







知识蒸馏(Knowledge Distillation)是一种模型压缩技术,旨在将复杂模型(教师模型)的知识迁移到更小、更高效的模型(学生模型)中,使其在保持性能的同时降低计算资源需求。
一.概念
1. 核心思想
知识蒸馏使用的是教师—学生模型,其中教师是“知识”的输出者,学生模型是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"教师模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"教师模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"学生模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
教师模型学习能力强,可以将它学到的知识迁移给学习能力相对弱的学生模型,以此来增强学生模型的泛化能力。复杂笨重但是效果好的教师模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的学生小模型。
2.简单流程
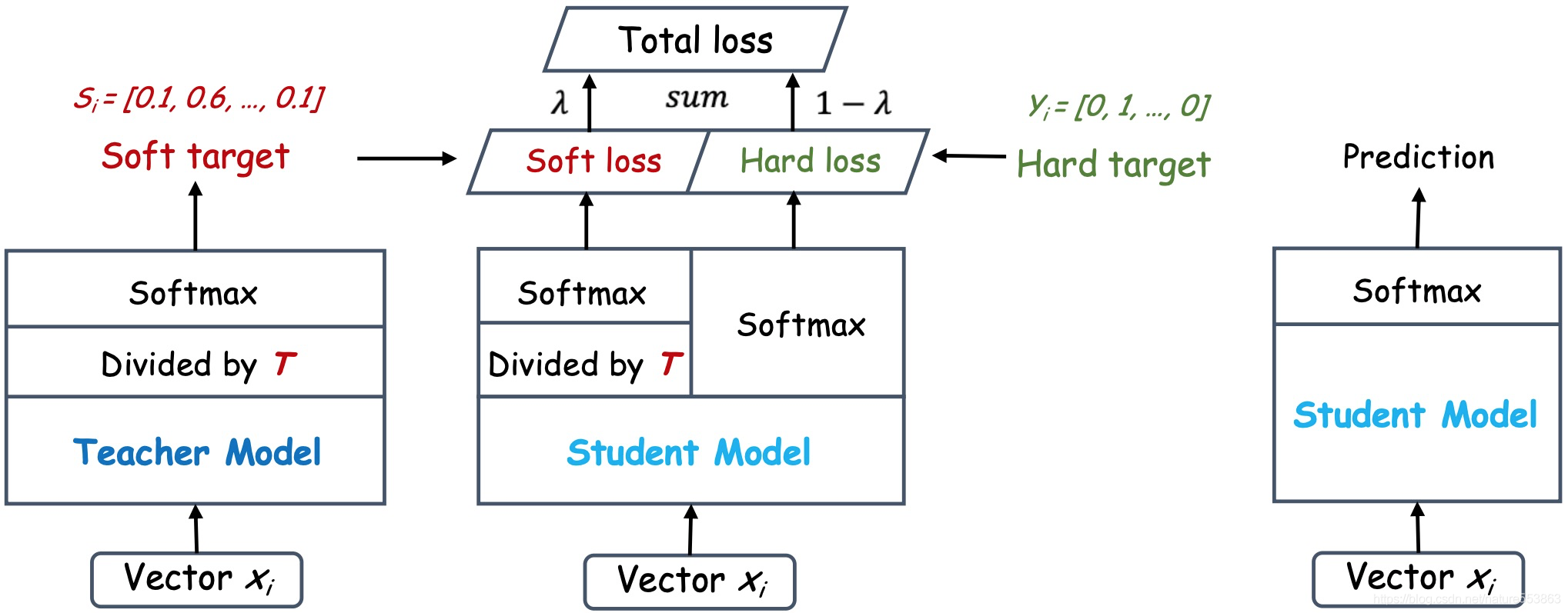
1. 输入与模型结构
- 输入数据:向量 x i x_i xi 同时输入教师模型(Teacher Model)和学生模型(Student Model)。
- 模型角色:
- 教师模型:预训练好的复杂模型,用于生成软标签(Soft Target)。
- 学生模型:待训练的轻量模型,目标是模仿教师的输出。
2. 输出处理(高温Softmax)
- 教师模型输出:
- 原始输出通过高温Softmax(Softmax with
T
T
T)生成软标签(Soft Target),概率分布平滑,例如
[0.7, 0.2, 0.1]。 - 公式:
p i teacher = Softmax ( z i / T ) = e z i / T ∑ j e z j / T p_i^{\text{teacher}} = \text{Softmax}(z_i / T) = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}} piteacher=Softmax(zi/T)=∑jezj/Tezi/T
- 原始输出通过高温Softmax(Softmax with
T
T
T)生成软标签(Soft Target),概率分布平滑,例如
- 学生模型输出:
- 同样使用高温Softmax处理,输出概率分布 p i student p_i^{\text{student}} pistudent。
3. 损失计算
- 软损失(Soft Loss):
- 通过KL散度衡量学生输出与教师软标签的差异:
L soft = T 2 ⋅ KL ( p teacher ∥ p student ) \mathcal{L}_{\text{soft}} = T^2 \cdot \text{KL}(p^{\text{teacher}} \parallel p^{\text{student}}) Lsoft=T2⋅KL(pteacher∥pstudent) - 温度 T T T 平方用于平衡梯度量级。
- 通过KL散度衡量学生输出与教师软标签的差异:
- 硬损失(Hard Loss):
- 学生输出与真实硬标签(Hard Target,如One-hot向量
y
i
=
[
0
,
1
,
.
.
.
,
0
]
y_i = [0, 1, ..., 0]
yi=[0,1,...,0])的交叉熵损失:
L hard = CrossEntropy ( y i , p student ) \mathcal{L}_{\text{hard}} = \text{CrossEntropy}(y_i, p^{\text{student}}) Lhard=CrossEntropy(yi,pstudent)
- 学生输出与真实硬标签(Hard Target,如One-hot向量
y
i
=
[
0
,
1
,
.
.
.
,
0
]
y_i = [0, 1, ..., 0]
yi=[0,1,...,0])的交叉熵损失:
- 总损失(Total Loss):
- 加权求和:
L total = λ L soft + ( 1 − λ ) L hard \mathcal{L}_{\text{total}} = \lambda \mathcal{L}_{\text{soft}} + (1 - \lambda) \mathcal{L}_{\text{hard}} Ltotal=λLsoft+(1−λ)Lhard
其中 λ \lambda λ 是软标签损失的权重(图中未明确数值)。
- 加权求和:
4. 训练过程
- 仅学生模型参与梯度更新,教师模型参数固定。
- 通过最小化
L
total
\mathcal{L}_{\text{total}}
Ltotal,学生模型同时学习:
- 教师模型的类别间关系(软标签)。
- 真实标签的确定性知识(硬标签)。
5.伪代码
-
初始化:
- 设置教师模型 T T T 为评估模式(冻结参数)
- 定义优化器 Optimizer S \text{Optimizer}_S OptimizerS 用于更新 S S S 的参数
-
for e = 1 e = 1 e=1 to E E E do:
-
将数据集 D \mathcal{D} D 划分为批量数据 { B k } k = 1 K \{\mathcal{B}_k\}_{k=1}^{K} {Bk}k=1K, K = ⌈ N / B ⌉ K = \lceil N/B \rceil K=⌈N/B⌉
-
for 每个批量 B k = { ( x i , y i ) } i = 1 B \mathcal{B}_k = \{(x_i, y_i)\}_{i=1}^B Bk={(xi,yi)}i=1B do:
-
教师模型生成软标签:
z T ← T ( x i ) // 教师模型前向传播 \quad \mathbf{z}^T \gets T(x_i) \quad \color{grey}{\text{// 教师模型前向传播}} zT←T(xi)// 教师模型前向传播
p T ← Softmax ( z T / τ ) // 高温Softmax \quad \mathbf{p}^T \gets \text{Softmax}(\mathbf{z}^T / \tau) \quad \color{grey}{\text{// 高温Softmax}} pT←Softmax(zT/τ)// 高温Softmax -
学生模型预测:
z S ← S ( x i ) \quad \mathbf{z}^S \gets S(x_i) zS←S(xi)
p S ← LogSoftmax ( z S / τ ) \quad \mathbf{p}^S \gets \text{LogSoftmax}(\mathbf{z}^S / \tau) pS←LogSoftmax(zS/τ) -
计算联合损失:
L KD ← τ 2 ⋅ KLDivLoss ( p S , p T ) // 蒸馏损失 \quad \mathcal{L}_{\text{KD}} \gets \tau^2 \cdot \text{KLDivLoss}(\mathbf{p}^S, \mathbf{p}^T) \quad \color{grey}{\text{// 蒸馏损失}} LKD←τ2⋅KLDivLoss(pS,pT)// 蒸馏损失
L CE ← CrossEntropy ( z S , y i ) // 学生损失 \quad \mathcal{L}_{\text{CE}} \gets \text{CrossEntropy}(\mathbf{z}^S, y_i) \quad \color{grey}{\text{// 学生损失}} LCE←CrossEntropy(zS,yi)// 学生损失
L ← α L KD + ( 1 − α ) L CE \quad \mathcal{L} \gets \alpha \mathcal{L}_{\text{KD}} + (1-\alpha) \mathcal{L}_{\text{CE}} L←αLKD+(1−α)LCE -
参数更新:
∇ L . backward ( ) // 反向传播 \quad \nabla \mathcal{L}.\text{backward}() \quad \color{grey}{\text{// 反向传播}} ∇L.backward()// 反向传播
Optimizer S . step ( ) \quad \text{Optimizer}_S.\text{step}() OptimizerS.step()
-
-
-
返回 训练完成的学生模型 S ∗ S^* S∗
3. 关键技术
1. 高温Softmax(Temperature Scaling)
- 作用:平滑教师模型的输出概率分布,增强类别间关系的表达能力。
- 原理:
- 标准Softmax输出尖锐的概率分布(如
[0.9, 0.1, 0.0]),丢失类别间相似性信息。 - 高温Softmax通过温度参数
T
T
T 调整分布:
p i = exp ( z i / T ) ∑ j exp ( z j / T ) p_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} pi=∑jexp(zj/T)exp(zi/T)
当 T > 1 T > 1 T>1 时,概率分布更平滑(如[0.7, 0.2, 0.1]),保留“次优类别”的相对重要性。
- 标准Softmax输出尖锐的概率分布(如
- 示例:
- 教师模型对“哈士奇”的原始输出为
[狗:0.6, 狼:0.3, 猫:0.1],高温处理后更清晰地体现“狗与狼的相似性”。
- 教师模型对“哈士奇”的原始输出为
2. 损失函数设计
知识蒸馏通过联合优化两类损失传递知识:
(1) 蒸馏损失(Distillation Loss)
- 目标:使学生模型的输出分布逼近教师模型的高温Softmax分布。
- 公式:
L KD = T 2 ⋅ KL ( p teacher ∥ p student ) \mathcal{L}_{\text{KD}} = T^2 \cdot \text{KL}(p_{\text{teacher}} \parallel p_{\text{student}}) LKD=T2⋅KL(pteacher∥pstudent)- KL散度衡量两个分布的差异, T 2 T^2 T2 用于平衡温度缩放对梯度的影响。
(2) 学生损失(Student Loss)
- 目标:确保学生模型学习真实标签的监督信号。
- 公式:
L CE = − ∑ y true log p student \mathcal{L}_{\text{CE}} = -\sum y_{\text{true}} \log p_{\text{student}} LCE=−∑ytruelogpstudent- 交叉熵损失直接优化学生模型对真实标签的预测。
(3) 总损失
L = α L KD + ( 1 − α ) L CE \mathcal{L} = \alpha \mathcal{L}_{\text{KD}} + (1-\alpha) \mathcal{L}_{\text{CE}} L=αLKD+(1−α)LCE
- 超参数:
- α \alpha α:控制软标签与硬标签的权重(通常取0.5~0.9)。
- T T T:控制知识传递的“清晰度”(常用4~20)。
4. 扩展和变体
3.1. 动态蒸馏(Dynamic Distillation)
- 思想:教师模型和学生模型在训练过程中协同进化,而非固定教师模型。
- 方法:
- 联合训练:教师和学生模型交替更新参数。
- 在线蒸馏:多个学生模型互相学习,或教师模型随训练过程逐步更新。
- 优势:
- 避免教师模型的知识固化。
- 提升学生模型的最终性能(如Deep Mutual Learning)。
3.2. 多教师蒸馏(Multi-Teacher Distillation)
- 思想:集成多个教师模型的知识,增强学生模型的泛化能力。
- 方法:
- 概率平均:将多个教师的输出概率取平均作为软标签。
- 加权融合:根据教师模型的表现动态分配权重。
- 分阶段蒸馏:不同教师负责不同层次的知识迁移。
- 示例:
- 在目标检测任务中,一个教师负责分类,另一个教师负责定位。
3.3. 自蒸馏(Self-Distillation)
- 思想:同一模型内部不同模块或阶段的知识迁移。
- 方法:
- 深度监督:将深层特征蒸馏到浅层(如DenseNet)。
- 时序蒸馏:在训练过程中,用模型早期版本作为教师(如EMA模型)。
- 优势:
- 无需额外教师模型,降低计算成本。
- 提升模型的抗过拟合能力。
3.4. 对抗蒸馏(Adversarial Distillation)
- 思想:引入对抗训练提升学生模型的鲁棒性。
- 方法:
- 生成对抗网络(GAN):生成器伪造输入样本,判别器区分教师与学生的输出。
- 对抗扰动:在输入中添加扰动,使学生模型对对抗样本的预测与教师一致。
- 应用场景:模型需部署在对抗环境下(如人脸识别系统)。
3.5. 数据无关蒸馏(Data-Free Distillation)
- 挑战:原始训练数据不可用时(如隐私保护),如何迁移知识?
- 方法:
- 生成合成数据:利用教师模型生成伪样本(如通过GAN)。
- 特征反演:从教师模型的中间层特征重建输入数据。
- 经典工作:
- DAFL:通过对抗生成网络合成训练数据。
- ZSKD:基于零样本学习的知识蒸馏。
3.6. 量化感知蒸馏(Quantization-Aware Distillation)
- 目标:直接蒸馏到量化后的学生模型(如8位整型网络)。
- 方法:
- 在蒸馏过程中模拟量化误差(如引入量化噪声)。
- 联合优化蒸馏损失和量化损失。
- 优势:避免“先蒸馏后量化”导致性能下降。
3.7. 中间特征对齐(Intermediate Feature Distillation)
- 动机:仅对齐输出层可能丢失教师模型的中间层知识(如纹理、形状等低级特征)。
- 方法:
- 特征匹配:强制学生模型的中间层特征与教师模型的对应层特征相似。
- 损失设计:
L mid = ∥ f teacher − g ( f student ) ∥ 2 2 \mathcal{L}_{\text{mid}} = \| f_{\text{teacher}} - g(f_{\text{student}}) \|_2^2 Lmid=∥fteacher−g(fstudent)∥22
其中 g ( ⋅ ) g(\cdot) g(⋅) 为适配器(如全连接层),用于对齐特征维度差异。
- 经典工作:
- FitNets:让学生模型的中间层直接预测教师模型的中间特征。
- Attention Transfer:对齐教师和学生模型的注意力图。
关键技术的选择策略
| 场景 | 推荐技术 |
|---|---|
| 学生模型容量小 | 高温Softmax( T T T调大)+ 中间特征对齐 |
| 数据不足 | 自蒸馏 + 标签平滑化 |
| 多模态任务 | 中间特征对齐 + 对抗蒸馏 |
| 隐私敏感场景 | 数据无关蒸馏 |
| 需部署到低精度设备 | 量化感知蒸馏 |
5. 应用场景
- 模型压缩:将BERT、ResNet等大模型压缩为移动端可用的小模型。
- 提升小模型性能:学生模型在参数量减少的情况下接近教师精度。
- 隐私保护:无需原始数据,通过生成样本进行蒸馏(数据无关蒸馏)。zhish
6. 优势与挑战
- 优势:
- 学生模型高效且易于部署。
- Soft Targets提供正则化,增强泛化能力。
- 挑战:
- 教师与学生结构差异可能影响效果。
- 超参数( T T T、 α \alpha α)调优复杂。
- 依赖教师模型的质量。
二.学习中的困惑
1.高温Softmax与原本的softmax的区别在哪里,想出这个理念的人是为什么能想到?
高温Softmax与标准Softmax的核心区别在于概率分布的平滑性控制,其设计灵感来源于对模型“隐含知识”的挖掘需求。以下是详细分析:
1. 公式对比
- 标准Softmax:
p i = exp ( z i ) ∑ j exp ( z j ) p_i = \frac{\exp(z_i)}{\sum_j \exp(z_j)} pi=∑jexp(zj)exp(zi)
输出概率分布尖锐,最大概率值主导(如[0.9, 0.1, 0.0])。 - 高温Softmax:
p i = exp ( z i / T ) ∑ j exp ( z j / T ) p_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} pi=∑jexp(zj/T)exp(zi/T)
引入温度参数 T T T( T > 1 T > 1 T>1),使概率分布更平滑(如[0.7, 0.2, 0.1])。
温度 T T T 的作用 - T → 0 T \to 0 T→0:退化为One-hot向量(最大概率为1,其他为0)。
- T = 1 T = 1 T=1:等价于标准Softmax。
- T → + ∞ T \to +\infty T→+∞:所有类别概率趋近于均匀分布(如三分类时为[1/3, 1/3, 1/3])。
2. 为何有效?
- 信息熵提升:高温使概率分布的信息熵增大(更“不确定”),传递更多隐含知识(如类别间关系)。
- 正则化效果:平滑的软标签可防止学生模型对硬标签过拟合,提升泛化能力。
- 梯度稳定性:高温降低了正确类别的梯度幅值,缓解了学生模型训练初期的不稳定性。
3、实际应用技巧
-
训练阶段:
- 教师和学生使用相同的 T T T(如 T = 4 T=4 T=4)。
- 总损失 = α ⋅ KL散度损失 + ( 1 − α ) ⋅ 交叉熵损失 \alpha \cdot \text{KL散度损失} + (1-\alpha) \cdot \text{交叉熵损失} α⋅KL散度损失+(1−α)⋅交叉熵损失。
-
推理阶段:
- 学生模型恢复 T = 1 T=1 T=1,确保输出概率的实用性。
-
调参建议:
- 学生模型容量越小, T T T 需越大(需更平滑的监督信号)。
- 若教师模型过拟合,降低 α \alpha α 以增强真实标签的作用。
2.软标签和硬标签的区别
1. 硬标签(Hard Labels)
- 定义:
硬标签是确定性的分类标签,通常以 One-Hot 编码 形式表示。每个样本仅属于一个类别,标签中仅正确类别的值为1,其他为0。 - 示例:
例如,在猫、狗、鸟的三分类任务中:- 一张猫的图片的硬标签为
[1, 0, 0] - 一张狗的图片的硬标签为
[0, 1, 0]
- 一张猫的图片的硬标签为
- 特点:
- 信息单一:只反映样本的最终类别,不包含类别间的关系(如“猫和狗可能比猫和鸟更相似”)。
- 训练目标:模型需最大化正确类别的概率(直接优化交叉熵损失)。
- 应用场景:传统的监督学习任务(如ImageNet分类)。
- 优点:
- 标注简单,数据易获取。
- 训练目标明确,适合快速收敛。
- 缺点:
- 忽略类别间潜在的相似性(如“猫和狗的混淆性”)。
- 可能导致模型过拟合,尤其是数据量不足时。
2. 软标签(Soft Labels)
- 定义:
软标签是概率分布形式的标签,表示样本属于每个类别的概率(所有概率之和为1)。通常由模型生成(如知识蒸馏中的教师模型),或通过人工标注的概率分布得到。 - 示例:
在同样的三分类任务中:- 一张猫的图片的软标签可能是
[0.8, 0.15, 0.05](模型认为它更像猫,但和狗有一定相似性)。 - 知识蒸馏中教师模型输出的概率分布即软标签(如
[0.7, 0.2, 0.1])。
- 一张猫的图片的软标签可能是
- 特点:
- 信息丰富:包含类别间的相对关系(如“猫和狗的相似性高于猫和鸟”)。
- 训练目标:模型需匹配软标签的概率分布(如KL散度损失)。
- 应用场景:知识蒸馏、半监督学习、标签噪声处理。
- 优点:
- 传递更多隐含知识(如类别相似性)。
- 提供正则化效果,提升模型泛化性。
- 缺点:
- 依赖生成软标签的模型质量(如教师模型的性能)。
- 计算复杂度略高(需处理概率分布)。
3.区别
| 特征 | 硬标签 | 软标签 |
|---|---|---|
| 信息类型 | 确定性(非0即1) | 概率性(0~1的连续值) |
| 生成方式 | 人工标注或直接分类结果 | 模型预测(如教师模型)或人工概率标注 |
| 信息量 | 低(仅正确类别信息) | 高(包含类别间关系) |
| 训练目标 | 交叉熵损失(最大化正确类概率) | KL散度损失(匹配概率分布) |
| 典型应用 | 传统监督学习 | 知识蒸馏、标签平滑化 |
4.为什么需要软标签?
(1)知识蒸馏中的软标签
在知识蒸馏中,软标签是教师模型输出的概率分布,通过以下方式提升学生模型性能:
-
传递隐含知识:例如,教师模型对“哈士奇”图片可能给出
[0.6(狗), 0.3(狼), 0.1(猫)],表明“狗和狼的相似性”。 -
缓解过拟合:软标签的平滑性使学生模型避免对硬标签的绝对信任。
(2)标签平滑化(Label Smoothing)
一种人工生成软标签的方法,将硬标签的One-Hot分布调整为:
y
soft
=
(
1
−
ϵ
)
⋅
y
hard
+
ϵ
⋅
1
N
y_{\text{soft}} = (1-\epsilon) \cdot y_{\text{hard}} + \epsilon \cdot \frac{1}{N}
ysoft=(1−ϵ)⋅yhard+ϵ⋅N1
其中
ϵ
\epsilon
ϵ是平滑系数,
N
N
N是类别数。例如,三分类任务中:
原始硬标签 [1, 0, 0] → 软标签 [0.9, 0.05, 0.05](设
ϵ
=
0.1
\epsilon=0.1
ϵ=0.1)。
3:教师模型和学生模型必须是同类型吗?参数迁移是否困难?
教师模型和学生模型不需要是同类型,但结构差异过大会增加知识迁移的复杂度。以下是关键分析:
1. 模型类型差异的影响
| 场景 | 可行性 | 挑战与解决方案 |
|---|---|---|
| 同类型模型 | 高 | 直接对齐输出层或中间层,迁移效率高(如ResNet-50→ResNet-18)。 |
| 不同类型模型 | 中 | 需设计适配器或调整损失函数(如BERT→BiLSTM、CNN→Transformer)。 |
| 极简学生模型 | 低 | 学生容量过小可能无法学习教师知识,需增大温度 ( T ) 或简化任务(如仅分类不检测)。 |
2. 参数迁移的应对策略
- 适配器网络(Adapter):
当学生和教师模型的中间层维度不匹配时,插入轻量适配层(如1x1卷积或全连接层)对齐特征维度。# 示例:适配器调整学生特征维度 class Adapter(nn.Module): def __init__(self, in_dim, out_dim): super().__init__() self.fc = nn.Linear(in_dim, out_dim) def forward(self, x): return self.fc(x) # 学生中间层特征通过适配器对齐教师维度 student_feat = adapter(student_model.intermediate_feat) loss = MSE_loss(teacher_feat, student_feat) - 损失函数设计:
若输出层结构差异大(如教师多任务、学生单任务),可仅迁移部分知识(如分类概率,忽略检测框)。 - 渐进式蒸馏:
分阶段迁移知识(如先迁移低级特征,再迁移高级语义)。
4.知识蒸馏如何解决数据不足和隐私问题?
知识蒸馏通过软标签生成和无数据蒸馏技术应对数据不足与隐私挑战。
1. 解决数据不足
-
软标签作为数据增强:
教师模型生成的软标签包含更多信息(如类别间相似性),相当于扩充了监督信号。- 示例:100张真实图片 + 教师生成的软标签 → 等效于500张“增强数据”。
-
半监督蒸馏:
结合少量标注数据和大量无标注数据:- 用标注数据训练教师模型。
- 用教师对无标注数据生成软标签。
- 学生模型同时学习标注数据(硬标签)和无标注数据(软标签)。
2. 应对隐私敏感场景
-
数据无关蒸馏(Data-Free Distillation):
无需原始数据,直接通过教师模型生成合成数据:-
方法:
- 对抗生成网络(GAN):训练生成器 ( G ) 产生逼真样本,使教师模型 ( T ) 对 ( G(z) ) 的输出置信度最大化。
min G max T E z ∼ N [ Entropy ( T ( G ( z ) ) ) ] \min_G \max_T \mathbb{E}_{z \sim \mathcal{N}} [\text{Entropy}(T(G(z)))] GminTmaxEz∼N[Entropy(T(G(z)))] - 特征反演(Feature Inversion):从教师模型的中间层特征重建输入数据。
- 对抗生成网络(GAN):训练生成器 ( G ) 产生逼真样本,使教师模型 ( T ) 对 ( G(z) ) 的输出置信度最大化。
-
经典工作:
- DAFL (Data-Free Learning, CVPR 2020)
- ZSKD (Zero-Shot Knowledge Distillation, NeurIPS 2021)
-
-
联邦蒸馏(Federated Distillation):
在分布式设备上训练,原始数据不离开本地:- 各设备本地训练教师模型。
- 上传教师模型的输出概率(软标签)至中心服务器。
- 中心服务器聚合软标签训练学生模型。
5、模型设计者的关键洞见
- 软标签的价值:发现硬标签(One-hot)丢失了模型学习到的数据内在结构信息。
- 知识迁移的本质:学生模型的目标不是复现教师模型的绝对正确性,而是学习其决策边界和数据分布的“直觉”。
- 温度参数的物理类比:借鉴统计力学中“温度控制粒子运动混乱度”的思想,通过调节 T T T 控制知识传递的“清晰度”。
三. 知识蒸馏深入学习路径
- 选定一个简单任务,从基础蒸馏开始(如 MNIST 分类),用 高温Softmax + KL损失 理解软标签迁移过程。对比学生模型仅用硬标签和软硬标签联合训练的效果差异。
- 实现中间特征对齐(如 FitNets),在 CIFAR-10 上对齐教师和学生的中间层特征(如 ResNet-34 → 轻量CNN),观察特征分布变化。
- 尝试无数据蒸馏(如 GAN 生成数据),在无原始数据的情况下,仅用教师模型生成合成样本训练学生模型。
- 挑战复杂任务(如 BERT → TinyBERT),理解大模型压缩中的注意力迁移和层匹配技巧。
- 实验调参,测试不同温度 TT 和损失权重 αα 的影响,并用可视化工具(如 TensorBoard)分析收敛曲线。
- 部署优化,将蒸馏后的模型量化(如 INT8)并部署到边缘设备(如 Jetson Nano),测试推理速度提升效果。
关键建议:
- 每步配合一篇经典论文(如 Hinton 2015、FitNets 2015、TinyBERT)。
- 使用 PyTorch 或 Hugging Face 快速实验,并复现 Kaggle 相关比赛方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









