







官方是否经常繁忙,用户量激增导致服务器过载(日活突破500万)。
别担心,这些免费访问 DeepSeek 满血版的方式,助你 AI 探索的一臂之力。
| 方案 | 响应速度 | 上手难度 | 适用人群 |
|---|---|---|---|
| 第三方APP | ⚡️⚡️⚡️⚡️ | 🌟 | 手机党/小白用户 |
| API直连 | ⚡️⚡️⚡️⚡️⚡️ | 🌟🌟🌟 | 开发者/技术爱好者 |
| 本地部署 | ⚡️⚡️⚡️⚡️⚡️ | 🌟🌟🌟🌟 | 极客/企业用户 |
| 镜像网站 | ⚡️⚡️⚡️ | 🌟🌟 | 临时应急 |
| 参数优化 | ⚡️⚡️ | 🌟🌟🌟🌟🌟 | 企业/AI从业者 |
1 AskManyAI
✅ 推荐指数: 🌟🌟🌟🌟🌟
- 使用地址:https://askmanyai.cn/login
👉 操作步骤:
注册进入 AI 工作台,默认勾选了 DeepSeek-R1 联网版 和 DeepSeek-R1 满血版
💡特点:满血版免费,能够同时选中多个 AI 模型进行访问,对比不同的 AI 结果
缺点:需要关注公众号才能获取注册码

2 纳米 AI 搜索
✅ 推荐指数:🌟🌟🌟🌟🌟
📱APP 端和网页端都能免费使用,体验方式:
- 网页链接:https://bot.n.cn/
网页版截图如下:
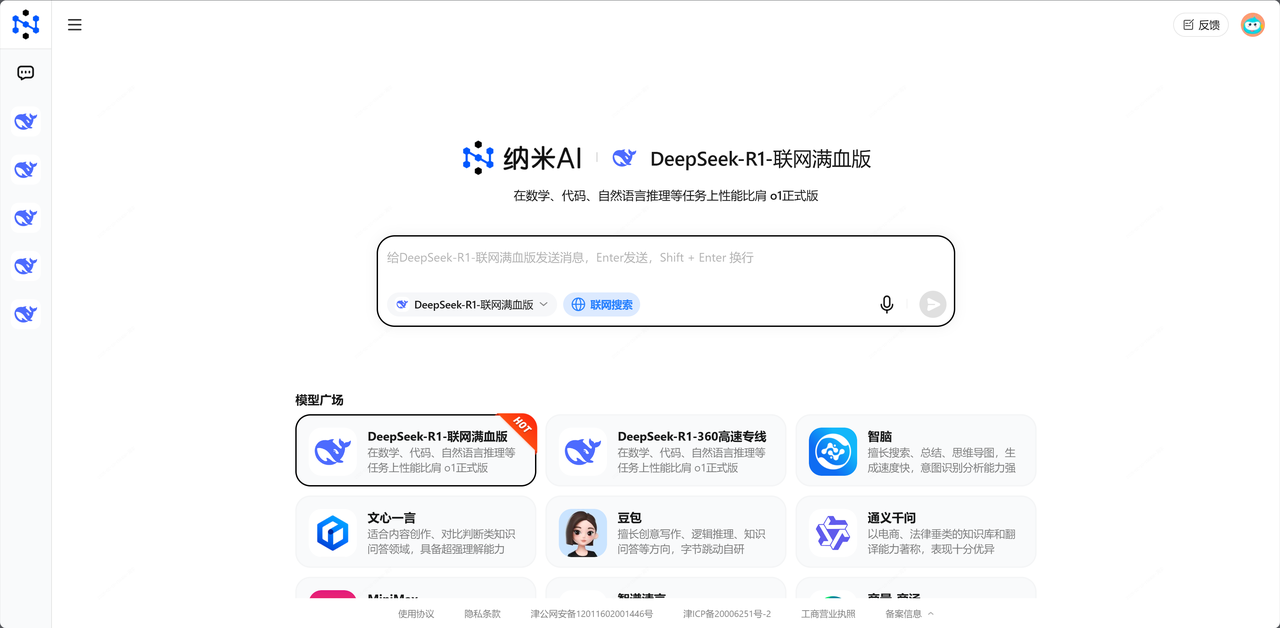
Ps:建议选择最新的 DeepSeek-R1联网满血版
👉 手机端操作步骤:
1️⃣ 应用商店搜索「纳米AI 搜索」安装(认准红色 LOGO)
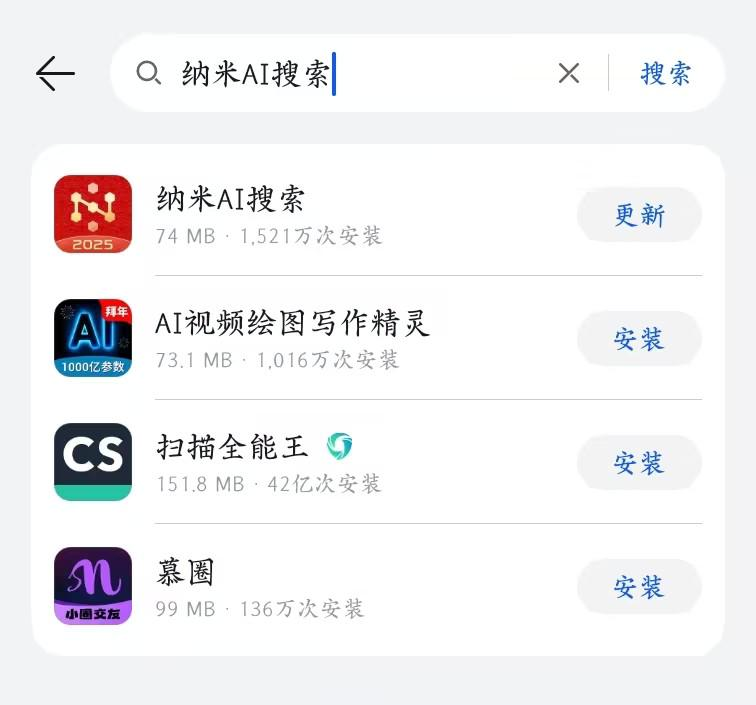
或者通过扫描下面的手机端下载注册二维码:

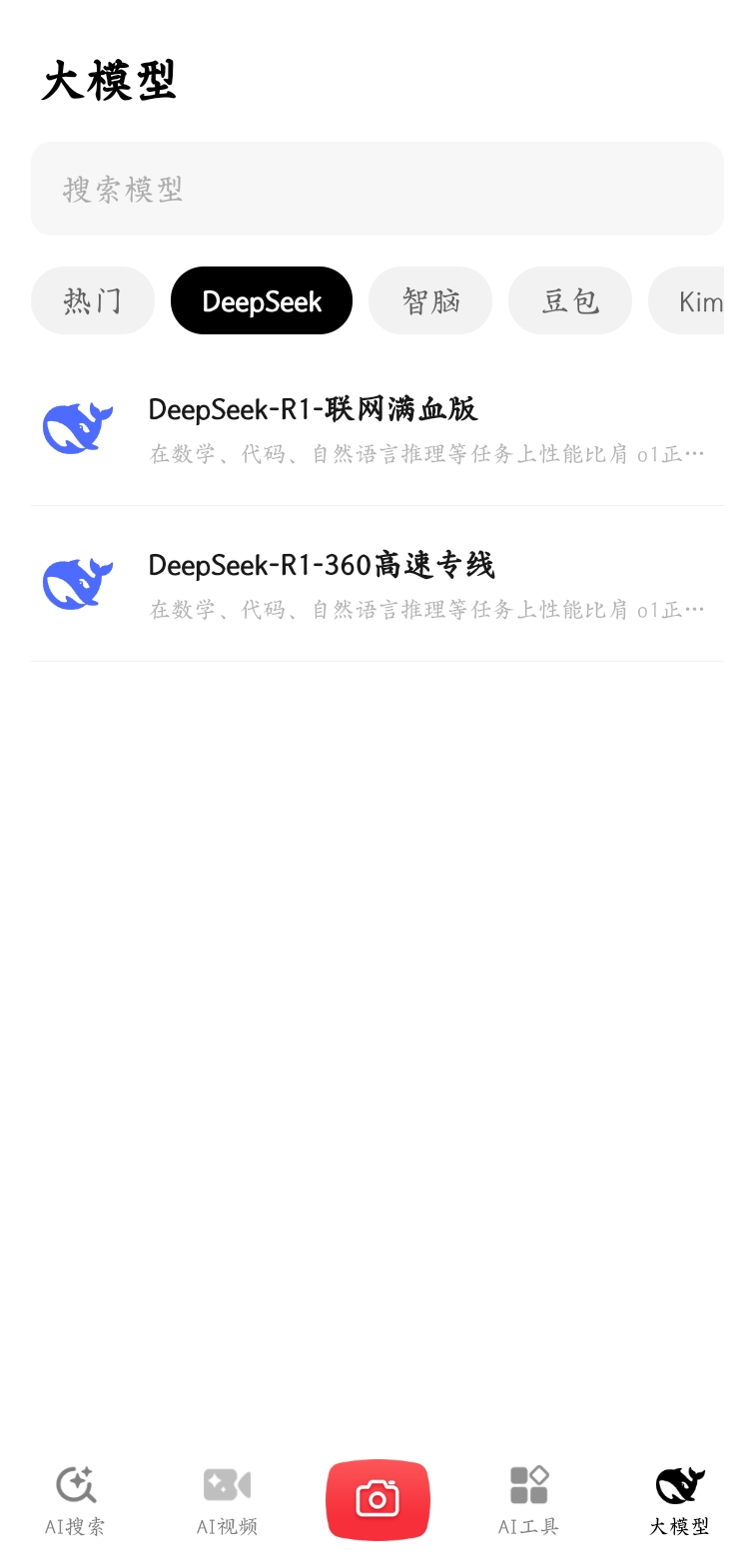
2️⃣ 打开APP→左下角「AI搜索」→选择「DeepSeek专线」
3️⃣ 点击「DeepSeek-R1-联网满血版」标识(进入对话框即为成功)
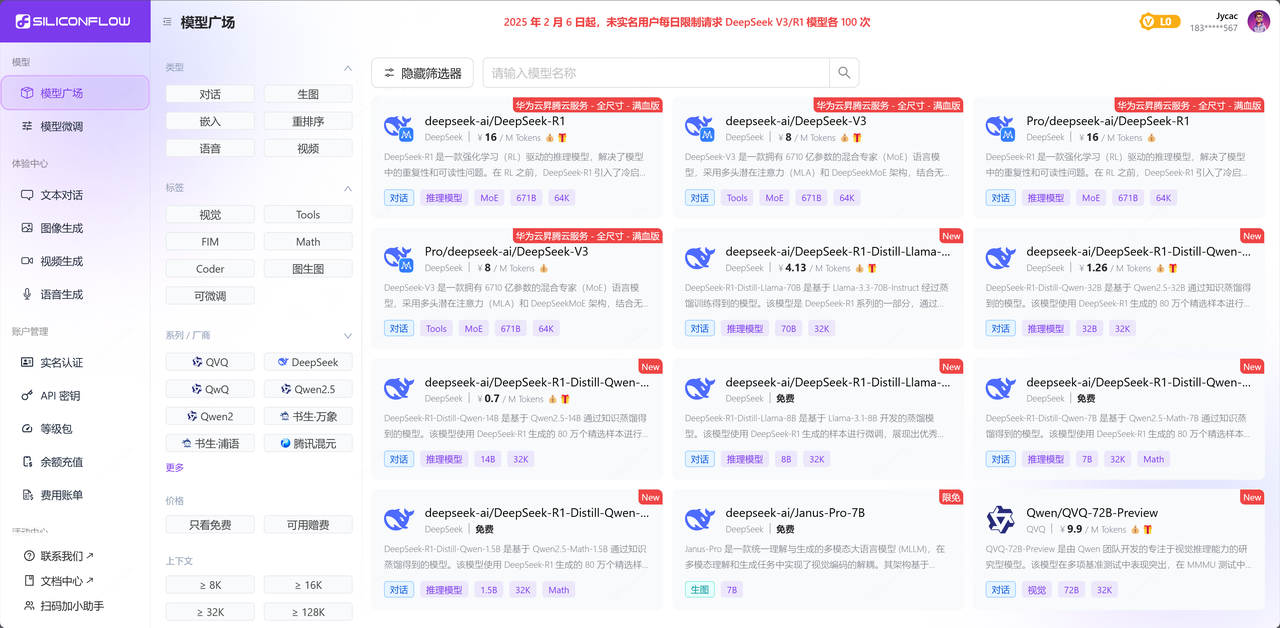
3 硅基流动(siliconflow)
✅ 推荐指数: 🌟🌟🌟🌟,支持众多模型
💡 特点: API 直连满血版,更适合开发者,尤其预算敏感或者需要集成多模型的开发者
使用方式: 调用方式与 OpenAPI 接口一致,开发者可以无缝迁移代码。
使用场景: 企业搭建 AI 助手、独立开发各种 AI 应用
目前注册就送 2 千万 Token,推荐一下我的注册链接:
https://cloud.siliconflow.cn/i/V5dNv0xi
👉 API 使用步骤
- 注册并获取 API 密钥
- 配置客户端、网页插件(如 ChatBox、Cursor AI),填入你的 API 密钥和服务地址
- 开始使用
4 秘塔 AI 搜索
✅ 推荐指数: 🌟🌟🌟🌟🌟
使用地址 :https://metaso.cn/
使用步骤: 选择“长思考-R1”,就会使用的 DeepSeek-R1 模型。
特点: AI 搜索,适用小白,无需注册,界面简单(类似百度、必应等网页搜索框)
缺点: 模型可能不是满血版,思考过程不及前面的使用方式
5 其他方式
最近,DeepSeek着实火出了圈!如今,众多 API 或聚合 AI 搜索工具,都忙着拿接入 DeepSeek 当作宣传噱头,热度居高不下。
大家都知道,天下没有免费的午餐。DeepSeek 当前的免费使用,确实给用户带来了不少实惠,可未来呢?前期的免费或补贴,就像诱人的开胃菜,之后会不会悄然变味,谁也说不准。
看看国内华为云昇腾云服务、阿里云百炼、字节火山引擎、百度云千帆、国家超算互联网平台。
国外英伟达 NIM、POE、Fireworks AI、GroqCloud(70B)这些。
但我就不在这里一一详细汇总了,毕竟“少即是多”,有时候信息精简反而更有力量。再说,真正对这些感兴趣的高手,就算不看我这篇教程,搭建和使用起来也是轻车熟路。
话说回来,科技世界日新月异,我相信肯定还有不少藏在角落里的“宝藏”工具。要是你发现了更好用的工具,不妨在留言区分享一下。我一有空,就把大家的推荐汇总整理出来,咱们一起探索更广阔的 AI 天地!
欢迎关注《宇宙之一粟》,一起学习 DeepSeek,一起学习 AI !


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









