






注:本篇文章重点讨论关于MapReduce分布式计算模型的大致信息,讲解在In2telliJ IDEA里创建项目的代码,而对于In2telliJ IDEA社区版的下载,HADOOP以及JDK的环境配置不做过多赘述,详细请参考其他相关博文。
目录
2.1修改pom.xml文件,添加以下部分代码;如果报红,则如下图设置:
2.2.在IDEA左侧的project栏下的Hadoop-src-main-java路径右键创建一个包,命名为com.hadoop.mapreduce.wordcount
2.3在项目名称\src\main\resources路径下添加一个文件(点击resource,右键-new-file),命名为log4j.properties,并添加以下代码
2.4在com.hadoop.mapreduce.wordcount包里,右键创建一个WordCountMap类
一、MapReduce简介
MapReduce是Google提出的一个编程模型,用于大规模数据集(大于1TB)的并行运算。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。MapReduce将复杂的并行计算过程高度抽象为了两个函数:Map和Reduce。
- Map函数:负责数据的拆分和映射。它将输入数据拆分成多个键值对(key-value pairs),并对每个键值对执行相同的操作,生成一系列的中间键值对。
- Reduce函数:负责数据的规约和合并。它将Map函数输出的中间键值对中具有相同键的所有值进行归约操作,生成最终的输出结果。
1.MapReduce工作原理
MapReduce的工作流程可以分为以下几个步骤:
- 数据输入:MapReduce框架从分布式文件系统中读取数据,并将其切分成多个数据块,每个数据块对应一个Map任务。
- Map阶段:每个Map任务读取一个数据块,并将数据块中的记录转换为键值对。然后,Map函数对每个键值对执行计算,生成一系列的中间键值对,并将它们写入本地磁盘。
- Shuffle阶段:MapReduce框架将Map阶段输出的中间键值对按照键进行排序和分组,并将具有相同键的所有值发送到同一个Reduce任务。
- Reduce阶段:Reduce任务从Shuffle阶段接收具有相同键的所有值,并对它们执行归约操作,生成最终的输出结果。
- 数据输出:Reduce任务将输出结果写入分布式文件系统或其他存储系统。
二、代码项目实训
1.打开In2telliJ IDEA 创建项目
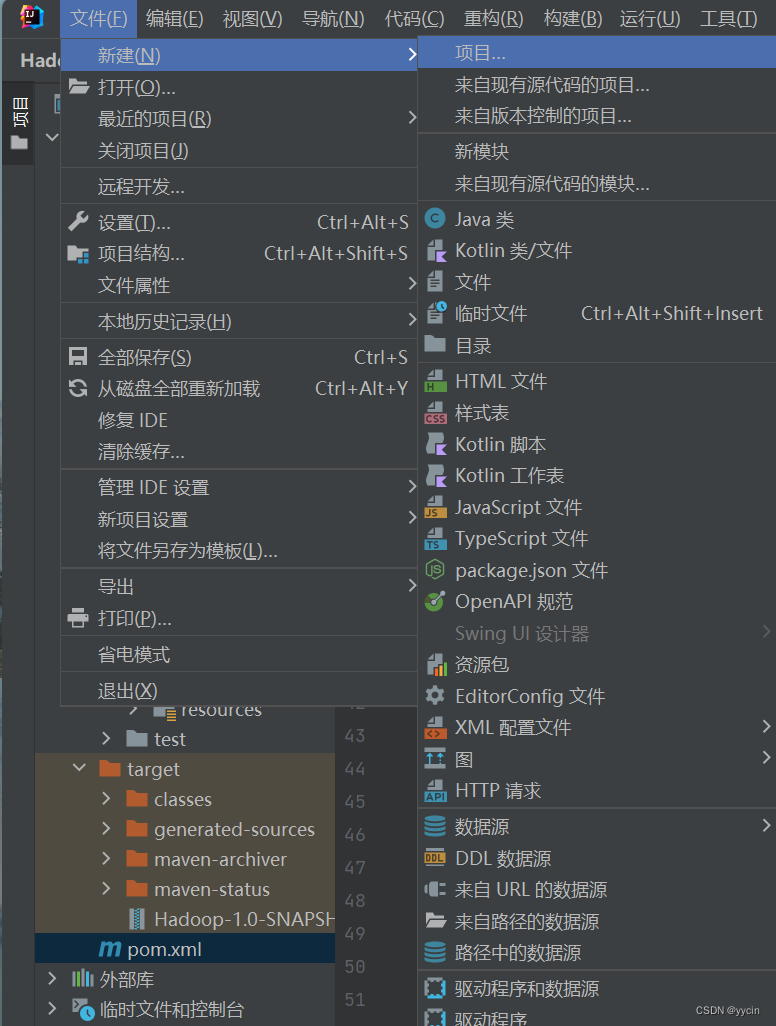
在创建新项目时因In2telliJ IDEA版本的不同,在新建项目的界面也会有所不同,但我们的构建系统是Maven的,语言是Java,有的是在”生成器“那一栏出现”Maven“的选项可以选择。JDK一般系统固定选好的。
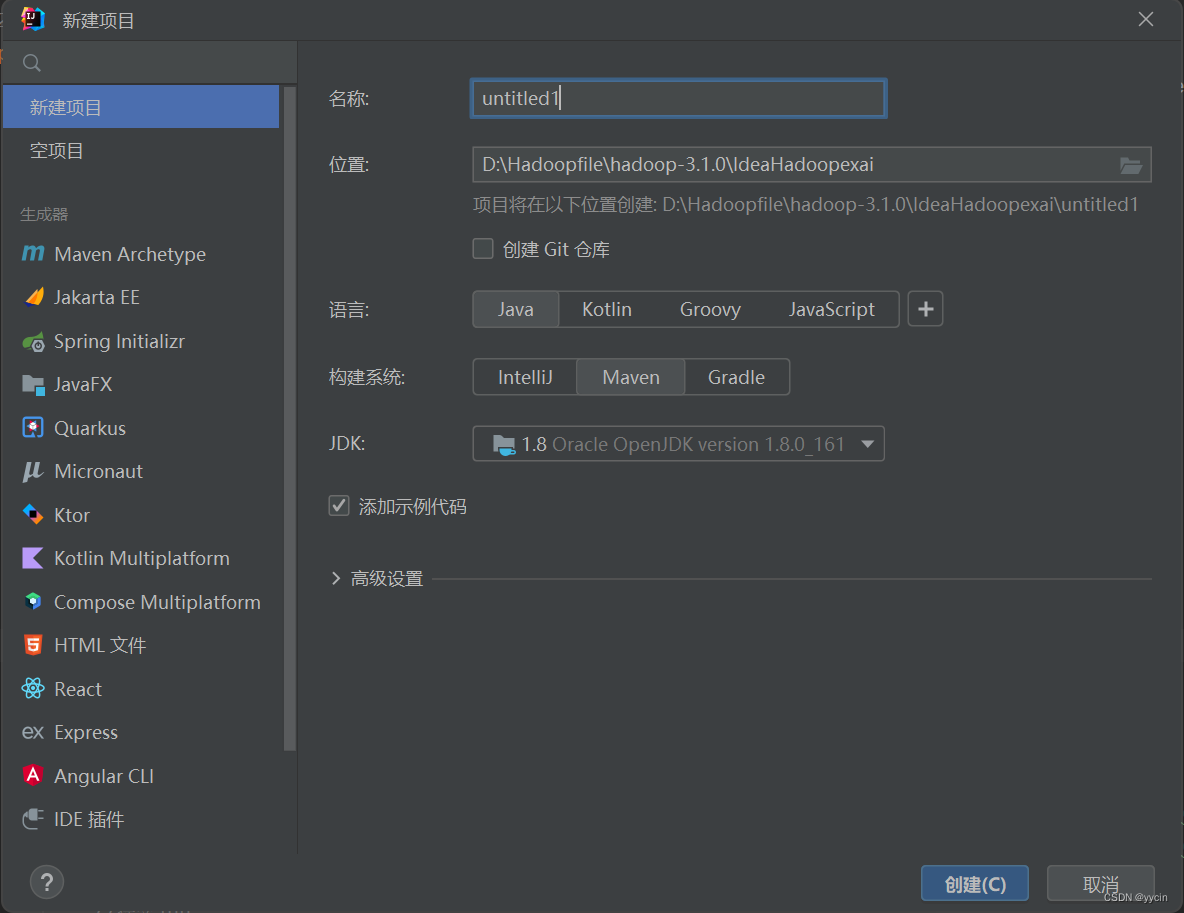
2.配置maven项目
在项目名称\src\main\resources路径下添加一个文件(点击resource,右键-new-file),命名为log4j.properties,并添加以下代码:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n添加如下:
2.1修改pom.xml文件,添加以下部分代码;如果报红,则如下图设置:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>鼠标悬停在爆红字体处
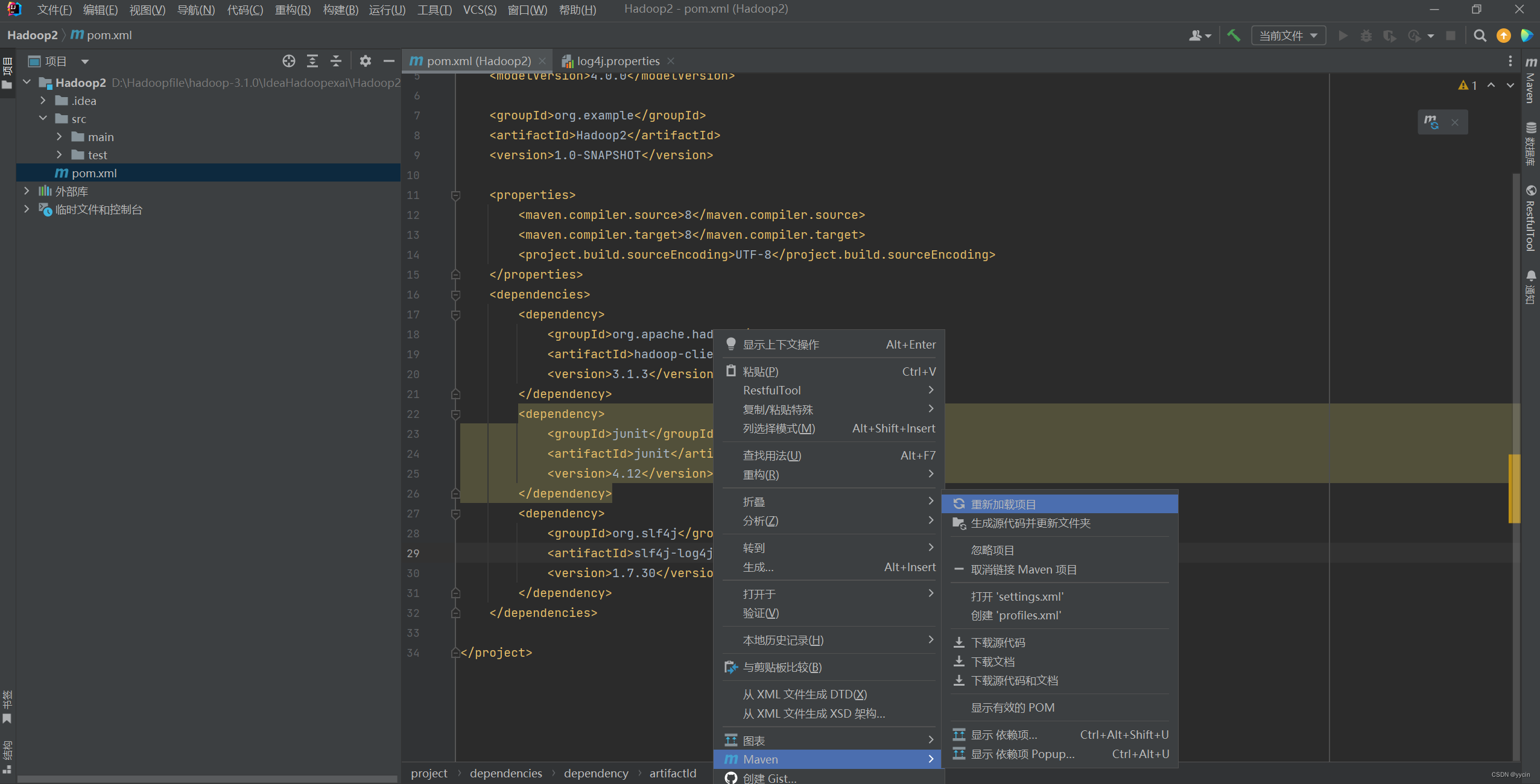
重新加载后,等待片刻就不会变红就算成功了。
2.2.在IDEA左侧的project栏下的Hadoop-src-main-java路径右键创建一个包,命名为com.hadoop.mapreduce.wordcount
注:不用担心包合在一起,当你创建类了之后就会分开的。
2.3在项目名称\src\main\resources路径下添加一个文件(点击resource,右键-new-file),命名为log4j.properties,并添加以下代码
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n2.4在com.hadoop.mapreduce.wordcount包里,右键创建一个WordCountMap类
3.map类阶段代码:
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入数据是key-value(KV)对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式(KV的类型可自定义)
- map()方法(MapTask进程)对每一个<K,V>调用一次
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable>{
private Text outkey =new Text();
private IntWritable outvalue=new IntWritable(1);
@Override
protected void map(LongWritable key,Text value,Mapper<LongWritable,Text,Text,IntWritable>.Context context)throws IOException,InterruptedException{
//获取第一行,技巧:输入value.toString().v弹出var提示时,点回车不起String xx=value.toString();
String line=value.toString();
//切割。元数据第一性是“a a a ”变成了:words=["a","a","a"]
String[] words=line.split(" ");
//3.循环输出,技巧:word.fo弹出for提示时,点回车不起循坏体
for(String word:words){
outkey.set(word);
//使用context把数据传给reduce
context.write(outkey,outvalue);
}
}
}
4.reduce类阶段代码:
- 用户自定义的Reducer要继承自己的父类
- Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer的业务逻辑写在reduce()方法中
- ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outvalue =new IntWritable();
@Override
public void reduce(Text key,Iterable<IntWritable> values,Reducer<Text,IntWritable,Text,IntWritable>.Context context)throws IOException,InterruptedException{
//super.reduce(key,values,context);
// aa.(1,1)
int sum=0;
//1.添加
for(IntWritable value:values){
sum+=value.get();
}
outvalue.set(sum);
//2.输出
context.write(key,outvalue);
}
}5.driver类阶段代码:
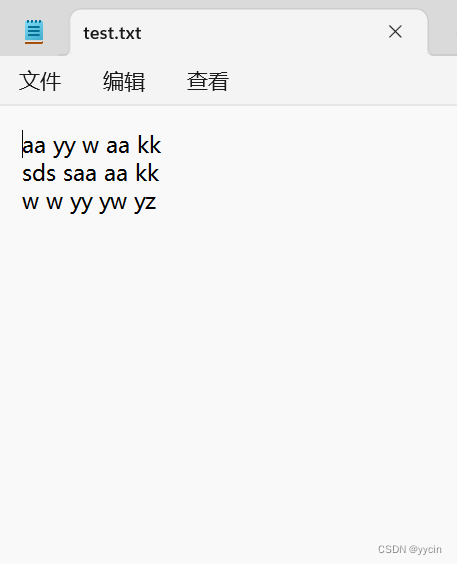
需要用到的.txt文件:
新建一个txt文件并在里面随便输入一些单词,保存后放在一个你知道的路径下,下面会需要此文件的绝对路径。
- 配置作业:设置作业的各种参数,如输入和输出的路径、使用的Mapper和Reducer类等。
- 提交作业:将配置好的作业提交给ResourceManager。
-
package com.hadoop.mapreduce.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.io.Text; import java.io.IOException; public class WordCountDrive { public static void main(String[] args)throws IOException,InterruptedException,ClassNotFoundException{ //获取job Configuration conf=new Configuration(); Job job= Job.getInstance(conf); //2.设置jar路径 job.setJarByClass(WordCountDrive.class); //3.关联mapper和reducer job.setMapperClass(WordCountMap.class); job.setReducerClass(WordCountReduce.class); //4设置map输出的key,value类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //5.设置最终输出的key,value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //6设置输入路径和输出路径 FileInputFormat.setInputPaths(job,new Path("D:\\Hadoopfile\\hadoop-3.1.0\\IdeaHadoopexai\\Hadoop\\input\\wordcount\\test.txt"));//这段输入你需要解析统计单词的.txt文件所在的绝对路径 FileOutputFormat.setOutputPath(job,new Path("D:\\Hadoopfile\\hadoop-3.1.0\\IdeaHadoopexai\\Hadoop\\output1\\outputword1"));//这段输入解析后文件夹所要存放的位置,每次执行该项目代码后请到该文件夹的位置把该文件夹及“outputword1”给删掉。不然会报错的 //提交job boolean result=job.waitForCompletion(true); System.exit(result ? 0 : 1); } } - 注:“outputword1”的文件夹不是我们创建的,是此项目运行后创建的,别自己手动创建
- 你也可以不叫这个“outputword1”名字,这就类似与我们定义名字让项目创建而已
-
三、执行WordCountDriver后的结果展示
3.1运行driver类
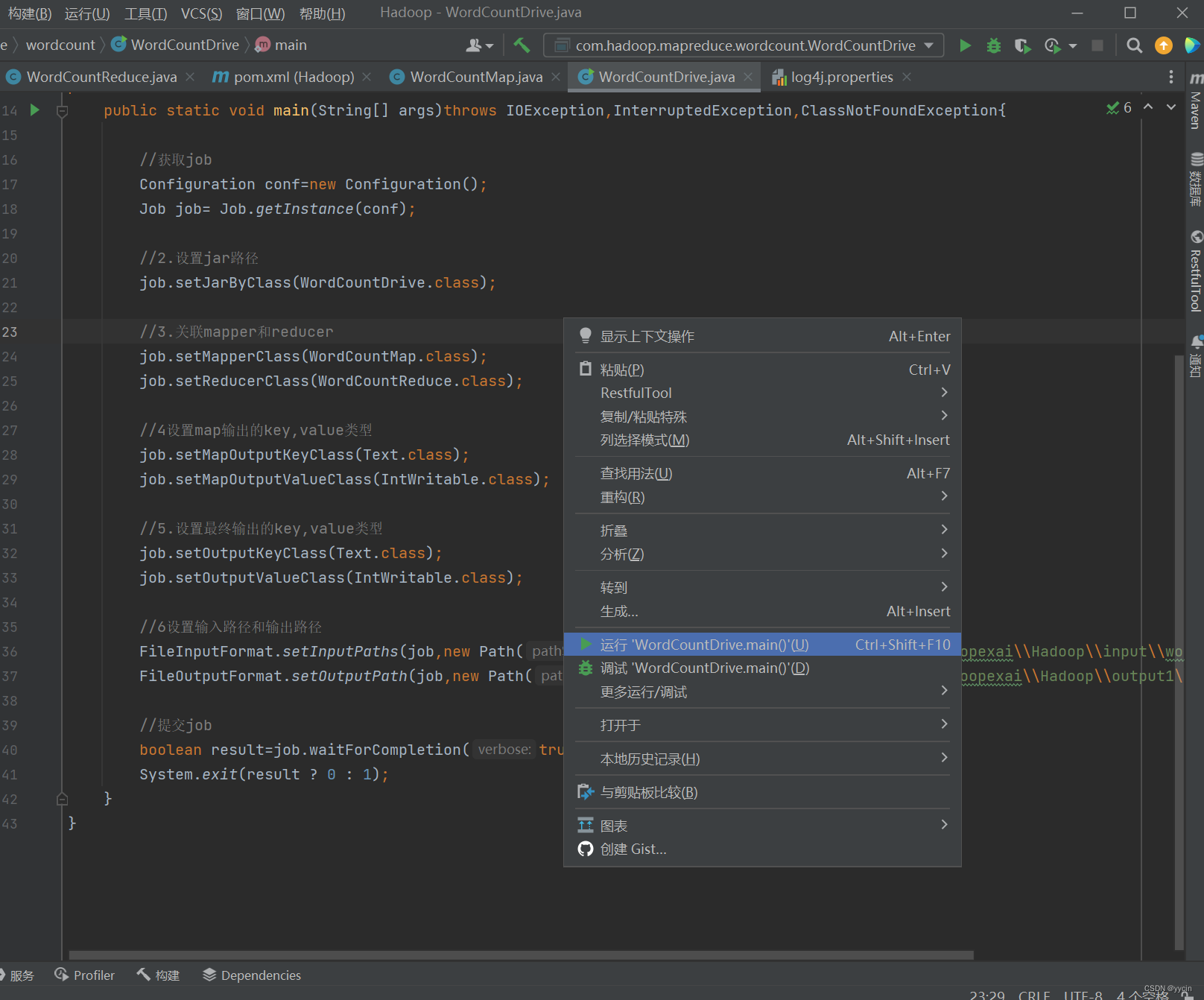
成功执行:
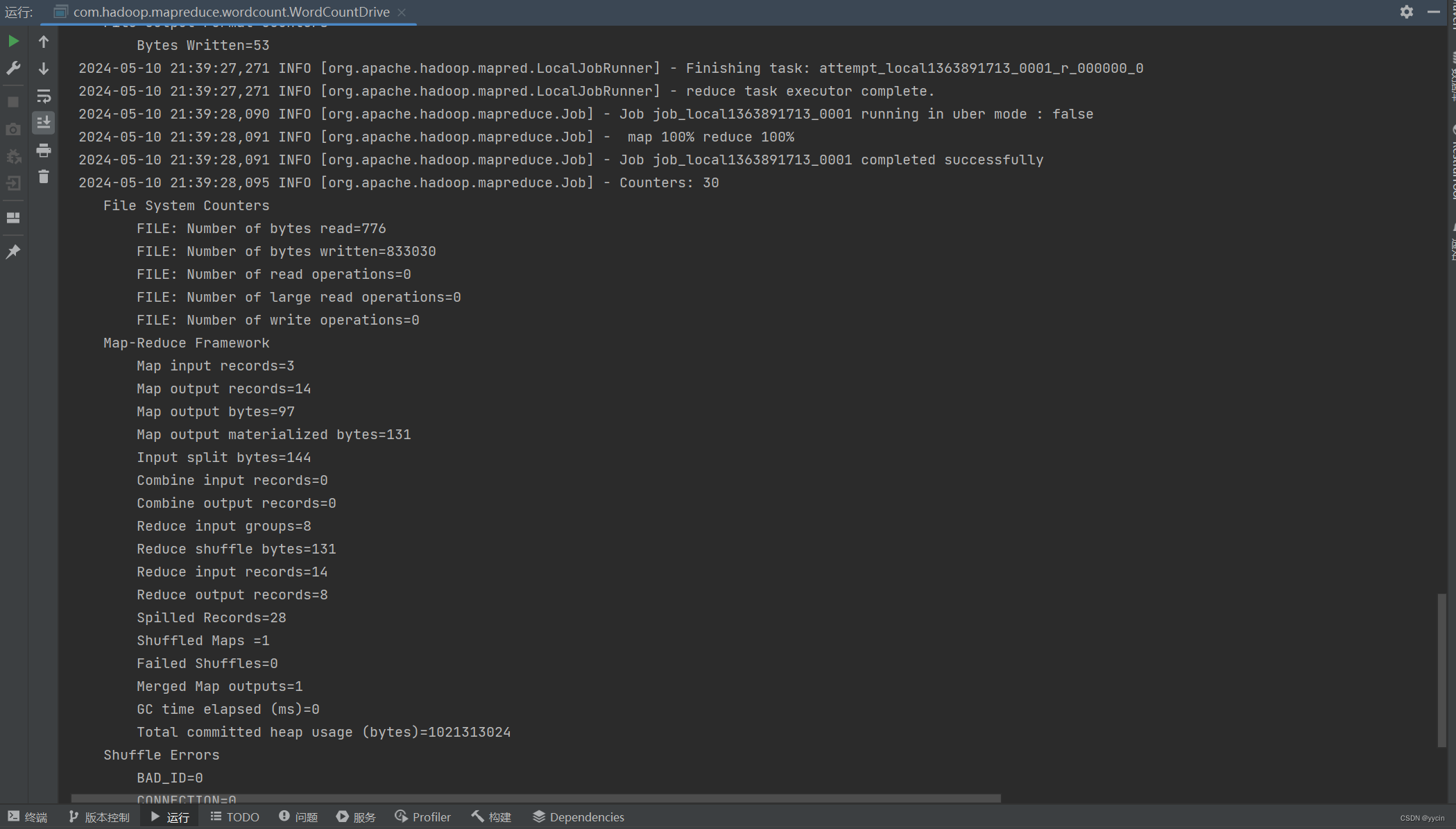
可以看到map和reduce都是100%才算执行成功的
通过打开代码输出文件夹可见到一份叫part-r-00000的文件
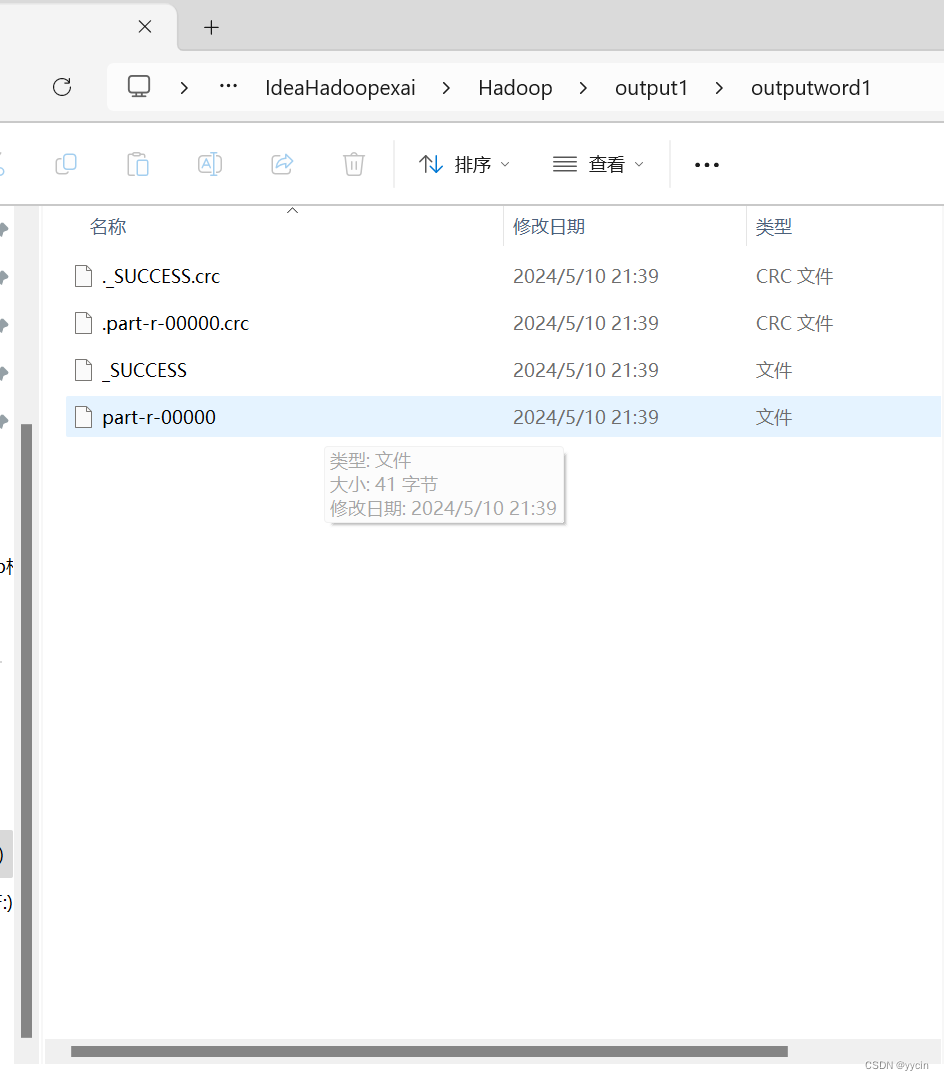
通过记事本打开
就会发现它把上面我们创建出来的txt文件里的单词统计了出来
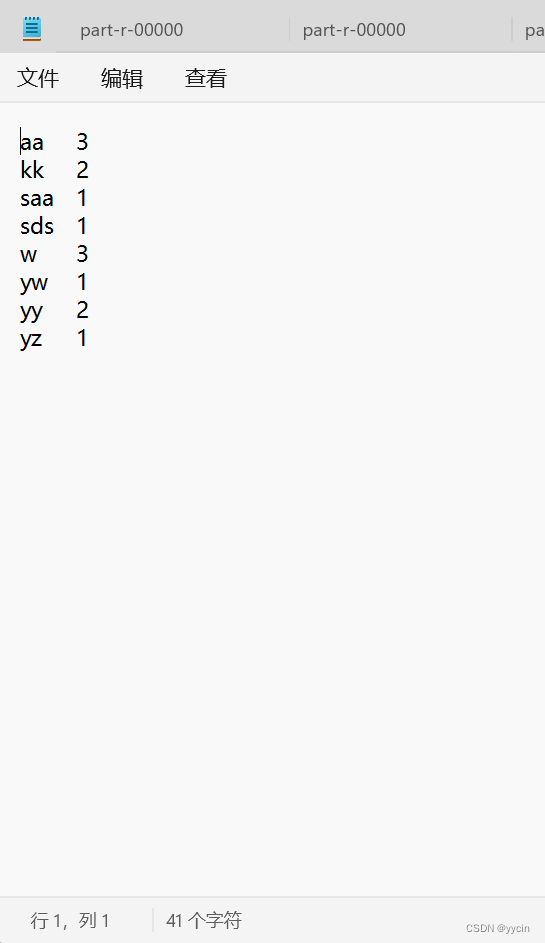
到此,这个简单的小项目就完成了。
四、以下是代码运行中容易出问题的情况:
1、每次运行记得把输出的文件夹删了
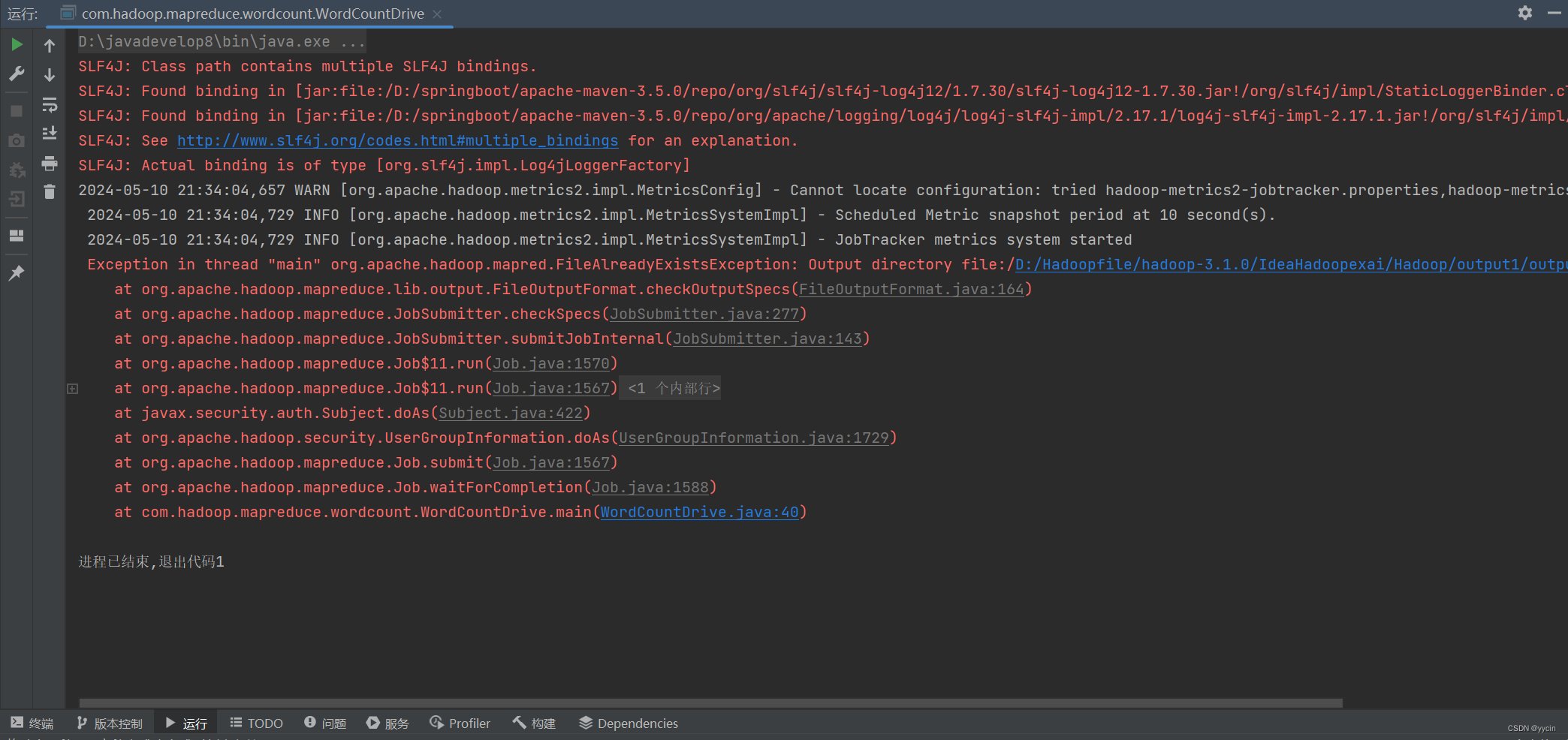
出现此种报错,说明在这之前你肯定运行了此项目,然后又运行了一遍,没删除上面我在代码中提醒的“outputword1”文件夹,找到文件夹所在路径,删了它就又可以运行了。
2、出现map100%但reduce为0%的情况
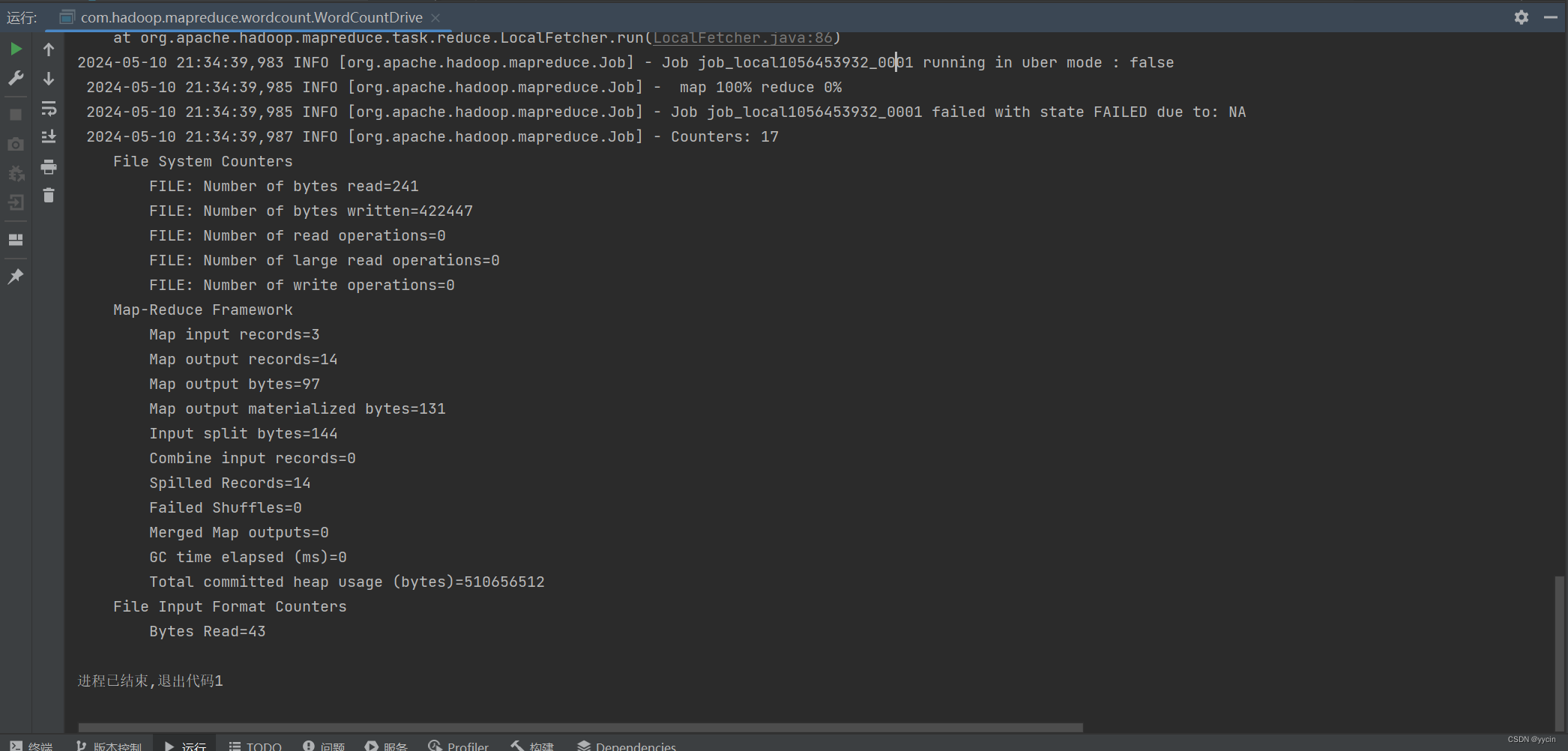
这个情况就比较复杂点,但我就选择能解决大部分人的答案,如果以下操作还不能解决的话,请跳转到更为专业详细解决该情况的博文。
点击“运行”选择“编辑配置”
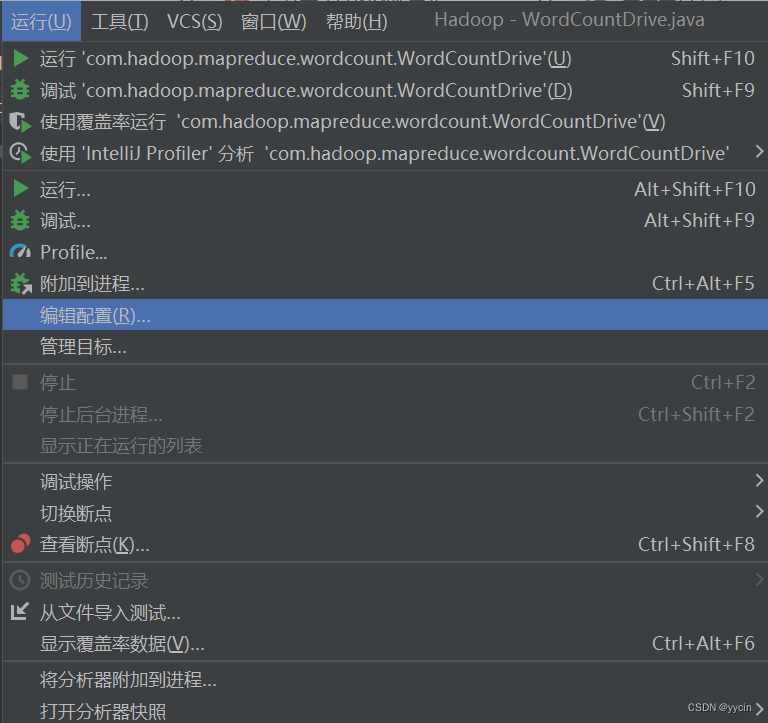
就会来到此界面点击“修改选项(M)”然后选择“添加VM选项”
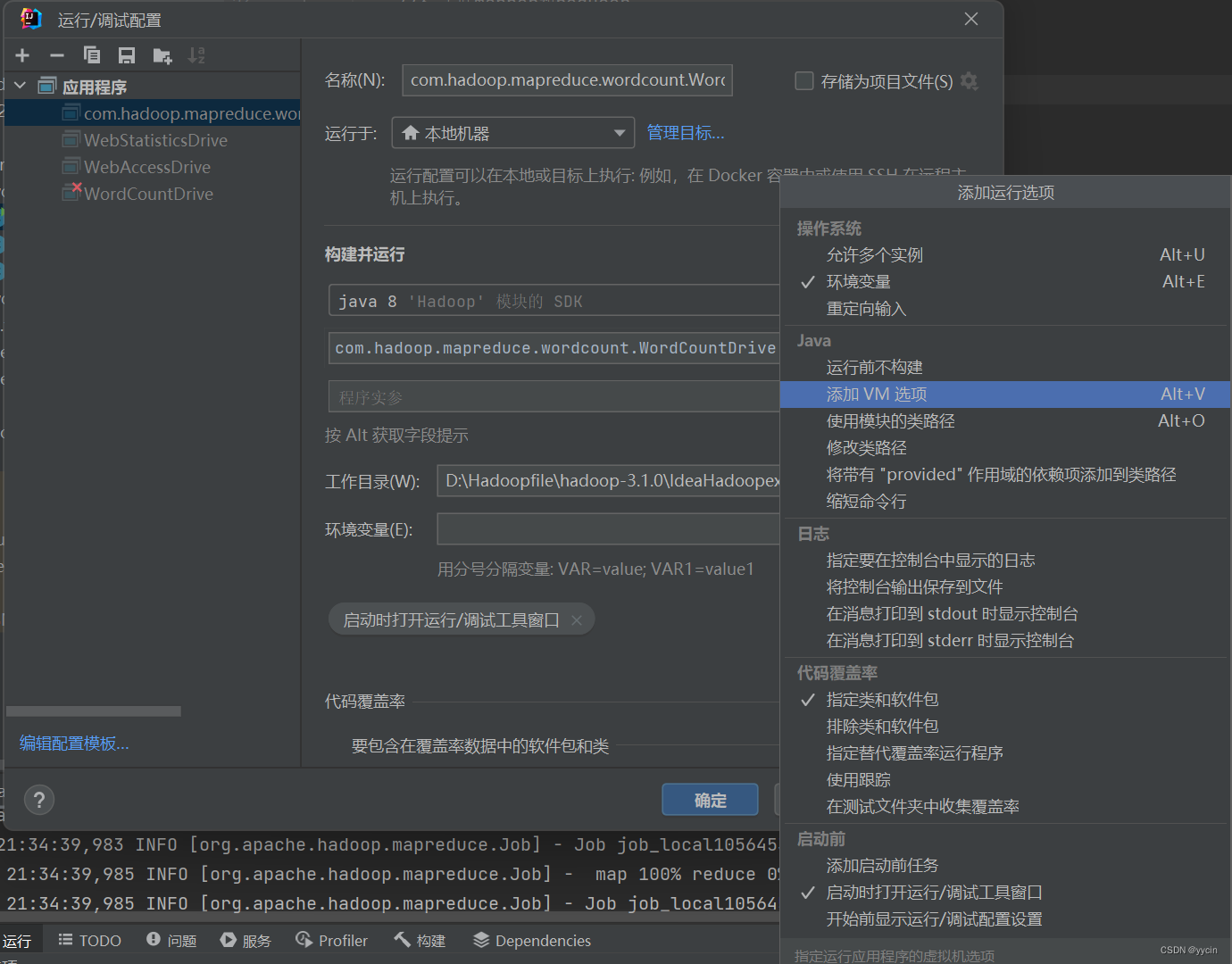
输入:-DHADOOP_USER_NAME=root
至于为什么要使用这个代码,更多情况是因为咱们在注册电脑用户名时使用一些电脑无法解析的字符,当然也有的是因为里面包含空格,所以只能该命令使用管理员运行,但是Hadoop集群通常不鼓励或不允许以root用户身份运行命令,因为这可能会带来安全风险。
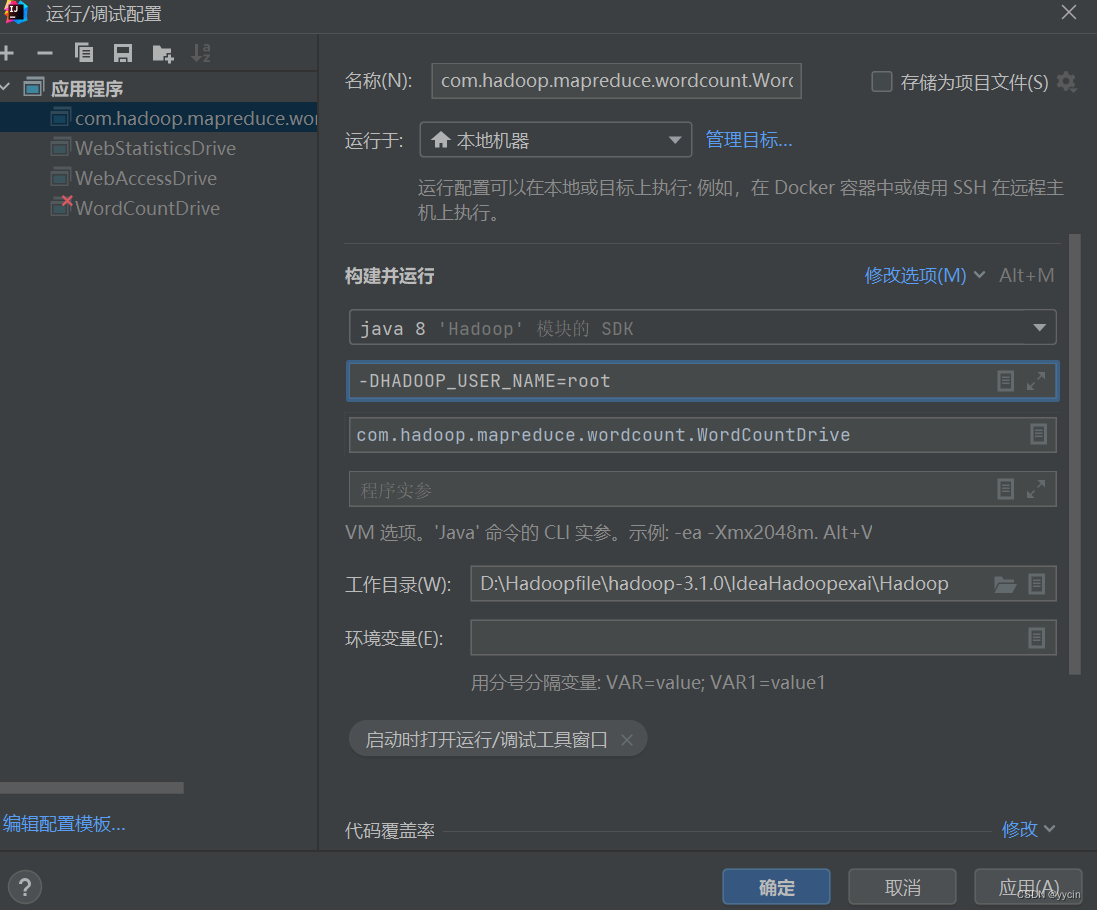
点击运用和确定后再一次运行,大部分情况下都会成功的。
以上就是基于MapReduce通过In2telliJ IDEA对.txt文本做简单词条统计。
五、小结:
MapReduce编程模型通过抽象复杂的并行计算过程,为大数据处理提供了一种简单、高效、可扩展的解决方案。通过Map和Reduce两个函数的组合,可以轻松地处理大规模数据集,并快速获得有价值的分析结果。随着大数据技术的不断发展,MapReduce模型将继续在各个领域发挥重要作用。















 2923
2923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









