









HDFS体系架构(最全)
参考博客:https://blog.csdn.net/Lord_War/article/details/78727049
汇总:https://www.cnblogs.com/meet/p/5439805.html
NN:http://www.cnblogs.com/zlslch/p/5081112.html
DN:http://www.cnblogs.com/zlslch/p/5081183.html
CLIENT:http://www.cnblogs.com/zlslch/p/5081200.html
辅以:《hadoop中NameNode、DataNode、Secondary、NameNode、ResourceManager、NodeManager 介绍》
HDFS总体架构
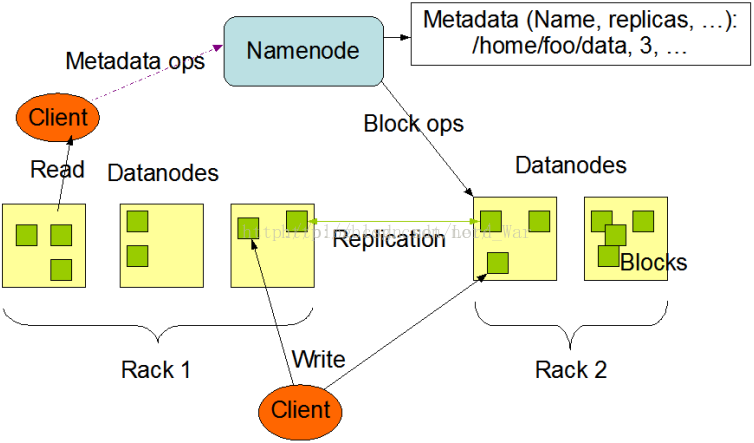
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。一个HDFS集群是由一个NameNode和一定数目的DataNode组成的。NameNode是一个中心服务器,负责管理文件系统的名字空间 (Namespace )及客户端对文件的访问。集群中的DataNode一般是一个节点运行一个DataNode进程,负责管理它所在节点上的存储。
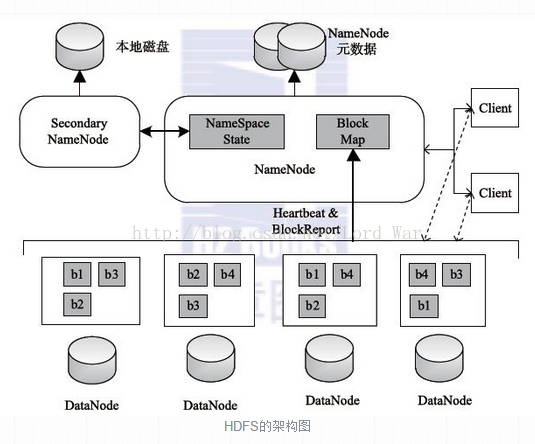
HDFS架构解析
(1)client
可能会有人有疑问,什么是client,Client是不是就是每位开发人员的电脑?是不是每个作业提交所在节点的机器,是不是....等?很多疑惑。基于此,我来给大家解答迷惑。
HDFS的Client是处于如下的一个位置,当然,这幅图只是一个引子罢了,不是固定的模板哈。

Client(代表用户)通过与 NameNode和DataNode 交互访问HDFS中的文件。Client 提供了一个类似 POSIX 的文件系统接口供用户调用。
(POSIX 表示可移植操作系统接口(Portable Operating System Interface ,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称,其 正式称呼为IEEE 1003,而国际标准名称为ISO/IEC 9945。)
想说的是,在hadoop生态各组件里,分别有其对应的Client。比如,在HDFS里,在分析其原理时,是HDFS Client。同理,在Mapreduce里,是Mapreduce Client。
注意:
访问HDFS的程序或HDFS shell命令都可以称为HDFS的客户端(client )。这只是部分而已。
在 HDFS的客户端中至少需要指定HDFS集群配置中的NameNode地址以及端口号信息,或者通过配置HDFS的core-site.xml配置文件来 指定。一般可以把客户端和HDFS节点服务器放在同一台机器上。但其前提是机器资源允许,并且我们能够接受不可靠的应用程序代码所带来的稳定性降低的风 险。
重要啊:
(即HDFS的Client)客户端是用户和HDFS进行交互的手段,HDFS提供了各种各样的客户端,包括命令行接口、Java API, Thrift接口、C语言库、用户空间文件系统〔Filesystem in Userspace,FUSE)等。
如master、slave1、slave2这样的非HA集群 + client。
或者 master1、master2、slave1、slave2、slave3这样的HA集群 + client。
HDFS客户端就是用来访问这个hadoop文件系统的机器,它可以是装有hadoop的机器,也可以是没有装hadoop的机器。
如果你的机器装有hadoop,那你这台机器既是服务器,又是客户端。
有人很好奇会问我,那为什么要这样来规划呢?是为了如client单独来安装如azkaban、oozie、flume、sqoop等(我这里指的是单节点的这些组件哈),只是为了初学学习罢了。这样即可以与集群方便管理。
在实际的开发环境中,在集群环境中开发往往存在很多安全隐患,例如集群文件被误删等等,所以一般的开发工作都是本地完成开发的。本地做MR开发时,由于没有hadoop环境,所以调试工作往往变的很难进行,所以在本地搭建一个hadoop client,不仅能提供本地调试环境,还能从直接从本地访问到hdfs 数据和提交任务到hadoop环境中。你可以在本地运行MR,不登陆服务器就能查看数据。
那之间怎么来连接呢?
(1)做好ssh免密码通信
(2)将如hadoop、spark等这样的集群,scp一份到client机器上即可。
在windows环境下搭建hadoop client 客户端模式搭建
http://blog.csdn.net/u013181284/article/details/70172119
(2)NameNode
NameNode就是HDFS的Master架构,主要负责HDFS文件系统的管理工作,具体包括名称空间(namespace)管理,文件Block管理。
(1)名称空间(namespace)管理:它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(fsimage)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。
(2)文件Block管理:Namenode记录着每个文件中各个块所在的数据节点的位置信息(元数据信息),从NameNode中你可以获得每个文件的每个块所在的DataNode。但是他并不持久化存储这些信息,因为这些信息NameNode会在每次启动系统时动态地重建这些信息。
这些元数据信息主要为:
“文件名 -> 数据块‘’映射
“数据块 -> DataNode列表”映射
其中,"文件名 -> 数据块"保存在磁盘上进行持久化存储,需要注意的是NameNode上不保存‘’数据块 -> DataNode列表”映射,该列表是通过DataNode上报给NameNode建立起来的。NameNode执行文件系统的名称空间(namespace)操作,例如打开、关闭、重命名文件和目录,同时决定文件数据块到具体DataNode节点的映射。
(3)DataNode
HDFS的管理节点是NameNode,用于存储并管理元数据。那么具体的文件数据存储在哪里呢?DataNode就是负责存储数据的组件,一个数 据块Block会在多个DataNode中进行冗余备份;而一个DataNode对于一个块最多只包含一个备份。所以可以简单地认为DataNode上存储了数据块ID和数据块内容,以及它们的映射关系。一个HDFS集群可能包含上千个DataNode节点,这些DataNode定时和NameNode进行通信,接受NameNode的指令,为了减轻NameNode的负担,NameNode上并不永久保存哪个DataNode上有哪些数据块的信息,而是通过DataNode启动时的上报来更新NameNode上的映射表。【这个和上述讲解namenode的职责是一样的】 DataNode和NameNode建立连接后,就会不断地和NameNode保持联系,反馈信息中也包含了NameNode对DataNode的一些命 令,如删除数据库或者把数据块复制到另一个DataNode。应该注意的是:NameNode不会发起到DataNode的请求,在这个通信过程中,它们 严格遵从客户端/服务器架构。
当然DataNode也作为服务器接受来自客户端的访问,处理数据块读/写请求。DataNode之间还会相互通信,执行数据块复制任务,同时,在客户端执行写操作的时候,DataNode之间需要相互配合,以保证写操作的一致性。
DataNode是文件系统Worker中的节点,用来执行具体的任务:存储文件块,被客户端和NameNode调用。同时,它会通过心跳(Heartbeat)定时向NameNode发送所存储的文件块信息。
(4)SecondaryNameNode
和NameNode最相关的还有一个概念就是Secondary NameNode,其主要是定时对NameNode的数据snapshots进行备份,这样可尽量降低NameNode崩溃之后导致数据丢失的风险,其所做的工作就是从NameNode获得fsimage和edits后把两者重新合并发给NameNode,这样,既能减轻NameNode的负担又能安全地备份,一旦HDFS的Master架构失效,就可以借助Secondary NameNode进行数据恢复。但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。
3.1NameNode的目录结构如下:
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
3.2Secondary NameNode的目录结构如下:
${fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous.checkpoint/VERSION
/edits
/fsimage
/fstime

如上图,Secondary NameNode主要是做Namespace image和Edit log合并的。
那么这两种文件是做什么的?当客户端执行写操作,则NameNode会在edit log记录下来,(我感觉这个文件有些像Oracle的online redo logo file)并在内存中保存一份文件系统的元数据。
Namespace image(fsimage)文件是文件系统元数据的持久化检查点,不会在写操作后马上更新,因为fsimage写非常慢(这个有比较像datafile)。
由于Edit log不断增长,在NameNode重启时,会造成长时间NameNode处于安全模式,不可用状态,是非常不符合Hadoop的设计初衷。所以要周期性合并Edit log,但是这个工作由NameNode来完成,会占用大量资源,这样就出现了Secondary NameNode,它可以进行image检查点的处理工作。步骤如下:
(1) Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2) 通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3) 读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4) 通过http post方式,将新的fsimage文件传送到NameNode;
(5) NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
整个处理过程完成。
Secondary NameNode的处理,是将fsimage和edites文件周期的合并,不会造成nameNode重启时造成长时间不可访问的情况。















 4181
4181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









