







本篇文章是在上一篇的的基础上所写,前文已经详细讲解了在怎样配置单机伪分布式的Hadoop,本文着重于完全分布式的配置。此次Hadoop的配置主要是参考了官网及网络上一些教程总结而来,初次搭建,如有错误,多谢指点。
伪分布式:http://blog.csdn.net/yuzhuzhong/article/details/49922845
本教程所使用的集群环境: 两台虚拟机,一台作为 Master,局域网 IP 为 192.168.9.131;另一台作为 Slave,局域网 IP 为 192.168.9.133。Java环境安装配置、Hadoop安装、SSH 安装等已在前文中介绍,此次将不再叙述。
一、先在一台虚拟机上完成伪分布式的安装
虚拟机Ubuntu下Hadoop2.6.1的安装和配置(伪分布式)
二、克隆得到第二台相同配置的
1.克隆之前需关闭客户机
2.如下图所示左侧需选中要克隆的虚拟机。
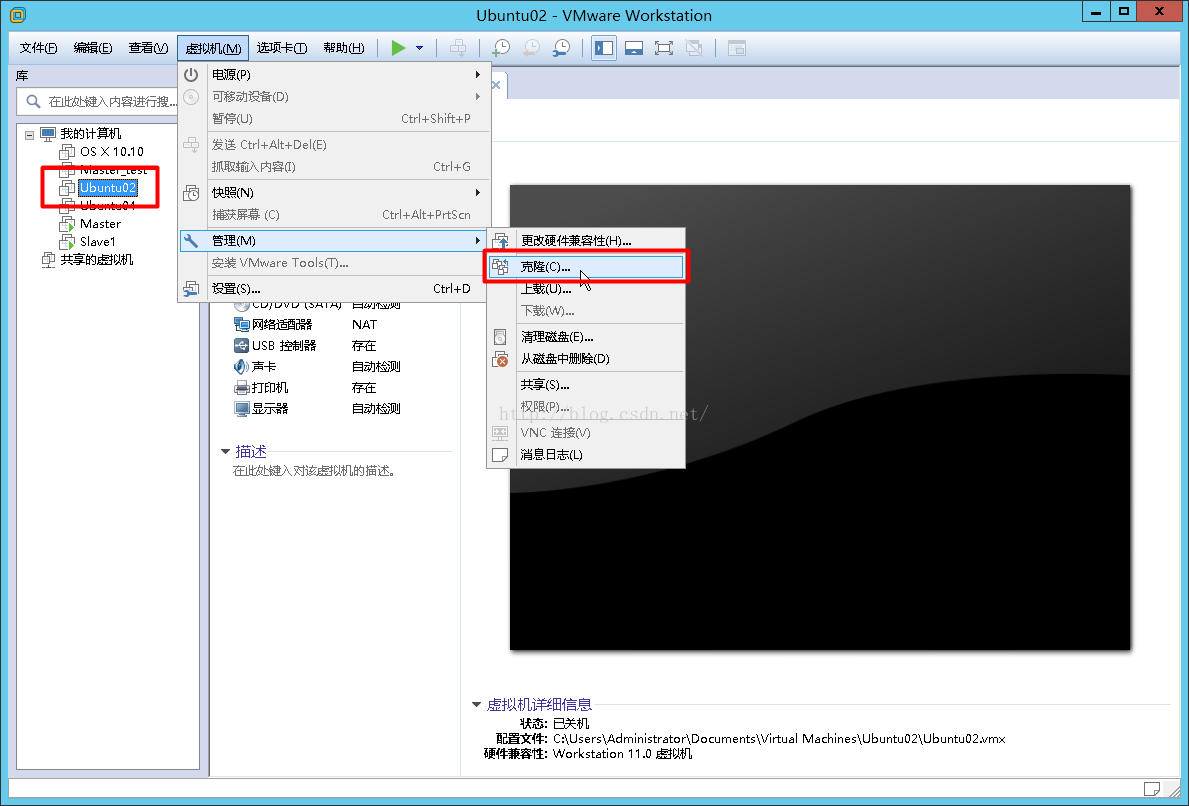
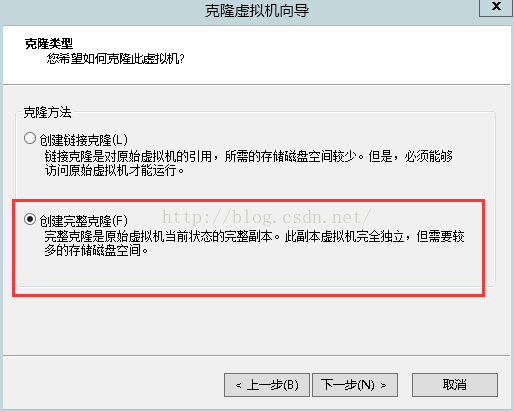
4.其他都选择默认
三、网络配置
1.进行集群配置之前需先关闭Hadoop:/usr/hadoop/hadoop-2.6.1/sbin/stop-dfs.sh
2.现有两台虚拟机,ip地址分别为192.168.9131和192.168.9133。选取其中一台虚拟机作为Master(如我选取的是192.168.9.131这台),然后在/etc/hostname文件中修改机器名为Master,另一台修改为Slave1。
3.在/etc/hosts文件中把所有集群的主机信息都写进去,若图所示
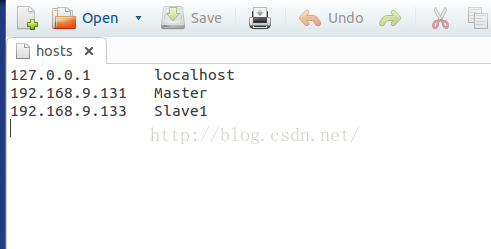
其中只能有一个127.0.0.1,对应为localhost,否则会出错。
4.注意,该网络配置需要在所有主机上进行
如上面讲的是 Master 主机的配置,而在其他的 Slave 主机上,也要对 /etc/hostname(修改为 Slave1、Slave2等) 和 /etc/hosts(一般跟 Master 上的配置一样) 这两个文件进行相应的修改!
5.最好重启一下。
6.别忘了把虚拟机名字改为相对应的(好像不影响使用,只是为了好区分一点)

四、虚拟机之间ping连通
我是在同一台物理机上搭建的两台虚拟机,使用NAT联网,ip地址在同一网段,所以可以ping通。如图
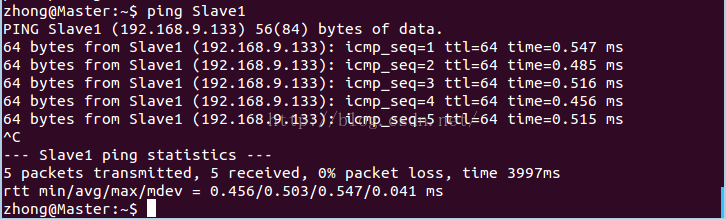
ping的过程一直持续,可以使用“Ctrl”+"C"按键停止。
五、SSH无密码登录节点
这个操作是让Master可以无密码直接登录到SSH节点上。
由于之前伪分布式配置是已能无密码localhost登录,可直接使用命令:ssh Slave1 若出现
六、集群配置(分布式环境)
本次需修改HADOOPHOME/etc/hadoop 中五个文件(注意所有主机中都得相同的更改)
1.slave文件
将原来 文件localhost 删除,把所有Slave的主机名写上,每行一个。例如我只有一个 Slave节点,那么该文件中就只有一行内容: Slave1。
2.core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3.hdfs-site.xml文件,因为只有一个Slave,所以dfs.replication的值设为1。
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.6.1/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.mapred-site.xml 文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
其中红色标注的部分需要根据自己安装目录修改。
6.切换 Hadoop 模式应删除之前的临时文件(此处为他人借鉴得来)
切换 Hadoop 的模式,不管是从集群切换到伪分布式,还是从伪分布式切换到集群,如果遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。或者可以为集群模式和伪分布式模式设置不同的临时文件夹(未验证)。所以如果集群以前能启动,但后来启动不了,特别是 DataNode 无法启动,不妨试着删除所有节点(包括 Slave 节点)上的 tmp 文件夹,重新执行一次bin/hdfs namenode -format,再次启动试试。
七、启动及验证
1.在Master节点上启动Hadoop
首先得进入安装目录:cd /usr/hadoop/hadoop-2.6.1
首次运行需执行格式化:bin/hdfs namenode-format
启动:sbin/start-dfs.sh
sbin/start-yarn.sh
成功启动后可用jps命令查看各个节点的

可以看到Master节点启动了NameNode、SecondrryNameNode、ResourceManager进程。

Slave节点则启动了DataNode和NodeManager进程。
关闭Hadoop集群也是在Master节点上执行(HADOOPHOME目录下):
sbin/stop-dfs.sh
sbin/stop-yarn.sh
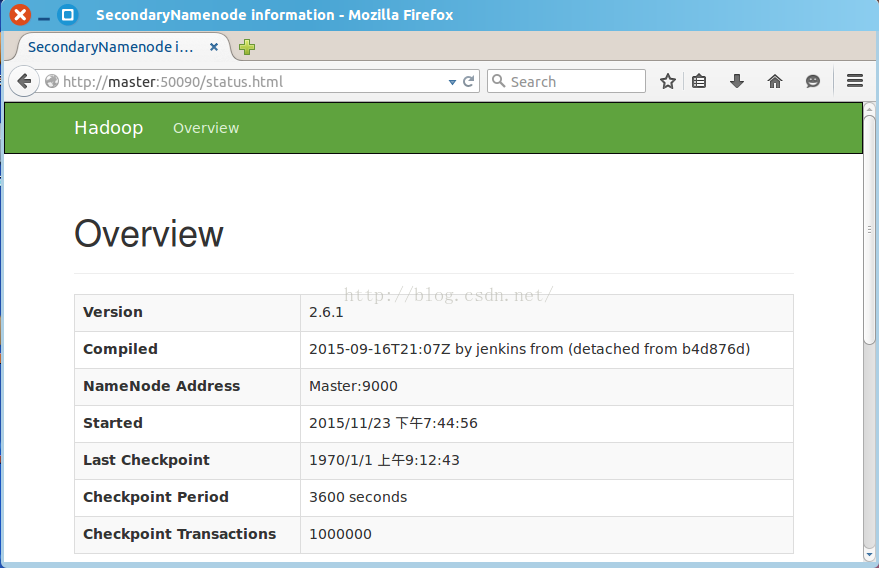
2.验证,可在Master或者Salve节点浏览器打开地址:http:// master:50090
通过查看启动日志分析启动失败原因
有时Hadoop集群无法正确启动,如 Master 上的 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,不过新手可能需要注意几点:
- 启动时会提示 “Master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-Master.out”,但其实启动日志信息是记录在 /usr/local/hadoop/logs/hadoop-hadoop-namenode-Master.log 中;
- 每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,这个看下记录的时间就知道了。
- 一般出错的提示在最后面,也就是写着 Error 或者 Java 异常的地方。
也可以通过Web页面看到查看DataNode和NameNode的状态,http://master:50070/















 2585
2585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









