







一、什么是脑裂
脑裂(split-brain)就是“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”,我们都知道,如果一个人有多个大脑,并且相互独立的话,那么会导致人体“手舞足蹈”,“不听使唤”。
为了满足业务高可用和连续性的要求,集群是常见的应用部署模式,而“脑裂”则通常出现在这些集群环境中,例如RabbitMQ,zookeeper集群等等。本文主要是介绍RabbitMQ的脑裂问题,同RabbitMQ官方文档描述的网络分区问题。
当RabbitMQ出现网络分区时,不同分区里的节点会认为不属于自身所在分区的节点都已经挂(down) 了,对于队列、交换器、绑定的操作仅对当前分区有效,它们各自为政。如果原集群中配置了镜像队列,而这个镜像队列又牵涉两个或者更多个网络分区中的节点时,每一个网络分区中都会出现一个master 节点,对于各个网络分区,此队列都是相互独立的。当然也会有一些其他未知的、怪异的事情发生。当网络恢复时,网络分区的状态还是会保持,除非你采取了一些措施去解决它。
网络分区是在使用RabbitMQ集群时所不得不面对的一个问题,网络分区的发生可能会引起消息丢失或者服务不可用等。不过我们仍然可以简单地通过重启的方式或者配置自动化处理的方式来处理这个问题,但还是得深究其内部机理,这样再处理网络分区问题的时候也会游刃有余。RabbitMQ 的默认配置下(ignore),即使网络恢复了也不会自动处理网络分区带来的问题。RabbitMQ 从3.1 版本开始会自动探测网络分区,并且提供了相应的配置(Partition Handling Strategies)来解决这个问题。
二、脑裂形成的原因
根据RabbitMQ的官方文档,RabbitMQ集群间内部通信的端口默认为25672(可以配置),节点之间会通过这个端口进行检测(也是一种心跳机制,但要注意区分client与server的心跳机制的不同,client与server的心跳机制通信的端口是5672),检测时长是根据"net_ticktime"参数来控制,默认60s,可以修改。
增加集群中所有节点的net_ticktime将使集群对短距离网络中断更具弹性,但会导致剩余节点检测崩溃节点所需的时间变得更长。相反,减少集群中所有节点的net_ticktime虽然会减少检测延迟,但会增加检测虚假分区的风险。应仔细考虑更改默认net_ticktime的影响,另外需要注意的是群集中的所有节点必须使用相同的net_ticktime。
在一个"net_ticktime"内做四次心跳检测,每次记为一次“tick”,如果一个节点在"net_ticktime" 25%时间内都没任何应答(没找到检测时间误差范围为25%的原因,官网没看到解释,但从后面模拟测试观察,也大致在60s左右,偏差在10s以内), 则可以判定此节点己处于" down" 状态, 其余节点可以将此节点剥离出当前分区,当检测超时,一般会记到服务日志中,并提示是哪个节点出故障,如下:
2021-10-13 17:11:27.932 [info] <0.4066.0> node rabbit@rabbitmq2 down: net_tick_timeout
从日志中可以看出,rabbitmq2节点down了
RabbitMQ不仅会将队列、交换器及绑定等信息存储在Mnesia 数据库(基于Erlang的一种分布式数据库,但不太主流,且学习成本高、操作麻烦)中,而且许多围绕网络分区的一些细节也都和这个Mnesia 的行为相关。如果中断的网络恢复正常之后, Mnesia 认定了发生网络分区的情况,这些会被记录到RabbitMQ 的服务日志之中, 如下:
2021-10-13 17:13:50.932 [error] <0.3908.0> Mnesia(rabbit@rabbitmq1): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@rabbitmq2}
除了以上通过服务日志可以发现网络分区的问题,我们还可以通过其他方法来判断:
例如前端Web管理页面(需开启RabbitMQ的管理插件,命令:rabbitmq-plugins enable rabbitmq_management)的Overview页面,会出现“Network partition....xxxx”的提示,如下:
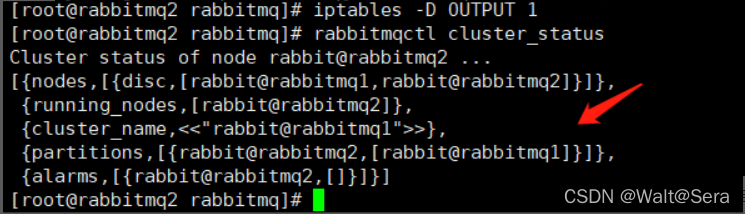
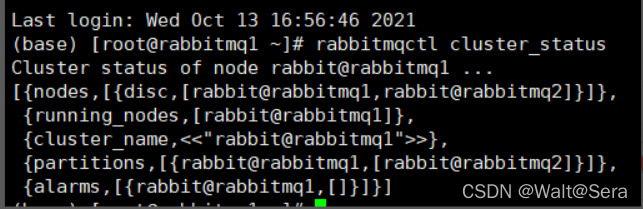
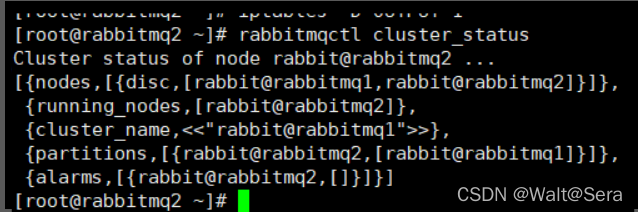
 又例如通过命令工具,“rabbitmqctl cluster_status”命令,partitions这个字段为空为正常,如果有值,则说明此时发生了网络分区。
又例如通过命令工具,“rabbitmqctl cluster_status”命令,partitions这个字段为空为正常,如果有值,则说明此时发生了网络分区。
综上,RabbitMQ发生网络分区时的过程如下,首先在"net_ticktime"\pm25%时间内四次心跳检测,这时如果有网络通信问题,检测期间RabbitMQ服务会暂停,检测期间没有任何应答(四次都失败了),则出现“net_tick_timeout”,然后直到网络恢复正常时,重新建立心跳,但出现网络分区的问题。RabbitMQ集群机制的原因,对网络分区的容错性不高,因此在官方文档中强调不建议直接使用在广域网中,需要配套一些其他机制来保证消息的传输,如Federation、Shovel插件等等。然而,就算在被认为网络很稳定的局域网中部署集群,也会出现由于网络硬件故障等问题,如交换机故障、网卡故障,而引起的网络分区问题,我们不能因为害怕出现问题就不使用新的技术,而是需要了解其机理,在遇到问题时选择适当的方案解决。
三、脑裂模拟
为了重现这次程序化交易系统生产环境遇到的问题,本人对RabbitMQ集群进行了模拟实验。模拟的方法也比较简单,就是人为的制造网络中断,使RabbitMQ集群心跳通信超时,通过监控服务日志观察到心跳检测超时后,再恢复网络,模拟出网络分区的问题。常见网络中断的方法一般有:
- 手工up/down网卡
- 防火墙iptables
本次模拟选用iptables的方法(阻隔集群间25672端口通信),这样既可以在模拟脑裂的同时监控服务日志。
1、环境准备
- 服务端环境和程序版本(同生产的版本)
| 主机节点 | 操作系统 | 软件 | 队列 |
| rabbitmq1 | Redhat 7.x | Rabbitmq-server: V3.7.8 Erlang:V20.3.8.6 | test2 |
| rabbitmq2 | Redhat 7.x | Rabbitmq-server: V3.7.8 Erlang:V20.3.8.6 | test2 |
由于RabbitMQ开源,可以很方便地从github上获取安装包,下载地址:
Release 20.3.8.6 · rabbitmq/erlang-rpm · GitHub
Release RabbitMQ 3.7.8 · rabbitmq/rabbitmq-server · GitHub
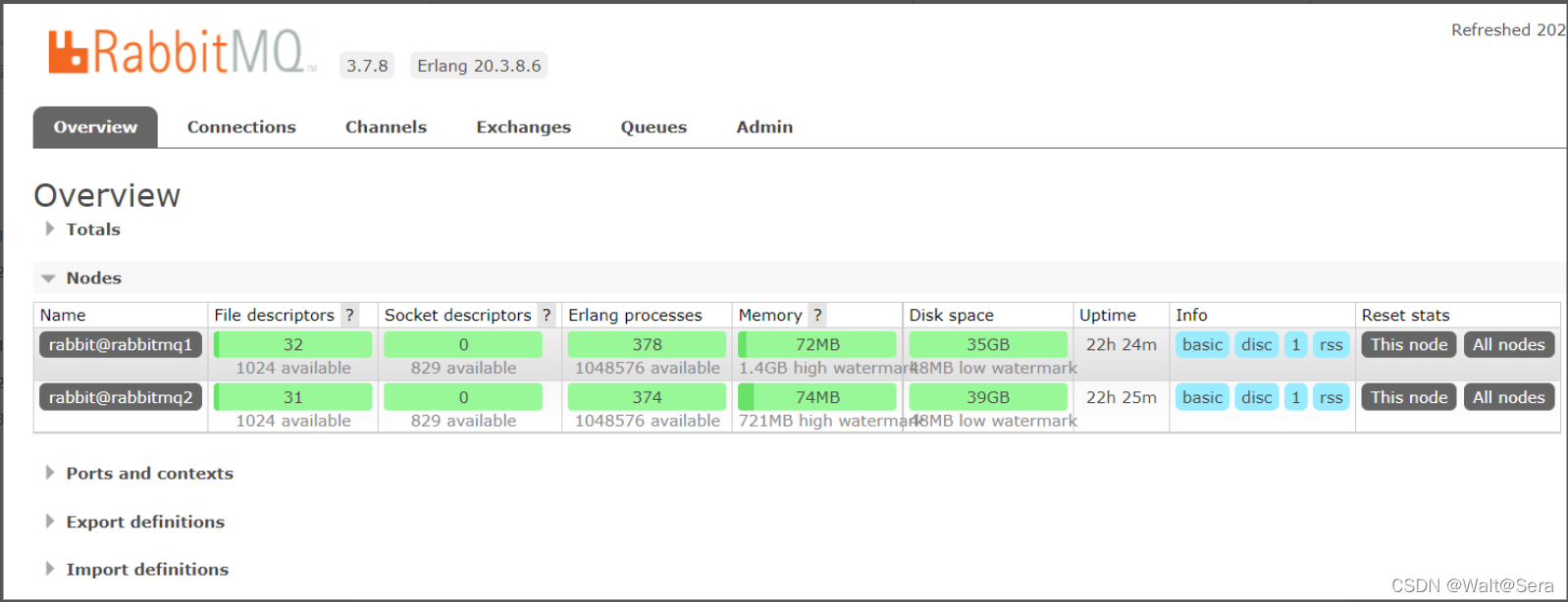
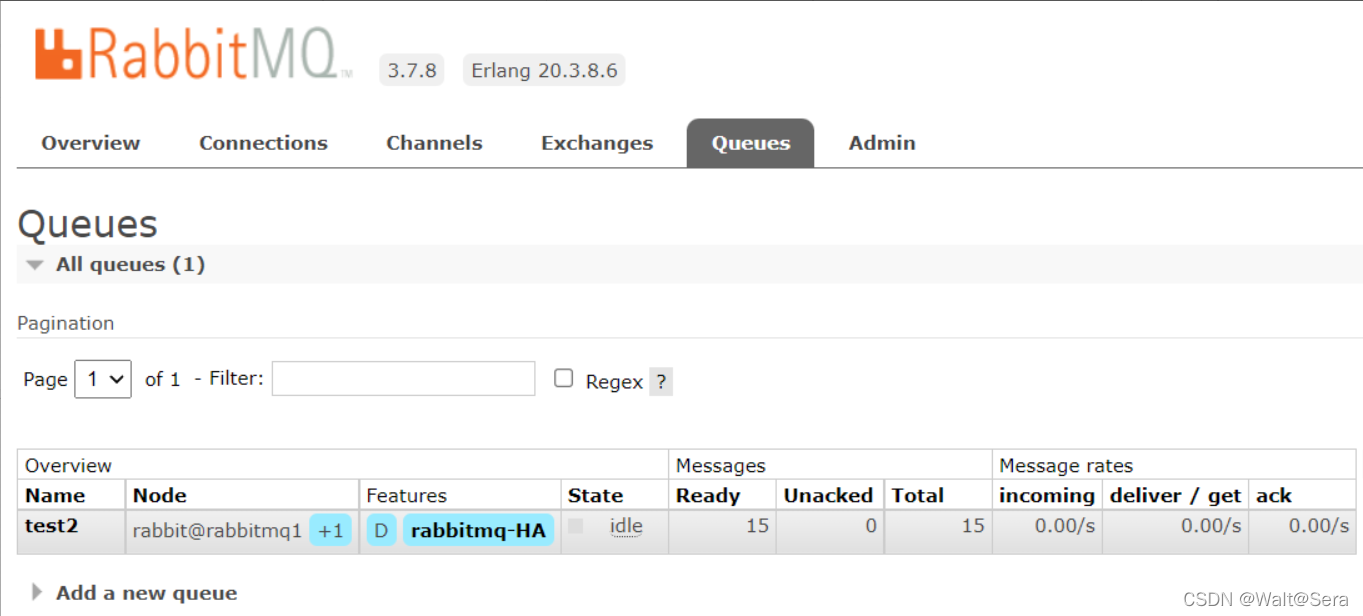
RabbitMQ集群安装过程比较简单,读者可以参考官方文档或者其他网上教程,这里不再赘述,但要注意的是部署集群的前提是保证集群各个节点RabbitMQ的版本必须一致。RabbitMQ集群安装完之后(别忘了配置镜像同步,可以保证两个broker节点都不存在单点故障,不然队列只会存在单个节点上,那个节点如果down了,此节点的队列就不可用了),通过前台管理页面可以清晰的看到集群已经建立,并新建了一个test2队列,如下:
- 客户端
RabbitMQ几乎支持所有的主流开放语言,可以简单地写个python或java的client的demo,分别模拟生产者client和消费者client,本人使用python来写,有兴趣做实验的读者可以直接用,但在使用之前需要安装pika的包,代码如下:
生产者:
# -*- coding: utf-8 -*-
import pika
import random
# 新建连接
# 主机IP
hostname = 'xxx.xxx.xxx.xxx'
# 用户和密码
credentials = pika.PlainCredentials('admin', 'admin')
# 端口和vhost
parameters = pika.ConnectionParameters(hostname,5672,'/',credentials)
connection = pika.BlockingConnection(parameters)
# 创建通道
channel = connection.channel()
# 声明一个队列,生产者和消费者都要声明一个相同的队列
channel.queue_declare(queue='test2',durable=True)
number = random.randint(1, 1000)
body = 'hello world:%s' % number
# 交换机; 队列名,写明将消息发往哪个队列; 消息内容
# routing_key在使用匿名交换机的时候才需要指定,表示发送到哪个队列
channel.basic_publish(exchange='', routing_key='test2', body=body)
print (" [x] Sent %s" % body)
connection.close()消费者:
# -*- coding: utf-8 -*-
import pika
# 新建连接
hostname = 'xxx.xxx.xxx.xxx'
credentials = pika.PlainCredentials('admin', 'admin')
parameters = pika.ConnectionParameters(hostname,5672,'/',credentials)
connection = pika.BlockingConnection(parameters)
# 创建通道
channel = connection.channel()
channel.queue_declare(queue='test2', durable=True)
def callback(ch, method, properties, body):
print (" [x] Received %r" % (body,))
# 告诉rabbitmq使用callback来接收信息
channel.basic_consume('test2', callback)
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理,按ctrl+c退出
print (' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()2、模拟过程
RabbitMQ集群部署之后,通过生产者client对队列写message,然后在rabbitmq2节点执行如下命令,root用户执行:
iptables -A INPUT -p tcp --dport 25672 -j DROP
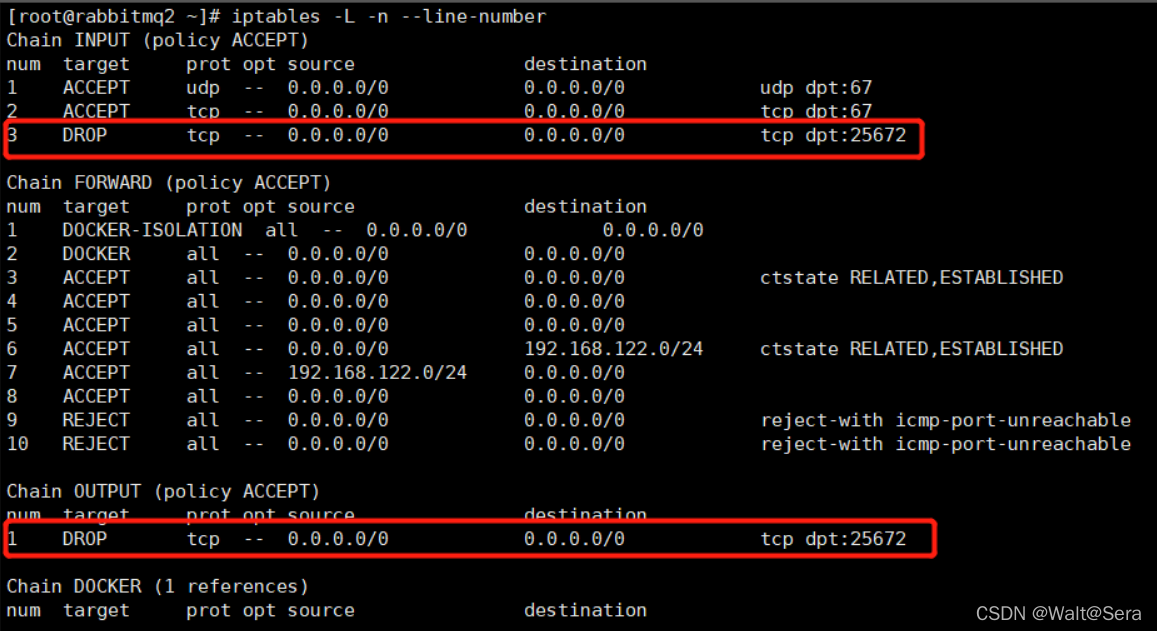
iptables -A OUTPUT -p tcp --dport 25672 -j DROP执行之后通过“iptables -L -n --line-number”命令查看:
 启用iptables策略之后,通过tail工具监控两个节点的服务日志,计时并观察两个节点日志情况,约过了60s左右,两个节点出现如下日志
启用iptables策略之后,通过tail工具监控两个节点的服务日志,计时并观察两个节点日志情况,约过了60s左右,两个节点出现如下日志
rabbitmq1节点:
2021-10-13 17:16:27.886 [error] <0.5507.0> ** Node rabbit@rabbitmq2 not responding **
** Removing (timedout) connection **
2021-10-13 17:16:27.886 [info] <0.5775.0> rabbit on node rabbit@rabbitmq2 down
2021-10-13 17:16:27.887 [warning] <0.6021.0> Management delegate query returned errors:
[{<36949.2852.0>,{exit,{nodedown,rabbit@rabbitmq2},[]}}]
2021-10-13 17:16:27.970 [info] <0.5775.0> Node rabbit@rabbitmq2 is down, deleting its listeners
2021-10-13 17:16:27.971 [info] <0.5775.0> node rabbit@rabbitmq2 down: net_tick_timeout
rabbitmq2节点:
2021-10-13 18:41:32.196 [error] <0.2225.0> ** Node rabbit@rabbitmq1 not responding **
** Removing (timedout) connection **
2021-10-13 18:41:32.197 [warning] <0.2858.0> Management delegate query returned errors:
[{<9600.1663.0>,{exit,{nodedown,rabbit@rabbitmq1},[]}}]
2021-10-13 18:41:32.197 [info] <0.2613.0> rabbit on node rabbit@rabbitmq1 down
2021-10-13 18:41:32.288 [info] <0.2613.0> Node rabbit@rabbitmq1 is down, deleting its listeners
2021-10-13 18:41:32.289 [info] <0.2613.0> node rabbit@rabbitmq1 down: net_tick_timeout
网络通信异常时,集群心跳检测期间,我们还可以观察到此时不仅集群数据无法同步,还会使整个broker节点的业务中断,client无法写入和读取消息,前台管理页面的数据也无法刷新。
确认心跳超时之后,模拟恢复集群间的网络通信,在rabbitmq2节点执行如下命令(这个命令通过行序号来删除iptables,删除前需先确定行序号再执行,否则将误删防火墙,很危险!),root用户执行:
iptables -D INPUT 3
iptables -D OUTPUT 1网络链路恢复正常后,观察服务日志可以发现,已经模拟出网络分区现象,两个节点相关信息如下:
rabbitmq1服务日志:
2021-10-13 17:13:50.930 [info] <0.4066.0> node rabbit@rabbitmq2 up
2021-10-13 17:13:50.932 [error] <0.3908.0> Mnesia(rabbit@rabbitmq1): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@rabbitmq2}
rabbitmq2服务日志:
2021-10-13 18:22:09.542 [info] <0.356.0> node rabbit@rabbitmq1 up
2021-10-13 18:22:09.543 [error] <0.180.0> Mnesia(rabbit@rabbitmq2): ** ERROR ** mnesia_event got {inconsistent_database, running_partitioned_network, rabbit@rabbitmq1}
rabbitmq1的管理界面:
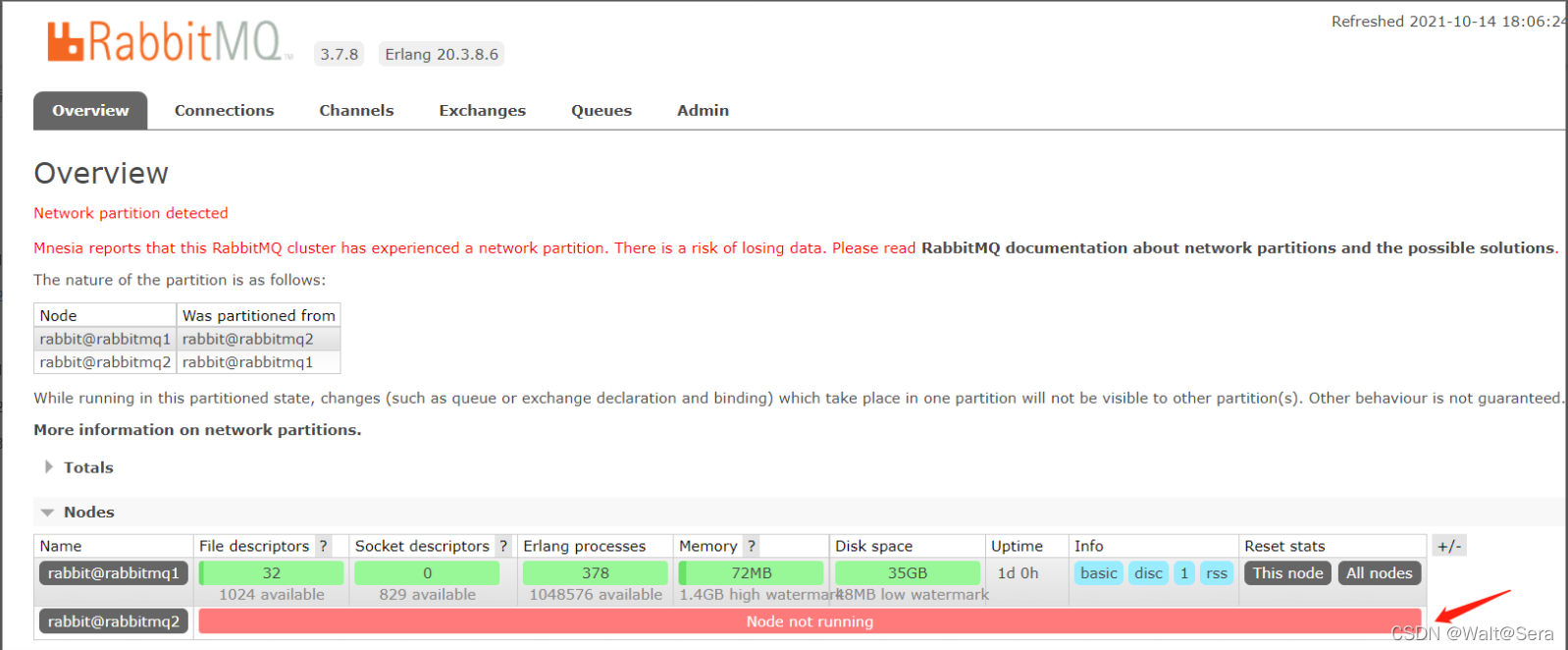
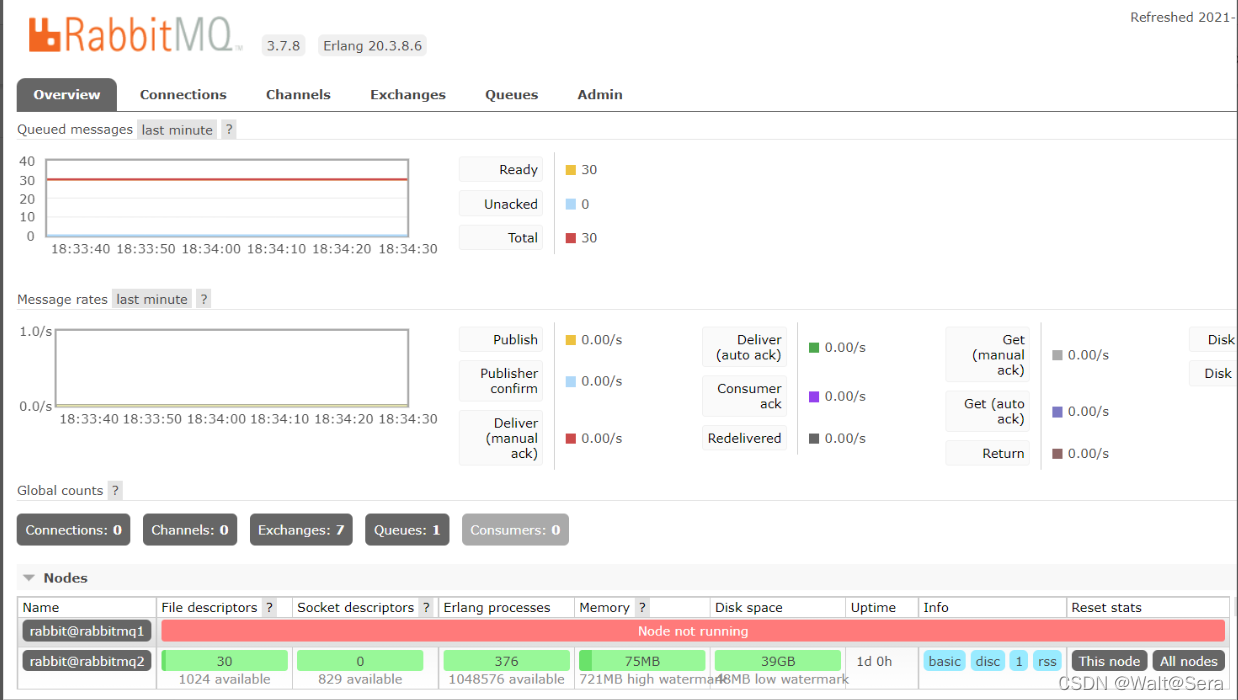
rabbimq2的管理界面:
rabbitmq1的控制命令查询:
rabbitmq2的控制命令查询:
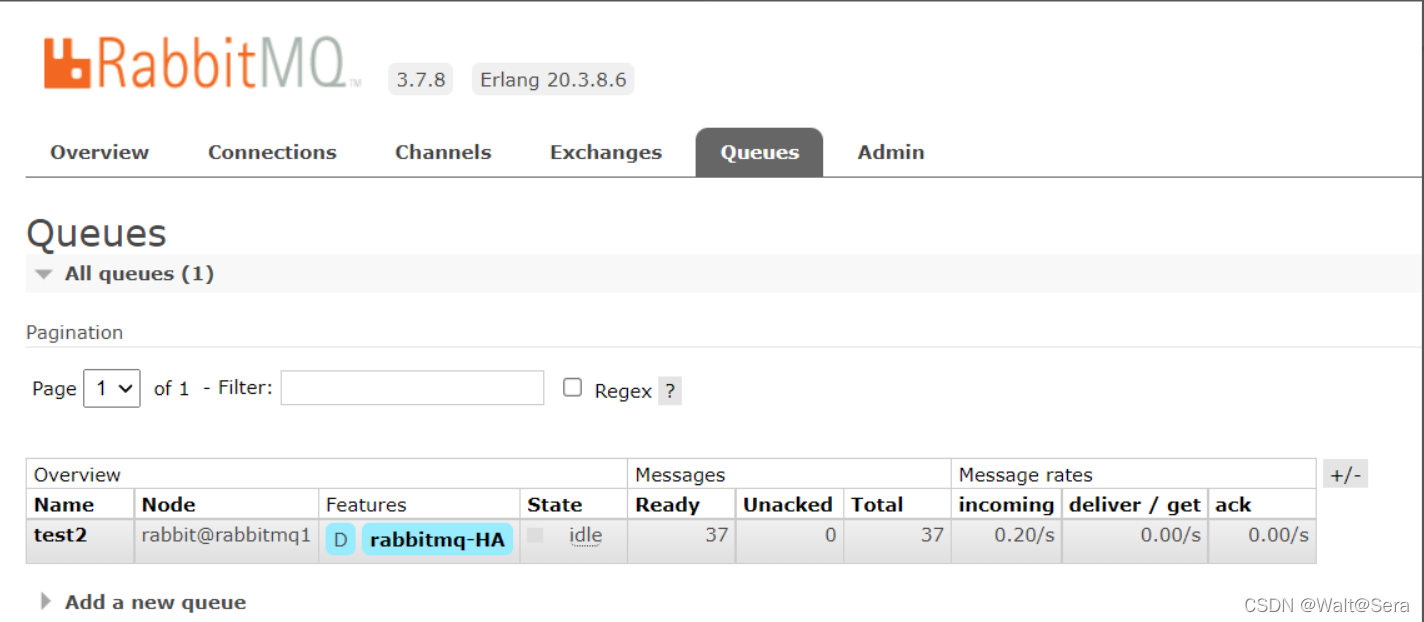
网络分区之后,集群可能还可以对外服务,生产者和消费者都可以继续对队列写入和读取消息,但是会引发网络分区的消息重复(网络分区会引起很多奇奇怪怪的问题,模拟时直观的现象是消息重复,有兴趣的读者可以深入研究其他现象)
分区前:
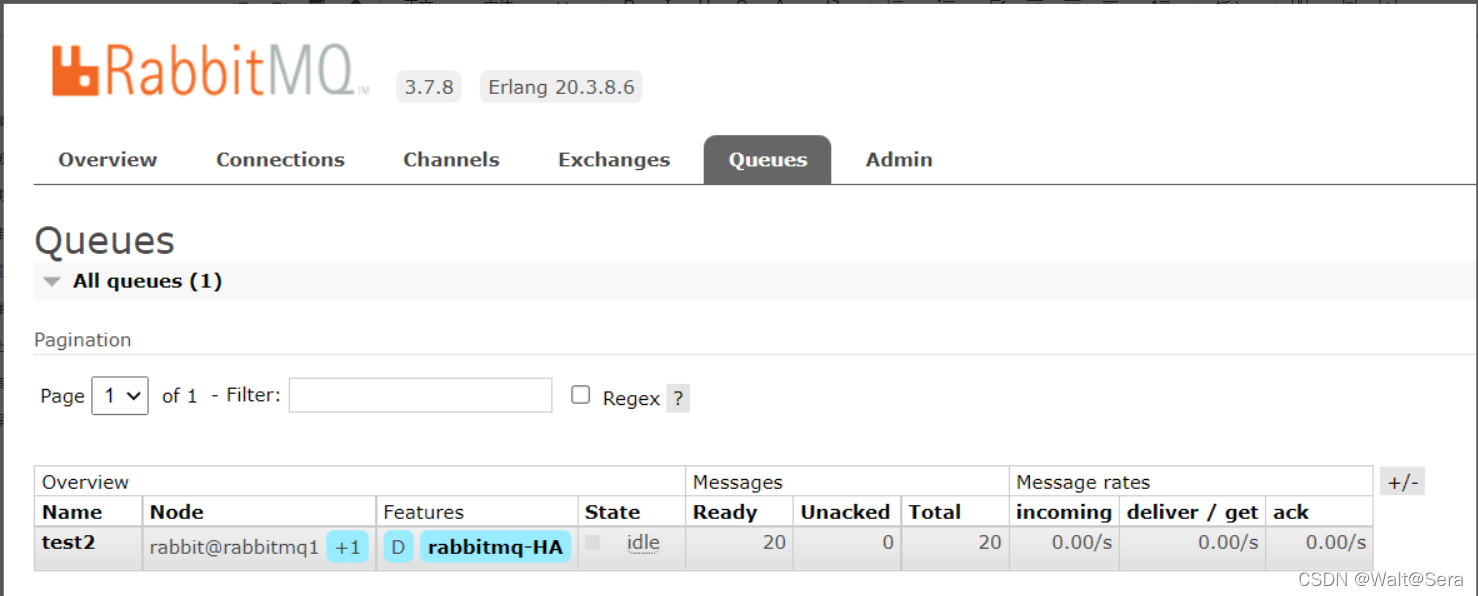
分区后:
四、脑裂的解决方案
1、手工处理
出现网络分区问题之后,RabbitMQ集群默认情况下是需要手工干预才能恢复。根据官方文档,如果节点只有两个,恢复步骤比较简单,如下(因为程序化交易系统生产只有两个节点,且只简单使用队列,情景比较简单,因此恢复步骤相对简单,而其他多分布式集群节点和复杂应用的情形,手工恢复会更加复杂和困难,非常容易造成数据丢失和业务中断,有兴趣的读者可以继续深入研究)
- 挑选信任分区
为了从网络分区中恢复,首先需要挑选一个信任分区,这个分区才有决定Mnesia 内容的权
限,发生在其他分区的改变将不会被记录到Mnesia 中而被直接丢弃。一般选择的标准:分区中的节点数最多、分区中的队列数最多、分区中的客户端连接数最多。
- 重启非信任分区节点
在挑选完信任分区之后,重启非信任分区中的节点。(重启的方法建议使用“rabbitmqctl stop_app”和“rabbitmqctl start_app”,这样只需重启应用而不用重启Erlang虚拟机)
手工处理之后,可以通过前端web管理界面看到,集群已恢复正常,且网络分区的告警消失:
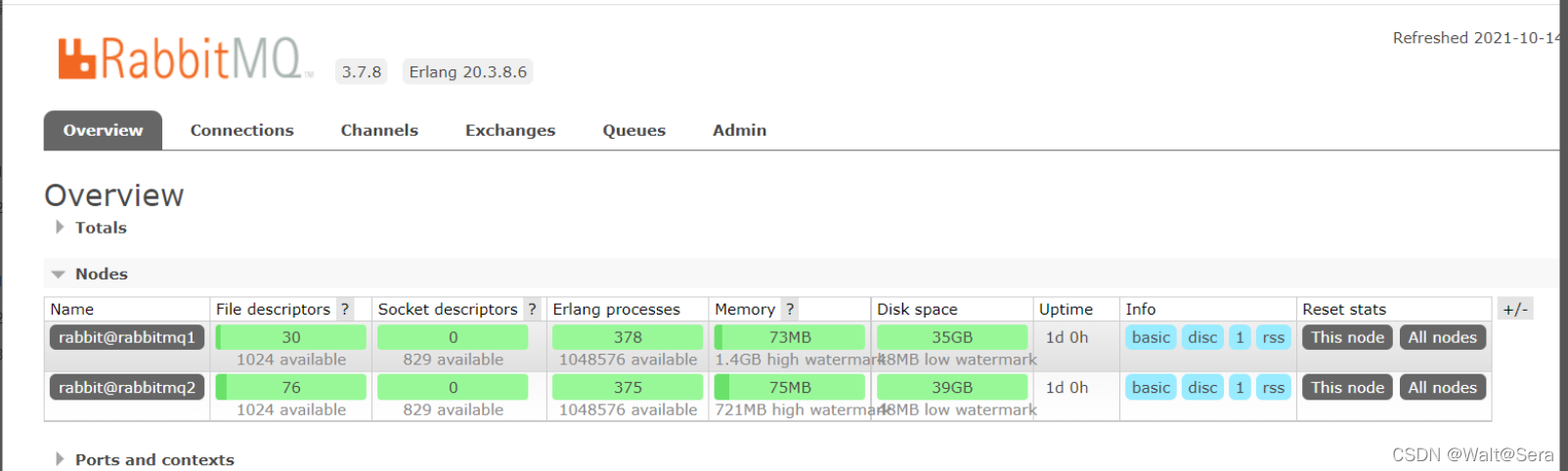
2、配置策略自动处理
根据官方文档,除了手工处理的方式外,还可以通过配置文件来选择网络分区自动处理的策略:
RabbitMQ also offers three ways to deal with network partitions automatically: pause-minority mode, pause-if-all-down mode and autoheal mode. The default behaviour is referred to as ignore mode.
You can enable either mode by setting the configuration parameter cluster_partition_handling for the rabbit application in the configuration file to
我们在rabbitmq.config 配置文件中增加cluster_partition_handling参数来实现网络分区自动的功能(需要注意的是所有节点的配置都要相同,修改完配置之后需要重启RabbitMQ)
[root@rabbitmq2 ~]# more /etc/rabbitmq/rabbitmq.conf cluster_partition_handling = autoheal
目前RabbitMQ官方只提供了三种策略模式,每种策略自动处理机理也大不相同:
- pause-minority模式
当发生网络分区时,RabbitMQ集群中的节点在发现某些节点"down"的时候,会自动检测其自身是否处于"少数派" (分区中的节点小于或者等于集群中一半的节点数), RabbitMQ 会自动关闭这些节点的运作。根据CAP原理,这里保障了P,即分区耐受性。这样确保了在发生网络分区的情况下,大多数节点(当然这些节点得在同一个分区中)可以继续运行。"少数派"中的节点在分区开始时会关闭, 当分区结束时又会启动。这种配置可以防止脑裂,因此能够自动从网络分区恢复,而不会出现不一致的情况。另外,这里关闭是指RabbitMQ 应用的关闭,而Erlang虚拟机并不关闭,类似于执行了“rabbitmqctl stop_app”命令。处于关闭的节点会每秒检测一次是否可连通到剩余集群中,如果可以则启动自身的应用。相当于执行"rabbitmqctl start_app"命令。(需要注意的是,RabbitMQ 也会关闭不是严格意义上的大多数,比如在一个集群中只有两个节点的时候并不适合采用pause-minority 的模式,因为其中任何一个节点失败而发生网络分区时,两个节点都会关闭。当网络恢复时, 有可能两个节点会自动启动恢复网络分区,也有可能仍保持关闭状态)
- pause_if_all_down模式
这种模式支持配置一个受信节点列表,当发生网络分区时,RabbitMQ集群中的节点在和所配置的列表中的任何节点不能通信时才会关闭。这与pause_minority模式很类似,但是它允许管理员自己决定选择哪些节点,而不是依赖上下文。例如,如果集群由机架A中的两个节点和机架B中的两个节点组成,并且机架之间的链路丢失,则pause_minority模式将暂停所有节点。在pause_if_all_down模式下,如果管理员配置列表机架A中的两个节点,则只有机架B中的节点将暂停。但是,当列表的节点是两个机架各自的其中一个节点,当机架A与机架B出现链路故障,此时所有节点都不会关闭,而会形成两个分区,在这种情况下,就需要额外的ignore/autoheal参数来指示如何从分区恢复,如果是ignore就需要手工处理,而配置autoheal会自动处理。
- autoheal 模式
当发生网络分区时, RabbitMQ 会自动决定一个获胜(winner)的分区,然后重启不在这个分区中的节点来从网络分区中恢复。一个获胜的分区是指客户端连接最多的分区,如果产生一个平局,即有两个或者多个分区的客户端连接数一样多,那么节点数最多的一个分区就是获胜分区。如果此时节点数也一样多,将以一种不指定的特定规则来挑选获胜分区,任意指定。
本次实验只测试了autoheal策略,其他策略读者们可以进一步实验。当RabbitMQ集群配置了自动处理策略后,当RabbitMQ集群出现网络分区的问题时,RabbitMQ会自动发现并处理,日志如下:
2021-10-13 18:12:37.835 [info] <0.366.0> Autoheal request sent to rabbit@rabbitmq1
2021-10-13 18:12:37.837 [info] <0.366.0> Autoheal: I am the winner, waiting for [rabbit@rabbitmq1] to stop
2021-10-13 18:12:38.048 [info] <0.366.0> rabbit on node rabbit@rabbitmq1 down
2021-10-13 18:12:38.094 [info] <0.366.0> Keeping rabbit@rabbitmq1 listeners: the node is already back
2021-10-13 18:12:38.096 [info] <0.366.0> Autoheal: final node has stopped, starting...
2021-10-13 18:12:39.070 [info] <0.366.0> rabbit on node rabbit@rabbitmq1 up
从日志中可以观察到,autoheal策略下,rabbitmq2节点获胜(winner),集群自动重启了rabbitmq1节点来修复网络分区的问题。但此策略存在一个问题,autoheal策略不是以队列中的消息数多少来判定获胜节点,如果此时rabbitmq1节点的消息多于rabbitmq2节点的消息数(在网络分区期间clieant写入不同的RabbitMQ节点造成的),则rabbitmq1节点比rabbitmq2多存的消息会丢失。
综上,配置自动处理策略的方案虽然很“香”,但是也不能保证消息不回完全丢失,因此我们需要针对特定的应用场景进行分析,选择最优的策略进行配置。
3、其他解决方案
经过以上的分析,不难发现每种方案都有其“让人难受”的地方,难道RabbitMQ就没有其他方案了吗?答案是肯定有的,但这些方案一开始并不是为了解决脑裂问题而提出的,而是为了保证数据不丢失而提出的解决方案。正如RabbitMQ官方文档开篇就提到,如果在广域网中使用,可以通过Federation或Shovel插件的加持,达到保证消息可靠性的目的,所以我们不妨考虑使用Federation或Shovel插件来替代集群的方案,具体的使用方法可以参考官方文档。
另外,在生产环境中,我们还可以根据脑裂模拟分析提到的网络分区的行为表现,增加监控(日志监控、HTTP-API、命令行等等),达到事前预警和提前处理的目的。



















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











