






今天我们来盘点一下主流AI大模型各方面性能的最新排名,分别从质量、速度、价格、对话能力、推理能力、编码、响应时间等能力来进行对比。
一、对话能力
Chatbot Arena是一个基于众包的大型模型评测基准。它为开发者和研究者提供了一个平台,在这里可以发布、测试和比较各种类型的聊天机器人,下面是根据Chatbot Arena的榜单排名。我们可以看出前三名是:GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro。
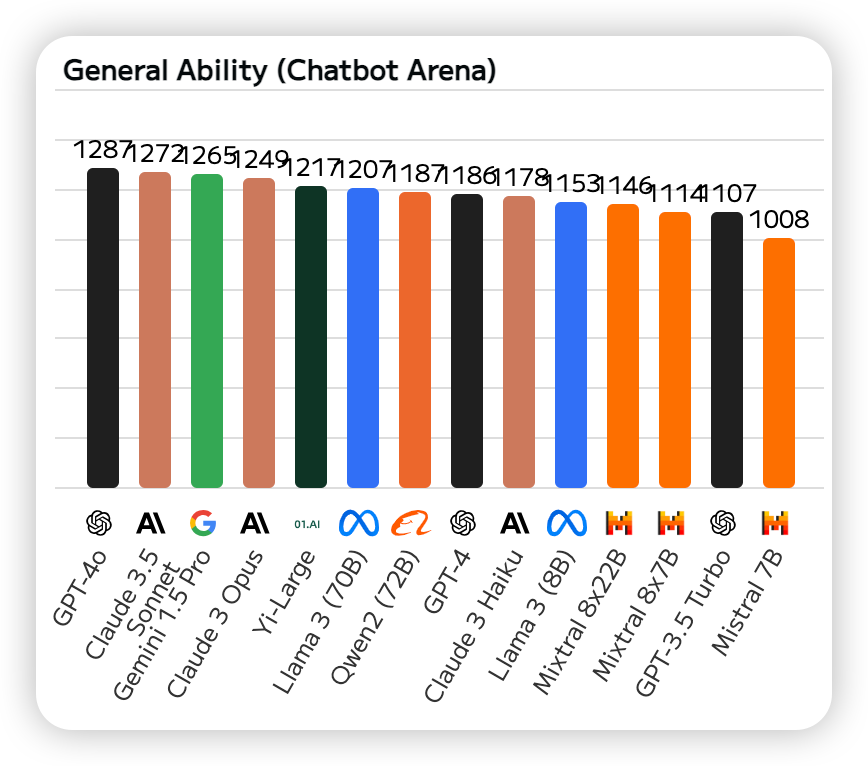
二、推理能力
MMLU(大规模多任务语言理解)是一项综合评估,MMLU 涵盖基础数学、美国历史、计算机科学和法律等 57 项任务。它需要模型来展示广泛的知识基础和解决问题的能力,下面是AI大模型根据MMLU的最新排名。我们可以看出前三名是GPT-4o、Claude 3.5 Sonnet、Claude 3 Opus。
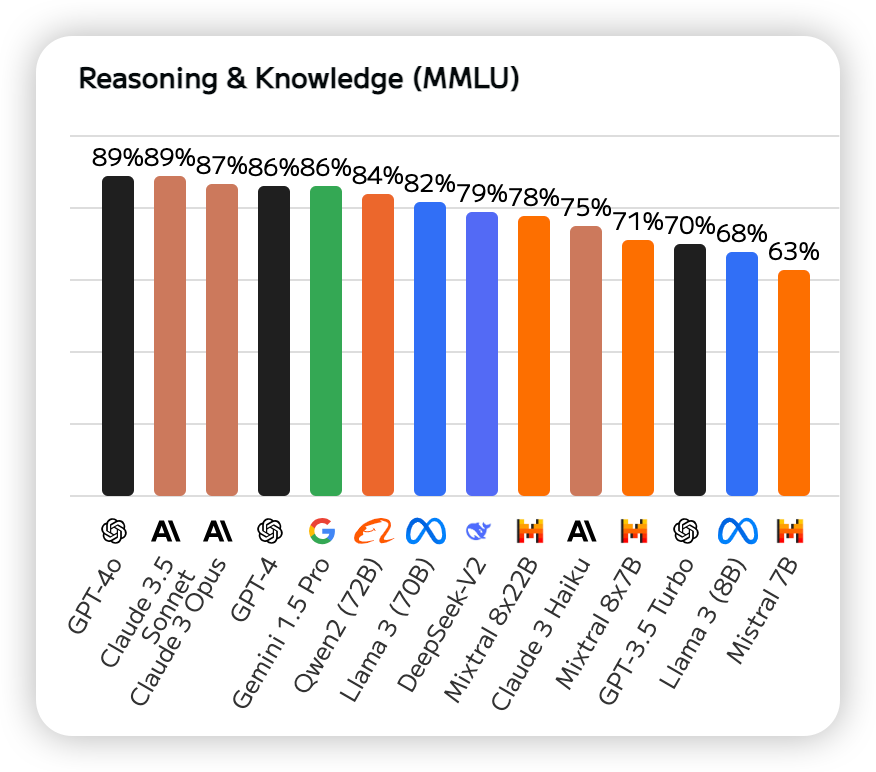
三、编程能力
HumanEval是一个用于评估代码生成模型性能的数据集,包含164个编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。下面是根据HumanEval排名的最新榜单。前三名是:Claude 3.5 Sonnet、GPT-4o、GPT-4。
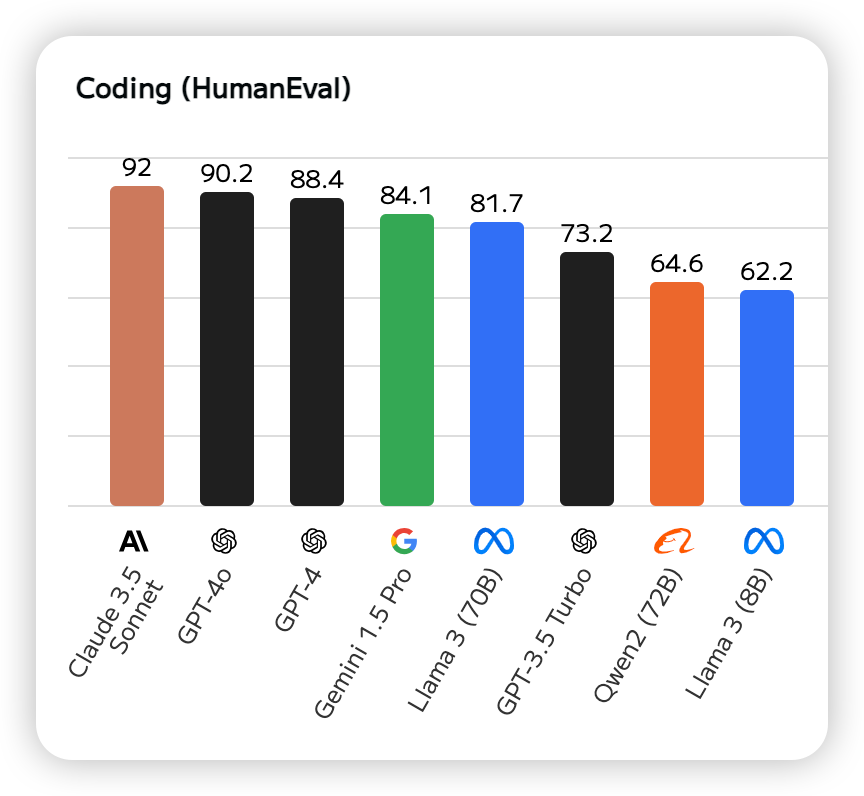
四、上下文窗口
上下文窗口指的是输入和输出标记的最大组合数量。当涉及到 RAG(检索增强生成)和大模型的工作流时,更大的上下文窗口变得非常重要,这些工作流通常需要对大量数据进行推理和信息检索。我们可以看到前三名是:Gemini 1.5 Pro、Claude 3.5 Sonnet、Claude 3 Opus。

五、输入输出的价格
每百万tokens的美元价格,排名越靠前越便宜。在这里我们可以看到国内的DeepSeek大模型价格最低,价格最高的是GPT-4。
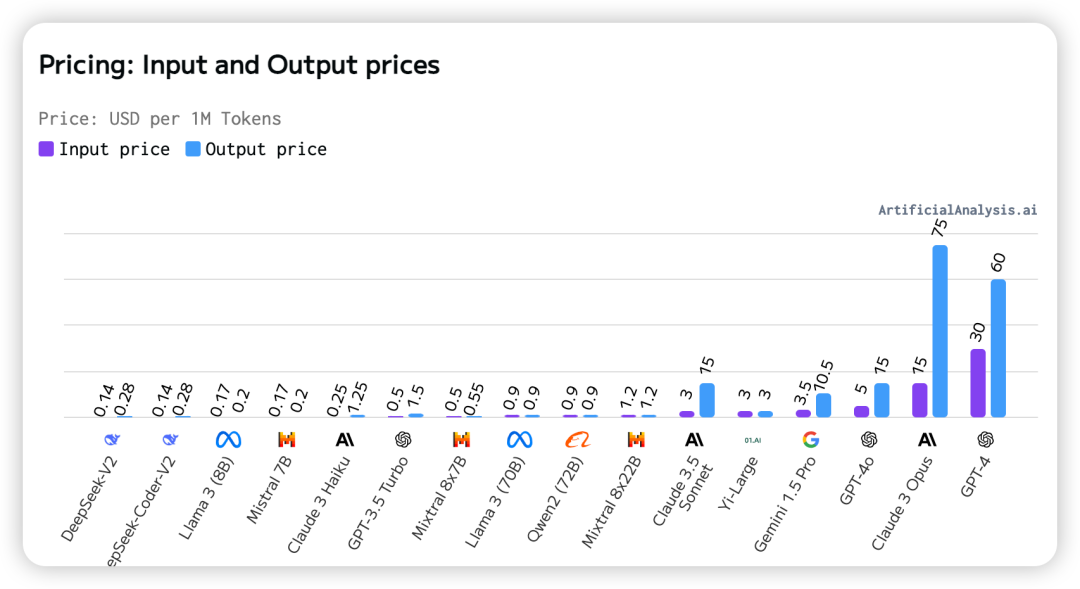
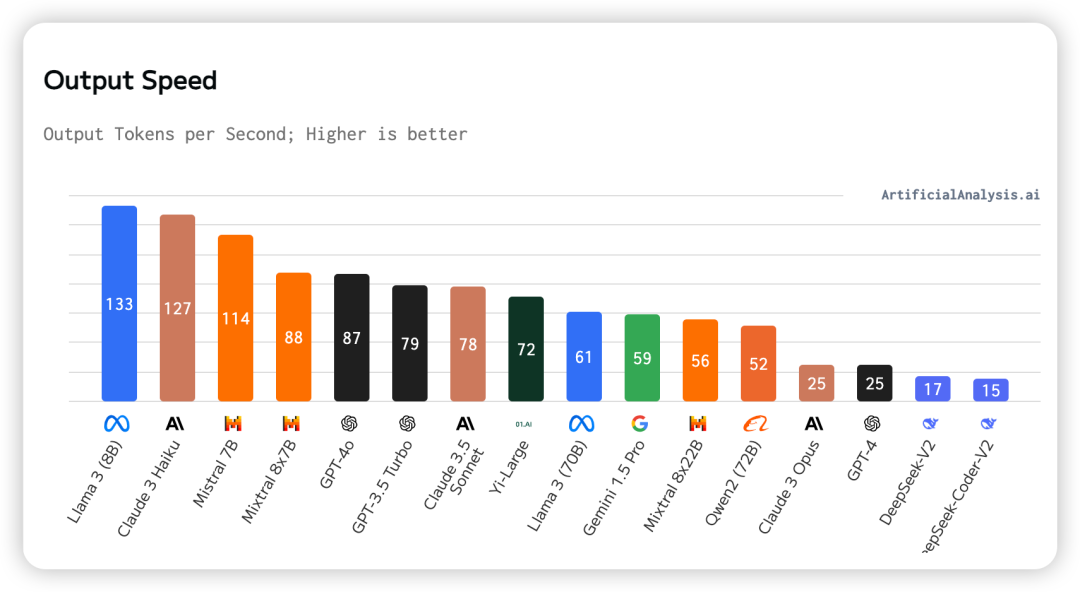
六、输出速度
模型生成token时每秒输出的token数量。 在这里我们可以看到输出速度最快的是Llama 3(8B),输出最慢的是DeepSeek-Coder-V2。
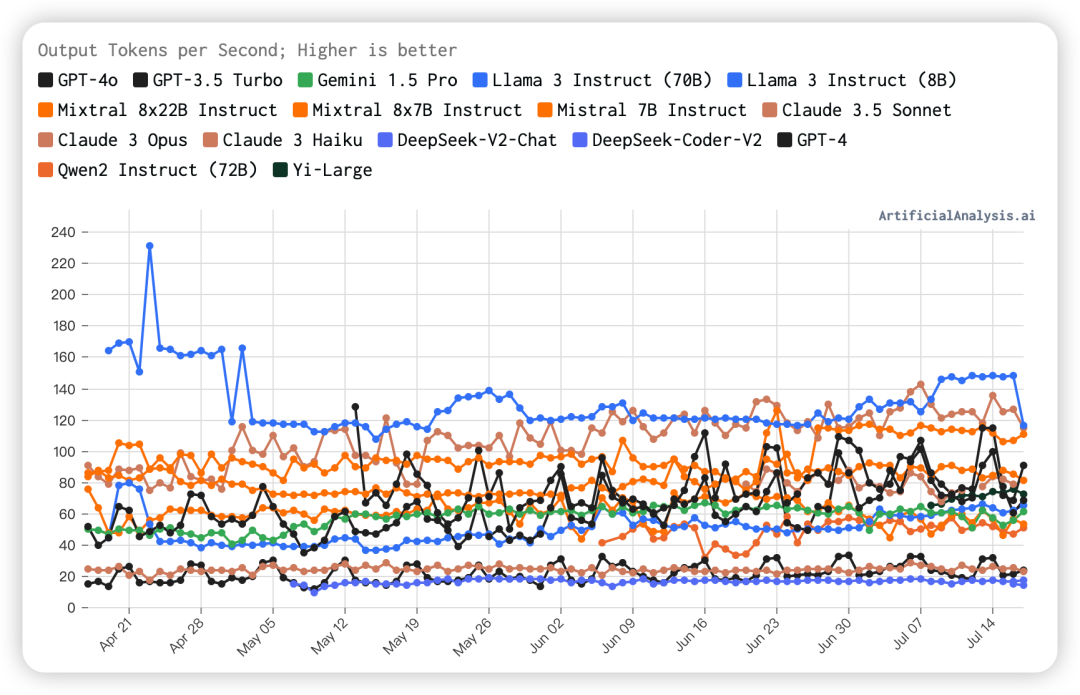
七、随时间变化的输出速度
我们从图中可以看出Llama3 Instruct(8B)的输出速度一直保持较高水平,不过最近有点下降。
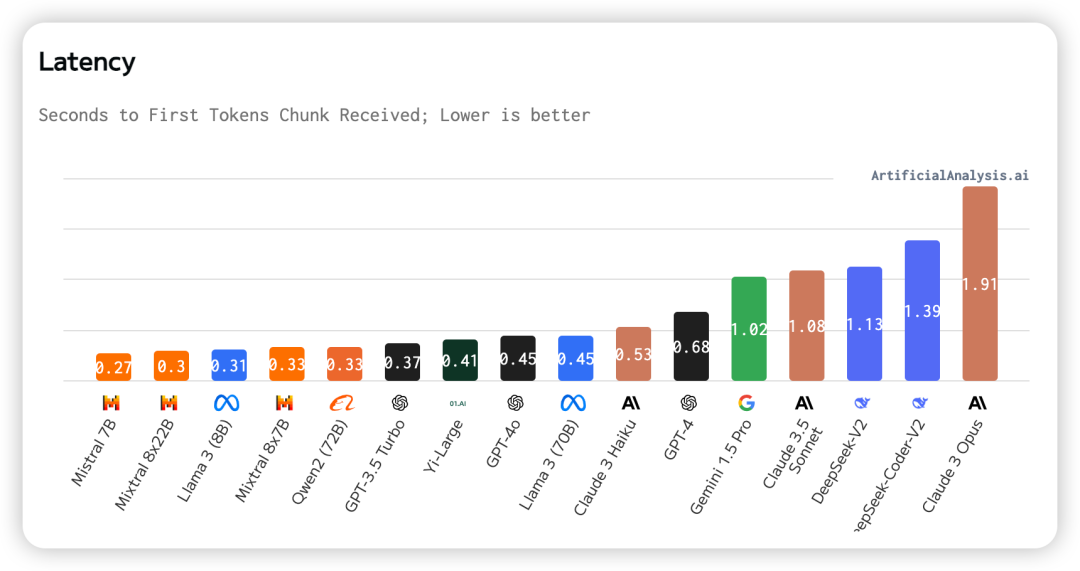
八、延迟
延迟的定义为发送 API 请求后,接收到第一个token所需的时间。在图中我们可以看到Mistral 7B的延迟最低,Claude 3 Opus的延迟最高。
九、随时间变化的延迟
从图中我们可以清晰地看出Claude 3 Opus的延迟一直较高,而Gemini 1.5 Pro的延迟有明显的改善。其他大模型的延迟都较低。

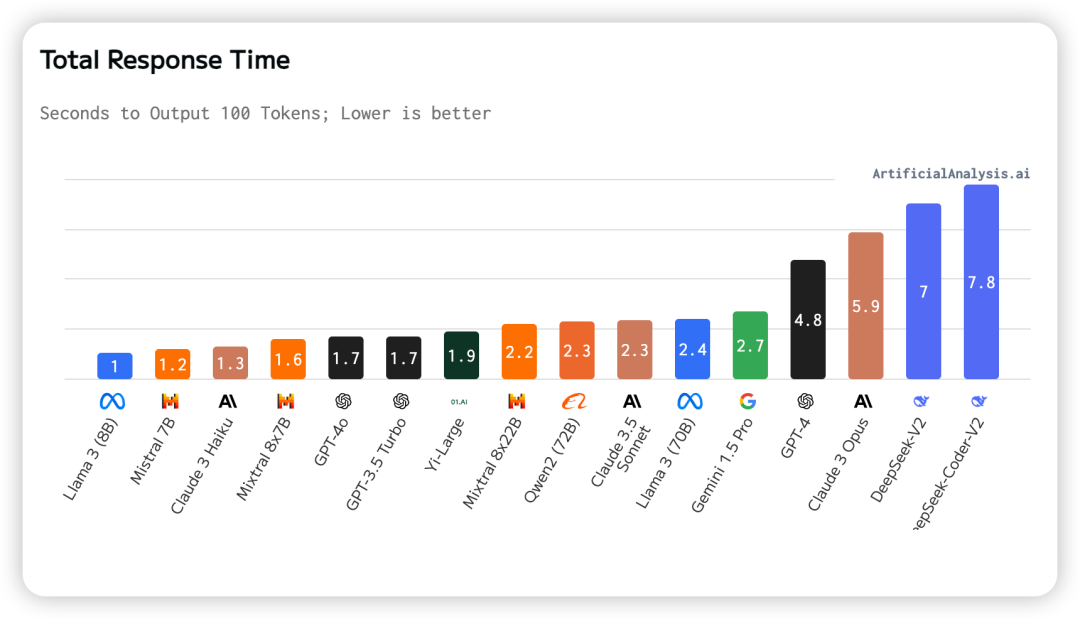
十、总响应时间
总响应时间为接收 100 个tokens所需的时间。根据延迟(接收第一个token的时间)和输出速度(每秒输出token数量)估算得出。从图中我们可以看出Llama3(8B)的总响应时间最短,而DeepSeek-Coder-V2的总响应时间最长。
大模型各方面的性能对我们开发AI产品的应用场景至关重要,对大模型各方面的性能进行测评可以帮助我们选择合适的选择合适的大模型和API提供商。无论是优化质量、提升速度、控制成本,还是需要特定的应用能力,这些大模型都为我们提供了丰富的选择。















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









