






前些日子,做了一个物业收费系统,cs模式,用到了linq to sql 技术,这是我第一次使用这个东东写程序存取数据库,迷迷糊糊搞得一塌糊涂,当时有个同学他们找好的分页组件,然后写好了调用方法,由于时间比较急,而且第一次用,所以没有怎么研究就直接按照注释使用他们写好的分页方法,然而开发过程中一直都对他们写的方法有怀疑,会不会是一种投机取巧,胡编乱造的?后来我也做过一些简单分析,我发现程序在业务逻辑层中每次都从数据库中将数据全部读取出来,然后循环将数据转成特定的List,也就是遍历整个数据集合,然后在显示层中将List进行分页,最后放到DataGridView中,其中列名自动设定为类的属性值,刚开始我还一直认为这样的方法好方便啊,一下子全部生成了,直到程序马上接近尾声时,我发现程序的操作日志记录已经达到了4500条,每次打开日志管理界面时,程序都要加载上半天才能出来,我彻底对linq产生了怀疑,确切的说并不是对linq产生怀疑,而是分页方法以及程序算法产生了怀疑。
显示层的分页代码部分:
显示层的分页代码部分:
1 dataGridView.DataSource = data.Take(pagerControl1.PageSize * pagerControl1.PageIndex).Skip(pagerControl1.PageSize * (pagerControl1.PageIndex - 1)).ToList();,其中data是业务逻辑层获取到的数据,业务逻辑层:
2
3
4 var data = from d in jx.LogTable
5 orderby d.OperTime descending
6 where Tflag.Equals("全部") ||
7 ((d.OperTime >= t1 && d.OperTime <= t2) && (d.OperName.Contains(content) || d.UserID.Contains(content)))
8 select d;
9 List<LogTable> items = new List<LogTable>();
10 foreach (var d in data)
11 {
12 LogTable item = new LogTable();
13 item.编号 = trim(d.ID);
14 item.事件 = trim(d.OperName);
15 item.操作员 = trim(d.UserID);
16 item.标志 = trim(d.mark);
17 item.操作时间 = trim(d.OperTime);
18 items.Add(item);
19 }
20 return items;
此处不仅将所有数据全部读取出来了,而且还遍历了一遍,当数据达到4500条时就出现了卡顿现象,情况糟糕程度可想而知,好丑陋的代码啊,而且程序牵扯到这个的地方简直多的要命,如果要改动的话,一定是一场灾难!
之前一直在忙,没有时间去测试程序中所存在的问题以及如何能更高效的使用linq开发应用程序,今天挤出点时间来做了个小小的测试,这让我重新对linq产生了兴趣。
测试中的数据库表仍然不改变,还是操作日志表,不同的是我在该表中追加了更多的数据,总记录数几乎达到 110万条,然后对这110万条数据进行测试。具体测试如下:
当点击数据总条数时,弹出数据库操作日志表的总记录数,点击加载数据时,对110万条数据进行分页 , 每页10条,取第三页的10条数据,点清空数据时,对表格中加载的数据进行清空处理:
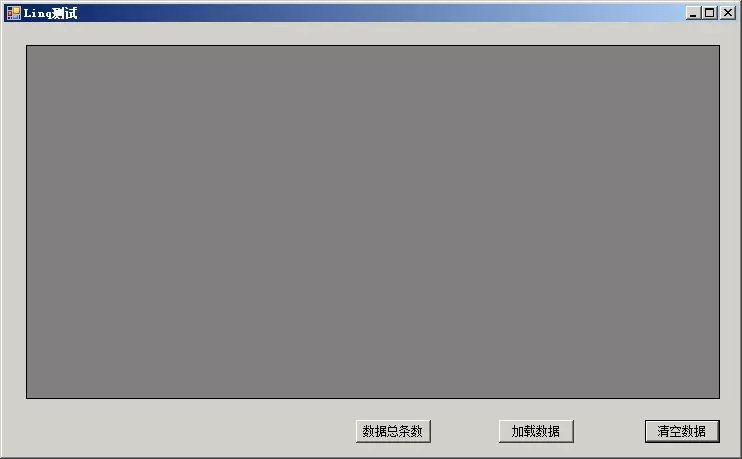 总条数如下:
总条数如下:
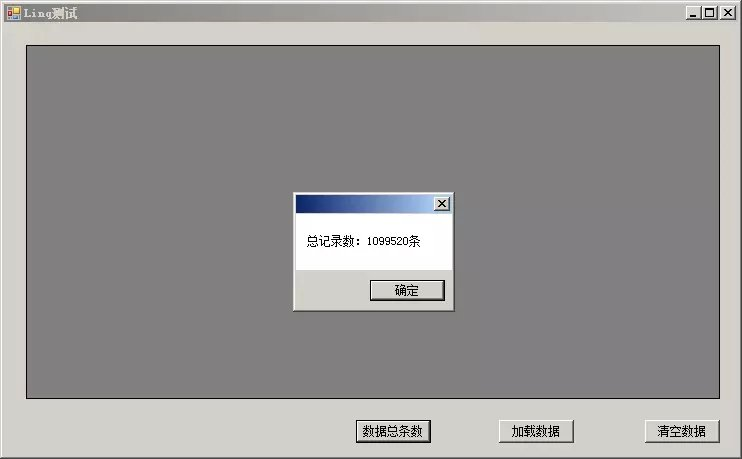 首次运行,点击加载数据时,共耗时9100毫秒:
首次运行,点击加载数据时,共耗时9100毫秒:
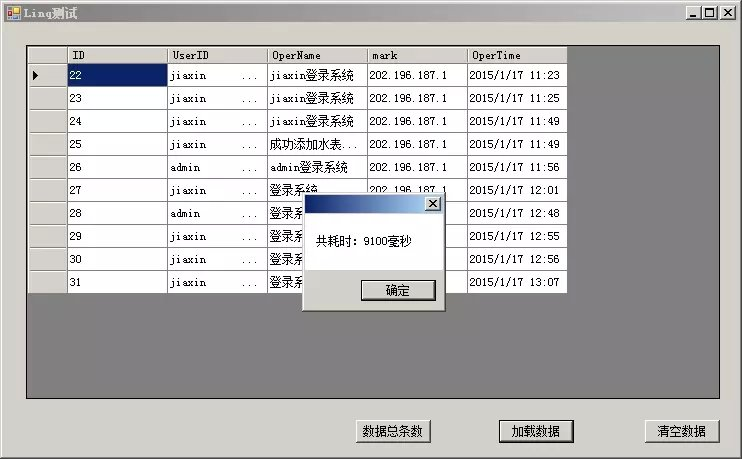
于是,为了测试效率,我将数据追加到了220万条,重新测试:
之前一直在忙,没有时间去测试程序中所存在的问题以及如何能更高效的使用linq开发应用程序,今天挤出点时间来做了个小小的测试,这让我重新对linq产生了兴趣。
测试中的数据库表仍然不改变,还是操作日志表,不同的是我在该表中追加了更多的数据,总记录数几乎达到 110万条,然后对这110万条数据进行测试。具体测试如下:
当点击数据总条数时,弹出数据库操作日志表的总记录数,点击加载数据时,对110万条数据进行分页 , 每页10条,取第三页的10条数据,点清空数据时,对表格中加载的数据进行清空处理:
然后点击清空数据,再次点击加载数据时,共耗时2899毫秒:

之后重复测试,时间一直保持在3000毫秒左右,也就是3秒钟,第二次点击后发现时间明显加快了,3倍有余,但是我想说的是这个速度还是非常非常慢的,因为表中的数据列所存储的值很小,没有什么大的数据,为什么会这么慢呢?看代码:
1 Stopwatch sw = new Stopwatch();
2 sw.Start(); //开始计时
3
4 var data = (from d in db.Log select d).ToList();//将数据全部查询出来,并且ToList()
5 dataGridView1.DataSource = data.Skip(20).Take(10).ToList();//分页
6
7 sw.Stop(); //计时结束
8 MessageBox.Show("共耗时:"+sw.ElapsedMilliseconds.ToString()+"毫秒");
9
然后我对代码做了改变,如下:
1 Stopwatch sw = new Stopwatch();
2 sw.Start(); //开始计时
3
4 var data = (from d in db.Log select d);//只是写好了查询条件,注意此处
5 dataGridView1.DataSource = data.Skip(20).Take(10).ToList();//分页
6
7 sw.Stop(); //计时结束
8 MessageBox.Show("共耗时:"+sw.ElapsedMilliseconds.ToString()+"毫秒");
其实只是将上边标红的地方删掉了,也就是ToList()部分, 采用控制变量法,其他数据和条件全部不做任何变动,看效果:
首次点击加载数据时,共耗时185毫秒:
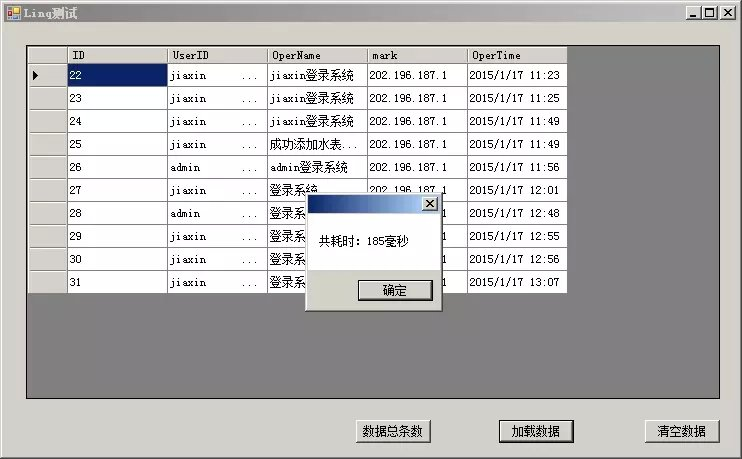
首次点击加载数据时,共耗时185毫秒:
清空后,第二次点击加载数据时,共耗时39毫秒:
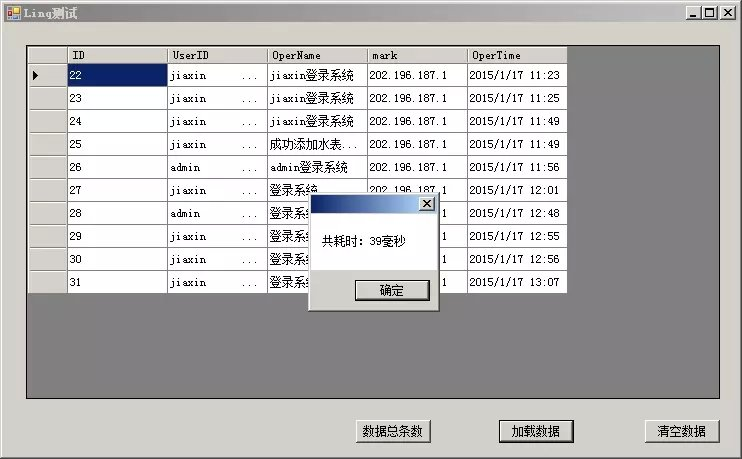
之后测试,一直保持在40毫秒左右,差距为什么会这么大?
其实,LINQ执行过程的一个重要特征是延迟加载,就是知道要获取数据时,才会进行计算。大家可能认为执行完var data = from db.Log select d语句,然后在开始skip,take函数进行分页,所有的值都会存到data中了,实际上,这条语句会延迟到foreach或者ToList()调用时才会执行。而var data = (from db.Log select d)Skip(20).Take(10);语句执行完之后,程序只是生成了一个比较完美的sql语句等待着执行,直到ToList()或者foreach出现,也就是一直等待程序需要获取数据时才开始执行数据库查询,这就解释了为什么差距会这么大的问题,同时也说明了linq进行分页的效率还是非常可以的,在110万条记录下进行分页最多需要大约200毫秒时间,最快大约40毫秒。
一定要注意:先分页在获取,而不是先获取再分页!
一定要注意:先分页在获取,而不是先获取再分页!
大功告成,经过测试,在linq分页前不能调用读取方法,应该分页后再查询...看来本次的项目开发可以大胆的继续使用linq来操作数据库了。当然,之前的物业管理系统,等忙完这一段时间,我得帮忙改改去,做人得负责任啊!!!
没文化真可怕,这么简单的知识竟然现在才知道!
我的网址是:http://www.yxxrui.cn














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









