







 本文档介绍了基于C语言的语法分析器的实现,主要采用自顶向下的预测分析技术,详细阐述了预测分析法的原理和步骤,包括LL(1)文法的检查、预测分析表的构造以及错误处理机制。同时,还讨论了C语言文法设计,从函数定义到各种语句声明的文法结构。
本文档介绍了基于C语言的语法分析器的实现,主要采用自顶向下的预测分析技术,详细阐述了预测分析法的原理和步骤,包括LL(1)文法的检查、预测分析表的构造以及错误处理机制。同时,还讨论了C语言文法设计,从函数定义到各种语句声明的文法结构。
一. 总体实现思想
我采用自顶向下的预测分析技术来实现,其基本方法如下:
从文法开始符号出发,在每一步推导过程中根据当前句型的最左非终结符A和当前输入符号a,选择正确的A-产生式。为保证分析的确定性,选出的候选式必须是唯一的。具体的非递归的预测语法分析结构如下所示:
非递归的预测分析不需要为每个非终结符编写递归下降过程,而是根据预测分析表构造一个自动机,也叫表驱动的预测分析
表驱动的预测分析法的算法
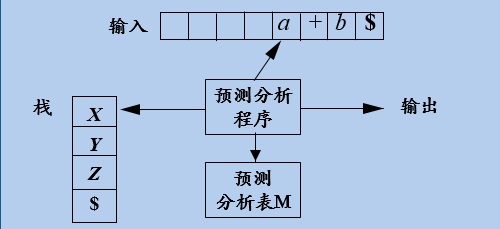
3.1输入:一个串w和文法G的分析表 M
3.2输出:如果w在L(G )中,输出w的最左推导;否则给出错误指示
3.3方法:最初,语法分析器的格局如下:输入缓冲区中是w ,G的开始符号位于栈顶,其下面是 。下面的程序使用预测分析表M生成了处理这个输入的预测分析过程
设置ip使它指向w的第一个符号,其中ip 是输入指针;
令X=栈顶符号;
while ( X ≠ $ ){ / * 栈非空 */
if ( X 等于ip所指向的符号a) 执行栈的弹出操作,将ip向前移动一个位置;
else if ( X是一个终结符号) error ( ) ;
else if ( M[X,a]是一个报错条目) error ( ) ;
else if ( M[X,a] = X →Y1Y2 … Yk ){
输出产生式 X →Y1Y2 … Yk ;
弹出栈顶符号;
将Yk,Yk-1 …,Yi 压入栈中,其中Y1位于栈顶。
}
令X=栈顶符号
}
4.非递归的预测分析法主控程序规模较小,需载入分析表(表较小),直观性较差,分析时间大约正比于待分析程序的长度,但是自动生成较容易
5. 预测分析法的实现步骤
1)构造文法
2)改造文法:消除二义性、消除左递归、消除回溯
3)求每个变量的FIRST集和FOLLOW集,从而求得每个
候选式的SELECT集
4)检查是不是 LL(1) 文法。若是,构造预测分析表
5)对于递归的预测分析,根据预测分析表为每一个非终结
符编写一个过程;对于非递归的预测分析,实现表驱动
的预测分析算法,我们采用的是后面一种
6.预测分析的错误处理
6.1错误检测:
栈顶的终结符和当前输入符号不匹配、
栈顶非终结符与当前输入符号在预测分析表对应项中的信息为空
6.2恐慌模式
6.2.1忽略输入中的一些符号,直到输入中出现由设计者选定的同步词法单元(synchronizing token)集合中的某个词法单元
1)其效果依赖于同步集合的选取。集合的选取应该使得语法分 析器能从实际遇到的错误中快速恢复。例如可以把FOLLOW(A)中的所有终结符放入非终结符A的同步记号集合
6.2.2如果终结符在栈顶而不能匹配,一个简单的办法就是弹出此终结符
6.2.1分析表的使用方法
如果M[A,a]是空,表示检测到错误,根据恐慌模式,忽略输入号a
如果M[A,a]是synch,则弹出栈顶的非终结符A,试图继续分析后面的语法成分
如果栈顶的终结符和输入符号不匹配,则弹出栈顶的终结符
二. C语言文法设计
- c语言基本程序主要是由函数定义组成,故定义文法为:
program->function_definition program'
program'->function_definition program'|$ //c语言的程序构造- 而函数定义又包括了类型定义、函数声明、复合声明,故文法定义为
function_definition->type_specifier declarator_func compound_statement
type_specifier->VOID|CHAR|INT|FLOAT //函数定义- 函数声明又包含函数名字和参数,故文法所以定义为
declarator_func->ID dec' //declarator_func函数声明
declarator->ID dec
dec->[ DIGIT ]|$
dec'->( declarator'|$
declarator'->parameter_list )|)
param 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









