






目录
概述
为什么要使用elasticsearch,在很多网站,我们通常去搜索一条信息都是通过模糊查询去搜索的,但是模糊查询有一个痛点,就是它会去数据库里逐一的把每一条数据都进行扫描然后查询是否包含搜索信息,平时我们可能感觉不到,这要是有数百万条数据,那效率可就特别慢了
那我们用elasticsearch就可以解决这个问题了 ,通过名字就可以知道,es主要是用于查询
特点:数据存储、分析数据、搜索数据
一、elasticsearch安装
1.安装es
首先,在虚拟机部署一个
准备centos7
Elasticsearch 7.8.0 | Elastic下载链接
这边下载的7.8.0linux版本的
![]()
连接虚拟机
将压缩包放进用户级的目录下
解压到当前目录的es7.8下
tar -zxvf elasticsearch-7.8.0.tar.gz -C es7.8
2.创建新用户
需要创建一个新的虚拟机用户 如果有就不用了
因为不能通过root用户使用es
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
设置权限
chown -R es:es /usr/local/src/es7/es7.8 #文件夹所有者3.修改配置
1.修改/usr/local/src/es7/es7.8/config/elasticsearch.yml文件(注意自己es的安装位置)
vim /usr/local/src/es7/es7.8/config/elasticsearch.yml# 加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
2.还需要修改虚拟机系统的配置 修改/etc/security/limits.conf
直接复制到最下面即可
防止es启动报错
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
es soft nproc 4096
es hard nproc 4096
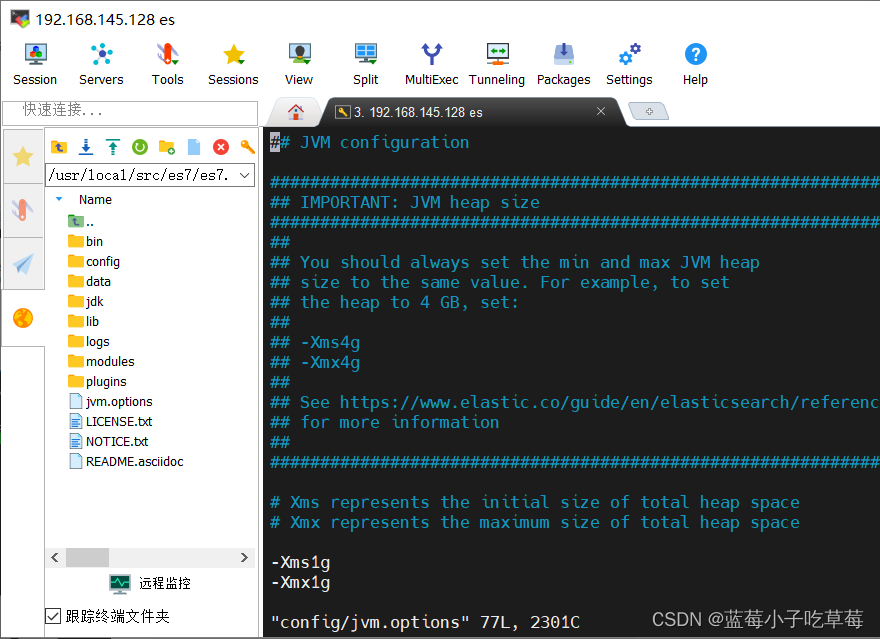
3.修改jvm配置
修改es的config文件下的jvm.options
vim config/jvm.options
我这里设置的最小的内存了 不能小于1G
4.修改/etc/sysctl.conf
设置最大虚拟内存
vm.max_map_count=655360重新加载
sysctl -p4.在防火墙放行端口
注意开放防火墙需要root用户的权限
开放9200
firewall-cmd --add-port=9200/tcp --permanent重启防火墙
firewall-cmd --reload查看是否开放
firewall-cmd --list-ports
5.启动
进入安装目录
通过命令启动
bin/elasticsearch
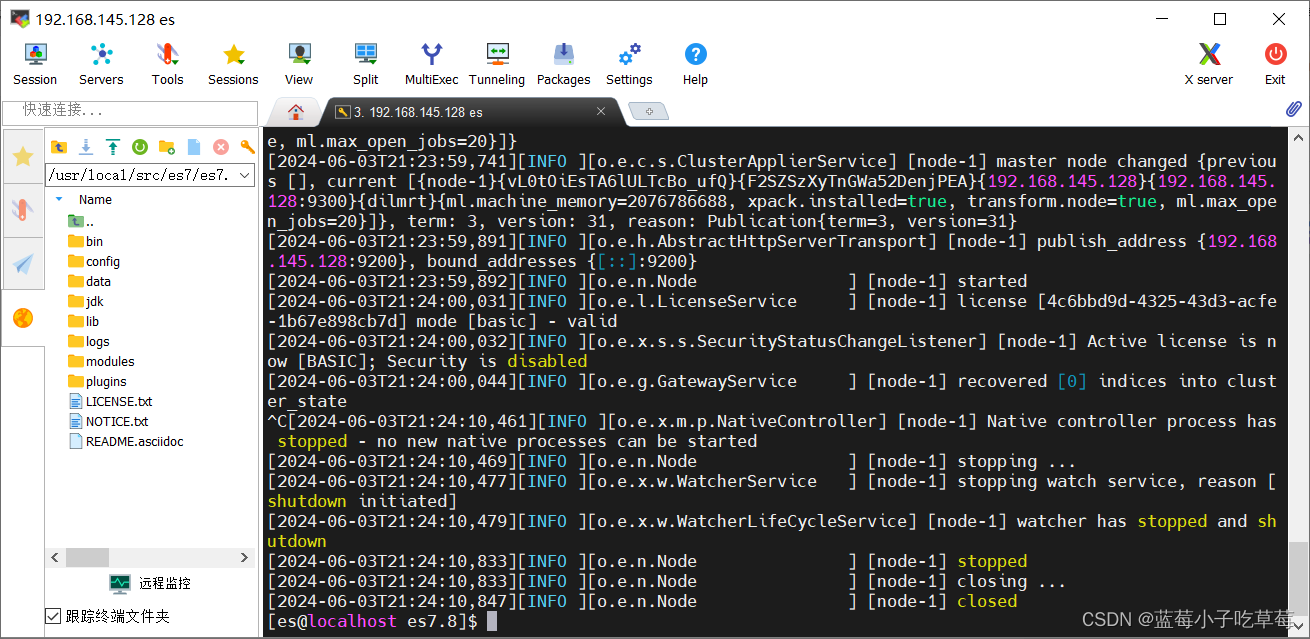
后台启动
bin/elasticsearch -d 没有报错就是启动成功了
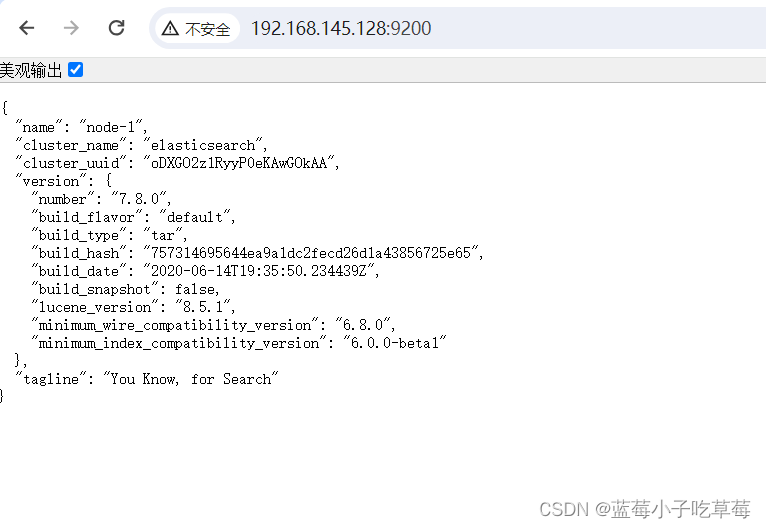
6.访问
在浏览器输入 虚拟机的id:9200
7.安装kibana
kibana是一个图形化工具,可以更方便的操作es
注意:kibana的版本最好和es的一致
我们可以前往官网下载: https://www.elastic.co/cn/downloads/kibana
![]()
然后上传到虚拟机/usr/local/src/kibana/
解压到当前目录
tar -zxvf kibana-7.11.1.tar.gz
修改kibana配置
vim /usr/local/src/kibana/config/kibana.yml需要修改五个地方
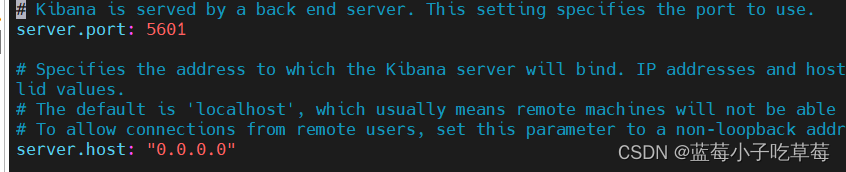
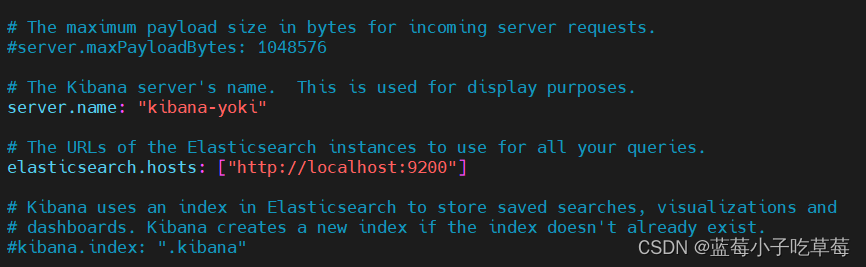

server.port : http 访问端口
server.host : ip 地址,0.0.0.0 表示任何地址都可以访问
server.name : kibana服务名
elasticsearch.hosts : elasticsearch 地址
elasticsearch.requestTimeout :请求 elasticsearch 超时时间,默认为 30000 ,此处可根据情况设置
记得要给kibana文件设置为允许es用户访问
chown -R es:es /usr/local/src/kibana/在防火墙开启kibana的端口5601
firewall-cmd --add-port=5601/tcp --permanent重启防护墙
firewall-cmd --reload通过es用户启动kibana
cd /usr/local/src/kibana/kibana7.8/
bin/kibana
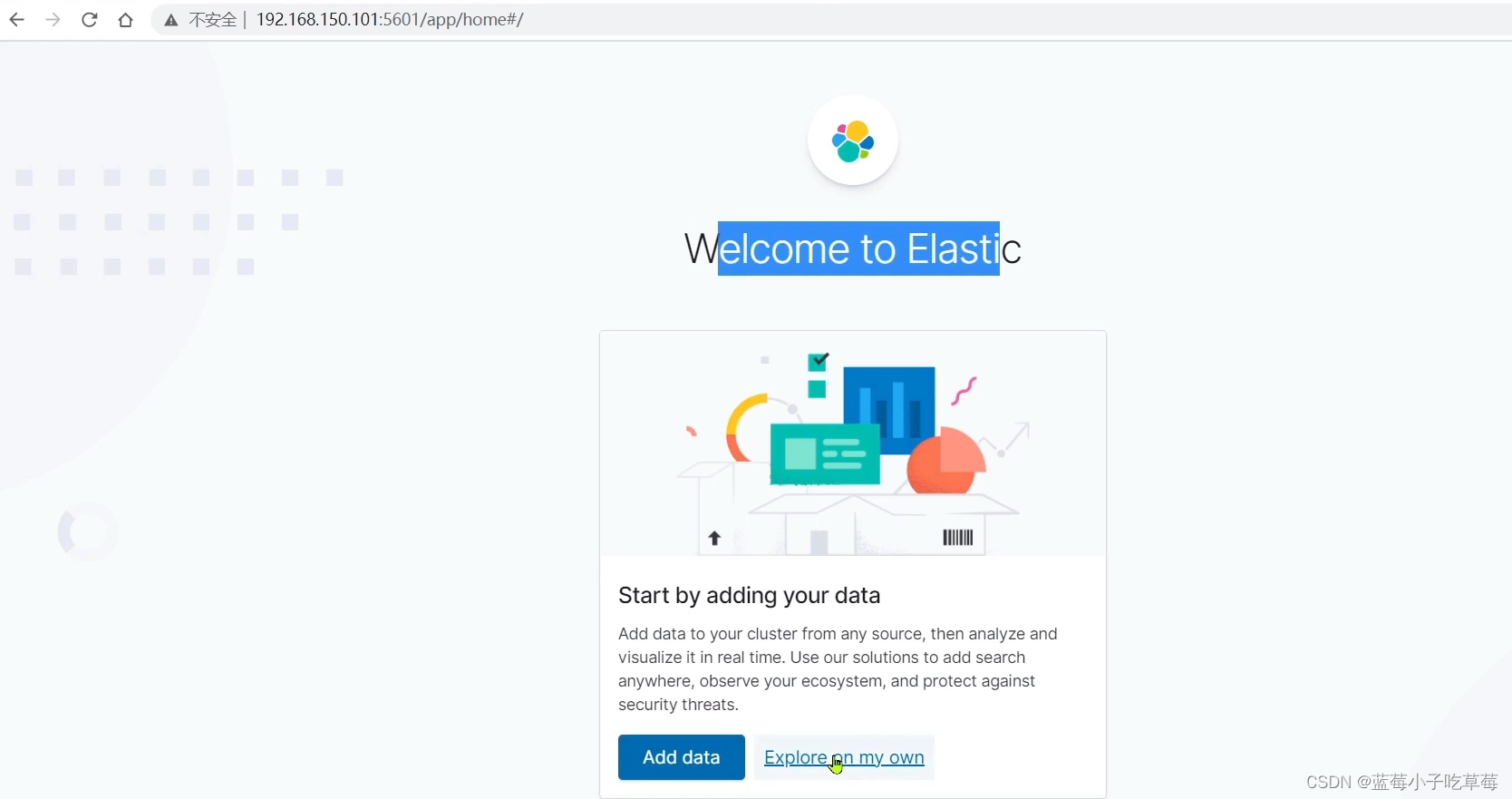
选择explore on my own 自己探索
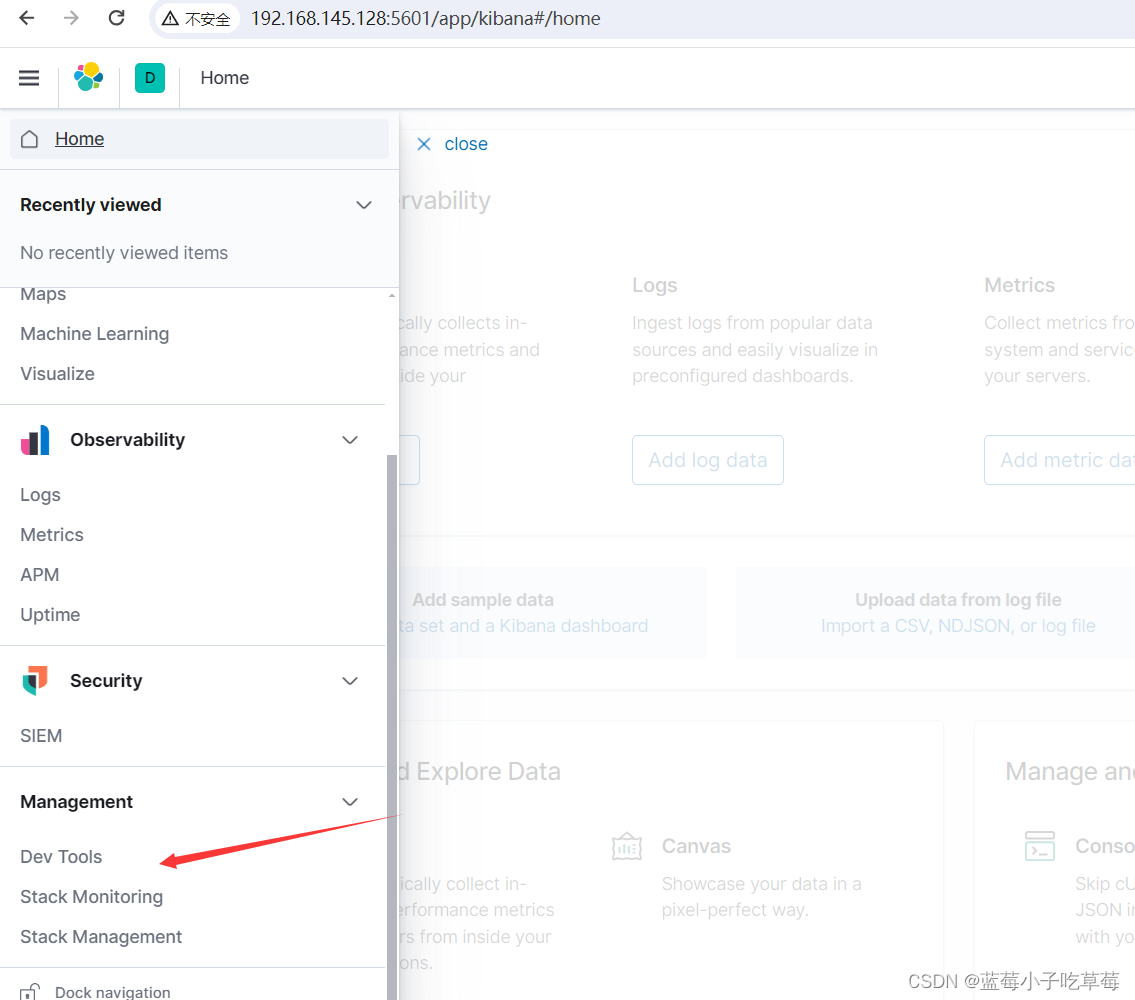
通过 dev tools 进行对es 的操作
这一个框框里的就是dsl语句 get代表是发送get的请求 发送一个restful的请求到es中
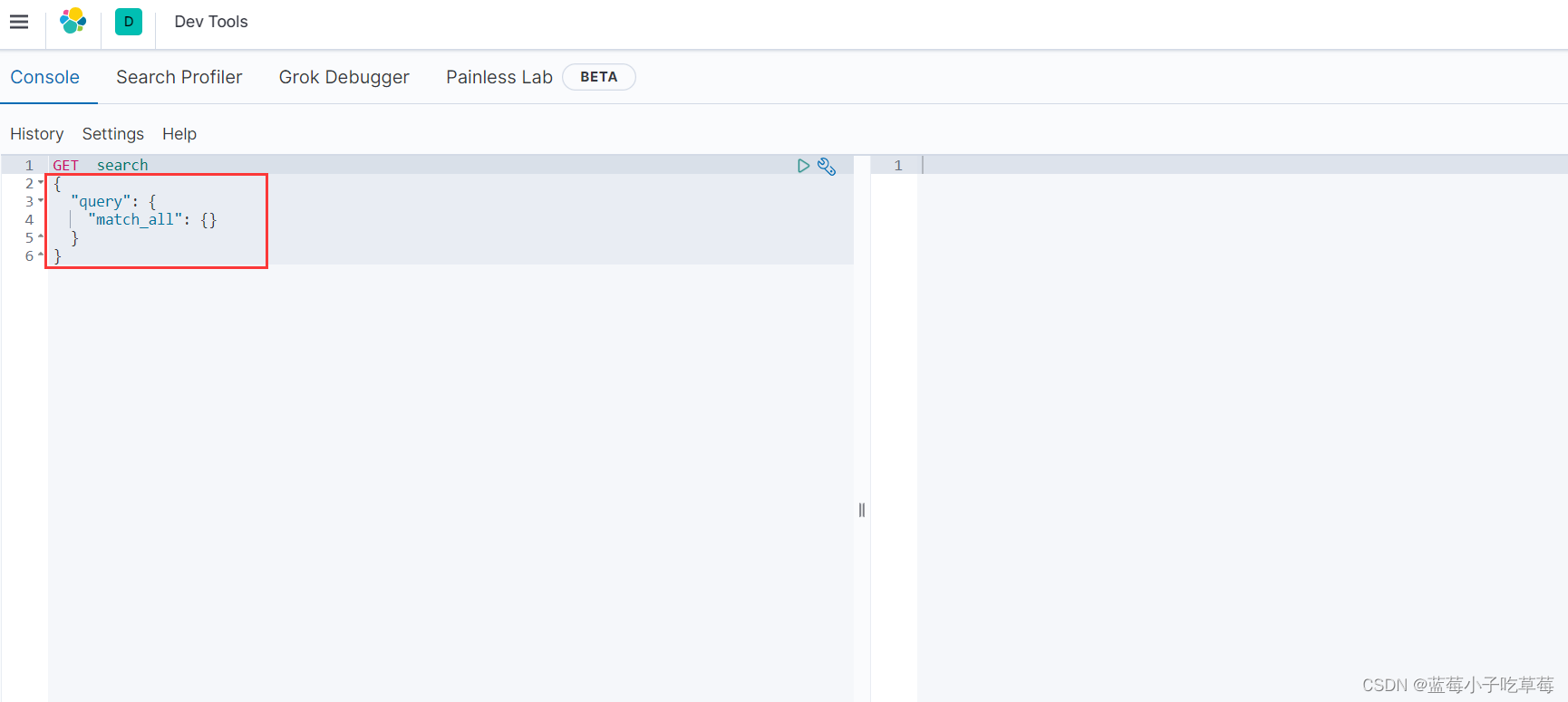
这里不用指定es的ip端口 是因为在配置kibana的时候已经配置好了
这里我们测试一下
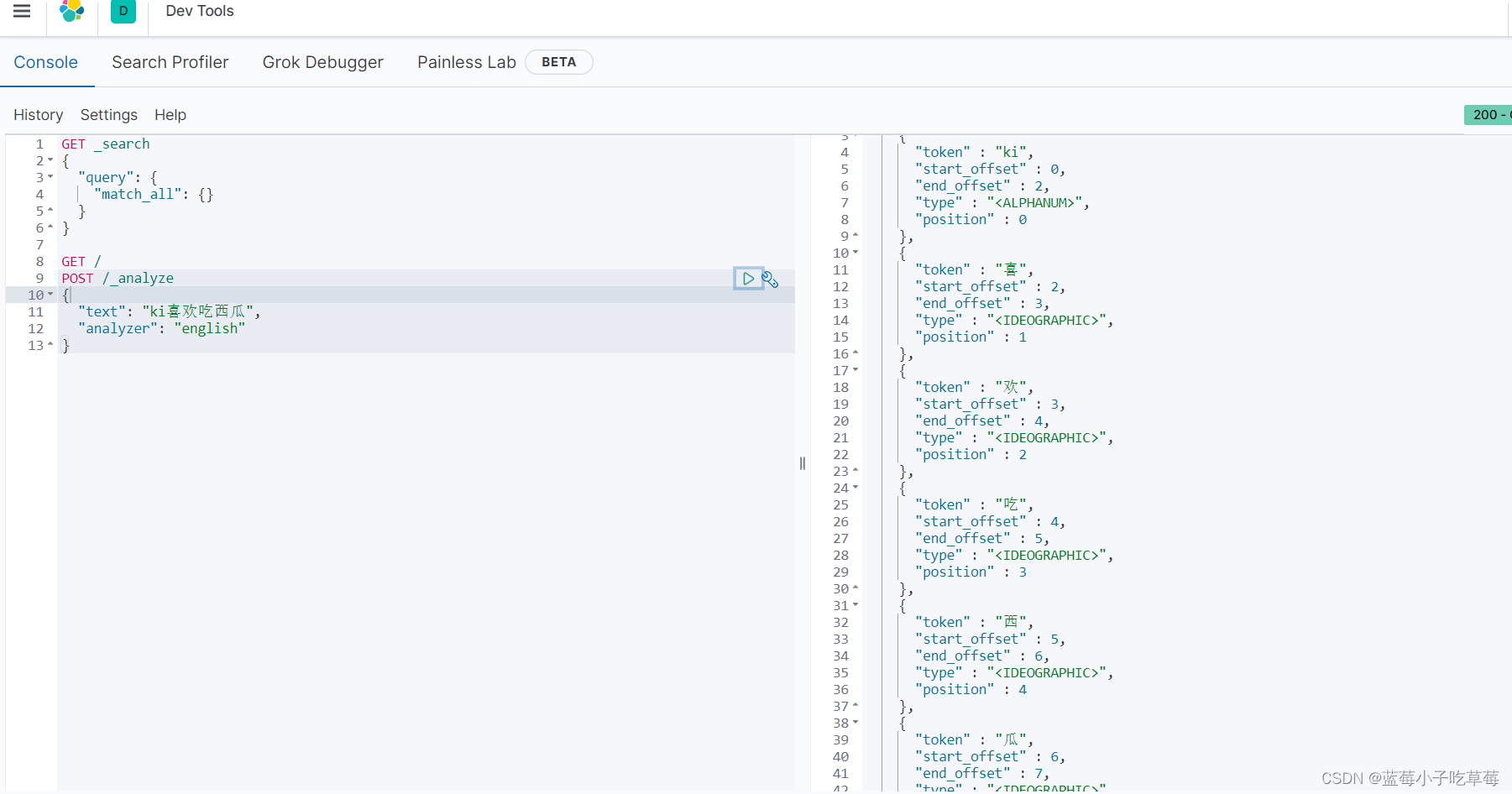
可以看到对于我们的中文都是一个字进行拆分的
安装一个插件注意版本一致
分词器 :https://github.com/medcl/elasticsearch-analysis-ik
不要下到源文件了
我这里是先解压后改名为ik再放入到/usr/local/src/es7/es7.8/plugins/
然后再重新启动访问kibana
analyzer改为ik_max_word
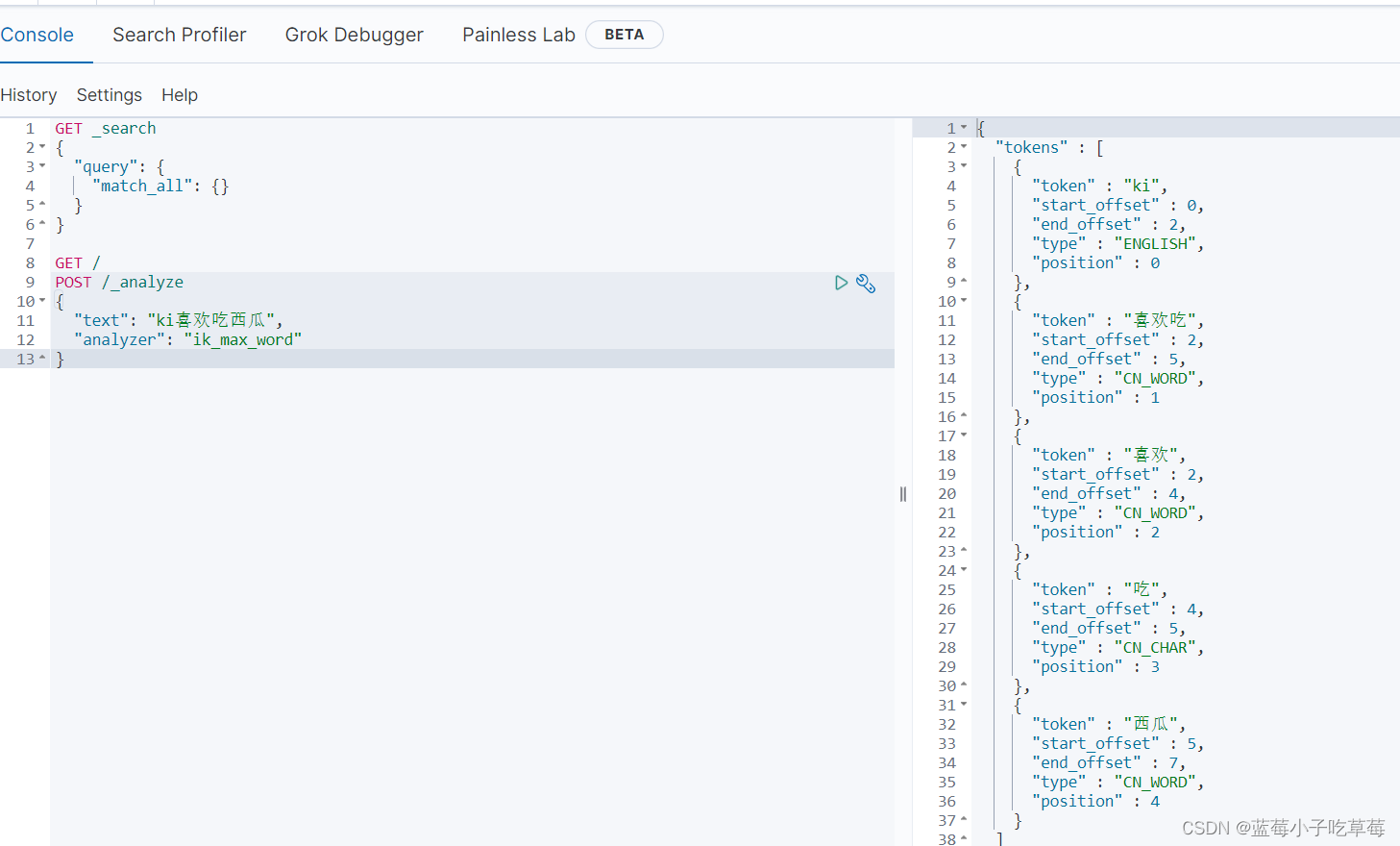
当然这里的分词是不一定满足我们的需求的
我们可以去ik的配置文件下的xml文件
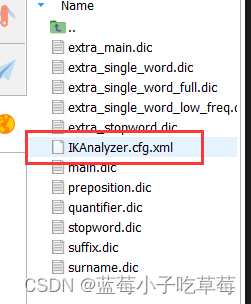
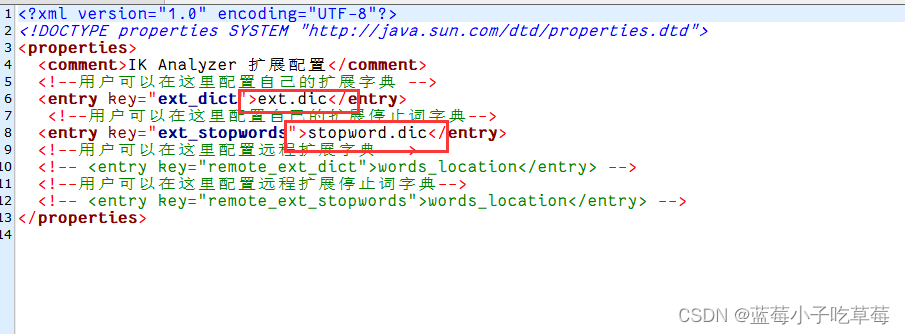
去新增分词和禁用
ext.dic是需要自己创建一个的
stopword.dic是有的
二、认识elasticsearch
1.倒排索引
es其实也是一个数据库 ,它和平常的mysql不一样的地方是, mysql采用的是正向索引
而es的核心是倒排索引
1.什么是倒排索引
在倒排索引中分为了,文档和词条
倒排索引就是根据内容查询到id
每一条文档就是一条数据
词条是对文档进行分词得到的
在es中文档id和词条就组成一个一个索引
我们的查询流程就变成了 先去倒排索引中查找词条 ,再根据词条的的id去正向索引中查找
2.es与mysql的概念对比
mysql中有table、row、column、schema、sql
在es中对应了index、document、field、mapping、dsl
看着是差不多的,都有对应关系,那是不是可以用es替代mysql呢?
当然 ,是不能够的
因为他们两个擅长的领域是不一样的
mysql更擅长事务的处理、确保数据的安全性和一致性
而es则是在海量的数据里面查找需要的信息
所以说,他们两个是都不能少的
3.索引库操作
1.mapping属性
对于数据库我们肯定需要对其进行约束
也就是mapping mapping包括4个方面
- type 数据类型
- index 是否索引 参与搜索
- analyzer 分词器
- properties 子字段
type常见的类型
- 字符串 text 可以分词的 keyword精确的 不可分词
- 数值 long integer short float double
- 布尔值 true flase
- 对象 object
- 日期 date
2.创建index
使用put 索引名称 以及mapping进行约束
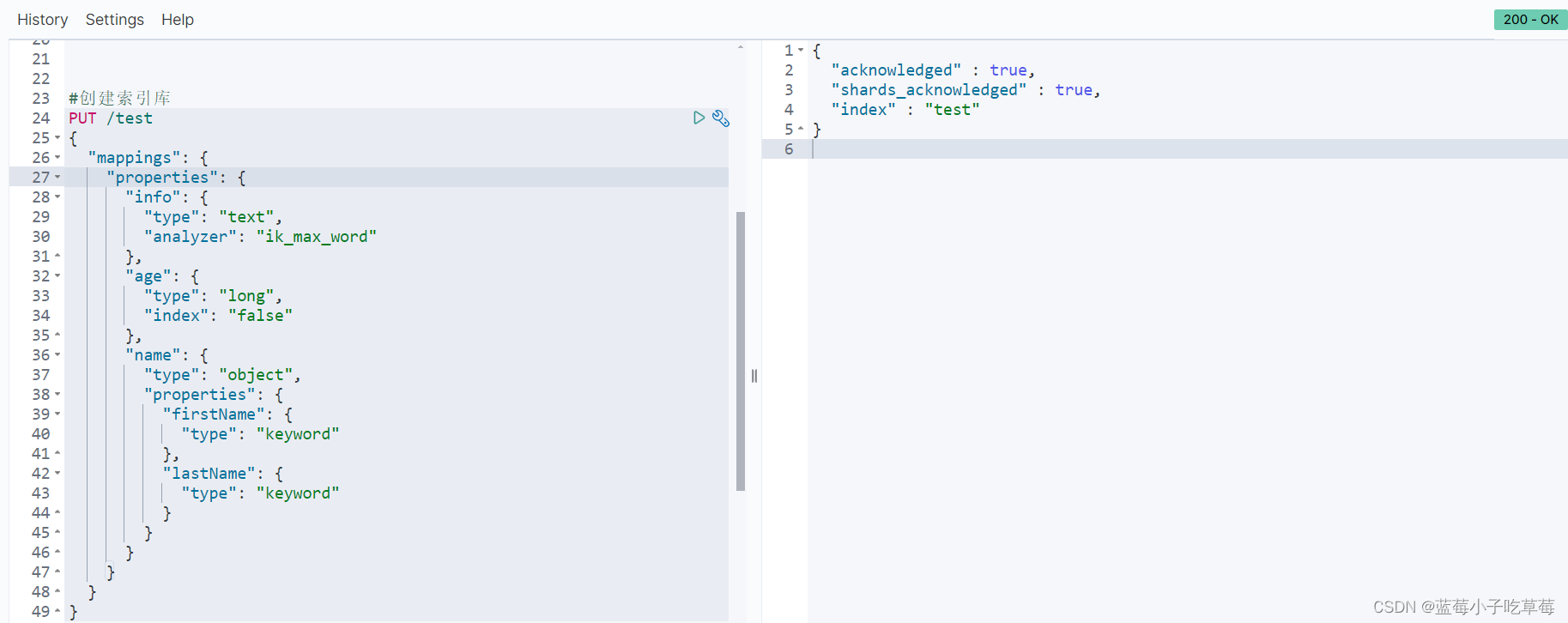
其它操作

总结:对索引库的操作 发送的请求只有get 、put、delete 其中put可以创建,也可以修改 ,但是修改是只能在原来的基础上进行添加
4.对文档的操作
1.文档的crud
新增文档的语法
Post /索引库名/_doc/文档id
#新增文档
POST /test/_doc/t001
{
"age":"18",
"info":"人中吕布,马中赤兔",
"name": {
"firstName": "吕",
"lastName": "布"
},
"sex": 1
}
其它操作就只需要换一下请求方式
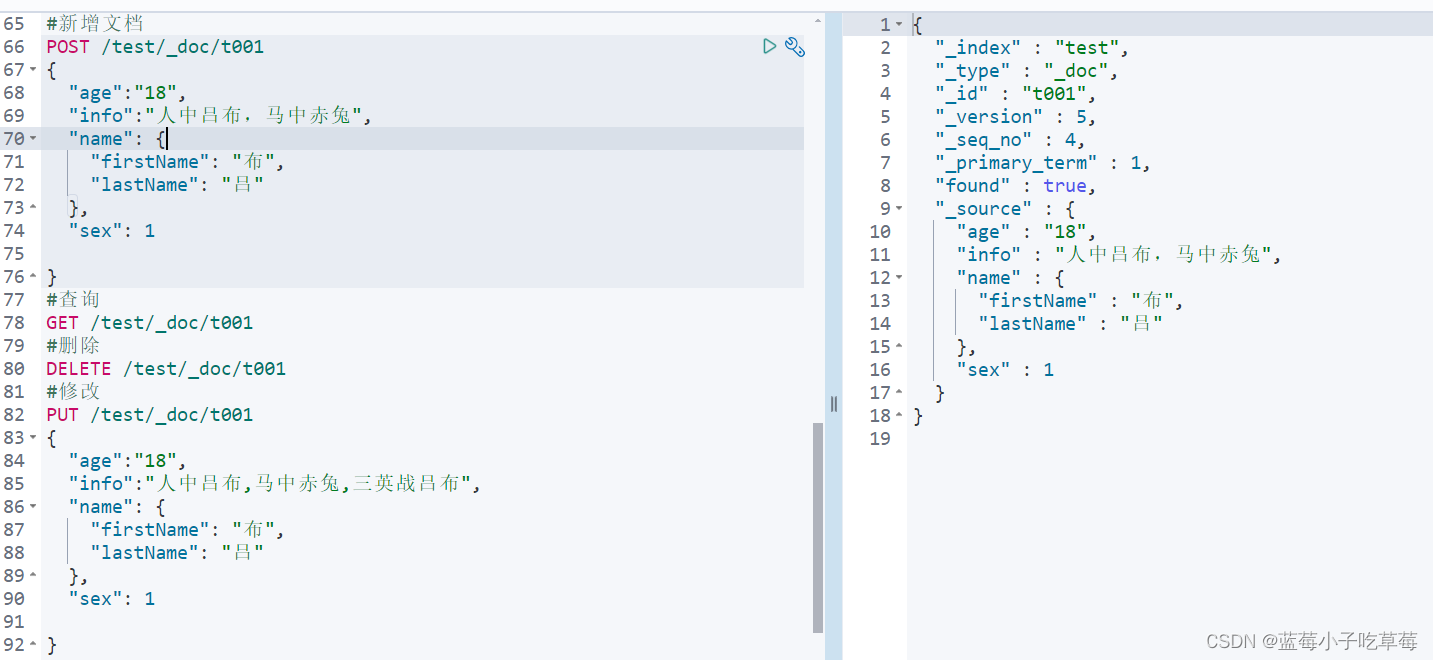
返回结果
{
"_index" : "test", //索引库
"_type" : "_doc", //文档类型
"_id" : "t001",//文档id
"_version" : 5,//版本 代表修改的次数
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {//原始文档
"age" : "18",
"info" : "人中吕布,马中赤兔",
"name" : {
"firstName" : "布",
"lastName" : "吕"
},
"sex" : 1
}
}
注意:修改操作有全量修改和增量修改
全量修改就是把原来的删掉再重新插入 增量修改是只修改需要的
#全量修改 和新增的区别就是换了个请求方式 如果文档id存在就是修改 不存在 就是新增
PUT /test/_doc/t001
{
"age":"18",
"info":"人中吕布,马中赤兔,三英战吕布",
"name": {
"firstName": "布",
"lastName": "吕"
},
"sex": 1
}
#增量修改
POST /索引库/_update/文档id
{
"doc": {
"字段名":
}
}
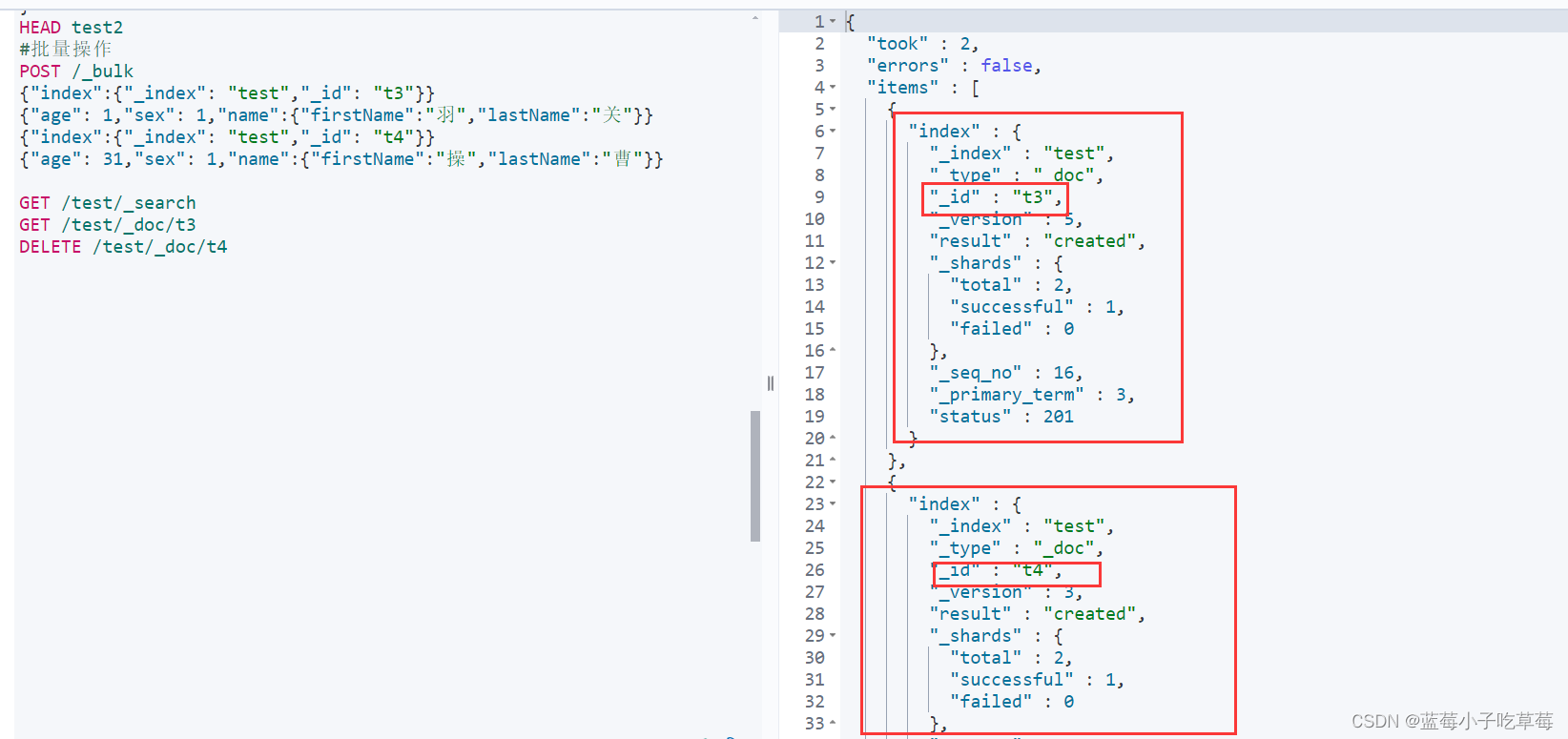
2.批量操作
语法 _bulk表示批量的意思
POST /_bulk
{"index":{"_index": "索引库","_id": "文档id"}}
{"age": 1,"sex": 1,"name":{"firstName":"羽","lastName":"关"}}
{"index":{"_index": "索引库","_id": "文档id"}}
{"age": 31,"sex": 1,"name":{"firstName":"操","lastName":"曹"}}
可以看到外面新增成功了















 3480
3480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









