







top命令查看内存占用情况:

RES: 进程实际使用的内存大小;
%MEM:进程使用内存占总内存的百分比;
free -m命令查看内存占用情况:(其中-m的是用MB来显示输出的内容)

Mem: 内存的使用信息
Swap: 交换空间的使用信息
total : 系统总的物理内存大小
used: 系统已使用物理内存大小
free: 系统还剩余的物理内存大小
shared: 被共享使用的物理内存大小
buff/cache: buffers/cache(缓冲区)使用的物理内存大小
Buffer: Buffer Cache缓存磁盘blocks以优化block I/O;
Buffer Cache是针对磁盘块的缓存,缓冲的这一部分内存数据最终是要写入到磁盘中;
缓冲的数据不是实时写入到磁盘的,防止数据丢失可以在计算机断电前多执行几次sync
命令;
cache: Page Cache缓存文件内容以优化文件I/O;
Page Cache是针对文件系统的缓存,从磁盘读取的内容会写入到这里,因此应用程序读
取时速度会非常快。比如grep等命令,第一次查找时会慢很多,后面再重复执行就会快
很多。
buffers&cached的区别:参考资料:https://www.cnblogs.com/zengkefu/p/5589833.html
available:从应用程序角度来看,还可以被 应用程序 使用的物理内存大小;
total = used + free + buff/cache;
buff/cache = buffers + cache;
available = free + buff/cache - 不可释放部分;
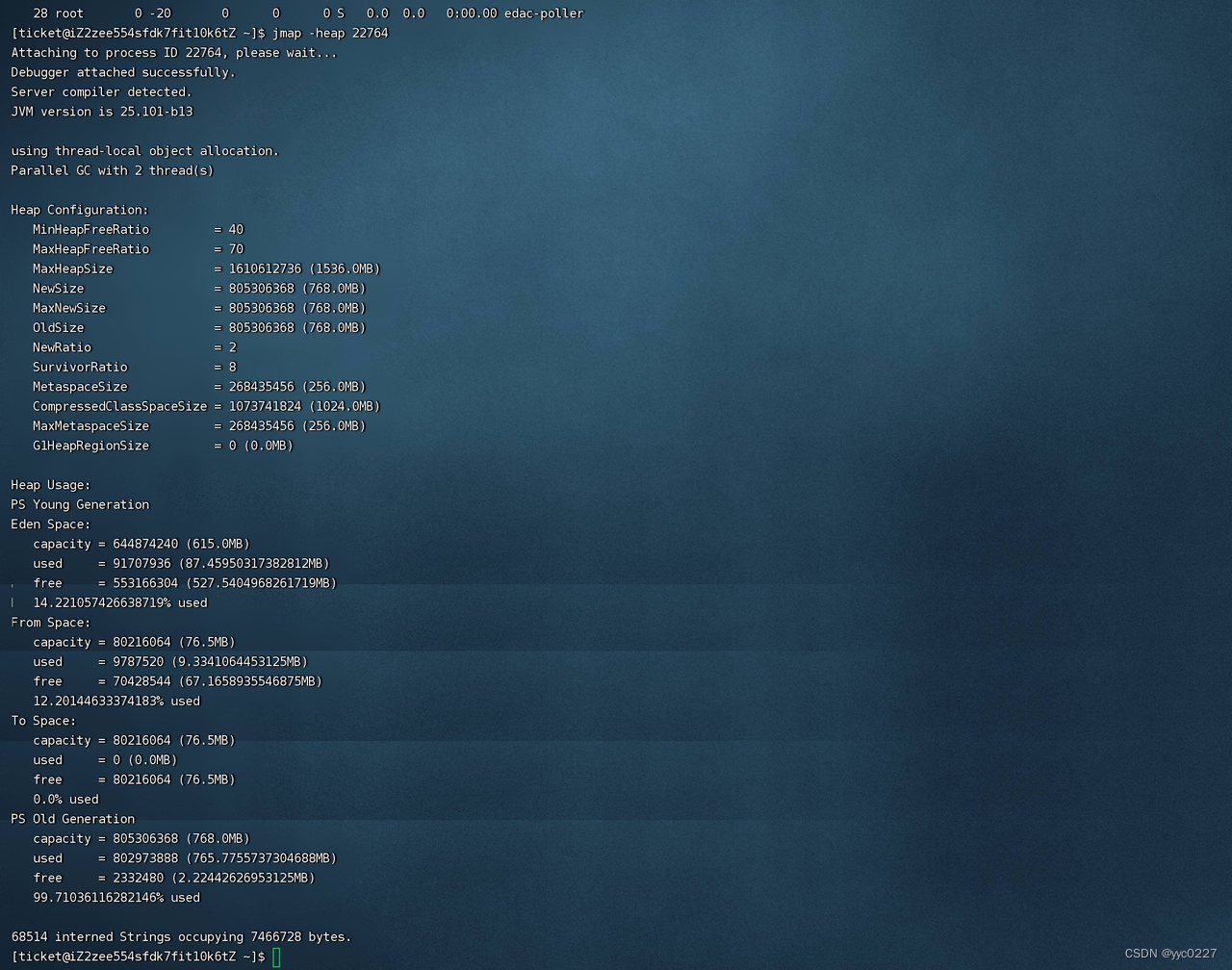
jmap -heap 命令查看JVM内存分配信息:
本机内存跟踪(NMT):
默认情况下,NMT处于关闭状态,但我们可以使它查看其观测结果的摘要或详细视图。
启用本地内存跟踪:-XX:NativeMemoryTracking = off | summary | detail
off:关闭内存跟踪;
summary:仅显示JVM子系统(如:Java heap\class\code\thread等)的内存使用情况;
detail:除了显示JVM子系统内存使用情况外,还展示单独的虚拟内存区域&提交内存区域等使用 情况;
示例:$ java -XX:NativeMemoryTracking=summary -Xms300m -Xmx300m -XX:+UseG1GC -jar app.jar
使用G1作为GC算法,在分配300 MB堆空间的同时启用NMT;
启用NMT后,我们可以随时使用 jcmd 命令获取本机内存信息:
jcmd <pid> VM.native_memory
$ java -Xms1536m -Xmx1536m -Xmn768m -XX:SurvivorRatio=8 -XX:-UseAdaptiveSizePolicy -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:-OmitStackTraceInFastThrow -XX:NativeMemoryTracking=summary -Djasypt.encryptor.password=$JASYPT_PASSWORD -jar $SERVICE_NAME.jar --spring.profiles.active=$ACTIVE_PROFILE
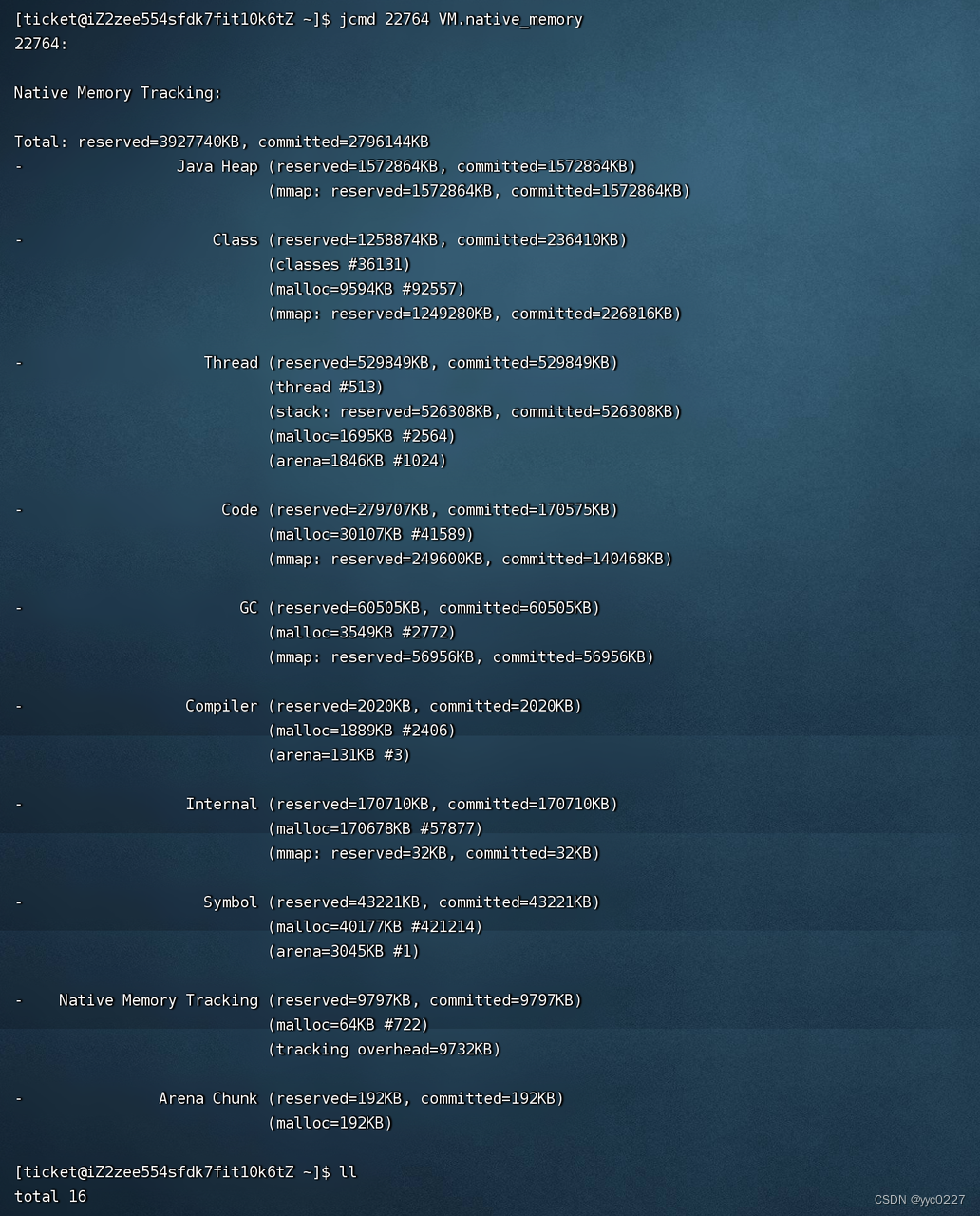
整个JVM内存主要包含Java Heap、Class、Thread、Code、GC、Compiler、Internal、Symbol、Native Memory Tracking、Arena Chunk这几部分;
reserved:保留内存大小,表示应用可用的内存大小;
committed:提交内存大小,表示应用正在使用的内存大小;
Java Heap:表示JVM堆内存;
Class:表示已加载类的类元数据(元空间);
Thread:表示线程栈;
线程堆栈大小取决于平台,但是在大多数现代的64位操作系统中,大约为1 MB。
此大小也可通过【-Xss】JVM参数进行配置;
当对线程数没有限制时,分配给堆栈的总内存实际上是不受限制的。
还值得一提的是,JVM本身需要一些线程来执行其内部操作,例如:GC或即时编译。
Code:表示代码缓存;
为了在不同平台上运行JVM字节码,需要将其转换为机器指令。
在执行程序时,JIT编译器负责此编译;
JVM将字节码编译为汇编指令时,会将这些指令存储在称为【代码缓存】的特殊非堆数据 区域中 。
可以像JVM中的其他数据区域一样管理代码缓存。
可通过JVM参数-XX:InitialCodeCacheSize 和 -XX:ReservedCodeCacheSize 配置代码
缓存中的初始和最大可能大小。
GC:表示用于帮助GC使用的内存;
Compiler:表示JIT编译器Compiler生成code时占用的内存;
Internal:表示JVM内部命令行解析、JVMTI(JVM Tool Interface)、PerfData等占用的内存;
可用JVM参数-XX:MaxDirectMemorySize限制Direct Buffer;
Symbol:表示字符串&常量池等占用的内存;
JVM将生成的字符串存储在特殊的本机固定大小的哈希表中;
该哈希表称为String Table,也称为String Pool;
可以通过JVM参数-XX:StringTableSize来配置表的大小;
除了字符串表外,还有另一个本机数据区域,称为运行时常量池。
JVM使用运行时常量池存储必须在运行时解析的常量,例如编译时数字文字,方法和
字段引用等;
Native Memory Tracking:本地内存跟踪使用占用内存;
Arena Chunk:JVM分配的内存块;
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
| Jcmd NMT 选项 | 说明 |
| summary | 打印按类别汇总的摘要信息 |
| detail |
|
| baseline | 创建一个新的内存使用状况的快照,用以进行比较 |
| summary.diff | 根据上一个 baseline 基线打印新的 summary 对比报告 |
| detail.diff | 根据上一个 baseline 基线打印新的 detail 对比报告 |
| shutdown | 停止NMT |
1)NMT 默认打印的报告是 KB 来进行呈现的,为了满足我们不同的需求,我们可以使用 scale=MB | GB 来更加直观的打印数据。
2)创建 baseline 之后使用 diff 功能可以很直观地对比出两次 NMT 数据之间的差距。
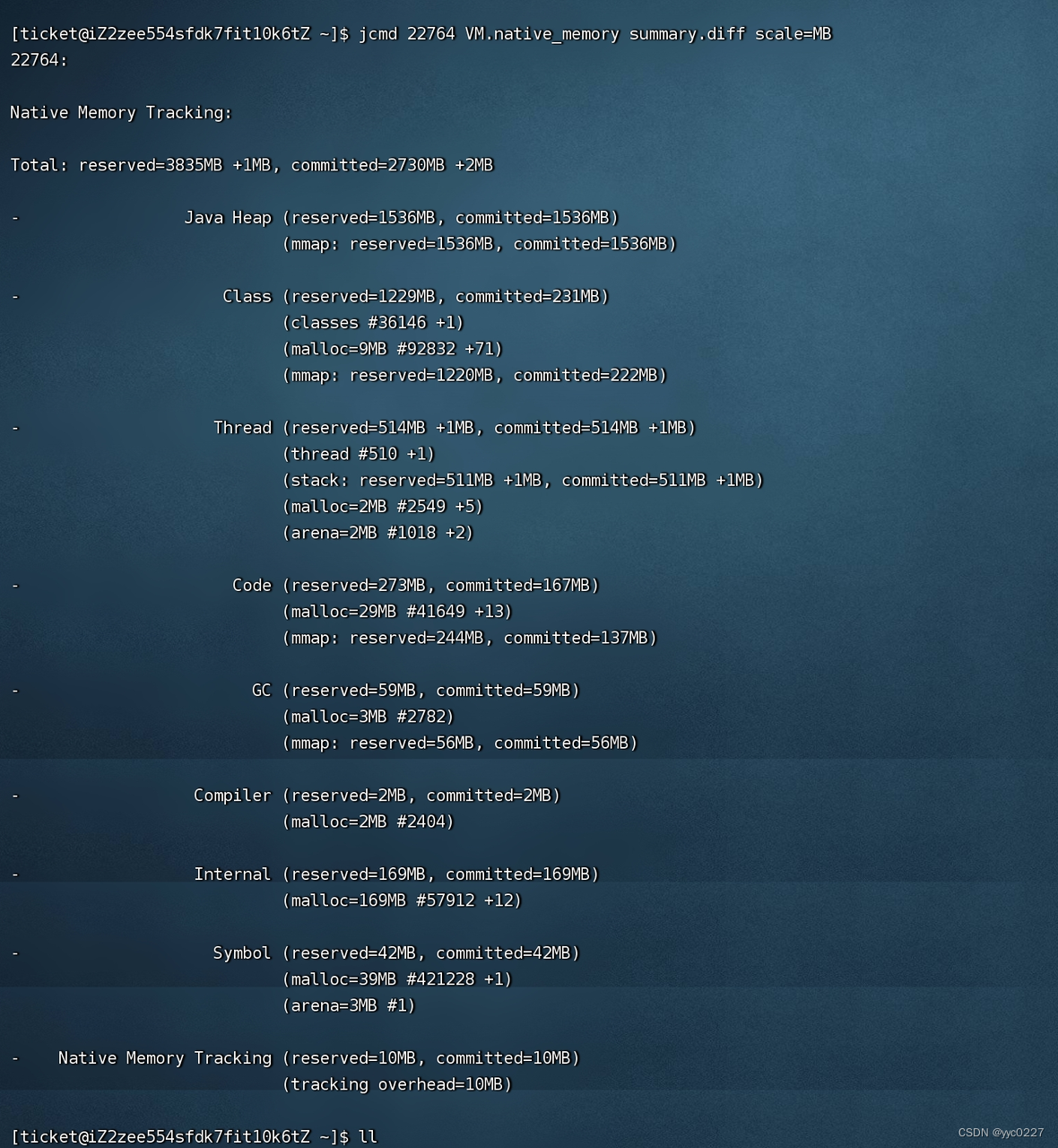
NMT数据对比报告查看:
先创建内存状态快照基线:
jcmd <pid> VM.native_memory baseline
以此时间点的内存状态快照为基准进行对比;
基线创建之后,可查看此时间点到当前时间点的内存变化情况,从而可分析内存持续增长的原因:
jcmd <pid> VM.native_memory summary.diff scale=MB
参考资料:
Linux下free命令详解系列一:https://blog.csdn.net/lybxttj/article/details/105570359
JVM 堆外内存查看方法:https://blog.csdn.net/Andrew_Chenwq/article/details/133933478
JVM实际内存占用超过Xmx的原因,设置Xmx的技巧:https://blog.csdn.net/begefefsef/article/details/126411842
史上最全的JVM配置参数大全:https://blog.csdn.net/weixin_41883161/article/details/129557331
Native Memory Tracking 详解-基础介绍:https://blog.csdn.net/2301_76434200/article/details/136205530
聊聊jvm的CompressedClassSpace:https://blog.csdn.net/li123128/article/details/88928392















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









