







Data augmentation using learned transformations for one-shot medical image segmentation使用学习变换进行一次性医学图像分割的数据增强
论文原文链接
这篇文章做了一件什么事情?
为了解决医学图像标注数据缺乏的问题,提出了一种通过学习图像的变换来合成带标签医学图像的自动数据增强的半监督分割方法,并将其运用在一次性MRI脑部医学图像分割任务中。
这件事情的难点在什么地方?
这件事情的难度来自几个方面:医学图像分割本身的、空间和外观变换模型的构建上的、少样本的自然图像分割上的、数据增强方面的。
其中最大的难点在于:虽然基于卷积神经网络的图像分割方法能获得很高的精度,但它们通常依赖于带有大量有标签数据集的监督培训。然而标记医学图像需要大量的专业知识和时间,并且用于数据增强的典型手动调整方法未能捕获这些图像中的复杂变化。文章需要解决的问题是,如何使用仅一个有标签的数据和很多其他无标签数据,来进行分割训练。
这篇文章具体是怎么做的?
使用一个带标签的图像和一组无标签的示例,运用基于学习的配准方法,通过学习独立的空间(spatial)和外观(appearance)变换模型来捕捉图像数据集中诸如非线性变形和成像强度的变化,然后使用这些变换模型和有标签的示例来合成新的带标签的示例,从而达到扩充带标签数据集的目的,生成各种逼真的新图像。再把这些新合成的带标签数据集用于训练有监督的分割网络模型,该模型在one-shot分割中优于现有方法。
直观来说就是文章中的这幅过程图:
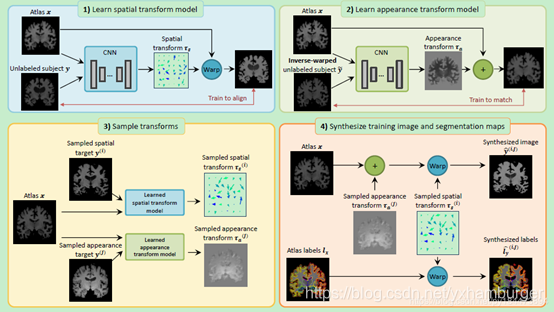
第一步,将有标签的x和无标签的y通过一个CNN网络的学习,得到一个空间转换模型,即学习到一个由y映射到x的空间转换模型。
第二步,同第一步类似,学习到一个y关于x的外观转换模型。
第三步,将x和采样过的y的空间和外观通过之前学习到的两个模型,得到采样后的空间和外观映射。
第四步,根据之前得到的映射,合成新的y和y的标记。
个人启发
运用一种新奇的数据增强方法(不是普通地对已有标签的数据进行旋转和缩放等操作),巧妙地解决了解决医学图像标注数据缺乏的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









