







以前一直没搞清楚tomcat输出的buffer的结构,在tomcat中有两对response和request,其中一组是对http请求header的最基本的封装,另一组是对servlet规范中response和request的实现,这组是调用servlet中service方法的request和response。在这两对request和response都有一个内在的buffer,其中servlet规范那组是缓冲servlet中的输出的,缓冲response.getWriter().write()的buffer,另外一组responserequest的buffer是缓冲httpheader的一些信息的。
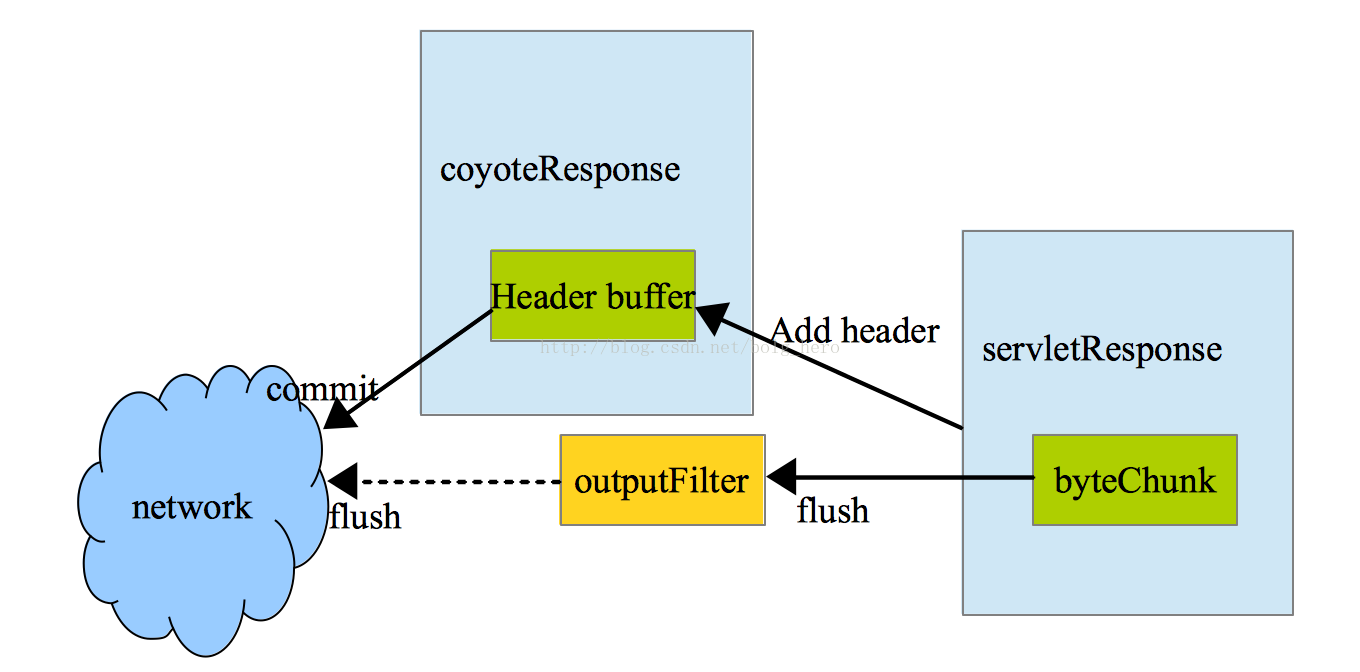
上图就是整体tomcat的输出框架,coyoteResponse的buffer来控制httpheader的存储,这个header 的buffer是不可以扩充的,因为在配置时会设置它的默认大小默认8192字节,对于httpheader(无论是输出还是输入)都不可以超出这个大小。servletResponse的buffer存储servlet的输出,即http响应信息。这个buffer大小时可以扩充的,默认大小时8192字节。它的实现是byteChunk。
tomcat输出分两个部分一个是header的输出,另一个http消息体的输出,对于servletResponse的bufferflush操作都是直接把byteChunk传入outputFilter,这些filter是关于chunked输出和gzip输出或者计算content-length的filter,在gzipfilter的时候,输出会buffer住一些,filter最后面连接的是socket的 outputStream。
byteChunk的实现肯定是byte数组,tomcat在初始化的时候会设置默认8192大小的byte数组。在写数据的时候,判断byte数组的大小,如果输出数据小于byte数组剩余容量,直接把数据追加到byte数组中,如果byte数组不足以容纳输出数据,那么直接flush8192字节大小的数据,剩下的数据继续存在buffer中。
看下buffer写数据的几种情况:1. buffer 可以容下输出数据得时候:

buffer flush一次可以容下输出数据:
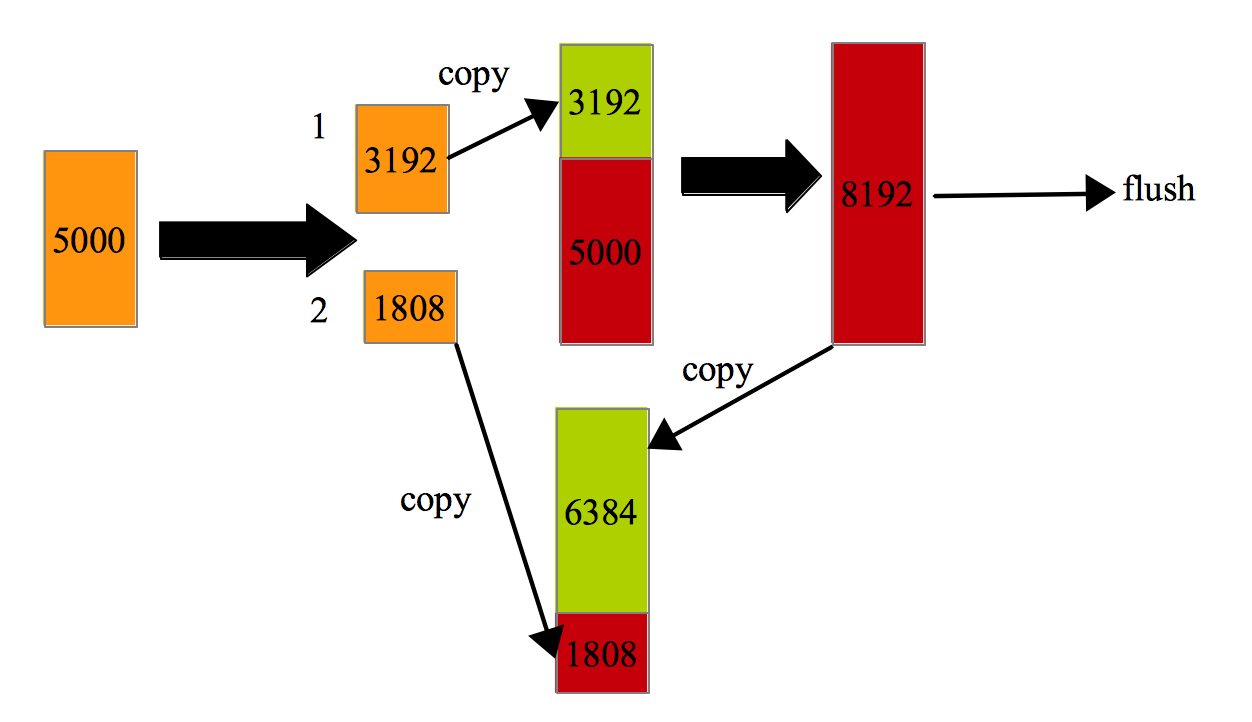
3.buffer flush多次可以容下数据:
看下byteChunkwrite 数据的代码:
public void append( byte src[], int off, int len )
throws IOException
{
// will grow, up to limit
makeSpace( len );
// if we don't have limit: makeSpace can grow as it wants
if( limit < 0 ) {
//limit是byte数组的最大值,如果小于0,代表limit无限大,直接copy src数据到byteChunk的byte数组里面就可以了
// assert: makeSpace made enough space
System.arraycopy( src, off, buff, end, len );
end+=len;
return;
}
// Optimize on a common case.
// If the buffer is empty and the source is going to fill up all the
// space in buffer, may as well write it directly to the output,
// and avoid an extra copy
//这里面是个优化方法,如果当时这个buffer是空的,而且src的数据大小恰好等于limit,那么就不用再次copy src数组到byte数组了,直接flush就可以了
if ( optimizedWrite && len == limit && end == start && out != null ) {
out.realWriteBytes( src, off, len );
return;
}
//如果byte数组足够放下src数组,直接copy
// if we have limit and we're below
if( len <= limit - end ) {
// makeSpace will grow the buffer to the limit,
// so we have space
System.arraycopy( src, off, buff, end, len );
end+=len;
return;
}
// need more space than we can afford, need to flush
// buffer
// the buffer is already at ( or bigger than ) limit
// We chunk the data into slices fitting in the buffer limit, although
// if the data is written directly if it doesn't fit
int avail=limit-end;
//先把byte数组填满,flush一次
System.arraycopy(src, off, buff, end, avail);
end += avail;
flushBuffer();
int remain = len - avail;
//再看下剩余数据是否能够填满8192,只要能填满,直接flush
while (remain > (limit - end)) {
out.realWriteBytes( src, (off + len) - remain, limit - end );
remain = remain - (limit - end);
}
//最后剩下一些不够8192了,放在byte数组中,等待flush操作或者等待再次写数据
System.arraycopy(src, (off + len) - remain, buff, end, remain);
end += remain;
}上面说了 tomcat 中存储 servlet 输出的 buffer ,这个 buffer 是 byteChunk ,写操作和 flush 操作都可以激发 byteChunkflush 数据到 outputFilter 中或者直接到网络中。但是这里面有问题,如果数据 flush 到网络,如果这个数据前面不加上 header 的数据,是不对的,因为 response 数据前面肯定是 httpheader 数据,如果直接将 byteChunk 数据 flush 到网络,就不是 http 响应数据了,对于客户端程序肯定会出错。所以 byteChunkflush 数据肯定要通知 coyoteResponse 准备 header 数据,然后在 flushbyteChunk 之前,把 header 数据全部 flush 到网络中。
看下tomcatflush数据到网络的时机有这么几个:
1.当servletservice方法中,write了数据,但是这个数据比byteChunk 的buffer(8192默认)大,这个时候byteChunk就开始write一部分数据到客户端,并且在这个数据之前先write全部header数据。注意这个header数据是确定全部write到客户端,但是对于write信息体数据,如果在没有outputfilter的情况下,这些数据肯定会全部输出到客户端,但是如果有gzipfilter,那么这个write操作并不能保证所有数据都gzip完成后输出到客户端,上面这个操作并不能flushgzip中的数据。所以说这种被动的flush数据,并不能保证flush的消息体数据全部到达客户端。
从触发的情况来说,servlet也并没有主动flush,也就说servlet也并不想flush出去的数据全部让客户端收到,只是说response的buffer不够了,腾出一部分空间就行了,其他的不管了。
当byteChunkflush数据的时候会调用coyoteResponse的doWrite方法:
public int doWrite(ByteChunk chunk, Response res) //chunk就是需要flush的数据
throws IOException {
if (!committed) {
// Send the connector a request for commit. The connector should
// then validate the headers, send them (using sendHeaders) and
// set the filters accordingly.
response.action(ActionCode.COMMIT, null); //这个地方就是先flush header数据
}
if (lastActiveFilter == -1)
return outputStreamOutputBuffer.doWrite(chunk, res); //flush数据到网络中
else
return activeFilters[lastActiveFilter].doWrite(chunk, res);//或者把数据写入filter中,注意这个地方不会flush这些filter。
}
这个 commit 操作很重要,后面 commitheader 数据到网络都是这一套逻辑,首先要把 add 的 header 生成 bytestream ,然后 flush 出去。
else if (actionCode == ActionCode.COMMIT) {
// Commit current response
if (response.isCommitted()) {
//记录这个header数据是否flush出去了,注意,如果之前flush了一次,那就证明了header已经全部flush出去了,后面在有header数据也不flush了,因为之前
flush header之后,已经flush 响应数据了,再flush header就会出错(不是http响应了)
return;
}
// Validate and write response headers
try {
prepareResponse(); //先生成header数据,然后放到coyoteResponse的buffer中
getOutputBuffer().commit(); //把上面buffer中生成的数据commit出去
} catch (IOException e) {
// Set error flag
error = true;
}
看下commit函数的代码,写的很清楚
protected void commit()
throws IOException {
// The response is now committed
committed = true; //设置header已经commit了,后面就不会再commit这个http header数据了
response.setCommitted(true);
if (pos > 0) {
// Sending the response header buffer
if (useSocketBuffer) {
socketBuffer.append(buf, 0, pos);
} else {
outputStream.write(buf, 0, pos); //不管那种方式,header反正是直接flush到网络中了
}
}
}
2.当在service方法中调用了flush类方法。这种方法如果之后在addHeader是不管用的,因为flush数据的时候已经先flush header完了,已经开始flush数据阶段,这种情况是servlet主动flush,这个操作是必须保证buffer中的数据一定会write到客户端的。
protected void doFlush(boolean realFlush)
throws IOException {
if (suspended) {
return;
}
try {
doFlush = true;
if (initial) {
coyoteResponse.sendHeaders(); //先flush header
initial = false; //flush一次header就够了
}
if (cb.getLength() > 0) { //flush charChunk
cb.flushBuffer();
}
if (bb.getLength() > 0) { //flush byteChunk
bb.flushBuffer();
}
} finally {
doFlush = false;
}
//这个就是被动flush和主动flush的区别,realFlush就是主动flush,这个保证了那个gzip filter flush全部数据
if (realFlush) {
coyoteResponse.action(ActionCode.CLIENT_FLUSH,
coyoteResponse);
// If some exception occurred earlier, or if some IOE occurred
// here, notify the servlet with an IOE
if (coyoteResponse.isExceptionPresent()) {
throw new ClientAbortException
(coyoteResponse.getErrorException());
}
}
}
这个 CLIENT_FLUSH主要处理逻辑如下:
for (int i = 0; i <= lastActiveFilter; i++) {
if (activeFilters[i] instanceof GzipOutputFilter) { //直接flush Gzip的filter数据
if (log.isDebugEnabled()) {
log.debug("Flushing the gzip filter at position " + i +
" of the filter chain...");
}
((GzipOutputFilter) activeFilters[i]).flush();
break;
}
}
从这个主动flush数据看来,servlet是愿意flush出全部数据的,所以这个过程比被动flush多了一个 flush gzip filter的过程。
3.在coyoteAdapter的处理完service方法之后,最后会flush全部数据到客户端,close那些stream,回收request,response,重新设置状态等等,我们关心的就是flush数据的过程。前面的逻辑过程和时机1的代码基本类似,都是先flush http header数据,然后在flush http entity数据到outputFilter 中,但是这个最后还会调用endRequest函数,这个函数就是flush 那些outputFilter的。
public void endRequest()
throws IOException {
if (!committed) {
// Send the connector a request for commit. The connector should
// then validate the headers, send them (using sendHeader) and
// set the filters accordingly.
response.action(ActionCode.COMMIT, null);
}
if (finished)
return;
if (lastActiveFilter != -1)
activeFilters[lastActiveFilter].end(); //flush output filter
finished = true;
}
这个end函数就是关闭filter中打开的stream,然后重置buffer等等,列举一下GzipOutputFilter的end函数代码:
public long end()
throws IOException {
if (compressionStream == null) {
compressionStream = new FlushableGZIPOutputStream(fakeOutputStream);
}
compressionStream.finish();
compressionStream.close();
return ((OutputFilter) buffer).end();
}
总结:
tomcat中存在两个buffer一个是缓冲httpheader的,另一个是缓冲httpentity的,当httpheader满的时候,就会报错,当httpentity的buffer满的时候就会flush数据到客户端,这个flush数据之前只会flush一次的全部的http header。flush数据的时机会有3个,第一个是entityheader满的时候被动flush数据到客户端,flush的数据不保证全部到客户端,因为有GzipoutputFilter的存在,会缓冲一些数据。第二个时机是servlet主动flush数据,这个过程除了flushhttp header和entity数据,还会把GzipoutputFilter的缓冲数据flush出去。第三个就是在servlet 的service方法完成后,也会flush全部数据,并且关闭buffer中的stream还有重置那些buffer的状态。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









