







Python抓取网页内容的方法很多,常用的有BeautifulSoup、re、xpath等。
在前述应用中,主要通过BeautifulSoup4 的find、select 抓取网页信息,这里做下简单说明
def getSoufangList ( self , fang_url , args ):'''根据传入的网页入口,逐页爬取房源清单信息。并存入MySQL数据库。这里主要通过BeautifulSoup4 的find、select 抓取网页信息,有个别字段不是标准网页元素,通过select、xpath无法获取所有信息,故多种方式并用。:param fang_url:根据传入的URL(可以在城市、一级行政区域、二级行政区域链接入口),搜房网比链家规整,各城市、层级 房源信息格式基本一致,可以公用。:param args:这里的参数是一个数据,因为房源明细信息不全(如没有包含行政区域等),通过数组封装起来,可以把房源的城市、行政区域、URL入口等一并传入保存至数据库,参数数量又不至于太多:return: 返回房源详细信息'''base_url = args [ 'base_url' ]result = {}res = getURL ( fang_url )res . encoding = 'gbk'soup = BeautifulSoup ( res . text , 'html.parser' )#这里使用CSS获取房源信息列表,用chrome浏览器的审查元素方法,发现搜房网房源核心信息所在位置均为class为info rel floatr 的dd tag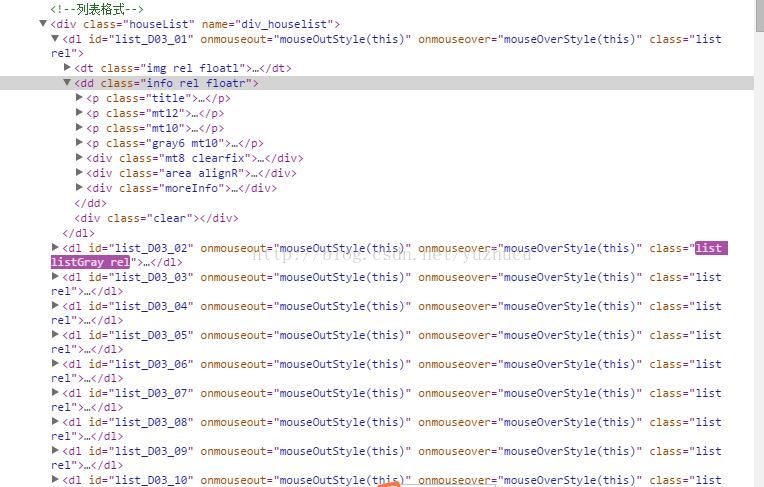 for fang in soup . find_all ( "dd" , class_ = "info rel floatr" ):#下面详细字段的获取主要通过css选择器来获取。Beautiful Soup支持大部分的CSS选择器 , 在
for fang in soup . find_all ( "dd" , class_ = "info rel floatr" ):#下面详细字段的获取主要通过css选择器来获取。Beautiful Soup支持大部分的CSS选择器 , 在Tag或BeautifulSoup对象的.select()方法中传入字符串参数, 即可使用CSS选择器的语法找到tag:try :#这里找到第一个p tag中的超链接a['href'],并去掉前后的空格result [ 'fang_key' ] = fang . select ( 'p' )[ 0 ] . a [ 'href' ] . strip ()result [ 'city' ] = args [ 'city' ]result [ 'quyu' ] = args [ 'region' ]result [ 'bankuai' ] = args [ 'subRegion' ]#获取房源的描述信息,即第一个p tag的textresult [ 'fang_desc' ] = fang . select ( 'p' )[ 0 ] . text . strip ()result [ 'fang_url' ] = base_url + fang . select ( 'p' )[ 0 ] . a [ 'href' ] . strip ()# 户型、楼层、朝向等多个元素都在第二个p tag中,并通过span分割,没法根据名字区分;这里可以用p tag的.contents属性将其子节点以列表的方式输出result [ 'huxing' ] = fang . select ( 'p' )[ 1 ] . contents [ 0 ] . strip ()result [ 'louceng' ] = fang . select ( 'p' )[ 1 ] . contents [ 2 ] . strip ()result [ 'chaoxiang' ] = fang . select ( 'p' )[ 1 ] . contents [ 4 ] . strip ()try :result [ 'age' ] = fang . select ( 'p' )[ 1 ] . contents [ 6 ] . strip ()except Exception as e :# 建筑年代和朝向可能不全,如缺失先放一样,先确保房源信息完没有丢失result [ 'age' ] = result [ 'chaoxiang' ]print self . getCurrentTime (), u"Exception: %s " % ( e . message ), result [ 'fang_url' ], result ['fang_desc' ], 'chaoxiang:' , result [ 'chaoxiang' ], 'age:' , result [ 'age' ]result [ 'xiaoqu' ] = fang . select ( 'p' )[ 2 ] . span . text . strip ()#为什么这里用find不用select?想一想result [ 'address' ] = fang . find ( 'span' , 'iconAdress ml10 gray9' ) . get_text ()#这里可以尝试用不同的方式达到同样的效果,上面其实也可以# result['subway']=fang.find('span','train note').text.strip()# result['subway']=fang.select('div.mt8.clearfix > div.pt4.floatl > span.train.note')[0].text# result['subway']=fang.select('div')[0].text.strip()result [ 'mianji' ] = fang . find ( 'div' , 'area alignR' ) . get_text () . strip ()# result['mianji'] = fang.find('div', 'area alignR').get_text().encode("utf-8").strip().strip('建筑面积').strip()mianji = fang . find ( 'div' , 'area alignR' ) . get_text () . encode ( "utf-8" ) . strip () . strip ( '建筑面积' ) . strip ()# result['mianji']=mianji#边测边改,不清楚的打印出来遛遛就知道了# print type( result['mianji']),type(mianji),type(fang.find('div', 'area alignR').get_text().encode("utf-8").strip().strip('建筑面积').strip())result [ 'price' ] = fang . find ( 'span' , 'price' ) . get_text () . strip ()#这里尝试使用下CSS选择器,可以直接在审查元素时用copy css path方式快速获取result [ 'price_pre' ] = fang . select ( 'div.moreInfo > p.danjia.alignR.mt5' )[ 0 ] . get_text () . strip ()# print fang.select('div.moreInfo > p.danjia.alignR.mt5')[0].get_text().strip()result [ 'data_source' ] = 'Soufang'result [ 'updated_date' ] = time . strftime ( '%Y-%m- %d %H:%M:%S' , time . localtime ( time . time ()))mySQL . insertData ( 'soufang_fang_list' , result )# print resultprint self . getCurrentTime (), u'在售:' , result [ 'city' ], result [ 'quyu' ], result [ 'bankuai' ], result [ 'xiaoqu' ], result [ 'address' ], \result [ 'huxing' ], result [ 'louceng' ], result [ 'chaoxiang' ], result [ 'price' ], u'万' , result ['price_pre' ], mianji , result [ 'fang_desc' ]except Exception as e :print self . getCurrentTime (), args [ 'city' ], args [ 'region' ], args [ 'subRegion' ], ':' , u"Exception: %s " % ( e . message ), result [ 'fang_url' ], result [ 'fang_desc' ]return result
附 BeautiifulSoup4 中文翻译,这里仅将常用的列出,便于后续快速查阅,全文链接参考: http://docs.pythontab.com/beautifulsoup4/#
find_all() 参考
find_all( name , attrs , recursive , string , **kwargs )
find_all()方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:soup.find_all("title") # [<title>The Dormouse's story</title>] soup.find_all("p", "title") # [<p class="title"><b>The Dormouse's story</b></p>] soup.find_all("a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find_all(id="link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] import re soup.find(string=re.compile("sisters")) # u'Once upon a time there were three little sisters; and their names were\n'有几个方法很相似,还有几个方法是新的,参数中的
string和id是什么含义? 为什么find_all("p", "title")返回的是CSS Class为”title”的<p>标签? 我们来仔细看一下find_all()的参数name 参数
name参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉.简单的用法如下:
soup.find_all("title") # [<title>The Dormouse's story</title>]重申: 搜索
name参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是True.keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为
id的参数,Beautiful Soup会搜索每个tag的”id”属性.soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]如果传入
href参数,Beautiful Soup会搜索每个tag的”href”属性:soup.find_all(href=re.compile("elsie")) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含
id属性的tag,无论id的值是什么:soup.find_all(id=True) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>') data_soup.find_all(data-foo="value") # SyntaxError: keyword can't be an expression但是可以通过
find_all()方法的attrs参数定义一个字典参数来搜索包含特殊属性的tag:data_soup.find_all(attrs={"data-foo": "value"}) # [<div data-foo="value">foo!</div>]按CSS搜索 参考
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字
class在Python中是保留字,使用class做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过class_参数搜索有指定CSS类名的tag:soup.find_all("a", class_="sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
class_参数同样接受不同类型的过滤器,字符串,正则表达式,方法或True:soup.find_all(class_=re.compile("itl")) # [<p class="title"><b>The Dormouse's story</b></p>] def has_six_characters(css_class): return css_class is not None and len(css_class) == 6 soup.find_all(class_=has_six_characters) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]tag的
class属性是 多值属性 .按照CSS类名搜索tag时,可以分别搜索tag中的每个CSS类名:css_soup = BeautifulSoup('<p class="body strikeout"></p>') css_soup.find_all("p", class_="strikeout") # [<p class="body strikeout"></p>] css_soup.find_all("p", class_="body") # [<p class="body strikeout"></p>]搜索
class属性时也可以通过CSS值完全匹配:css_soup.find_all("p", class_="body strikeout") # [<p class="body strikeout"></p>]完全匹配
class的值时,如果CSS类名的顺序与实际不符,将搜索不到结果:soup.find_all("a", attrs={"class": "sister"}) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
find() 参考
find( name , attrs , recursive , string , **kwargs )
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的:
soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]
soup.find('title')
# <title>The Dormouse's story</title>
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# None
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>
CSS选择器 原文
Beautiful Soup支持大部分的CSS选择器 http://www.w3.org/TR/CSS2/selector.html [6] , 在 Tag 或BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag:
soup.select("title")
# [<title>The Dormouse's story</title>]
soup.select("p nth-of-type(3)")
# [<p class="story">...</p>]
通过tag标签逐层查找:
soup.select("body a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("html head title")
# [<title>The Dormouse's story</title>]
找到某个tag标签下的直接子标签 [6] :
soup.select("head > title")
# [<title>The Dormouse's story</title>]
soup.select("p > a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("p > a:nth-of-type(2)")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
soup.select("p > #link1")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select("body > a")
# []
找到兄弟节点标签:
soup.select("#link1 ~ .sister")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("#link1 + .sister")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过CSS的类名查找:
soup.select(".sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("[class~=sister]")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过tag的id查找:
soup.select("#link1")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select("a#link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
同时用多种CSS选择器查询元素:
soup.select("#link1,#link2")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过是否存在某个属性来查找:
soup.select('a[href]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过属性的值来查找:
soup.select('a[href="http://example.com/elsie"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select('a[href^="http://example.com/"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href$="tillie"]')
# [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href*=".com/el"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
通过语言设置来查找:
multilingual_markup = """
<p lang="en">Hello</p>
<p lang="en-us">Howdy, y'all</p>
<p lang="en-gb">Pip-pip, old fruit</p>
<p lang="fr">Bonjour mes amis</p>
"""
multilingual_soup = BeautifulSoup(multilingual_markup)
multilingual_soup.select('p[lang|=en]')
# [<p lang="en">Hello</p>,
# <p lang="en-us">Howdy, y'all</p>,
# <p lang="en-gb">Pip-pip, old fruit</p>]
返回查找到的元素的第一个
soup.select_one(".sister")
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
对于熟悉CSS选择器语法的人来说这是个非常方便的方法.Beautiful Soup也支持CSS选择器API, 如果你仅仅需要CSS选择器的功能,那么直接使用 lxml 也可以, 而且速度更快,支持更多的CSS选择器语法,但Beautiful Soup整合了CSS选择器的语法和自身方便使用API.
子节点
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点.Beautiful Soup提供了许多操作和遍历子节点的属性.
注意: Beautiful Soup中字符串节点不支持这些属性,因为字符串没有子节点
tag的名字
操作文档树最简单的方法就是告诉它你想获取的tag的name.如果想获取 <head> 标签,只要用soup.head :
soup.head
# <head><title>The Dormouse's story</title></head>
soup.title
# <title>The Dormouse's story</title>
这是个获取tag的小窍门,可以在文档树的tag中多次调用这个方法.下面的代码可以获取<body>标签中的第一个<b>标签:
soup.body.b
# <b>The Dormouse's story</b>
通过点取属性的方式只能获得当前名字的第一个tag:
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
如果想要得到所有的<a>标签,或是通过名字得到比一个tag更多的内容的时候,就需要用到 Searching the tree 中描述的方法,比如: find_all()
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
.contents 和 .children
tag的 .contents 属性可以将tag的子节点以列表的方式输出:
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
BeautifulSoup 对象本身一定会包含子节点,也就是说<html>标签也是 BeautifulSoup 对象的子节点:
len(soup.contents)
# 1
soup.contents[0].name
# u'html'
字符串没有 .contents 属性,因为字符串没有子节点:
text = title_tag.contents[0]
text.contents
# AttributeError: 'NavigableString' object has no attribute 'contents'
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's story
.descendants
.contents 和 .children 属性仅包含tag的直接子节点.例如,<head>标签只有一个直接子节点<title>
head_tag.contents
# [<title>The Dormouse's story</title>]
但是<title>标签也包含一个子节点:字符串 “The Dormouse’s story”,这种情况下字符串 “The Dormouse’s story”也属于<head>标签的子孙节点. .descendants 属性可以对所有tag的子孙节点进行递归循环 [5] :
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's story
上面的例子中, <head>标签只有一个子节点,但是有2个子孙节点:<head>节点和<head>的子节点,BeautifulSoup 有一个直接子节点(<html>节点),却有很多子孙节点:
len(list(soup.children))
# 1
len(list(soup.descendants))
# 25
.string
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点:
title_tag.string
# u'The Dormouse's story'
如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的.string 结果相同:
head_tag.contents
# [<title>The Dormouse's story</title>]
head_tag.string
# u'The Dormouse's story'
如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None :
print(soup.html.string)
# None
.strings 和 stripped_strings
如果tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取:
for string in soup.strings:
print(repr(string))
# u"The Dormouse's story"
# u'\n\n'
# u"The Dormouse's story"
# u'\n\n'
# u'Once upon a time there were three little sisters; and their names were\n'
# u'Elsie'
# u',\n'
# u'Lacie'
# u' and\n'
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'\n\n'
# u'...'
# u'\n'
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容:
for string in soup.stripped_strings:
print(repr(string))
# u"The Dormouse's story"
# u"The Dormouse's story"
# u'Once upon a time there were three little sisters; and their names were'
# u'Elsie'
# u','
# u'Lacie'
# u'and'
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'...'
全部是空格的行会被忽略掉,段首和段末的空白会被删除















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









