






OCR(Optical Character Recognition,光学字符识别),可能大家不太明白是什么意思。
说人话就是图片内容识别,今天要介绍的这款工具——Umi-OCR,就是把图片内容转换成文本内容。
1、什么是Umi-OCR?
Umi-OCR是一款基于深度学习的OCR工具,能够快速将扫描的图像或PDF文档中的文字提取出来。
下载安装软件以后,上传需要识别的图像或PDF文件,选择识别语言和输出格式,点击开始识别即可。经过几秒钟的处理,用户将获得高质量的文本输出。
其核心技术源自先进的人工智能算法,支持多种语言和字体,使其在各种场景下都能表现出色,而且这个软件是完全免费的。
2、下载 Umi-OCR
https://pan.quark.cn/s/579d539eac0d
下载以后直接双击安装即可。注意这是离线版软件,安装完成以后也没有桌面快捷方式,在安装目录下,双击打开。
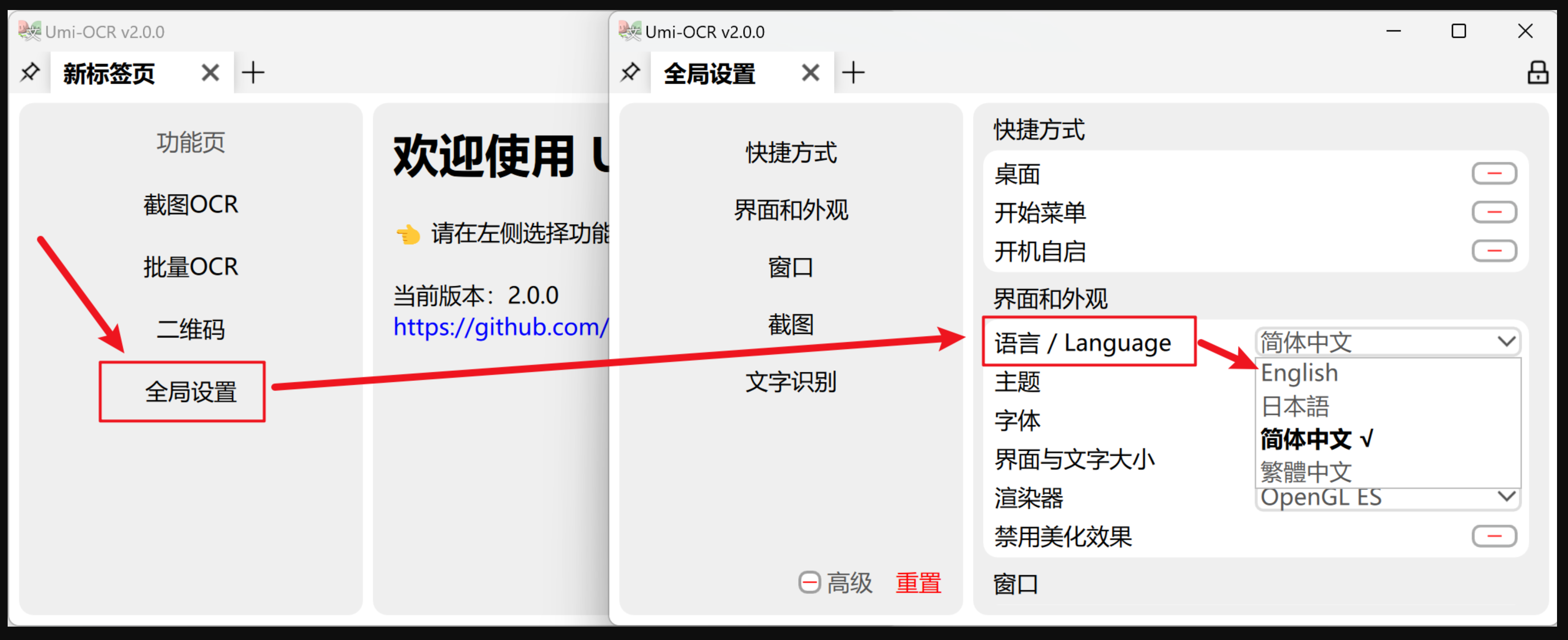
3、界面语言
Umi-OCR 支持的界面多国语言。在第一次打开软件时,将会按照你的电脑的系统设置,自动切换语言。
如果需要手动切换语言,请参考下图,全局设置→语言/Language 。
4、截图OCR
打开截图OCR标签页,然后把图片拖入该窗口,或直接复制粘贴图片到该窗口。
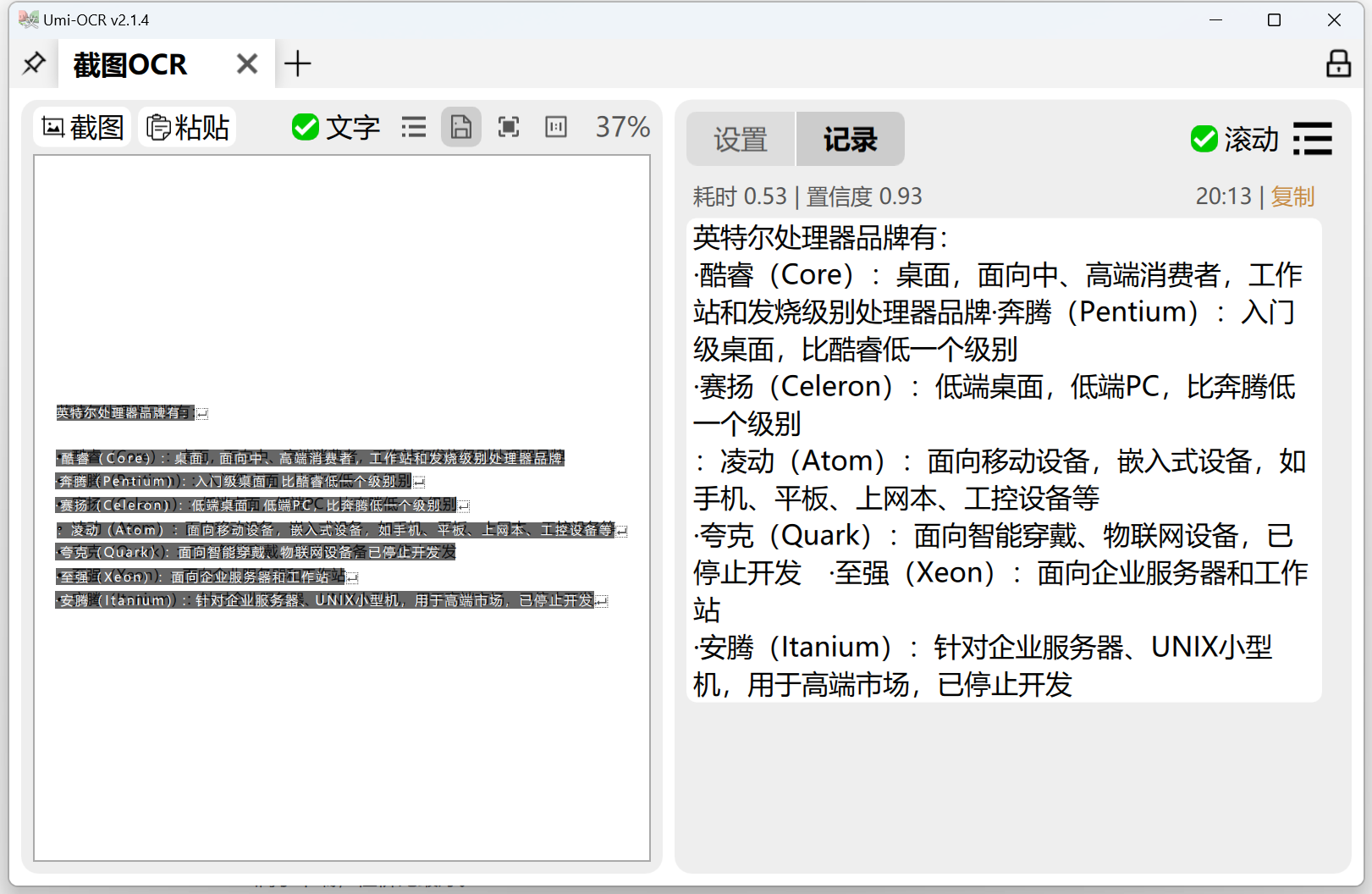
如果觉得识别的文本排版不行,还可以进行文本后处理。
打开【设置】
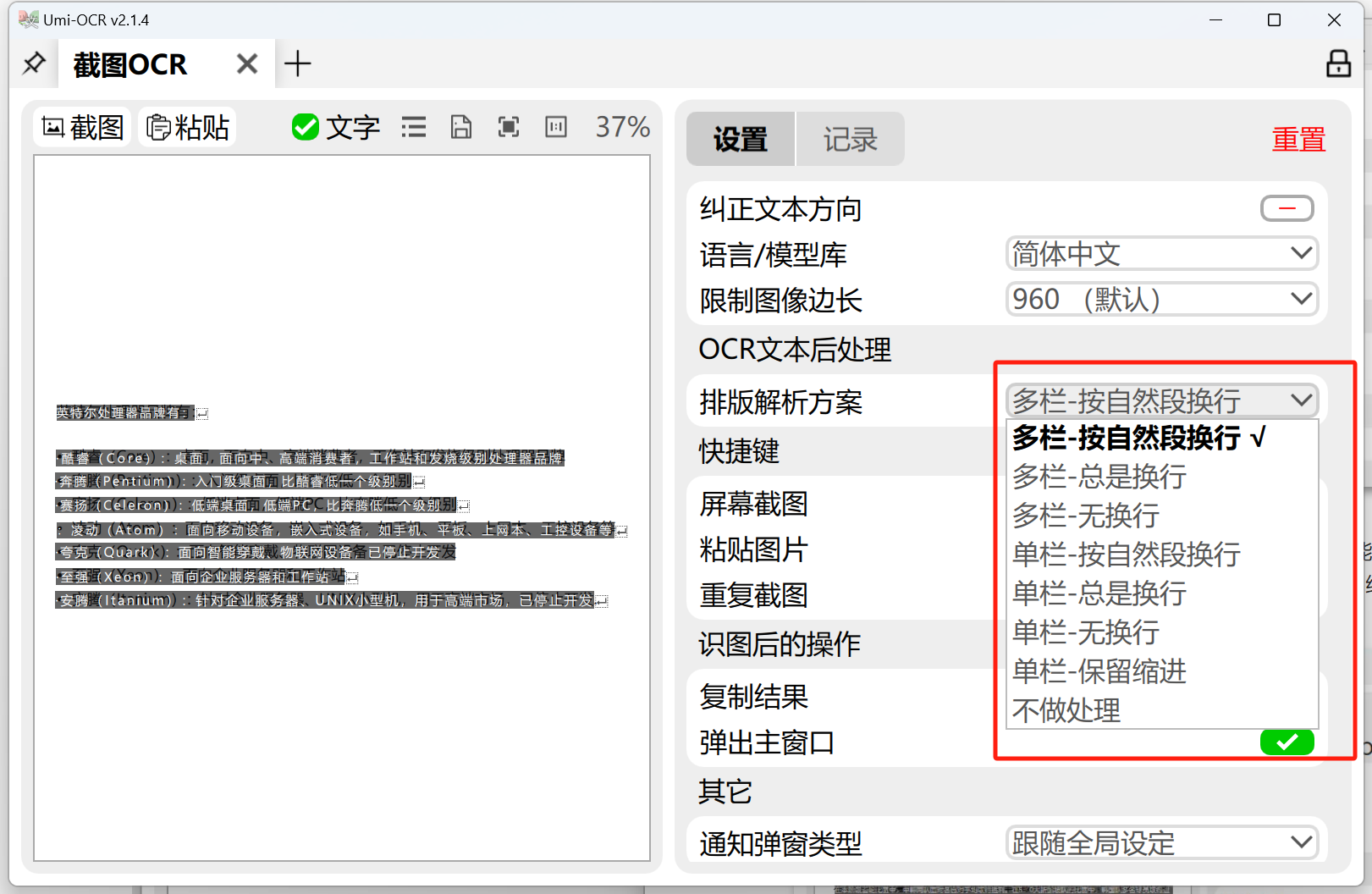
多栏-按自然段换行:适合大部分情景,自动识别多栏布局,按自然段规则进行换行。多栏-总是换行:每段语句都进行换行。多栏-无换行:强制将所有语句合并到同一行。单栏-按自然段换行/总是换行/无换行:与上述类似,不过 不区分多栏布局。单栏-保留缩进:适用于解析代码截图,保留行首缩进和行中空格。不做处理:OCR引擎的原始输出,默认每段语句都进行换行。
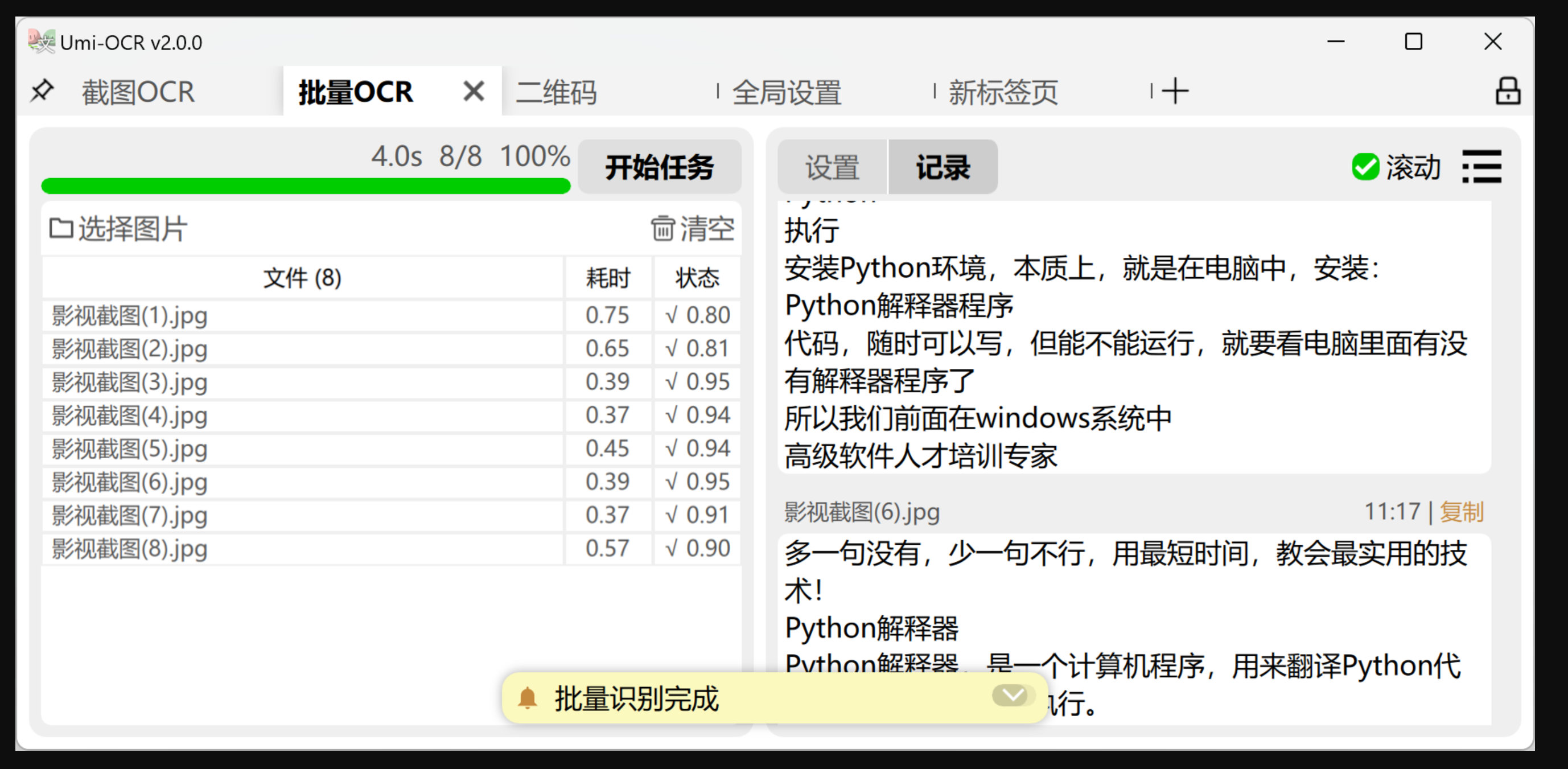
5、批量OCR
批量OCR:这一页用于批量导入本地图片进行识别。
- 支持格式:
jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff。 - 保存识别结果的支持格式:
txt, jsonl, md, csv(Excel)。 - 与截图OCR一样,支持
文本后处理功能,整理OCR文本的排版和顺序。 - 没有数量上限,可一次性导入几百张图片进行任务。
- 支持任务完成后自动关机/待机。
- 如果要识别像素超大的长图或大图,请调整:页面的设置→文字识别→限制图像边长→【调高数值】。
- 拥有特殊功能
忽略区域。
关于 OCR文本后处理 - 忽略区域: 批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。
- 注意,只有处于忽略区域框内部的整个文本块(而不是单个字符)会被忽略。如下图所示,黄色边框的深色矩形是一个忽略区域。那么只有
key_mouse才会被忽略。pubsub_connector.py、pubsub_service.py这两个文本块得以保留。
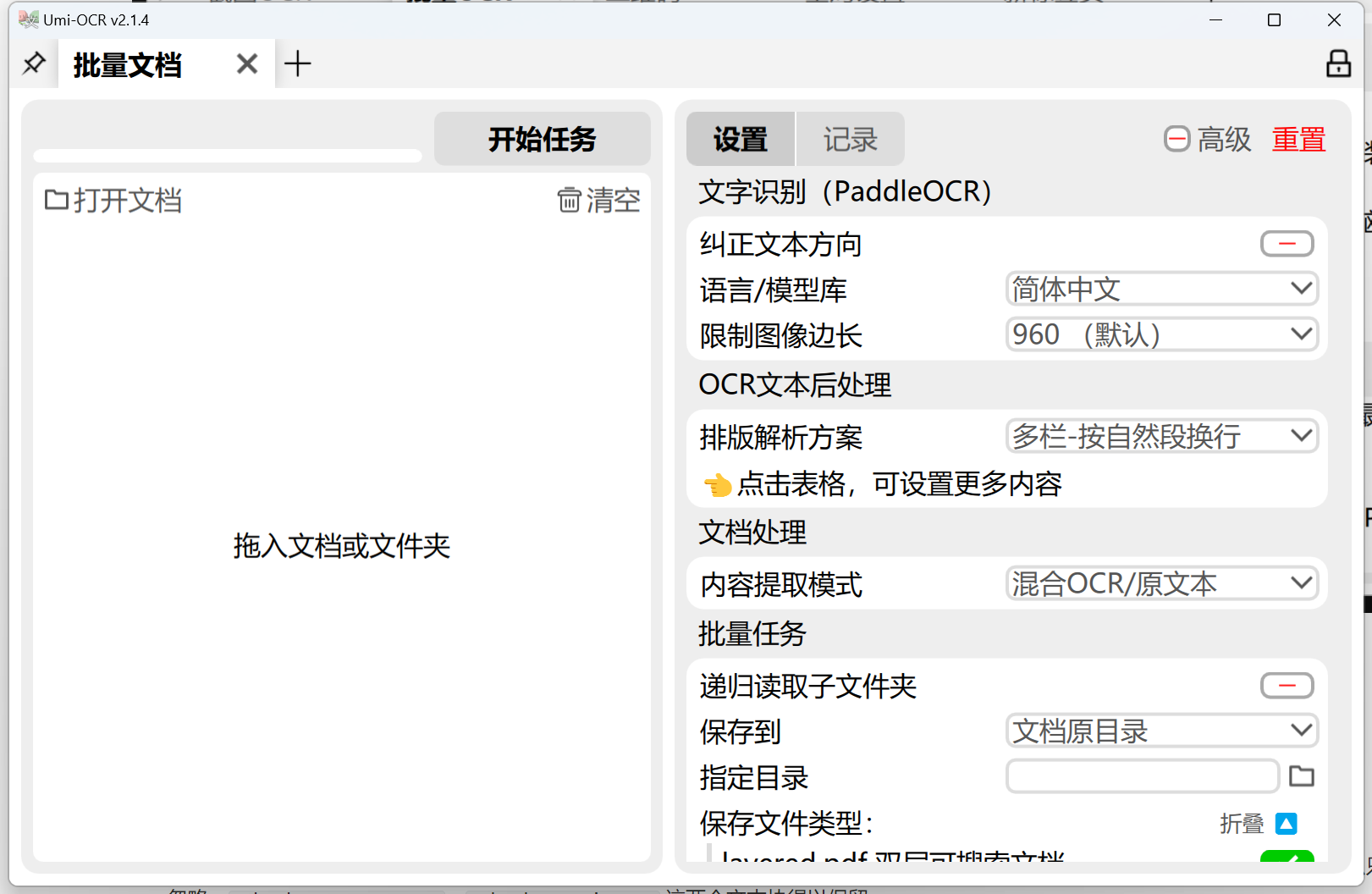
6、文档识别
文档识别:
- 支持格式:
pdf, xps, epub, mobi, fb2, cbz。 - 对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF 。
- 支持设定 忽略区域 ,可用于排除页眉页脚的文字。
- 可设置任务完成后 自动关机/休眠 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









