
CounterCell[] as = counterCells; CounterCell a;
// baseCount就是基础窗口的数量
long sum = baseCount;
// 这里就是将基础窗口数量 + 所有备用窗口的数量,就得到总数量了
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
8. get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 老规矩,计算一下hash码
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
// 使用寻址算法,得到自己应该去数组的那个位置找
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果头节点就是自己找的元素,直接返回就好
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果eh < 0,说明正在迁移到新数组,此时就是链表形式
else if (eh < 0)
// 调用e.find方法遍历链表的方式查找
return (p = e.find(h, key)) != null ? p.val : null;
// 如果还在旧数组,遍历查找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
6.9 ThreadLocal
1. 概述
ThreadLocal,线程可存储独有的数据,线程之间是隔离的,可在线程的不同方法之间实现透传,比如先set()某值,再执行其他操作,最后get()可取出该值。
2. 线程的threadLocals
public class Thread implements Runnable {
// 线程名
private volatile String name;
// 线程优先级
private int priority;
// 线程运行的任务
private Runnable target;
// 线程组
private ThreadGroup group;
// 线程内部定义的数据结构ThreadLocalMap
// 这里说明每个线程内部都有一个ThreadLocalMap数据结构
ThreadLocal.ThreadLocalMap threadLocals = null;
}

3. set
public void set(T value) {
// 1. 首先获取当前操作的线程t
Thread t = Thread.currentThread();
// 2. 根据当前线程取到一个ThreadLocalMap的数据结构
ThreadLocalMap map = getMap(t);
// 3. 如果map不为空,说明这个map结构初始化好了,可以正常存储数据
if (map != null)
// 这里注意,具体的数据是存储在ThreadLocalMap这个数据结构里面的
// 注意key是this,也就是ThreadLocal对象本身,value值就是我们存储的数据
map.set(this, value);
else
// 如果map为空,说明map未初始化,需要创建ThreadLocalMap初始化,并且将value值存储进去
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
// 这里让人很惊讶,竟然是将当前线程的t的threadLocals属性直接返回了
// 说明每个线程t内部都有一个ThreadLocalMap的数据结构
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
// 1.首先创建一个ThreadLocalMap对象出来,并且使用ThreadLocal对象作为key,value就是我们要存储的值
// 2. 然后将key,value的映射存储在ThreadLocalMap这个Map数据结构中
// 3.然后就是为当前线程对象t的threadLocals属性赋值为刚创建出来的map
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
4. get
public T get() {
// 获取当前线程对象t
Thread t = Thread.currentThread();
// 获取线程对象t内部的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 如果map不为空,从map中查找数据
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 走到这里说明map为null,执行初始化,跟set方法流程差不多
return setInitialValue();
}
5. remove
public void remove() {
// 这里就很简单明了,直接获取当前线程对象内部的ThreadLocalMap对象
ThreadLocalMap m = getMap(Thread.currentThread());
// 如果m不为空,执行remove操作
if (m != null)
m.remove(this);
}
6. 操作总结
① ThreadLocal内部定义ThreadLocalMap,类型Map;
② 线程Thread内部有threadLocals,即每个线程有ThreadLocalMap数据结构;
③ 用户不能操作线程内部threadLocals,需通过ThreadLocal对象获取,执行set、get、remove方法,操作线程内部的threadLocals对象,能确保线程安全。

7. 内存泄漏
ThreadLocalMap中的数据,key是threadLocal对象,value是存入的值,threadLocal对象是static修饰的静态变量,不会被虚拟机回收。若大量数据未被remove(),会导致内存泄露。
7 线程池
7.1 线程池概述
1. ThreadPoolExecutor
public class ThreadPoolDemo {
public static ExecutorService createThreadPool() {
// 创建一个线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(
// 核心线程数设置为2
2,
// 最大线程数设置为5
5,
// 当线程池中的线程数量大于2,这多出的线程在没有任务执行的最大空闲时间,60
60,
// 空闲时间的单位,这里设置秒
TimeUnit.SECONDS,
// 线程池的阻塞队列使用LinkedBlockingQueue无界阻塞队列
new LinkedBlockingQueue(),
// 创建线程的线程工厂,这里test-pool是设置这个线程池的名字
new DefaultThreadFactory("test-pool"),
// 当任务太多,线程池线程不足、阻塞队列满时候采取什么拒绝策略
new ThreadPoolExecutor.CallerRunsPolicy()
);
// 返回创建的线程池
return executor;
}
public static void main(String[] args) {
// 创建一个线程池
ExecutorService executor = createThreadPool();
for (int i = 0; i < 1000; i++) {
final int num = i;
// 封装任务,每个任务就是打印自己是当前第几个号
Runnable task = () -> {
System.out.println(num);
};
// 往线程池提交任务
executor.execute(task);
}
}
}
① createThreadPool()创建个线程池;
② 有1000个任务,每个任务打印当前序号;
③ 封装1000个任务,调用execute()提交1000个任务。
④ ThreadPoolExecutor线程池,该线程池提交任务后,若有线程资源空闲会立即执行任务。
2. ScheduledThreadPoolExecutor
public class ScheduledThreadPoolDemo {
// 创建一个调度线程池
public static ScheduledExecutorService createThreadPool() {
ScheduledExecutorService executor = new ScheduledThreadPoolExecutor(
// 线程池的核心线程数,配置为3
3,
// 创建线程的工厂,test-schedule-pool为线程池的名称
new DefaultThreadFactory("test-schedule-pool"),
// 任务拒绝策略,线程资源不足的时候,策略是“使用调用线程池的线程来执行”
new ThreadPoolExecutor.CallerRunsPolicy()
);
return executor;
}
public static void main(String[] args) {
// 获取调度线程池
ScheduledExecutorService executor = createThreadPool();
// 打印当前时间
System.out.println("当前时间:" + new Date());
// 立即执行的任务
Runnable nowTask = () -> {
System.out.println("当前时间:" + new Date() + "------执行【立即】任务");
};
// 延迟执行的任务
Runnable delayTask = () -> {
System.out.println("当前时间:" + new Date() + "------执行【延迟】任务");
};
// 周期性执行的任务
Runnable periodTask = () -> {
System.out.println("当前时间:" + new Date() + "------执行【周期性】任务");
};
// 提交立即任务,有线程空闲立即执行
executor.execute(nowTask);
// 提交一次性延迟任务,延迟2秒执行
executor.schedule(delayTask, 2, TimeUnit.SECONDS);
// 提交周期性的延迟任务,10秒后每3秒执行一次
executor.scheduleWithFixedDelay(periodTask, 10, 3, TimeUnit.SECONDS);
}
}
① 调用execute()提交的任务立即执行;
② 调用schedule()提交的延时任务,在指定延迟时间点执行;
③ 调用scheduleWithFixedDelay()提交的周期性任务,按周期执行;
④ ScheduledExecutorService线程池,该线程池支持任务延迟调度、周期性调度、即时调度。
3. Executors
public class ExecutorsDemo {
public static void main(String[] args) {
// 创建一个缓存型的线程池,这种线程池每来一个任务就会创建一个线程来执行
Executors.newCachedThreadPool();
// 创建一个固定线程数量的线程池
Executors.newFixedThreadPool(3);
// 创建一个单线程的线程池
Executors.newSingleThreadExecutor();
// 创建一个单线程的调度线程池
Executors.newSingleThreadScheduledExecutor();
// 创建一个固定线程数量的调度线程池
Executors.newScheduledThreadPool(3);
}
}
Executors工具类封装了创建线程池的方法,但不建议使用Executors,其参数设置不合理。
4. 常见线程池分类
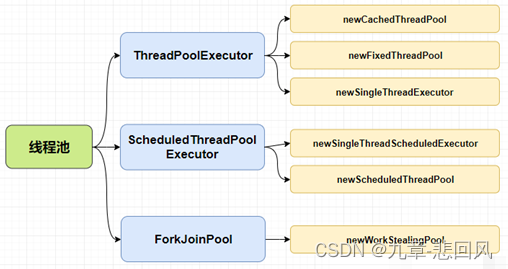
7.2 ThreadPoolExecutor
7.2.1 参数
7.2.1.1 状态和线程数量表
public class ThreadPoolExecutor extends AbstractExecutorService {
// 使用一个Int类型的32位同时表示: 线程池状态、线程数量
// 其中高3位表示线程池状态,也就是0~2位表示线程池状态
// 低29位也就是3~31位表示线程数量,最多能容纳2^29 - 1 约为500多万个线程
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// Integer.SIZE = 32, COUNT_BITS = 32 - 3 = 29
// 这里的意思就是使用29位表示线程数量
private static final int COUNT_BITS = Integer.SIZE - 3;
// 线程池的容量为 CAPACITY = 2^29 - 1 约为500多万,(1 << COUNT_BITS也就是1左移29位也就是2的29次方)
// 这里CAPACITY对应的32二进制位为 000 11111111111111111111111111111(高3位全为0,低29位全为1)
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// -1 左移29位得到 111 00000000000000000000000000000
// 其中高3位也就是111表示当前线程池为运行状态RUNNING
private static final int RUNNING = -1 << COUNT_BITS;
// 0 左移动29位得到 000 00000000000000000000000000000
// 其中高3位为000表示当前线程池为状态为SHUTDOWN
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 1 左移动29位得到 001 00000000000000000000000000000
// 其中高3位为001表示当前线程池为状态为STOP
private static final int STOP = 1 << COUNT_BITS;
// 2 左移动29位得到 010 00000000000000000000000000000
// 其中高3位为010表示当前线程池为状态为TIDYING
private static final int TIDYING = 2 << COUNT_BITS;
// 3 左移动29位得到 011 00000000000000000000000000000
// 其中高3位为011表示当前线程池为状态为TERMINATED
private static final int TERMINATED = 3 << COUNT_BITS;
}
private static int runStateOf(int c) {
// 1. 这里的c就是传入ctl的值
// 2. ~CAPACITY 的32位值是 111 00000000000000000000000000000(高3位为1,低29位为0)
// 这样c & ~ CAPACITY操作就能保留c的高三位值
// 由于使用ctl的高3位表示线程池状态,这样也就得到了线程池的状态
return c & ~CAPACITY;
}
private static int workerCountOf(int c) {
// CAPACITY的32位为 000 11111111111111111111111111111(高3位全为0,低29位全为1)
// c与CAPACITY进行与运算,会得到低29位结果,也就是得到当前线程数量
return c & CAPACITY;
}
private static int ctlOf(int rs, int wc) {
// rc表示线程池状态(RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED)
// wc表示当前线程池大小
// rc | wc 进行或操作就可以得到ctl的值(相当于得到一个新的数组,高3位就是rc的值,低29位是wc的值)
return rs | wc;
}
ctl变量高3位表示线程池状态,低29位表示线程池大小,线程池状态可通过runStateOf()获取,线程数量可通过workerCountOf()获得,当线程池状态、线程池大小更新之后,调用ctlOf(线程池状态|线程池大小)更新即可。

7.2.1.2 状态种类和意义
① RUNNING:运行中,该状态线程池,能接收新任务,并处理已接收的任务;
② SHUTDOWN:不接收新任务,但会处理已接收的任务;
③ STOP:不接收新任务,不处理阻塞队列中任务,中断正在运行任务;
④ TIDYING:不接收新任务,终止所有任务,释放线程池,直到线程数量为0;
⑤ TERMINATED:终止状态,不接受、不运行、线程池关闭。
7.2.1.3 其它属性
// 核心线程数
private volatile int corePoolSize;
// 最大线程池数
private volatile int maximumPoolSize;
// 创建线程的工厂
private volatile ThreadFactory threadFactory;
// 阻塞队列,用户存放任务的容器
private final BlockingQueue<Runnable> workQueue;
// 线程容器,Worker就是工作者,一个Worker内部封装了一个Thread线程
// 这里使用HashSet进行存储,表示工作者容器,线程容器
private final HashSet<Worker> workers = new HashSet<Worker>();
// 互斥锁,由于上面的HashSet不是并发安全的,所以操作的时候肯定需要上锁
private final ReentrantLock mainLock = new ReentrantLock();
// 等待条件
private final Condition termination = mainLock.newCondition();
// 当前线程数 > corePoolSize时候,这部分多出的线程在空闲多久之后会被销毁掉
private volatile long keepAliveTime;
// 是否允许核心线程超时
// 如果是false,核心线程不会被销毁
// 如果是true,核心线程在keepAliveTime时间后依然空闲,则会被销毁掉
private volatile boolean allowCoreThreadTimeOut;
// 一个标记变量,标记曾经线程池的最大大小
// 举例:corePoolSize = 5, maximumPoolSize = 10
// 线程池最大的时候有过8个线程,那么largestPoolSize = 8,只是标记一些曾经的最大值
private int largestPoolSize;
// 一个统计变量,线程池已经完成的任务数量
private long completedTaskCount;
// 线程池拒绝策略
// 当线程池饱和(阻塞队列满了,存不进新的任务;同时线程池的数量达到了maximumPoolSize无法再增加新线程)的时候提交新任务会触发此策略的执行
// 当线程池状态为SHUTDOWN,表示我要关闭了,不再接收新任务;此时向线程池提交新任务也会触发此策略的执行
private volatile RejectedExecutionHandler handler;
// 默认的拒绝策略,直接抛出异常(Abort是中止的意思)
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
7.2.1.4 拒绝策略
1. AbortPolicy中止策略
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 这里直接抛出一个异常,也就是线程池饱和或者线程池SHUTDOWN的时候直接抛出异常
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
2. DiscardPolicy抛弃最新任务
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
// r是最新提交的任务
// 看这里什么都不干,就是将最新提交的任务忽略了,不会执行它,相当于将它丢弃了
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
3. DiscardOldestPolicy丢弃阻塞队列中最久的任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 如果当前线程池未关闭,也就是正常运行的
if (!e.isShutdown()) {
// 从阻塞队列中poll出一个任务,按照先进先出的方式
// 也就是当前阻塞队列头部的任务,是这个阻塞队列中最先进去的,最老的意思
e.getQueue().poll();
// 抛弃最老的任务之后,调用e.execute(r)将当前任务交给线程池
e.execute(r);
}
}
}
4. CallerRunsPolicy使用调用者线程运行任务策略
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 如果当前线程池状态不是SHUTDOWN,也就是正常的
if (!e.isShutdown()) {
// 直接执行任务的run方法
// 注意,这个时候不是使用线程池里面的线程,是直接使用你当前的线程去执行
r.run();
}
}
}
5. 拒绝策略总结
以上ThreadPoolExecutor线程池提供的4种拒绝策略,默认使用AbortPolicy策略,4种策略均实现RejectedExecutionHandler接口,若需要定制执行策略,直接实现RejectedExecutionHandler接口即可,然后在构建线程池时传入拒绝策略。
7.2.2 execute提交任务
1. execute
public void execute(Runnable command) {
// 如果提交任务为null,直接抛出异常,没啥好说的,就是不允许提交空任务
if (command == null)
throw new NullPointerException();
// 这里获取线程池的控制变量ctl (该变量同时存储了线程池状态、线程池大小)
int c = ctl.get();
// workerCountOf(c)位运算方法得到当前线程池的线程数量,这里上一章讲过这个方法
if (workerCountOf(c) < corePoolSize) {
// 如果当前线程数量 < corePoolSize,也就是线程数还没达到设置的核心线程数
// 这里就调用addWorder方法,创建一个新的线程,然后将command任务交给这个新线程去运行
if (addWorker(command, true))
// 走到这里说明addWorder返回true,说明创建新线程成功,任务提交成功,直接返回
return;
// 走到这里说明addWorker失败了,说明创建新线程失败
c = ctl.get();
}
// 走到这里有两种情况:
// (1) 当前线程数量 >= corePoolSize
// (2) 当前线程数量 < corePoolSize 但是addWorker创建新线程失败了,几乎不会发生,可以忽略
// isRunning(c) 判断当前线程池是否处于RUNNING状态,也就是是否还正常运行
// 如果正常运行,调用workQueue.offer(command)方法将任务放入阻塞队列
// 注意:阻塞队列在上一篇非常详细的讲解过了,这里的offer方法在容量满的时候不会阻塞调用线程
if (isRunning(c) && workQueue.offer(command)) {
// 如果任务放入阻塞队列成功,重新获取线程池控制状态ctl
int recheck = ctl.get();
// !isRunning(recheck) ==true 表示当前线程池关闭了,可能就在这个时候有别人关闭了线程池
// 需要调用remove方法将刚放入队列的任务取出,执行reject拒绝策略
// 表示线程池关闭了,不能提交新任务了,执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
// 走到这里说明当前线程池肯定是RUNNING状态
// workerCountOf计算一下当前线程数,如果是0,说明没有线程,需要调用addWorker方法创建新线程
else if (workerCountOf(recheck) == 0)
// 新创建线程,由于command任务放入阻塞队列了,所以此时传给新线程任务为null
// 新线程自己会从阻塞队列取任务来执行
addWorker(null, false);
}
// 走到这里说明:阻塞队列任务提交失败了,说明阻塞队列满了
// 这个时候再次去创建新线程,只要当前线程数 < maximumPoolSize就可以创建成功
// 如果创建成功,将command任务交给新线程运行
else if (!addWorker(command, false))
// 走到这里说明新线程创建失败,阻塞队列也满了
// 没办法,此时线程池饱和了,只能执行拒绝策略了
reject(command);
}
① 计算当前线程数,若当前线程数<corePoolSize,则创建线程并将任务交给新线程,创建成功直接返回,失败进入下一步;
② 若当前线程数>=corePoolSize,判断线程池状态是否为RUNNING,是则优先将任务放入阻塞队列,如果放入阻塞队列成功,则再次判断线程池;
③ 比如判断状态参数是否为RUNNING,如果不是则说明线程池已关闭,将刚放入队列任务取出,执行拒绝策略;
④ 比如判断当前线程是否为0,如果是0则创建线程执行任务;
⑤ 当前线程数>=corePoolSize,并且当前任务放入阻塞队列失败时,则会再次执行addWorker(),再次尝试创建线程;
⑥ 只要当前线程数<maximumPoolSize,并且线程池为RUNNING时才会创建成功,否则创建新线程失败,执行拒绝策略。

2. 任务处理策略
① corePoolSize:当前线程数<corePoolSize时,提交任务会不断创建新线程,然后将任务交给新线程,直到当前线程数等于corePoolSize为止;
② 阻塞队列:当线程数量>=corePoolSize时,提交任务会优先将任务放入阻塞队列;
③ maximumPoolSize:当线程数量>=corePoolSize时,任务会优先进入阻塞队列,阻塞队列满载后会创建新线程,直至线程数量达到maximumPoolSize;
④ 拒绝策略:当线程数量=maximumPoolSize时,提交任务会尝试放进阻塞队列,放入成功则返回,若阻塞队列满载,放入失败则执行拒绝策略。
⑤ 拒绝策略触发场景:
提交任务时线程池状态不是RUNNING,会触发拒绝策略执行;
提交任务时线程池是RUNNING,但阻塞队列满载,线程数量=maximumPoolSize,会触发拒绝策略执行。
3. addWorker
// addWorker方法由两个参数
// firstTask 表示新创建线程的时候,给这个线程的第一个任务是什么,
// 如果不是null,则新线程创建好后会立马执行这个任务
// 如果传入是null,新线程自己会从阻塞对了取任务出来执行
// core 是核心的意思,表示创建线程的数量限制是 核心线程数(corePoolSize)
// 当core == turu,只有当前线程数 < corePoolSize才允许创建新线程
// 当core == false,当前线程数 < maximumPoolSize 才允许创建新线程
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 无限循环,会不断进行重试
for (;;) {
// 获取当前线程池的控制变量(该变量存储了线程池状态、线程数量)
int c = ctl.get();
// 计算得到当前线程池状态
int rs = runStateOf(c);
// 这里返回false,也就是不允许创建新线程的情况有
// 1. 状态非RUNNING,也就是线程池关闭了,并且workQueue非空
// 2. 状态非RUNNING,并且firstTask 非空
// 3. 状态非RUNNING,并且非SHUTDOWN,可能为STOP、TIDYING、TERMINATED
// 以上集中情况说明线程池关闭了,不允许再创建新线程出来,直接返回false
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 无限循环,里面进行cas操作,直到成功
for (;;) {
// 获取当前线程数量
int wc = workerCountOf(c);
// 如果线程数量大于等于CAPACITY,则线程数量达到了线程池能记录的上线,不允许创建了
// 因为线程数量使用ctl的低29位表示,超过2^29次方ctl变量表示不了了
if (wc >= CAPACITY ||
// 这就是上面core参数的控制逻辑了
// 当core == true,当前线程舒朗 < corePoolSize才允许创建新线程
// 当core == false,当前线程数量 < maxumumPoolSize才允许创建新线程
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 走到这里说明线程数量未达到上限,允许创建新线程
// 则执行cas操作,将当前线程数量+1
if (compareAndIncrementWorkerCount(c))
// 如果cas成功,跳出此次循环
break retry;
// 走到这里说明cas失败,重试
c = ctl.get();
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 这里就是创建一个新的工作者Worker出来,将firstTask作为这个工作者的第一个任务
// 这个工作者内部包含一个线程
w = new Worker(firstTask);
// 获取工作者内部的工作线程
final Thread t = w.thread;
// 如果工作线程非空,下面的操作可能是将Worker放入HashSet容器了,加锁,释放锁、线程池状态校验之类的
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// 进行加锁,互斥锁
mainLock.lock();
try {
// 获取当前线程池状态
int rs = runStateOf(ctl.get());
// 1.如果线程池状态为RUNNING,表示线程池状态成功,可以继续
// 2. 如果线程池为SHUTDOWN,表示线程池关闭中,不接受新任务,但是会继续执行已经提交的任务
// 并且 firstTask == null 表示不是新任务,此时允许创建新线程,新线程会从阻塞队列取任务来执行
// 满足上面的1、2两种情况可以创建新线程
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
// 满足上面的校验之后,就会将新创建的工作者放入容器中,就是放入HashSet中
workers.add(w);
// 当前线程池工作者数量
int s = workers.size();
// 更新一下largestestPoolSize,也就是线程池达到过的最大数量是多少
if (s > largestPoolSize)
largestPoolSize = s;
// 更新一下标志变量,表示创建成功
workerAdded = true;
}
} finally {
// 释放锁
mainLock.unlock();
}
// 启动工作者的内部线程,设置启动成功标识为true
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果启动失败了,执行失败操作,肯定是将worker从HashSet容器移除,线程数量减少一个
if (! workerStarted)
addWorkerFailed(w);
}
// 返回是否创建成功、启动成功标识
return workerStarted;
}

7.2.3 Worker工作者
1. Worker内部结构
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
// Worker内部持有的工作线程,就是依靠这个线程来不断运行线程池中的一个个task的
final Thread thread;
// 提交给这个Worker的首个任务
Runnable firstTask;
// 一个统计变量,记录着这个worker总共完成了多少个任务
volatile long completedTasks;
// 构造方法,创建Worker的时候给这个worker传入第一个运行的任务
Worker(Runnable firstTask) {
// 初始化AQS内部的state资源变量为-1
setState(-1);
// 保存一下首个任务
this.firstTask = firstTask;
// 使用线程工厂创建出来一个线程,这个线程负责运行任务
this.thread = getThreadFactory().newThread(this);
}
// 内部的run方法,这个方法执行一个个任务
public void run() {
// runWorker方法,去运行一个个task
runWorker(this);
}
// 实现AQS的互斥锁,这里是否持有互斥锁,不等于0就是持有
protected boolean isHeldExclusively() {
return getState() != 0;
}
// 实现AQS加互斥锁逻辑,就是CAS将state从0设置为1,成功就获取锁
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 是新AQS释放互斥锁逻辑,就是将state变量从1设置为0,成功就释放锁成功
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// 加锁
public void lock() { acquire(1); }
// 尝试加锁
public boolean tryLock() { return tryAcquire(1); }
// 解锁
public void unlock() { release(1); }
// 是否持有锁
public boolean isLocked() { return isHeldExclusively(); }
}
① Worker工作者继承了AQS,是一个同步器;
② Worker实现了Runnable接口;
③ Worker是线程池内部的工作者,每个Worker持有一个线程,addWorker()创建Worker工作者,并放入HashSet的容器中。
2. runWorker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// 获取worker的第一个任务firstTask,赋值给task(要运行的任务)
Runnable task = w.firstTask;
// firstTask传给task之后,设置firstTask为null (方便firstTask完成之后垃圾回收)
w.firstTask = null;
// 初始化一下,将w的同步器设置为解锁状态
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 这里是重点
// 假如task != null ,是因为上边将firstTask设置给了task,所以优先运行第一个任务firstTask
// 假如task == null,那么调用getTask方法,从线程池的阻塞队列里面取任务出来
while (task != null || (task = getTask()) != null) {
// 运行任务之前需要进行加锁
w.lock();
// 这里就是校验一下线程池的状态
// 如果是STOP、TIDYING、TERMINATED 需要中断一下当前线程wt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 这里是一个钩子,执行任务前可以做一些自定义操作
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 这里就是运行任务了,调用task的run方法执行task任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 这里就是一个后置钩子,运行完毕任务之后可以做一些自定义操作
afterExecute(task, thrown);
}
} finally {
// 运行完task之后,需要设置task为null,否则就会死循环不断运行
task = null;
// 将worker完成的任务数+1,
w.completedTasks++;
// 解锁
w.unlock();
}
}
// 如果走到这里,说明跳出了上面的while循环,当前worker需要进行销毁了
completedAbruptly = false;
} finally {
// 销毁当前worker
processWorkerExit(w, completedAbruptly);
}
}
① 在while循环里,不断运行任务task,task来源可能有两种;
② task可能是创建worker时传入的firstTask,或者是调用getTask()从阻塞队列取的task;
③ 每次调用task.run()执行任务之前,先加锁,然后运行task任务,然后释放锁锁;
④ 每次循环前,如果获取运行的task任务为null,则需要跳出while循环,准备销毁worker。
⑤ Worker执行task前,都要执行w.lock,对worker进行加锁,然后才能执行task任务;
⑥ 此时如果有其他线程要中断Worker,也需要获取w的互斥锁,执行w.tryLock()方法;
⑦ 如果执行tryLock加锁失败,说明当前Worker()正在执行task,不允许中断。

3. getTask
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
// 在一个循环里面,进行重试
for (;;) {
// 获取当前线程池的控制变量(包含线程池状态、线程数量)
int c = ctl.get();
// 获取当前线程池的状态
int rs = runStateOf(c);
// 如果当前线程池状态是STOP、TIDYING、TERMINATED,则说明线程池关闭了,直接返回null
// 如果当前线程池状态为SHUTDOWN、并且阻塞队列是空,说明线程池即将关闭,并且没有多余要执行的任务了,直接返回ull
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// 计算当前线程池中线程数量wc
int wc = workerCountOf(c);
// 注意这里的timed控制变量很重要,表示从阻塞队列中获取任务的时候,是一直阻塞还是具有超时时间的阻塞
// (1)当前线程数量 wc > corePoolSize 的时候为true
// 假如corePoolSize = 5, maximumPoolSize = 0, wc = 8
// 当前线程数8 > corePoolSize,那么多出的这3个线程,在keepAliveTime时间内空闲就干掉
// (2) 当allowCoreThreadTimeout 为true,则timed为true
// 这里的意思是,线程池内的线程,只要超过keepAliveTime空闲的全部干掉
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// wc > maximumPoolSize 正常情况不可能发生的
// 这里的意思是如果超时了,超时了还取不到任务,就返回null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 这的意思就是
// 如果timed == true, 从阻塞队列取任务最多阻塞keepAliveTime时间,如果娶不到返回null
// 如果timed == false。则调用take方法从阻塞队列取任务,一直阻塞,知道取到任务位置
// 这里涉及的一些阻塞队列的知识,我们在上一篇并发容器的时候已经非常深入的分析过了
Runnable r = timed ?
// 调用poll方法,最多阻塞keepAliveTime时间
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
// 调用take方法,在取到任务之前会一直阻塞
workQueue.take();
// 如果从队列取到任务,直接返回
if (r != null)
return r;
// 否则就是超时了
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
① 判断当前线程池状态,若是STOP、TIDYING、TERMINATED,则返回null,并销毁掉worker;
② 若是SHUTDOWN,并且workerQueue阻塞队列是空,说明线程池即将关闭,销毁worker;
③ 如果当前线程数量>corePoolSize,若多出的线程在keepAliveTimeout时间内没取出任务,则返回null,销毁多出的worker;
④ 如果allowCoreThreadTimeout==true,表示允许销毁所有线程包括核心线程,即任意线程超过keepAliveTimeout时间内没取到任务,则会销毁线程及worker。

4. 空闲线程被销毁
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// completeAbruptly表示当前线程是否因为被中断而被销毁的
// 如果是正常情况,因为keepAliveTimeout空闲而被销毁,则为false
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
// 计算一下线程池完成总的任务数量
completedTaskCount += w.completedTasks;
// 从HashSet容器中移除当前的worker
workers.remove(w);
} finally {
// 释放锁
mainLock.unlock();
}
// 尝试中止线程池,这里我们后面的章节再分析
tryTerminate();
int c = ctl.get();
// 如果当前线程状态为RUNNING、SHUTDOWN
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
// 这就是计算一下当前线程池允许的最小线程数
// 正常情况是min=corePoolSize,但是当allowCoreThreadTimeout为true时候,允许销毁所有线程,则min=0
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果min = 0 并且 阻塞队列非空,说明还有任务没执行
// 此时最少要保留1个线程去运行这些任务,不能销毁所有
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 如果当前线程数量 >= min值,可以了,销毁动作结束了
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 说明completedAbruptly == true,说明可能是因为线程被中断(interrupted方法)而被销毁
// 此时可能还有很多任务还没执行,需要加会容器里面
addWorker(null, false);
}
}
① 如果是正常情况keepAliveTimeout空闲时间被销毁,则从HashSet容器里面移除;
② 如果当前线程池状态是RUNNING、SHUTDOWN,说明还有任务待执行;
③ 从HashSet容器移除当前worker后,需判断如果worker是否因为异常被中断,是则需要新创建worker来继续执行任务。
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 遍历容器中的所有worker
for (Worker w : workers) {
Thread t = w.thread;
// 这里核心点就是要调用w.tryLock方法尝试获取锁
if (!t.isInterrupted() && w.tryLock()) {
try {
// 只有获取w工作者的互斥锁之后才能中断它
t.interrupt();
} catch (SecurityException ignore) {
} finally {
// 释放锁
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
7.2.4 线程池预热、关闭和统计
7.2.4.1 预热
public boolean prestartCoreThread() {
// 获取当前线程数
// 如果 当前线程数 < corePoolSize,则创建出来一个线程
// 这里调用addWorker(null, true)方法,之前源码讲解过,
// 传递true参数的时候,只有线程数小于corePoolSize的时候才会创建Worker出来
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
}
public int prestartAllCoreThreads() {
int n = 0;
// 这里调用addWorker(null,true)
// true表示 当前线程 < corePoolSize的时候允许创建线程
// 所以这里的while会一直创建出Worker,直到 线程数 == corePoolSize位置
while (addWorker(null, true))
++n;
return n;
}
preStartCoreThread提前创建一个核心线程,preStartAllCoreThread提前创建所有核心线程,线程池提供的预热方法,目的是提前创建出来一些线程,应对大批量任务。
7.2.4.2 关闭
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
// 进行加锁
mainLock.lock();
try {
// 做一些安全检查,不是核心点
checkShutdownAccess();
// 把当前线程池的状态改为SHUTDOWN
advanceRunState(SHUTDOWN);
// 销毁线程池中空闲的线程
interruptIdleWorkers();
// 关闭线程池的回调钩子,可以做一些自定义操作
onShutdown();
} finally {
mainLock.unlock();
}
// 尝试进行中止线程池
tryTerminate();
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
// 这里传入的onlyOne参数,表示是否只销毁一个空闲的线程
// true:如果线程池有多个空闲线程,只会销毁一个就退出,比如有10个空闲线程,只销毁1个
// false:销毁所有空闲的线程
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
// 进行加锁
mainLock.lock();
try {
// 遍历worker容器
for (Worker w : workers) {
Thread t = w.thread;
// 首先判断线程t是非中断状态才能中断,如果中断了那么就不需要再中断了
// 然后尝试去获取worker的锁,执行truLock方法,获取锁
// 为什么说是优雅关闭,就是这里需要获取锁才能中断,而不是强制中断
// 因为如果获取锁失败,说明当前worker正在执行任务,不能强制中断worker执行的任务,
// 而是等它在非执行任务的时候才能中断
if (!t.isInterrupted() && w.tryLock()) {
try {
// 只有获取worker的互斥锁才能走到这里
// 这里就是中断线程
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
// 这里就是判断是否只是中断一个了,如果是就直接返回了,不是的话继续for循环中断其它空闲worker
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
① 循环遍历worker,找出可以中断的worker,进行中断;
② 中断worker前需要对worker进行加锁,获取锁成功说明worker不是在执行任务,才能中断;
③ shutdown是线程池提供的一种优雅关闭的方式,不会强行中断正在执行任务的worker。
final void tryTerminate() {
// 进行循环重试
for (;;) {
// 获取当前线程池的控制变量(包含线程池状态、线程数量)
int c = ctl.get();
// 这里直接return的情况,也就是不能进行中止线程池的情况有:
// 1. isRunning(c) 也就是当前线程池还是RUNNING正常运行,不能中止
// 2. 线程池为SHUTDOWN 并且 阻塞队列非空,说明还有一些任务没有执行,需要继续执行任务,不能中止
// 3. runStateAtLeast(c,TIDYING) 至少是TIDYING,也就是可能是TIDYING、TERMINATED这两种状态之一
// 处于TIDYING、TERMINATED 状态说明线程池已经关闭完成了,正在中止或者已经中止,这里就不需要再次中止了
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// 如果当前当前线程数量不为0,不能中止线程池,需要中断所有线程才能中止线程池
if (workerCountOf(c) != 0) {
// 去中断线程池里面一个空闲的线程
interruptIdleWorkers(ONLY_ONE);
return;
}
// 走到这里说明上面的那些校验统统不满足
// 也就是当前线程池的状态为SHUTDOWN或者STOP、阻塞队列为空、线程池线程数量为0,
// 这个时候就可以尝试中止线程池了
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
// 设置线程池的状态为TIDYING(终止中..)
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 这里是终止的一个回调钩子方法,可以做一些自定义操作
terminated();
} finally {
// 设置当前线程池状态为TERMINATEd(已终止)
ctl.set(ctlOf(TERMINATED, 0));
// 唤醒因为termination条件而沉睡的线程
termination.signalAll();
}
return;
}
} finally {
// 释放锁
mainLock.unlock();
}
}
}

另外,ThreadPoolExecutor提供了暴力关闭线程池方法shutdownNow(),会立即中断正在运行的线程,强行清空阻塞队列中的任务,销毁所有线程,终止掉线程池。
7.2.4.3 统计
1. getPoolSize获取线程池大小
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
// 进行加锁
mainLock.lock();
try {
// 如果当前线程池状态至少是TIDYING,也就是处于TIDYING、TERMINATED中的一种
// 说明线程池已经终止了,当前线程个数为0
// 如果处于RUUNING、SHUTDOWN、STOP状态,返回worker容器中worker工作者个数
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}
2. getActiveCount正在执行任务的线程数
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
// isLock方法说明被加锁了,正在执行任务
// 所以也就是统计正在执行task任务的线程个数
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}
3. getCompletedTaskCount线程池完成的任务总数
public long getCompletedTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers)
// 这里就是将每个worker完成的任务数进行加和
// 就得到已经完成的任务总数了
n += w.completedTasks;
return n;
} finally {
mainLock.unlock();
}
}
4. getTaskCount提交到线程池的任务总数
public long getTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers) {
// 统计已经完成的任务总数
n += w.completedTasks;
if (w.isLocked())
// 正在执行的任务也要算进去
++n;
}
// 阻塞队列的任务也要算进入
return n + workQueue.size();
} finally {
mainLock.unlock();
}
}
5. getLargestPoolSize线程池线程数达到的最大值
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// largetstPoolSize记录着这个线程池曾经线程数量的最大值,直接返回即可
return largestPoolSize;
} finally {
mainLock.unlock();
}
}
7.2.5 submit提交任务
// 这里传入一个Callable<T> task任务
// submit有几个重载方法,传入的无论是Callable、Runnable,内部的实现流程都是一样的
public <T> Future<T> submit(Callable<T> task) {
// 校验一下传入的任务,如果是空,则抛出异常
if (task == null) throw new NullPointerException();
// 将传入的task任务包装成一个RunnableFuture
RunnableFuture<T> ftask = newTaskFor(task);
// 这里就是调用线程池内部的execute方法来执行类,这里的execute方法我们之前分析过了
execute(ftask);
// 这里就将包装得到的RunnableTask返回
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
// 很简单,就是创建出来一个FutureTask实例,然后将callable任务封装在这个FutureTask中
return new FutureTask<T>(callable);
}
① submit()核心逻辑为,将传入的task任务封装成一个FutureTask;
② 将FutureTask(实现了runnable接口)交给execute()提交任务;
③ 将FutureTask返回给调用者;
④ submit和execute不同在于构建了FutureTask对象。

7.2.6 Future接口
public class FutureTaskDemo {
//创建一个线程池
public static ThreadPoolExecutor executor = new ThreadPoolExecutor(
2,
5,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
new DefaultThreadFactory("future-pool-test"),
new ThreadPoolExecutor.CallerRunsPolicy()
);
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 封装一个Runnable任务
Runnable runnableTask = () -> {
System.out.println("线程池线程::当前时间:"+new Date() + " 开始执行Runnable任务");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程池线程::当前时间:"+new Date() + " 开始执行Runnable任务");
};
// 将一个runnable任务通过submit方法提交给线程池
// 线程池返回一个Future接口的实现类
// 上面我们分析过了,其实就是返回一个FutureTask实例
Future future = executor.submit(runnableTask);
// 这里主线程调用future的get接口会被阻塞住,知道runnable任务执行成功为止
// 这里获取任务的结果,由于是Runnable接口没有返回值,所以得到结果一定是Null
Object result = future.get();
System.out.println("主线程/调用线程当前时间:"+new Date() + " 执行runnableTask结束, 获取结果为:" + result);
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 封装一个Callable任务
Callable<Integer> callTask = () -> {
System.out.println("线程池线程::当前时间:"+new Date() + " 开始执行Callable任务");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程池线程::当前时间:"+new Date() + " 开始执行Callable任务");
// 执行结束后返回结果值
return 10000;
};
// 将一个Callable任务通过submit方法提交给线程池
// 线程池返回一个Future接口的实现类
// 上面我们分析过了,其实就是返回一个FutureTask实例
Future<Integer> future = executor.submit(callTask);
// 这里主线程调用future的get接口会被阻塞住,知道Callable任务执行成功为止
// 这里获取任务的结果,根据返回值应该得到结果是 10000
Integer result = future.get();
System.out.println("主线程/调用线程当前时间:"+new Date() + " 执行callableTask结束, 获取结果为:" + result);
}
① 调用Future接口get方法的线程会被阻塞住(示例中主线程被阻塞),直到线程池执行完任务之后将结果值返回;
② Callable接口跟Runnable接口不同,Callable接口有返回值;
③ 很多情况下,可以通过Callable、Future、submit方式交给线程池执行,且可以同步获取结果。
7.2.7 FutureTask任务封装
1. RunnableFuture
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
public class FutureTask<V> implements RunnableFuture<V> {
// 要执行的任务
private Callable<V> callable;
// Callable任务的返回结果
private Object outcome;
// 运行任务的线程
private volatile Thread runner;
// 内部有一个state变量,表示任务执行的状态
private volatile int state;
// 表示FutureTask刚创建出来
private static final int NEW = 0;
// 完成中
private static final int COMPLETING = 1;
// 已完成状态
private static final int NORMAL = 2;
// 异常,运行过程抛出异常
private static final int EXCEPTIONAL = 3;
// 已经被取消
private static final int CANCELLED = 4;
// 中断进行中
private static final int INTERRUPTING = 5;
// 已经被中断
private static final int INTERRUPTED = 6;
// 阻塞线程列表(由于调用Future.get方法而被阻塞的线程链表)
// 任务完成之后,会把该链表的线程一个个唤醒
private volatile WaitNode waiters;
}
RunnableFuture接口继承自Runnable和Future,FutureTask实现RunnableFuture。
2. 构造方法
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
// 保存一下callable任务
this.callable = callable;
// 内部任务的状态初始化为NEW(刚创建)
this.state = NEW;
}
public FutureTask(Runnable runnable, V result) {
// 这里将Runnable任务进行包装成一个Callable任务并保存起来
this.callable = Executors.callable(runnable, result);
// 任务的状态为NEW(刚创建)
this.state = NEW;
}
3. get
public V get() throws InterruptedException, ExecutionException {
// 获取当前任务的执行状态
int s = state;
// 如果状态小于等于COMPLETING,说明任务还未完成
// 如果任务完成,那么状态应该是NORMAL状态
// 所以当前线程应该阻塞,直到任务完成被唤醒
if (s <= COMPLETING)
// 这里就是实际阻塞调用者线程的方法
s = awaitDone(false, 0L);
// 走到这里说明任务已经完成,调用report方法返回任务的执行结果
return report(s);
}
// 这里timed表示是否有时间限制的阻塞
// false:没有超时时间限制,会一直阻塞直到任务完成
// true:有超时时间限制,会阻塞nacos的时间,如果超时了就会唤醒调用线程
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
// 获取超时时间,也就是截止时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 初始化一个等待节点(当前线程被封装到一个等待节点中,进入等待链表阻塞等待)
WaitNode q = null;
boolean queued = false;
// for循环重试,直到操作完成
for (;;) {
// 如果当前被中断了,那么不需要阻塞了
if (Thread.interrupted()) {
// 被中断线程从等待链表中移除
removeWaiter(q);
// 抛出中断异常
throw new InterruptedException();
}
// 获取当前任务执行状态
int s = state;
// 如果任务状态大于COMPLETING说明任务已完成、被取消、被中断等,不需要再阻塞等待
// 只有小于NORMAL的任务才需要被阻塞
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
// 如果任务状态是完成中..。,说明很快就会完成了,先让出cpu一段时间,也不需要进行阻塞了
else if (s == COMPLETING)
// 这里就相当于让出cpu一下
Thread.yield();
// 走到这里state状态肯定是NEW,说明任务刚状态或者是运行中
// 肯定是主要阻塞调用线程的
else if (q == null)
// 如果q为null,初始化一个等待节点
q = new WaitNode();
// 走到这里q不为null,并且queued为false表示还没入队成功
else if (!queued)
// 这里的queued表示是否入队成功,cas操作设置当前waitNode等待节点到链表尾部
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
// timed表示是否有超时时间限制的阻塞
else if (timed) {
nanos = deadline - System.nanoTime();
// 如果是有超时时间限制,但是超时时间是0,明显不合理,直接返回
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
// 注意:这里就是调用LockSupport.parkNanos方法实现超时间的阻塞
LockSupport.parkNanos(this, nanos);
}
else
// 注意:这里就是直接调用LockSupport的part方法进行阻塞
// 直到被调用LockSupport.unpark方法才能唤醒
LockSupport.park(this);
}
}
private V report(int s) throws ExecutionException {
// 这里就是将任务的运行结果outcome保存在变量v中
Object x = outcome;
// 如果当前任务状态是NORMAl(已完成)则返回结果
if (s == NORMAL)
return (V)x;
// 如果当前状态大于等于CANCELLED表示被取消或者中断等异常状态,抛出异常
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}

4. run
public void run() {
// 如果不是NEW状态,说明任务可能被取消了,拒绝执行
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
// 获取Callable任务
Callable<V> c = callable;
// 重新判断一下状态是否是NEW
if (c != null && state == NEW) {
// 任务的结果保存进入result变量中
V result;
boolean ran;
try {
// 这里就是调用callable任务的call方法了,同时把结果保存到result变量中
result = c.call();
// 运行任务成功
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
// 这里的set其实就是将result保存到outcome变量中,方便以后对外输出结果
// 同时将任务的状态设置成为NORMAL(已完成)
// 同时还会唤醒之前调用get方法而沉睡的线程,
// 这些线程在等待队列waitnode中,需要一个个找出来调用LockSupport.unpark方法唤醒
set(result);
}
} finally {
runner = null;
// 如果被中断了,进行中断异常处理
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}

5. set
protected void set(V v) {
// 首先运行完任务之后,将state变量通过cas设置为COMPLETING(完成中)
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
// 然后将任务的结果保存到outcome变量中
outcome = v;
// 然后cas设置任务的状态为NORMAL(已完成)
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
// 这里就是一个个唤醒等待队列中的线程
finishCompletion();
}
}
private void finishCompletion() {
// 这里就是循环遍历waitNode等待队列
// 然后调用LockSupport.unpark方法一个个唤醒,没啥特别的
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
6. cancel
public boolean cancel(boolean mayInterruptIfRunning) {
// 如果当前状态是NEW,说明还未运行完成(运行完成是NORMAL)
// 所以尝试将状态改为INTERRUPTING或者CANCELLED
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
// 如果任务正在运行中,调用interrupt方法中断运行该任务的线程
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
// 唤醒一下等待队列的线程
finishCompletion();
}
return true;
}
7.3 ScheduledThreadPoolExecutor
7.3.1 类结构&构造函数
// 继承了ThreadPoolExecutor线程池,具有ThreadPoolExecutor的一切功能
// 同时具有ThreadPoolExecutor所有的核心参数,核心线程数、最大线程数、线程空闲存活时间、阻塞队列、拒绝策略等等
// 实现了ScheduleExecutorService接口,具有任务调度的功能
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 内部通过调用父类ThreadPoolExecutor的构造方法来构造线程池
// 注意:这里设置了最大线程数maximumPoolSize为Integer.MAX_VALUE
// 注意:这里设置了阻塞队列为内部实现的延迟队列DelayedWorkQueue (这个我们后面再研究)
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
// 内部调用父类ThreadPoolExecutor来构建线程池
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 内部调用父类ThreadPoolExecutor的构造方法来构建线程池
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
ScheduledThreadPoolExecutor继承ThreadPoolExecutor线程池,同时实现了ScheduleExecutorService接口,具有任务定时调度的功能。
7.3.2 execute提交立即执行任务
public void execute(Runnable command) {
// 内部调用了schedule方法去提交任务
// schedule 方法有三个参数:
// 第一个参数,就是要运行的任务
// 第二个参数,就是要延迟运行的时间,由于是execute要求是提交之后又线程空闲立即执行,所以这里延迟时间是0
// 第三个参数,延迟时间的时间单位,这里是纳秒
schedule(command, 0, NANOSECONDS);
}
7.3.3 schedule提交调度任务
// schedule方法有三个参数
// 第一个参数,表示要运行的任务
// 第二个参数,表示任务要延迟执行的时间,如果要求立即执行,可以传0
// 第三个参数,表示延迟执行的时间单位,毫秒、秒、分、小时等等
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
// 这里的逻辑其实就是将传入的任务command封装成一个ScheduledFutureTask对象
// FutureTask之前我们深入分析过了,这里ScheduleFutureTask具有FutureTask的一切功能,同时还具有延迟时间属性
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
// 这里就是核心的逻辑了,通过这个方法向线程池提交任务
delayedExecute(t);
return t;
}
7.3.4 delayedExecute提交任务
private void delayedExecute(RunnableScheduledFuture<?> task) {
// 如果线程池关闭了,不能再提交任务,直接执行拒绝策略
if (isShutdown())
reject(task);
else {
// 获取阻塞队列,也就是延迟队列DelayedWorkQueue
// 将任务放入到延迟阻塞队列中
super.getQueue().add(task);
// 再次进行校验,如果线程池关闭了
// 则刚提交的任务需要从队列移除,然后执行cancel方法取消这个任务
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
// 如果当前线程数 < corePoolSize,就创建出来一个新线程
ensurePrestart();
}
}
// 这里就是进行线程预热
// 核心逻辑就是如果当前线程数量小于corePoolSize或者为0;启动一个新线程
// 毕竟任务提交到阻塞队列了之后,需要线程从队列中不断取出任务来执行
void ensurePrestart() {
// 计算当前线程数量
int wc = workerCountOf(ctl.get());
// 如果当前线程数量 < corePoolSize,则调用addWorker方法创建出来一个工作者,也就是创建一个线程
if (wc < corePoolSize)
// 注意这里创建新worker的时候,传入的firstTask为null
// 也就是新线程创建后没有给与要运行的任务,让它自己从阻塞队列取任务出来运行
addWorker(null, true);
// 同样,如果当前线程数为0,也需要创建出新线程出来
else if (wc == 0)
addWorker(null, false);
}
7.3.5 submit提交任务
public Future<?> submit(Runnable task) {
// 内部也是通过schedule方法向提交一个任务,上面讲解过了
// 这里task是任务,0是延迟时间,说明要求立即执行,NANOSECONDS是时间单位
return schedule(task, 0, NANOSECONDS);
}
7.3.6 scheduleAtFixedRate提交延迟定时任务
// 这个方法是提交一个延迟的定时任务,具有定时执行的周期
// 第一个参数:command就是要运行的任务
// 第二个参数:initialDelay就是第一次执行任务延迟多久
// 第三个参数:定时运行任务的周期,如果配置为0那么就只会执行一次,如果不是0,那么就每隔period执行一次任务
// 第四个参数:时间单位
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
// 这里构建一个ScheduledFutureTask任务出来,具有FutureTask的特性,同时具有延迟任务、周期任务的属性
// 这里的period就是定时任务的周期,initialDelay是延迟属性,第一次执行延迟多少时间,后面就是每隔period执行一次
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
// 这里内部也是通过delayedExecute方法向线程池提交定时(只不过这里是定时任务)
delayedExecute(t);
return t;
}
7.3.7 提交任务总结
① execute、submit提交任务时,都是调用schedule提交任务,但延迟时间为0;
② schedule、scheduleAtFixRate需要将任务封装成ScheduleFututeTask,该任务具有延迟属性、定时周期属性等;
③ 底层均调用delayedExecute提交任务,首先将任务提交到阻塞队列,然后判断当前线程数,若小于corePoolSize则创建线程。


7.3.8 两种线程池异同点
1. ThreadPoolExecutor提交任务流程
① 判断当前线程数量,若小于corePoolSize,则创建新线程,将任务交给新线程;
② 判断当前线程数量,若大于等于corePoolSize,则将任务尝试放入阻塞队列中;
③ 如果放入阻塞队列失败,则阻塞队列可能满载,再次创建创建新线程;
④ 如果线程数量小于maximumPoolSize,则可创建新线程,任务交给新线程;
⑤ 如果线程数量达到maximumPoolSize,则不再创建新线程,执行线程拒绝策略。
2. ScheduleThreadPoolExecutor提交任务流程
① 将任务构建成ScheduleFutureTask对象,赋予延迟时间、周期执行时间等属性;
② 将任务放入DelayedWorkQueue延迟阻塞队列;
③ 判断当前线程数量,若小于corePoolSize则创建新线程。
3. 不同点
① ThreadPoolExecutor提交任务时,若线程数量小于corePoolSize则创建新线程,并将任务交给新线程,不会进入阻塞队列,ScheduledThreadPoolExecutor提交任务时,先放入阻塞队列,然后线程取出来执行;
② ThreadPoolExecutor线程数量在阻塞队列满载时,可增长到maximumPoolSize,ScheduledThreadPoolExecutor只有线程数量小于corePoolSize时才会创建线程,即最大线程数量为corePoolSize。
7.3.9 ScheduledFutureTask原理
1. 类结构

public interface Delayed extends Comparable<Delayed> {
// Delayed的getDelay接口,返回当前任务或者元素的延迟时间,也就是需要延迟多久
long getDelay(TimeUnit unit);
}
public interface RunnableScheduledFuture<V> extends RunnableFuture<V>, ScheduledFuture<V> {
// RunnableScheduledFuture的isPeriodic方法返回这个任务是否是周期性任务
// true,周期性任务
// false,非周期性任务
boolean isPeriodic();
}
2. 核心属性
// 序号id
// 默认情况下延迟任务按照时间优先级执行
// 也就是延迟时间越小,越先执行
// 但是如果两个任务延迟时间一样,则sequenceNumber小的优先级高,先执行
private final long sequenceNumber;
// 延迟时间,任务多久之后会执行
private long time;
// 是否是周期性重复任务
// 是否是0,则不是周期性任务,只是一次性的
// 如果大于0,则每隔period时间会重复执行一次
// 如果小于0,则每隔-period时间重复执行一次
private final long period;
// 这里就是具体的要执行的任务了
RunnableScheduledFuture<V> outerTask = this;
// 在延迟队列中的位置,DelyedWorkQueue延迟队列是基于数组和堆排序实现的
// 而ScheduledFutureTask存储在DelayedWorkQueue延迟队列中,也就是存在数组中
// 这里就是说这个任务是在堆的哪个位置,数组的哪个位置
int heapIndex;
3. 构造函数
ScheduledFutureTask(Runnable r, V result, long ns) {
// 调用父类FutureTask的构造方法
super(r, result);
// 具体的延迟时间
this.time = ns;
// 是否周期性任务,如果为0不是
this.period = 0;
// 任务的序号
// 如果两个任务延时时间一样,需要小的有限执行
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
4. getDelay获取延迟时间
public long getDelay(TimeUnit unit) {
// 任务的延迟时间就是time - 当前时间,然后转成纳秒单位
return unit.convert(time - now(), NANOSECONDS);
}
5. isPeriodic判断是否为周期性任务
public boolean isPeriodic() {
return period != 0;
}
6. setNextRunTime获取周期性任务下次执行时间
private void setNextRunTime() {
long p = period;
if (p > 0)
// 下一个周期执行时间为 time+p
time += p;
else
// 下一个周期执行时间为 now() - p
time = triggerTime(-p);
}
long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
7. compareTo比较任务优先级
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
// 如果Delayed延迟任务是SheduledFutureTask的子类
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
// 则先通过延迟时间比较,延迟时间小的优先级高
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
// 延迟时间一样则sequenceNumber小的优先级高
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
// 如果不是ScheduleFutureTask类的实例,直接比较延迟时间就好了
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
8. run运行任务
public void run() {
// 首先获取任务是否是周期性重复任务
boolean periodic = isPeriodic();
// 如果当前任务线程池状态不对,取消任务执行
if (!canRunInCurrentRunState(periodic))
cancel(false);
// 如果不是周期性的任务,只是一次性延迟任务
else if (!periodic)
// 直接调用父类FutureTask的run方法运行任务
ScheduledFutureTask.super.run();
// 走到这里periodic为true,说明是周期性重复任务
else if (ScheduledFutureTask.super.runAndReset()) {
// 设置下一次运行的时间
setNextRunTime();
// 这里就是运行任务,然后将任务重新方法延迟队列中,因为下一次运行的时间修改了
reExecutePeriodic(outerTask);
}
}
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
// 再次放入延迟阻塞队列中
super.getQueue().add(task);
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
9. ScheduledFutureTask总结
① 继承了FutureTask,具有FutureTask功能,可以获取任务结果和执行状态,可取消任务;
② 实现了Delayed接口,具有延迟时间属性,用于存入延迟队列;
③ 实现了RunnableScheduledFuture接口,用于判断任务是否是周期性任务。
④ compareTo()可用于排序,首先按照延迟时间比较,延迟时间越小优先级越高,其次按sequenceNumber比较,sequenceNumber越小优先级越高。
7.3.10 DelayedWorkQueue原理
1. 结构及属性
// DelayedWorkQueue实现了BlockingQueue接口,是一个阻塞队列
static class DelayedWorkQueue extends AbstractQueue<Runnable>
implements BlockingQueue<Runnable> {
}
// 初始化容量
private static final int INITIAL_CAPACITY = 16;
// 这里就是阻塞队列内部存储数据的结构,是用一个数组来进行存储的
// 数组的初始化长度是16
private RunnableScheduledFuture<?>[] queue =
new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
// 互斥锁,为实现线程安全和阻塞
private final ReentrantLock lock = new ReentrantLock();
// 等待条件
private final Condition available = lock.newCondition();
// 阻塞队列的大小
private int size = 0;
// leader,第一个等待的线程
private Thread leader = null;
//
2. put
public void put(Runnable e) {
offer(e);
}
3. add
public boolean add(Runnable e) {
return offer(e);
}
4. offer
public boolean offer(Runnable e, long timeout, TimeUnit unit) {
return offer(e);
}
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
// 进行加锁
lock.lock();
try {
// 获取当前阻塞队列的大小
int i = size;
// 如果当前队列大小大于等于内部数组的长度,说明存储任务的数组满了,需要进行扩容
if (i >= queue.length)
// 具体扩容的方法
grow();
// 队列大小+1
size = i + 1;
// 如果插入前i==0,说明自己是第一个插入元素,直接放入数组的0号元素即可
if (i == 0) {
queue[0] = e;
// 设置当前任务e在数组中的位置
setIndex(e, 0);
} else {
// 如果 i!=0 说明插入队列非空,数组有元素
// 需要插入任务e,同时进行排序,延迟时间小的排在前面
// 这里的siftUp方法就是插入和排序
siftUp(i, e);
}
// 如果调整之后,刚插入的元素就是延迟时间最小的元素,唤醒沉睡线程
if (queue[0] == e) {
leader = null;
available.signal();
}
} finally {
// 释放锁
lock.unlock();
}
return true;
}
5. grow数组扩容
private void grow() {
// 获取旧数组长度
int oldCapacity = queue.length;
// 新数组长度为旧数组长度的1.5倍
// 比如oldCapacity = 10
// newCapacity = 10 + (10 > 1) = 10 + 5 = 15
int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%
// 如果新数组长度小于0,那么新数组长度MAX_VALUE
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
// 这里就是将旧数组元素拷贝到新数组了,没啥好说的
queue = Arrays.copyOf(queue, newCapacity);
}
6. siftUp插入并排序
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
// 获取父节点
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
// 这里就是不断的跟父节点进行比较,进而调整堆结构
// 都是堆排序的知识了
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
7. poll非阻塞
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
try {
// 获取小顶堆的根元素
RunnableScheduledFuture<?> first = queue[0];
// 如果为null说明队列时空
// 如果延迟时间大于当前试下,说明任务还没到执行的时候
if (first == null || first.getDelay(NANOSECONDS) > 0)
// 当前没有可以执行的任务,返回null
return null;
else
// 走到这里fisrt非null,并且延迟时间小于当前时间,说明可以执行了
return finishPoll(first);
} finally {
// 释放锁
lock.unlock();
}
}
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
// 队列出队一个元素,大小减少1
int s = --size;
RunnableScheduledFuture<?> x = queue[s];
queue[s] = null;
// 重新调整堆结构,调整成小顶堆
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
return f;
}
8. take阻塞
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 循环重试
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
// 如果当前队列没有元素
if (first == null)
// avaiable 可用条件不满足
// 调用await方法释放锁,同时进入条件队列进行沉睡等待
// 等待当队列有元素的时候,调用singal方法唤醒自己
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
// 当前有元素,并且延迟时间小于当前时间,符合执行条件,完成出队
if (delay <= 0)
return finishPoll(first);
// 走到这里,说明delay > 0 队列中的元素延迟执行时间都大于当前时间
// 没有可以执行的任务
first = null; // don't retain ref while waiting
// 这里leader表示第一个获取元素失败则阻塞的线程
// 如果leader不为null,前面已经有人等着了,自己只需要等待就可以,别人会唤醒自己
if (leader != null)
// 进入等待队列等待
available.await();
else {
// 走到这里说明leader == null
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 由于阻塞队列第一个元素至少还有delay时间的延迟
// 所以自己只需要等待delay时间,就可以获取到元素
// 所以这里就是阻塞等待delay时间
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// 当前还有元素,继续唤醒其它等待线程,叫醒别人来取任务了
if (leader == null && queue[0] != null)
available.signal();
// 释放锁
lock.unlock();
}
}
9. DelayedWorkQueue总结
① DelayedWorkQueue使用数组存储数据,基于延迟时间和sequenceNumber实现优先级,基于优先级将数组构建为小顶堆;
② 插入/取出元素后需进行堆排序,排序时间复杂度是O(logN),N为堆中数据量;
③ DelayQueue底层采用PriorityQueue优先级队列来存储数据。

7.3.11 PriorityQueue优先级队列
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
// 底层也是采用数组的方式来进行存储数据的
transient Object[] queue;
// 初始化默认的容量,默认数组的长度是11
private static final int DEFAULT_INITIAL_CAPACITY = 11;
// 队列的大小
private int size = 0;
// 插入元素的方法
public boolean add(E e) {
return offer(e);
}
// 实际插入元素的方法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
// 修改次数+1(关联并发修改异常,ConcurrentModificationException)
modCount++;
// 获取当前元素的个数
int i = size;
// 如果元素达到数组容量上限,进行扩容
if (i >= queue.length)
// 扩容
grow(i + 1);
// 大小+1
size = i + 1;
// 如果数组内没存有元素,插入元素位于数组头部
if (i == 0)
queue[0] = e;
else
// 看到这里是不是很熟悉,这里就是跟之前DelayedWorkQueue一样的堆调整算法
siftUp(i, e);
return true;
}
// 插入元素之后,进行堆调整
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
// 这里就是实际进行堆调整的逻辑,原理跟之前讲解的DelayedWorkQueue一模一样的
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
}
① PriorityQueue允许自定义排序逻辑,传入了Comparator接口实现;
② DelayedWorkQueue排序规则已经写死,即根据延迟时间和sequenceNumber排序;
③ 两个队列均使用数组存储数据,均采用了堆排序思想构建小顶堆,时间复杂度为O(NlogN);
④ 区别为DelayedWorkQueue是阻塞队列,操作需要加锁,并发安全,PriorityQueue不需要加锁。
7.3.12 Timer定时器
1. Timer概述
JDK中Timer定时器,使用一个线程管理任务,存在效率问题。鉴于Timer的缺陷,Java8之后推出了基于线程池设计的ScheduledThreadPoolExecutor。Timer底层采用阻塞队列来存储任务,该队列具有延迟时间优先级的功能。

2. Timer和ScheduledThreadPoolExecutor的缺点
① 两个调度器底层均使用堆排序方式,不适合大规模任务调度,时间复杂度O(NlogN)较高;
② 取任务和执行任务未隔离,若ScheduledThreadPoolExecutor线程较少,所有线程在执行任务,会导致大量任务不能如期执行;
③ Timer只有一个线程,若某个任务执行时间过长,则导致所有任务推迟执行,
④ 为解决缺点,可将取任务和执行任务隔离,分别建立线程池,若任务量大,可增加任务执行线程池线程数量。

3. 时间轮算法
① 毫秒级别时间轮,有1000个刻度,每毫秒移动一个刻度,指针指向某刻度,则取出该刻度的所有任务交给执行线程池执行;
② 通过数组的方式,做到O(1)时间复杂度插入,指针移动一次时间复杂度也是O(1)。

① 秒级别时间轮,每秒移动一个刻度,指针指向某刻度则取出对应任务并执行;
② 在5秒刻度的任务列表中,有任务延迟500ms才能执行,则对该任务进行降级一个时间轮,放到毫秒级别时间轮。

7.4 线程池总结
7.4.1 线程池分类
7.4.2 ThreadPoolExecutor
① 基本使用
② 核心参数
③ execute提交任务及流程
④ submit提交任务(调用execute)
⑤ 工作者Worker
⑥ FutureTask任务
7.4.3 ScheduledThreadPoolExecutor
① schedule提交调度任务
② submmit提交任务(调用schedule)
③ execute提交立即任务(调用schedule)
④ scheduleAtFixRate提交任务
⑤ ScheduleFutureTask任务
⑥ DelayedWorkQueue
7.4.4 线程池关闭
① shutdown优雅关闭
② shutdownNow暴力关闭
7.4.5 不建议使用Executor构建线程池
1. newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0,
Integer.MAX_VALUE,
60L,
TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
① corePoolSize为0,maximumPoolSize为MAX_VALUE、阻塞队列为同步队列SynchronousQueue;
② 由于当前线程数 >= corePoolSize永远成立;
③ 所以提交任务时,优先提交到阻塞队列中;
④ 同步队列特点为生产者和消费者必须一一匹配,存在线程正在调用poll()或take(),当前线程调用offer()才会成功,否则阻塞;
⑤ 所以最开始提交任务到阻塞队列会失败,进而触发“线程数 < MAX_VALUE”条件,创建非核心线程成功;
⑥ 因此,如果瞬时提交较多任务,会瞬时创建很多线程;
⑦ 线程数量太多,cpu竞争剧烈,可能cpu 100%,每个线程需占用一定内存,默认1M,可能导致内存耗尽。
2. newFixdThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads,
nThreads,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
① 核心线程数、最大线程数为nThreads,即线程数固定,阻塞队列为无界阻塞队列LinkedBlocingQueue;
② 线程数 < corePoolSize时,提交任务会创建新线程;
③ 当线程数达到corePoolSize时,提交任务会优先存入阻塞队列;
④ 此处LinkedBlockingQueue使用默认构造函数,队列最大容量为Integer.MAX_VALUE,即容量无限制;
⑤ 若瞬时提交大量任务进入LinkedBlockingQueue,会导致内存耗尽。
3. newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
① 核心线程数、最大线程数为1,阻塞队列为无界阻塞队列LinkedBlockingQueue;
② 无界阻塞队列LinkedBlockingQueue,缺点同newFixedThreadPool。
4. newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 内部调用父类ThreadPoolExecutor线程的构造方法
super(corePoolSize,
Integer.MAX_VALUE,
0,
NANOSECONDS,
new DelayedWorkQueue());
}
① 使用延迟队列DelayedWorkQueue,DelayedWorkQueue会自动扩容,瞬时提交大量任务会导致内存耗尽;
② ScheduledThreadPoolExecutor使用需谨慎,不适合提交大量任务,适合少量任务、定时任务和延迟任务等。















 4561
4561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









