







UDF
一、概述(User Define Function)
1,如果hive的内置函数不够用,用户也可以自己定义函数来使用,这样的函数称为hive的用户自定义函数,简称UDF
2. UDF使得Hive的可扩展性增强
自定义类(打成jar包-export)
package cn.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.junit.Test;
//自定义hive函数
//用户自定义函数
public class GetInt extends UDF{
public int evaluate(String str){
str = str.replaceAll("\\D", "");
return Integer.parseInt(str);
}
// @Test
// public void test(){
// String s="aaa33ggh7";
// String str = s.replaceAll("\\d", "");
// System.out.println(str);
// System.out.println(Integer.parseInt(str));
// }
}
将jar包上传
[root@hadoop01 home]# mkdir resources
[root@hadoop01 home]# cd resources/
[root@hadoop01 resources]# rz
hive> add jar /home/resources/authsource.jar;
Added [/home/resources/authsource.jar] to class path
Added resources: [/home/resources/authsource.jar]
hive> create temporary function getint as 'cn.hive.GetInt';
OK
Time taken: 0.867 seconds
hive> select getint('aaa22dd23');
OK
2223
Time taken: 1.985 seconds, Fetched: 1 row(s)
登录数据库(Linux)
开放权限
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
mysql> grant all on *.* to 'root'@'%' identified by 'root';
权限生效
mysql> flush privileges;
创建hive元数据库
mysql> create database hive character set latin1;
[root@hadoop01 apache-hive-1.2.0-bin]# cd conf/
[root@hadoop01 conf]# pwd
/home/presoftware/apache-hive-1.2.0-bin/conf
[root@hadoop01 conf]# ls
beeline-log4j.properties.template hive-exec-log4j.properties.template
hive-default.xml.template hive-log4j.properties.template
hive-env.sh.template ivysettings.xml
[root@hadoop01 conf]# vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
[root@hadoop01 lib]# rz -E
rz waiting to receive.
[root@hadoop01 lib]# ll mysql-connector-java-5.1.39-bin.jar
启动hive
sh hive
报错
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1521)
... 14 more
Caused by: javax.jdo.JDOException: Couldnt obtain a new sequence (unique id) : Cannot execute statement: impossible to write to binary log since BINLOG_FORMAT = STATEMENT and at least one table uses a storage engine limited to row-based logging. InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED.
[root@hadoop01 lib]# cd /usr
[root@hadoop01 usr]# ls
bin etc games include lib lib64 libexec local sbin share src tmp
[root@hadoop01 usr]# vim my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
binlog_format=mixed
重启登录
[root@hadoop01 usr]# service mysql restart
Shutting down MySQL (Percona Server).... [确定]
Starting MySQL (Percona Server).......... [确定]
登录数据库验证
[root@hadoop01 usr]# mysql -uroot -proot
登录hive验证(成功)
sh hive
观察数据库
mysql> use hive;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hive |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| DATABASE_PARAMS |
| DBS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| PARTITIONS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_STATS |
| ROLES |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| VERSION |
+---------------------------+
29 rows in set (0.00 sec)
视图-view
1.在传统的关系型数据库中,为了提高查询效率,可以将一个selecti语句的查询结果进行封装,这个封装形式就是视图
2.在传统的关系型数据库中,视图分为虚拟视图以及物化视图
3.Hive中只支持虚拟视图
4. Hive的视图中,创建的时候,被存储的这句select语句此时并没有执行。
当针对此视图进行第一次操作的时候才会触发这句select语句
5.视图表在HDFS上并没有对应的目录,所以是虚拟视图
hive> create external table score(name string,chinese int,math int,english int) row format delimited fields terminated by ' ' location '/score';
OK
Time taken: 1.181 seconds
hive> select * from score;
OK
Bob 90 64 92
Alex 64 63 68
Grace 57 86 24
Henry 39 79 78
Adair 88 82 64
Chad 66 74 37
Colin 64 86 74
Eden 71 85 43
Grover 99 86 43
hive>
>
> create view score_v as select name,chinese from score;
OK
Time taken: 0.524 seconds
hive> select * from score_v;
OK
Bob 90
Alex 64
Grace 57
Henry 39
Adair 88
Chad 66
Colin 64
Eden 71
Grover 99
Time taken: 0.287 seconds, Fetched: 9 row(s)
hive>
hive> show tables;
OK
score
score_v(并没有创建这个表(视图表))
Time taken: 0.144 seconds, Fetched: 2 row(s)
hive> drop view score_v;
OK
Time taken: 2.302 seconds
索引-index
1.传统的关系型数据库都会建立索引,例如MySQL针对主键建立索引,所采取的索引机制是B+tree
2.在Hive中,如果需要建立索引,需要指定字段
4.在MySQL中,每添加一条数据,默认给这条数据来建立索引;但是在Hive
中,添加的数据不会自动建立索引需要手动建立
建索引
hive> create index score_index on table score (name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table name_index;
OK
Time taken: 0.581 seconds
hive> select * from name_index;
OK
Time taken: 0.361 seconds
hive> alter index score_index on score rebuild;
hive> select * from name_index;
OK
Adair hdfs://hadoop01:9000/score/score.txt [61]
Alex hdfs://hadoop01:9000/score/score.txt [14]
Bob hdfs://hadoop01:9000/score/score.txt [0]
Chad hdfs://hadoop01:9000/score/score.txt [77]
Colin hdfs://hadoop01:9000/score/score.txt [92]
Eden hdfs://hadoop01:9000/score/score.txt [108]
Grace hdfs://hadoop01:9000/score/score.txt [29]
Grover hdfs://hadoop01:9000/score/score.txt [123]
Henry hdfs://hadoop01:9000/score/score.txt [45]
Time taken: 0.737 seconds, Fetched: 9 row(s)
扩展

Hive的优化
1.map side join
表连接中,一个大表一个小表,(小表在前),且小表先缓存起来(大小不超25M)
2.如果在join操作中出现了where查询,那么最好先用子查询筛选条件,然后再进行join,这样做的目的是为了减少查询的数据量
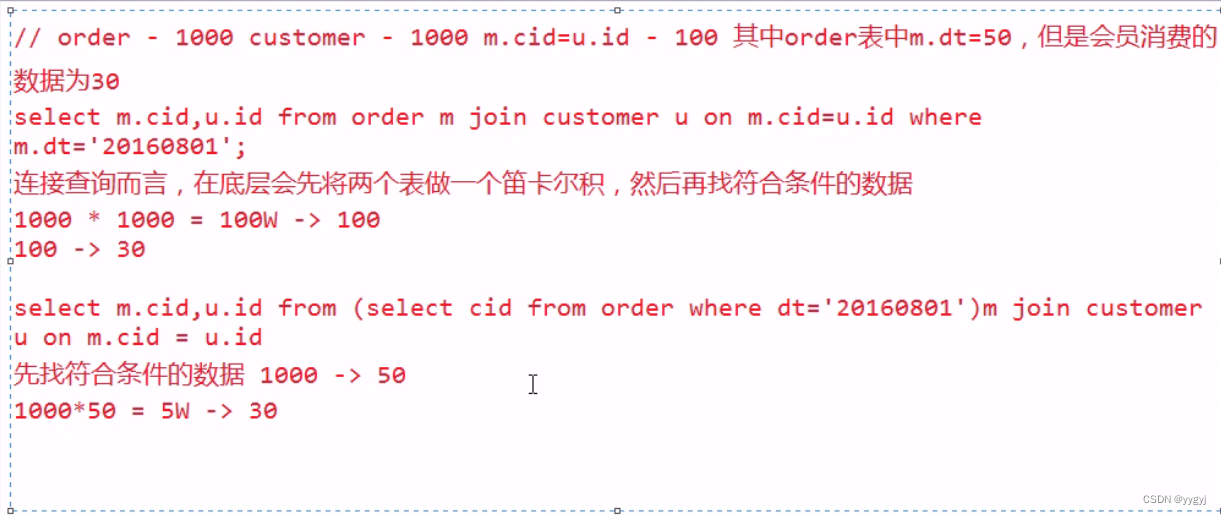
3. group by的优化实际是为了解决Reduce端的数据倾斜。在group by的时候,每一组都会对应一个ReduceTask。如果某一组的数据比其他组的数据多,那么这个时候就会产生数据倾斜。那么这个时候可以通过sethive.groupby.skewindata=true;来生成2个MapReduce,其中第一个MapReduce对数据进行均衡;第二个MapReduce对数据进行最终的聚合
4.count distinct
优化前: select count(distinct id )from tablename
idistinct:要求所有的去重必须发生在Reduce端-在加入distinct之后,在MapReduce计算过程中不允许存在Combiner-默认情况下只有一个ReduceTask,实际生产环境中,为了提高效率,可以考虑将数据进行分区来产生多个ReduceTask来提高效率,例如字母、数字、符号分别对应一个分区来进行去重icount:如果前边进行了分区,那么此时的count就变成了统计每一个分区中不同的id的个数,而SQL语句的要求是统计总的不同的id的个数而不是每一个分区中不同id的个数,那么也就意味着这个过程中不能进行分区
所以在这个场景下,只能有1个ReduceTask,而这唯一的一个ReduceTask既要去重还要计算个数,因此整体的计算效率就只能由这一个ReduceTask来决定
:优化后: select count(*) from (select distinct id from tablename)tmp;利用子查询,可以先在子查询中进行分区去重,最后再利用一个MapReduce来进行计数
5.如果一个文件中,每一行的字段数是比较多的,同时处理逻辑又比较复杂,那么此时可以通过缩小切片大小增多MapTask的数量的方式来提高效率
6.JVM重用:在MapReduce中,每一个MapTask或者是ReduceTask都会开启一次JⅣM子进程来执行任务,所以这个过程中会伴随着JVM的大量的开启和销毁,所以就设置JVM子进程的重用
7.关闭推测执行机制:推测执行机制适用于任务分配不均匀的场景,但是推测执行很明显的不适用于数据倾斜而导致的慢任务场景。在实际生产—场景中,数据倾斜出现的几率更高,此时开启推测执行机制,除了增加节点的负担以外没有任何效果,所以就会考虑关闭推测执行机制
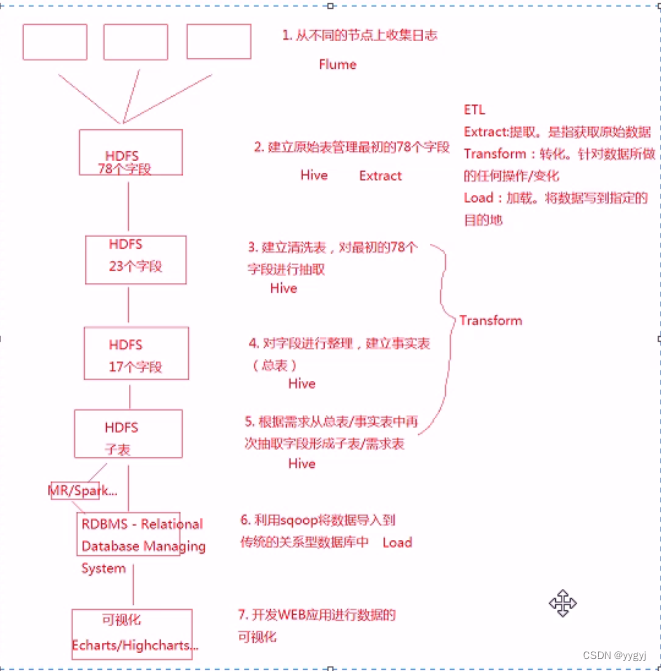
流程
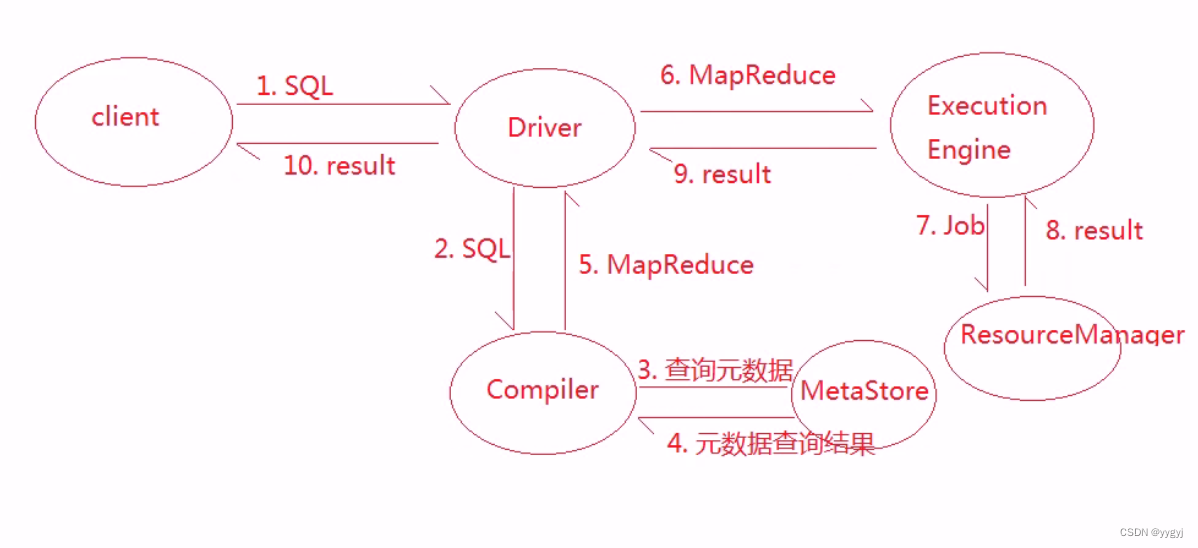
1 Driver:负责任务的调度
2 Compiler:负责将sQL转化为MapReduce
3 Execution Engine:负责和Hadoop进行交互
Sqoop
http://archive.apache.org/dist/sqoop/
[root@hadoop01 presoftware]# tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz
[root@hadoop01 presoftware]# mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha sqoop-1.4.4
上传驱动包
[root@hadoop01 lib]# ll mysql-connector-java-5.1.39-bin.jar
-rw-r--r--. 1 root root 989497 10月 26 2019 mysql-connector-java-5.1.39-bin.jar
[root@hadoop01 lib]# pwd
/home/presoftware/sqoop-1.4.4/lib
sqoop中查数据库
[root@hadoop01 bin]# sh sqoop list-databases --connect jdbc:mysql://hadoop01:3306 -username root -password root
Warning: /usr/lib/hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/lib/hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
22/07/23 13:45:02 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
22/07/23 13:45:02 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
easymall
hive
mstest
mysql
performance_schema
test
[root@hadoop01 bin]#
查表
[root@hadoop01 bin]# sh sqoop list-tables --connect jdbc:mysql://hadoop01:3306/hive -username root -password root
登录mysql,创建数据库
mysql> create database demo;
mysql> use demo;
mysql> create table score(name varchar(30) primary key,chinese int,math int,english int);
hive 中的score表(外部表)导入数据库(mysql)即将HDFS上的score目录下的数据导入到mysql中的score表中
[root@hadoop01 bin]# sh sqoop export --connect jdbc:mysql://hadoop01:3306/demo --username root --password root --export-dir '/score' --table score -m 1 --fields-terminated-by ' '
Java操作hive
@Test
public void testConnectAndQuery0 throws Exception {
注册数据库驱动,用的hive的jdbc,驱动名固定写死
Class.forName("org.apache.hive.jdbc.HiveDriver");
/如果用的是hive2服务,则写jdbc:hive2,后面跟上hive服务器的ip以及端口号,端口号默认是10000
Connection conn = DriverManager.getConnection("jdbc:hive2://192.168.253.129:10000/park", "root","root");
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from stu");while (rs.next()) {
String name = rs.getString("name");System.out.println(name);
stat.close();
conn.close();
}
项目
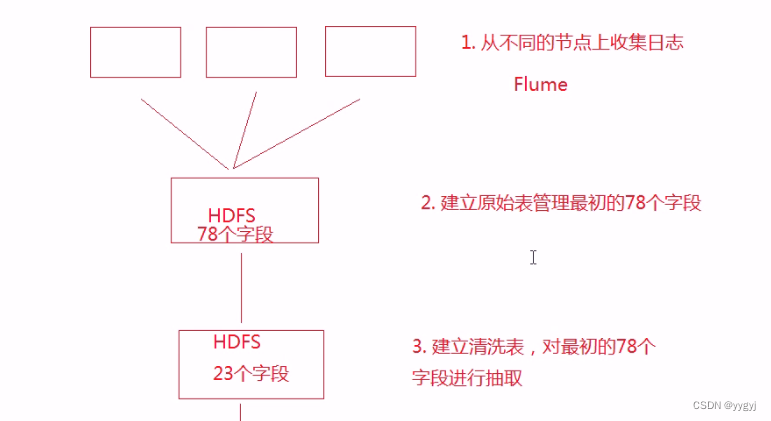
flume配置
a1.sources=r1 a1.channels=c1 a1.sinks=s1
a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/home/zebra
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://192.168.253.129:9000/zebra/reportTime=%Y-%m-%d
a1.sinks.s1.hdfs.fileType=DataStream a1.sinks.s1.hdfs.rollInterval=30
a1.sinks.s1.hdfs.rollSize=0 a1.sinks.s1.hdfs.rollCount=0
a1.channels.c1.type=memory
a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
[root@hadoop01 home]# mkdir zebra
[root@hadoop01 home]# cd zebra/
此处放日志内容
flume配置(执行收集日志)
[root@hadoop01 data]# vi zebra.conf
a1.sources=r1 a1.channels=c1 a1.sinks=s1
a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/home/zebra
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://192.168.253.129:9000/zebra/reporttime=%Y-%m-%d
a1.sinks.s1.hdfs.fileType=DataStream a1.sinks.s1.hdfs.rollInterval=30
a1.sinks.s1.hdfs.rollSize=0 a1.sinks.s1.hdfs.rollCount=0
a1.channels.c1.type=memory
a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
hive> create database zebra;
OK
hive> create EXTERNAL table zebra (a1 string,a2 string,a3 string,a4 string,a5 string,a6 string,a7 string,a8 string,a9 string,a10 string,a11 string,a12 string,a13 string,a14 string,a15 string,a16 string,a17 string,a18 string,a19 string,a20 string,a21 string,a22 string,a23 string,a24 string,a25 string,a26 string,a27 string,a28 string,a29 string,a30 string,a31 string,a32 string,a33 string,a34 string,a35 string,a36 string,a37 string,a38 string,a39 string,a40 string,a41 string,a42 string,a43 string,a44 string,a45 string,a46 string,a47 string,a48 string,a49 string,a50 string,a51 string,a52 string,a53 string,a54 string,a55 string,a56 string,a57 string,a58 string,a59 string,a60 string,a61 string,a62 string,a63 string,a64 string,a65 string,a66 string,a67 string,a68 string,a69 string,a70 string,a71 string,a72 string,a73 string,a74 string,a75 string,a76 string,a77 string) partitioned by (reporttime string) row format delimited fields terminated by '|' stored as textfile location '/zebra';
修复分区
msck repair table zebra;
修复分区2
hive> ALTER TABLE zebra add PARTITION (reportTime='2018-09-06') location '/zebra/reportTime= 2018-09-06';
清洗数据,从原来的77个字段变为23个字段
建表语句:
create table dataclear(reporttime string,appType bigint,appSubtype bigint,userIp string,userPort bigint,appServerIP string,appServerPort bigint,host string,cellid string,appTypeCode bigint,interruptType String,transStatus bigint,trafficUL bigint,trafficDL bigint,retranUL bigint,retranDL bigint,procdureStartTime bigint,procdureEndTime bigint)row format delimited fields terminated by '|';
从zebra表里导出数据到dataclear表里(23个字段的值)
建表语句:
insert overwrite table dataclear select concat(reporttime,'','00:00:00'),a23,a24,a27,a29,a31,a33,a59,a17,a19,a68,a55,a34,a35,a40,a41,a20,a21 from zebra;
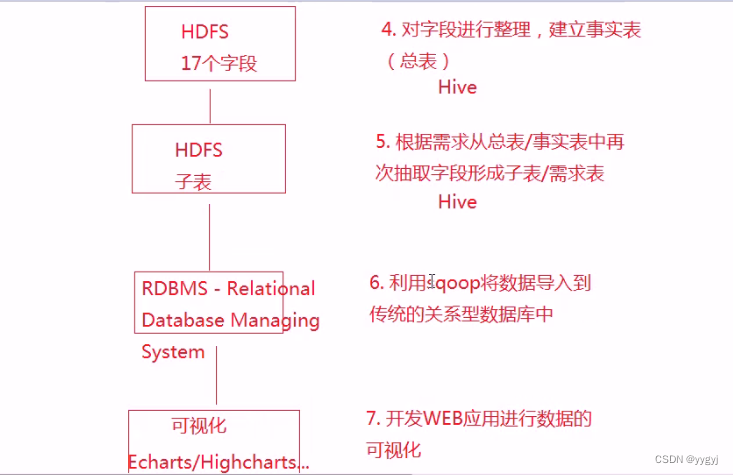
处理业务逻辑,得到dataproc表
建表语句:
create table dataproc (reporttime string,appType bigint,appSubtype bigint,userIp string,userPort bigint,appServerIP string,appServerPort bigint,host string,cellid string,attempts bigint,accepts bigint,trafficUL bigint,trafficDL bigint,retranUL bigint,retranDL bigint,failCount bigint,transDelay bigint)row format delimited fields terminated by '|';
根据业务规则,做字段处理
建表语句:
insert overwrite table dataproc select reporttime,appType,appSubtype,userIp,userPort,appServerIP,appServerPort,host,
if(cellid == '',"000000000",cellid),if(appTypeCode == 103,1,0),if(appTypeCode == 103 and find_in_set(transStatus,"10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,2
02,203,204,205,206,302,304,306")!=0 and interruptType == 0,1,0),if(apptypeCode == 103,trafficUL,0), if(apptypeCode == 103,trafficDL,0), if(apptypeCode == 103,retranUL,0), if(apptypeCode == 103,retranDL,0), if(appTypeCode == 103 and transStatus == 1 and interruptType == 0,1,0),if(appTypeCode == 103, procdureEndTime - procdureStartTime,0) from dataclear;
查询关心的信息,以应用受欢迎程度表为例:
建表语句:msyql
create table D_H_HTTP_APPTYPE(hourid string,appType int,appSubtype int,attempts bigint,accepts bigint,succRatio double,trafficUL bigint,trafficDL bigint,totalTraffic bigint,retranUL bigint,retranDL bigint,retranTraffic bigint,failCount bigint,transDelay bigint) row format delimited fields terminated by '|';
根据总表dataproc,按条件做聚合以及字段的累加
建表语句:
insert overwrite table D_H_HTTP_APPTYPE select reporttime,apptype,appsubtype,sum(attempts),sum(accepts),round(sum(accepts)/sum(attempts),2),sum(trafficUL),sum(trafficDL),sum(trafficUL)+sum(trafficDL),sum(retranUL),sum(retranDL),sum(retranUL)+sum(re tranDL),sum(failCount),sum(transDelay)from dataproc group by reporttime,apptype,appsubtype;
18.查询前5名受欢迎app
select hourid,apptype,sum(totalTraffic) as tt from D_H_HTTP_APPTYPE group by hourid,apptype sort by tt desc limit 5;
Sqoop组件工作流程:
将Hive表导出到Mysql数据库中,然后通过web应用程序+echarts做数据可视化工作。
实现步骤:
1.在mysql建立对应的表
2.利用sqoop导出d_h_http_apptype表导出语句:
sh sqoop export --connect jdbc:mysql://hadoop01:3306/zebra --username root --password root – export-dir '/user/hive/warehouse/zebra.db/d_h_http_apptype/000000_0' --table D_H_HTTP_APPTYPE -m 1 --fields-terminated-by '|'














 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









