







- forward and backward passes(前向迭代和反向迭代)是Net最基本的成分。
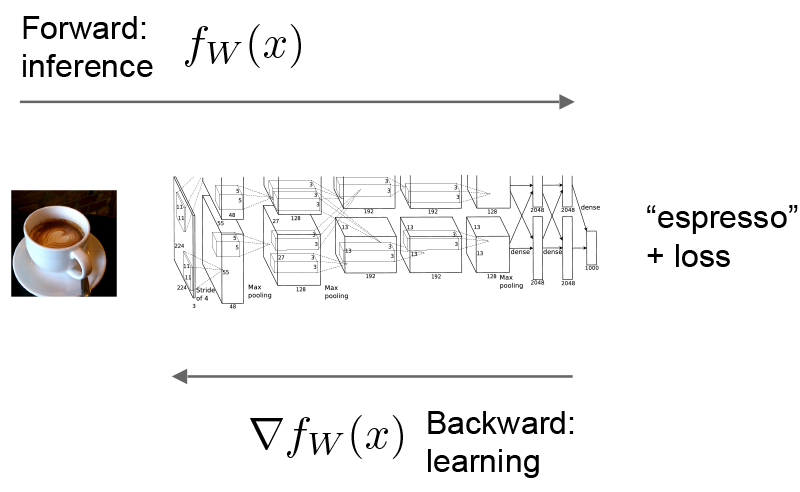
下面以简单的logistic regression classifier(逻辑回归分类器)为例。
- Forward Pass(前向迭代)利用给定的输入,根据模型设定的函数,计算出输出。This pass goes from bottom to top(数据流向从bottom到top)。
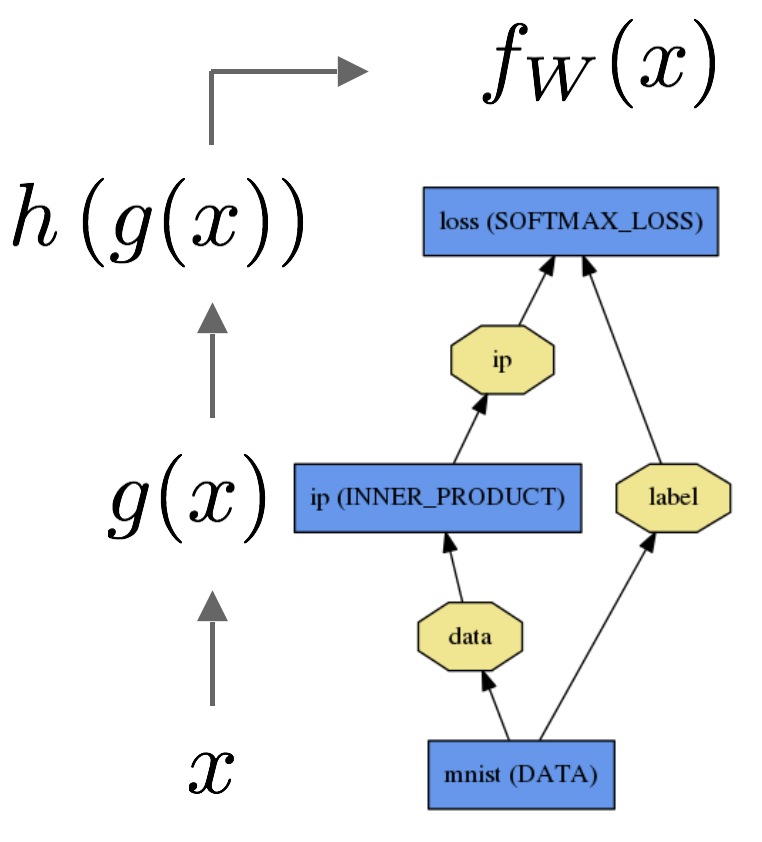
- 数据x通过一个inner product layer,函数为g(x),然后通过softmax layer,函数为h(x),最终将softmax loss输出为fW(x)。
- Backward Pass(反向迭代)计算由loss(损失)给出的gradient(梯度),用于学习、优化参数。Caffe反向计算每一层的gradient,通过automatic differentiation(自动微分)计算出整个模型的gradient(梯度)。这称为back-propagation(反向迭代)。This pass goes from top to bottom(数据流向从top到bottom)。
-
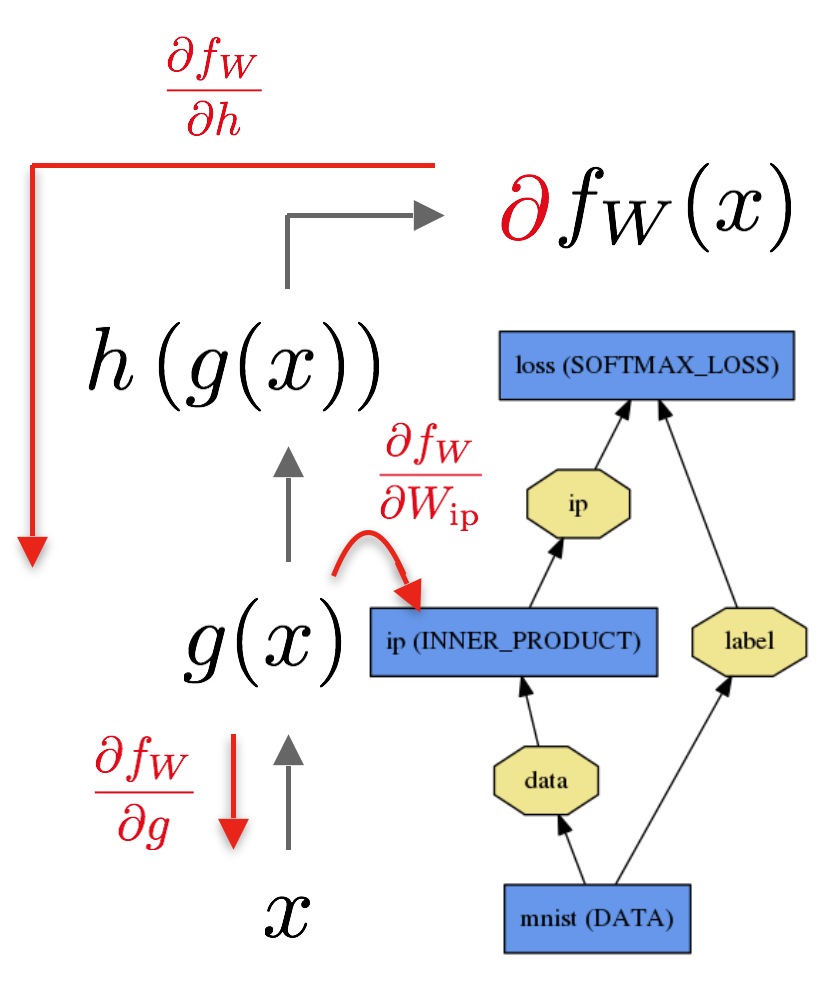
Backward Pass从loss开始,依据output的∂fW∂h计算出gradient,layer-by-layer地计算出整个模型的gradient。对于有参数的Layer,例如INNER_PRODUCT layer,根据其参数由∂fW∂Wip计算出其梯度。
-
Caffe如何进行forward and backward passes(前向迭代和反向迭代):
- 每一次计算时,Net::Forward()和Net::Backward() 方法会调用Layer::Forward()和Layer::Backward()方法
- 每一个Layer都有forward_{cpu,gpu}()和backward_{cpu,gpu}方法,一个Layer可以只使用CPU或者GPU模式,在某些特定约束条件下,或者为了便利。
- Solver(求解方法)优化模型的方法是:先调用forward pass计算output和loss,然后调用backward pass去计算模型的gradient。利用计算出的gradient赋予一定的weight(权重)去更新学习参数,以最大限度地降低loss。
- Solver,Net,和Layer之间的明确分工,是Caffe保持高度的模块化、开放的发展空间。
如果想要了解Caffe不同类型Layer的forward and backward step的细节,详见layer catalogue。















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









