







前言:
本章的内容上的理解并不困难,但最大熵模型的代码实现较为困难,其主要原因是李航老师的《统计学习方法》中关于特征函数fi(x,y)的解释为了追求泛化而让人感到迷惑。
这里感谢pku的大佬Dodo提供的思路和解释,本文章在Dodo实现的最大熵模型的基础上做了略微的改进,使得该模型可以对多标签(类别大于2)数据进行分类。
Dodo的博客:统计学习方法|最大熵原理剖析及实现 | Dodo
一、实现思路
1.1 文章所用的简单数据集
为了便于后文的解释,使用的简单训练数据集如下:
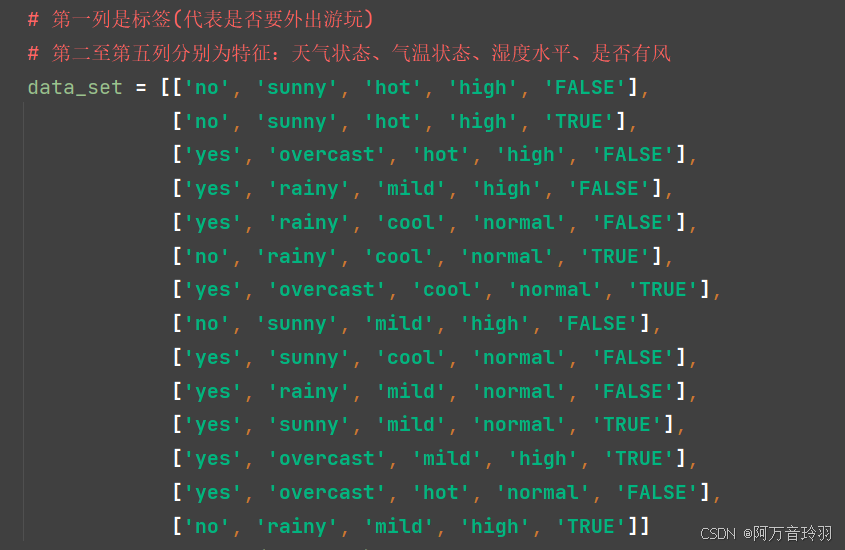
1.2 最大熵模型的基本形式

由课本内容可知,上图为该最大熵模型的具体形式。其作用是当给定测试数据X时,该模型输出每种类别的概率。
例如输入:X=['sunny', 'hot', 'high', 'FALSE'],输出:[('no', 0.9094), ('yes', 0.0905)]。
1.3 最大化目标函数

我们的目标是通过更新每个特征函数前面的拉格朗日乘子wi,使得对数似然函数达到最大。
本文使用的方法是改进迭代尺度算法(IIS)。

由于最大熵模型的参数w是一个序列(列表),其长度等于特征函数的数量n,所以在IIS中每次迭代更新时我们也需要一个σ序列,让w序列中的每个wi = wi+σi。
所以现在我们需要在每次迭代中得到一个σ序列,而计算σ序列中的每个σi都需要三个值,
分别是M、fi(x,y)的经验期望、fi(x,y)的期望。
1.3.1 关于特征函数fi(x,y)的解释


实际上特征函数真正的形式并非是fi(X,y) = fi( X = ['sunny', 'hot', 'high', 'FALSE'], y = ['no'] )的样子。而是对于该训练数据(X, y)生成的特征函数如下:
f1(x1,y) = (['sunny'] , ['no'])
f2(x2,y) = (['hot'] , ['no'])
f3(x3,y) = (['high'] , ['no'])
f4(x4,y) = (['FALSE'] , ['no'])
同样书中的P_(x)和P_(x, y)也是针对单一特征而言,例如P_(x,y) = P_(['sunny'] , ['no'] )。
1.3.2 关于IIS迭代过程的细节
其实从IIS算法求σ序列的过程我们可以发现一个细节,那就是在计算σi的过程中,log分子上的经验期望实际上是一成不变的,这是因为fi(x,y)的经验期望公式中没有涉及到最大熵模型P(y | x),而分母的fi(x,y)期望公式由于涉及到最大熵模型,所以每次迭代都需要重新计算fi(x,y)期望公式(因为上次迭代之后最大熵模型发生了更新)。
1.4 部分代码解释
1.4.1 fit函数
(1)首先我们给定训练数据和训练数据的标签。
(2)对训练数据和标签进行初始化,得到我们需要的各种变量。
(3)在指定迭代次数之内,按照IIS步骤进行:先求特征函数的期望(非经验)Epxy,再生成σ序列(利用M,fixy的经验期望,fixy的期望计算),然后利用σ序列对参数w进行更新。
def fit(self, x_train, y_train):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









