






注:仅展示部分文档内容和系统截图,需要完整的视频、代码、文章和安装调试环境请私信up主。
目 录
基于网络爬虫的招聘数据分析与可视化系统设计与实现
摘要:科学技术的快速发展,在面对网络招聘时我们会接收到大量的数据,网络爬虫能够定向抓取数据且快速的寻找出可用的数据,因此将海量的、庞大的数据通过可视化的方式进行展示,更有利于数据的理解和利用。本文介绍了基于网络爬虫的招聘数据分析系统的设计与实现的开发过程,包括开发环境介绍,系统设计框架以及数据库详细设计。该系统采用Python开发语言及Web框架Django,利用Pycharm开发平台完成系统的设计和实现,主要包括数据采集、数据导入、数据处理、数据分析、数据可视化等五个功能模块。系统首先用网络爬虫技术爬取中华英才网中的职位信息,然后用BeautifulSoup库解析网页内容,提取职位信息并保存。再将数据文件导入到系统中,接着进行去重、去空及数据的统一化,并用Jieba中文分词库将职位描述字段进行分词处理,最后通过统计词频的方式得到对应的热门职位。使用户能够高效的理解和分析招聘数据信息,更有利于用户明确学习方向,以及所需要掌握的工作技能和知识。
关键词:网络爬虫 数据处理 数据库 数据可视化 Python
-
- 研究内容
系统使用Flask web做框架,对招聘城市的城市编号爬取,根据在线招聘网站的URL规则,通过拼接获取招聘网站的城市URL,根据收到的URL进入招聘页面,观察页面结构组成使用标签定位,扫描职位信息,职位采集,职位浏览量等我们需要的数据。
通过 Django-allauth 将 Django 用于 Web 端,以便用户可以输入帐户、密码、个人信息进行注册,用户输入帐户密码以登录。
通过Python的Requests模块去网站爬取招聘市数据,通过Pandas对数据进行清理和解析,对数据的空值等进行处理,然后存入数据库。
可视化页面,使用Js的可视化框架Echarts实现数据交互式的可视化。
-
- 系统的需求分析
需求分析阶段是在设计系统之前必须定义的一个重要过程,因为系统的整体架构是基于需求的。它的首要任务是确定系统的目标是什么,以及系统应该如何设计以满足用户的需求。因此,只有仔细分析系统的要求,我们才能创建一个符合需求的系统。该系统的主要目的是为网站设计开发Python招聘数据分析管理系统,高效满足网站运营的各种需求,使管理更加方便多样,使计算机在网站区域发挥更高效、更灵活的功能。
-
- 功能分析
如下表4.1所示:
表4.1系统的角色分类
| 1、注册登录 2、数据采集模块 3、数据查询模块 4、数据处理模块 5、数据可视化 |
-
-
- 系统用例图
-
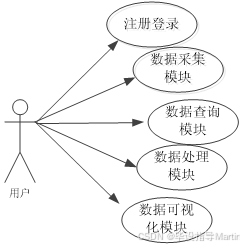
数据获取模块通过标签定位,爬取所需要的岗位等信息,将得到的数据进行处理,之后存入数据库内,最后通过可视化框架实现数据交互。
URL 是访问可从 Internet 检索的资源的位置和方法以及 Internet 上的标准资源地址的综合表示。互联网上的每个文件都有一个唯一的URL,其中包含指示文件位置的信息[15]。
- 通过url获取网站源码
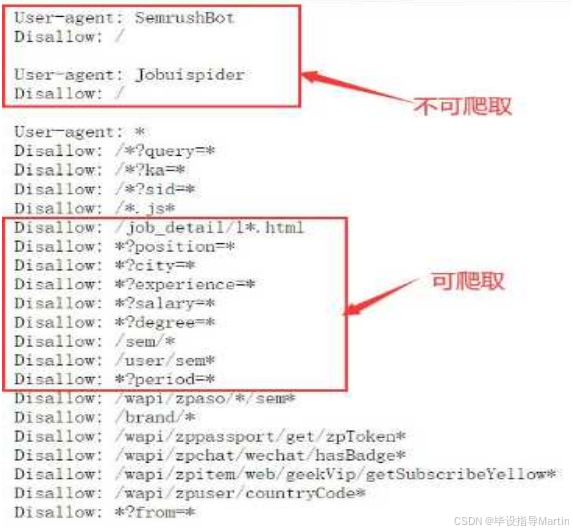
通过Pandas对数据进行清理和解析。
首先,导入数据分析的库。
import pandas as pd
import matplotlib.pyplot as plt
import wordcloud as spark_cloud # 词云展示库
增加一个配置顶,解决matplotlib中文乱码的问题。
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块问题
Mysql数据库体积小、速度快、总体拥有成本低且开源;支持多种操作系统;提供的接口支持多种语言连接操作[16];
网站开发人员是MySQL最大的客户群,也是MySQL历史上最重要的支持力量。Mysql之所以能成为网站开发者最流行的数据库管理系统,是因为安装和配置Mysql数据库非常简单,使用过程中的维护也不像很多大型商业数据库管理系统那么复杂,而且性能出色[17] 。
招聘信息实体主要的成员属性有:工作岗位、单位名称、工作类型、工资待遇、工作地点、福利待遇、经验要求、公司规模、发布时间、学历要求。招聘信息实体属性图如图4.8所示。
- 系统实现
- 系统登录
用户在电脑上使用系统时,需要登录,在界面中输入相应的账号和密码,还需要正确填写,点击“提交”,系统会将用户提供的账号和密码与自己数据库中的相应数据进行比较,数据返回给系统,系统做出判定并提示登录成功才能进入系统首页。该Python招聘数据分析管理系统如图5.1所示:

-
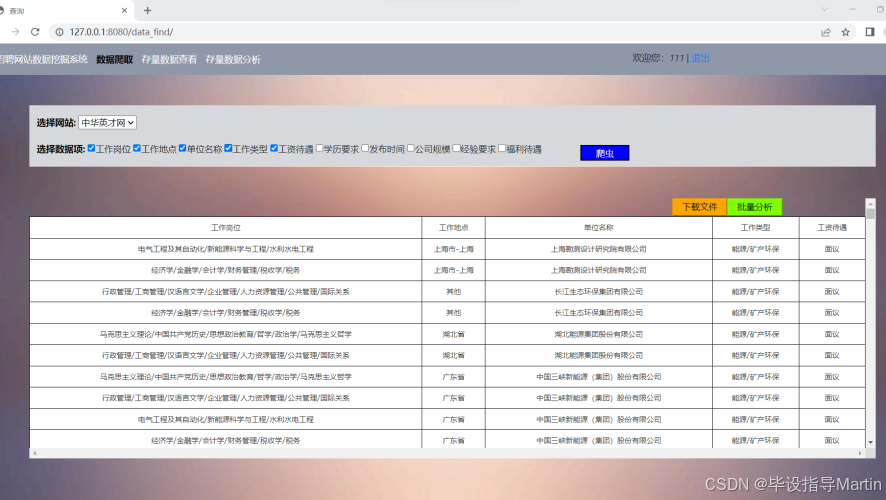
- 数据查询
下面以爬取中华英才网中工作岗位、工作地点、单位名称、工作类型、工资待遇为例,可以看到所爬取的结果。如图5.3所示。
-
- 读取数据
获取前程无忧网和中华英才网中的网站数据,核心代码如下:
website_list = ['前程无忧网', '中华英才网']
item_list = ['工作岗位', '工作地点', '单位名称', '工作类型', '工资待遇', '学历要求', '发布时间', '公司规模', '经验要求', '福利待遇']
return render(request, 'data_find.html', context={'website_list':website_list, 'item_list':item_list})
-
- 数据清洗
根据该系统的需求数据清洗模块,需要由程序员通过爬虫程序对爬取到的原始数据进行清洗工作。通常情况下,需要通过编写一串代码将原始数据的数据格式进行统一,并进行修补缺失的数据等操作。核心代码如下:
first = re.compile(r' ') # compile构造去掉空格的正则
time_for_sub = first.sub('', city_to_people[each]) # 把空格替换为没有,等于去掉空格
another = re.compile(r'/') # compile构造去掉/的正则
the_final_info = another.sub('', time_for_sub) # 把/替换为空格,等于去掉/
-
- 防止反爬
对于反爬虫,是通过构建headers,伪造成浏览器去爬信息。核心代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
df = pd.DataFrame(columns=header_list)
df.to_csv(os.path.join(settings.UPLOADFILES_DIRS,'51job.csv'), encoding='utf_8_sig', index=False, sep=',')
-
- 数据库存储
MySQL数据库的存储可以理解为将数据以表格的形式存储在一个或多个文件中,这些文件可以存储在计算机的硬盘或云端服务器中。核心代码如下:
import pyMysql
pyMysql.install_as_Mysqldb()# 告诉django用pyMysql代替Mysqldb连接数据库
import pandas as pd
file_name_list = ['51job.csv', 'zhyc.csv']
-
- 数据库可视化
数据可视化是指将MySQL数据库中的数据以图表、表格、地图等形式展示出来,使用户更直观地了解数据的含义和趋势。可通过柱状图实现数据库的可视化。核心代码如下:
# 工作城市数
if '工作地点' in headers:
worklocation = csv_data['工作地点'].tolist()
city_list = [each.split('-')[0] for each in worklocation if each != '']
# 工作地点分析图
sorted_city_count_dict = sorted(city_count_dict.items(), key=lambda item: item[1], reverse=True)[0:10]
plt.title("工作地点分析柱状图")
plt.ylabel('岗位数', fontsize=10)
plt.xlabel('工作地点', fontsize=10)
# 学历要求类数
if '学历要求' in headers:
graduation_list = csv_data['学历要求'].tolist()
plt.title("学历要求分析饼图")
picture_list.append('../static/assets/images/videos/picture2.png')
#福利待遇
if '福利待遇' in headers:
raw_benefit_list = csv_data['福利待遇'].tolist()
mask = np.array(Image.open(os.path.join(settings.UPLOADFILES_DIRS, '51job.jpg')))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









