







摘要
本周聚焦模型优化与多模态LLM技术。在模型优化方面,系统研究了量化技术的位精度实现方法、稀疏矩阵的压缩特性及蒸馏学习的知识迁移机制;在多模态LLM领域,深入对比了统一嵌入解码器与跨模态注意力两种架构的实现差异与训练策略,构建了从模型压缩到多模态扩展的技术框架。
Abstract
This week focused on model optimization and multimodal LLM technologies. For model optimization, it systematically studied bit-precision implementation in quantization, compression characteristics of sparse matrices, and knowledge transfer mechanisms in distillation learning. In multimodal LLM, the research conducted an in-depth comparison between unified embedding-decoder and cross-modal attention architectures regarding implementation differences and training strategies, establishing a technical framework from model compression to multimodal extension.
1、模型优化技术
1.1 量化(Quantization)
量化是降低模型权重和激活精度的过程。大多数模型都以 32 或 16 位精度进行训练,其中每个参数和激活元素占用 32 或 16 位内存(单精度浮点)。然而,大多数深度学习模型可以用每个值八个甚至更少的位来有效表示。
- 权重量化(Weight Quantization):将模型的权重(weights)从32位浮点数转换为较低精度(如8位整数)。这种方法通常会减少存储和计算负担。
- 激活量化(Activation Quantization):将模型中的激活值(中间计算结果)量化为低精度表示,进一步减少计算资源。
- 混合量化(Mixed Precision Quantization):不同的层或参数使用不同的量化精度,某些关键层使用较高精度,其他层使用较低精度,以平衡性能和效率。
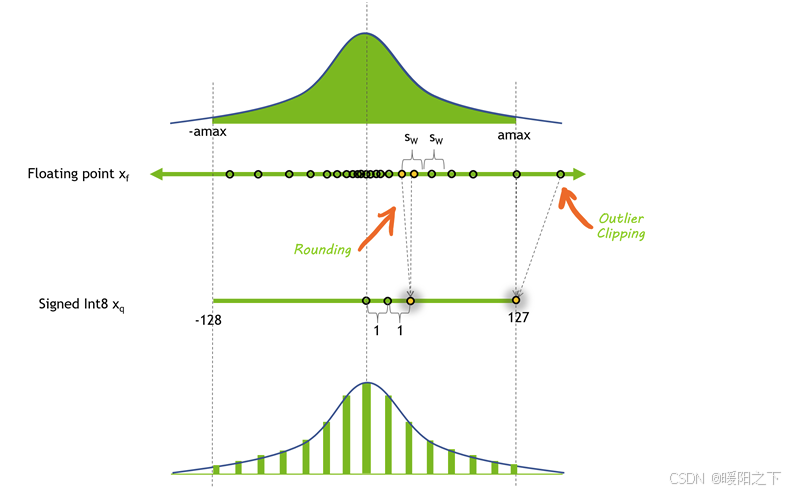
上图显示了一种可能的量化方法之前和之后的值分布。在这种情况下,会丢失一些精度,并且剪裁会丢失一些动态范围,从而允许以更小的格式表示值。
但是降低模型的精度可以带来多种好处。如果模型占用的内存空间较少,则可以在相同数量的硬件上安运行更大的模型。「量化还意味着可以在相同的带宽上传输更多参数,这有助于加速带宽有限的模型」。
可以直接使用Bitsandbytes库进行量化操作:
8bit量化
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_8bit=True, # 启用 8-bit 量化 [−128,127]
llm_int8_threshold=6.0, # 设置低精度计算的阈值:当某个权重的绝对值超过这个阈值时,认为它对模型性能的影响较大,将其保留为高精度类型。
llm_int8_skip_modules=None # 指定跳过量化的模块(可选)
)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"/path/to/qwen_2B_instruct", torch_dtype=torch.bfloat16, device_map="cuda", quantization_config=quantization_config,
)
4bit量化
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用 4-bit 量化 [-8, 7]
bnb_4bit_compute_dtype="float16", # 计算时的精度:量化主要针对模型的权重存储,而实际计算仍然需要浮点数来保持精度。
bnb_4bit_use_double_quant=True, # 双重量化:4-bit 权重的值被先量化为 int8,然后再进一步压缩到 4-bit。
bnb_4bit_quant_type="nf4" # 量化类型(如 `nf4` 或标准量化) NF4 使用对数分布或其他非均匀分布来更精确地表示权重值。
)
1.2 稀疏(Sparsity)
与量化类似,事实证明,许多深度学习模型对于修剪或用 0 本身替换某些接近 0 的值具有鲁棒性。「稀疏矩阵是许多元素为 0 的矩阵」。这些矩阵可以用压缩形式表示,比完整的稠密矩阵占用的空间更少。
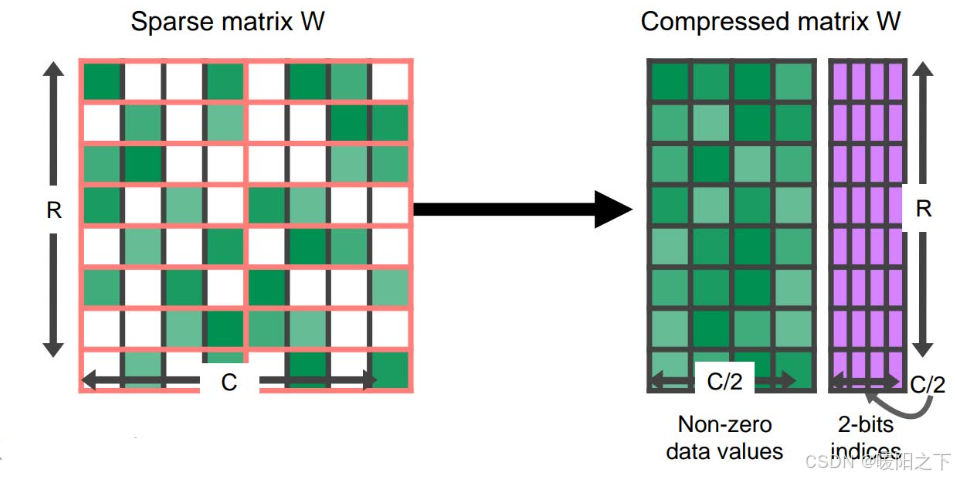
GPU 尤其具有针对某种结构化稀疏性的硬件加速,其中每四个值中有两个由零表示。稀疏表示还可以与量化相结合,以实现更大的执行速度。「寻找以稀疏格式表示大型语言模型的最佳方法仍然是一个活跃的研究领域」,并为未来提高推理速度提供了一个有希望的方向。
1.3 蒸馏(Distillation)
蒸馏(Distillation)是一种 模型压缩和优化 技术,通常用于让 小模型 学习 大模型 的知识,使其在推理时更高效,同时仍然保留较强的能力。
蒸馏过程的核心:
- 教师模型(Teacher Model): 一个 大模型,通常性能更强,但计算开销大。
- 学生模型(Student Model): 一个 较小的模型,通过学习教师模型的知识,尝试在较低计算成本下达到类似的效果。
- 学习方式:
- 传统训练是用数据和标签让模型学习,而蒸馏是让学生模型模仿教师模型的输出(软标签 Soft Labels)。
- 除了标准的交叉熵损失,蒸馏可能会引入 KL 散度或匹配中间层的表示 作为额外的训练目标,使得小模型更接近大模型的行为。
蒸馏模型的成功例子包括 DistilBERT,它将 BERT 模型压缩了 40%,同时保留了 97% 的语言理解能力,速度提高了 60%。
虽然LLMs中的蒸馏是一个活跃的研究领域,但神经网络的一般方法首次在论文Distilling the Knowledge in a Neural Network(https://arxiv.org/abs/1503.02531)中提出:学生网络经过训练,可以反映较大教师网络的性能,使用损失函数来测量其输出之间的差异。该目标还可能包括将学生的输出与真实标签进行匹配的原始损失函数。
匹配的教师输出可以是最后一层(称为 logits)或中间层激活。
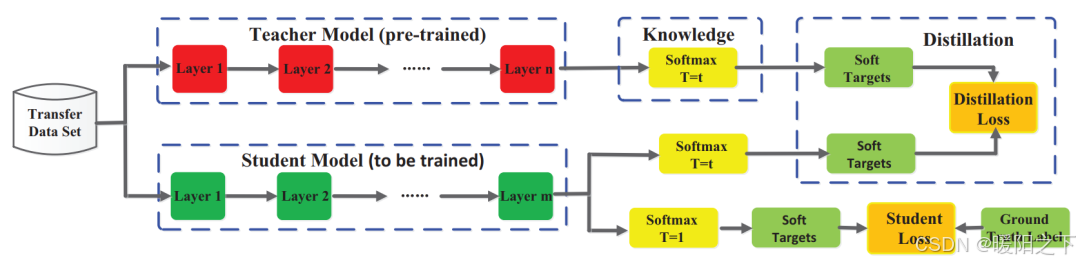
上图显示了知识蒸馏通用的总体框架(https://arxiv.org/pdf/2006.05525)。教师的 logits是学生使用蒸馏损失进行优化的软目标。其他蒸馏方法可能会使用其他损失措施来从老师那里“蒸馏”知识。
「蒸馏的另一种方法是使用教师合成的数据对LLMs学生进行监督培训,这在人工注释稀缺或不可用时特别有用」。一步一步蒸馏!更进一步,除了作为基本事实的标签之外,还从LLMs教师那里提取基本原理。这些基本原理作为中间推理步骤,以数据有效的方式培训规模较小的LLMs。
值得注意的是,当今许多最先进的LLMs都拥有限制性许可证,禁止使用他们的成果来训练其他LLMs,这使得找到合适的教师模型具有挑战性。
2、多模态LLM
2.1 简介
多模态 LLM 是能够处理多种类型输入的大型语言模型, 多模态 LLM 可以接受不同的输入模态(音频、文本、图像和视频)并返回文本作为输出模态。
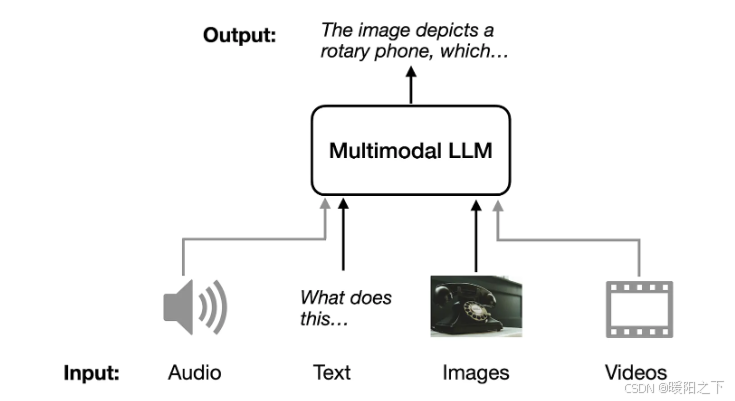
多模态 LLM 的一个直观的应用场景是为图像生成描述,提供输入图像,模型会生成图像的描述,如下图所示。

2.2 构建多模态 LLM
构建多模态 LLM 有两种主要方法:统一嵌入解码器架构方法; 跨模态注意力架构方法。
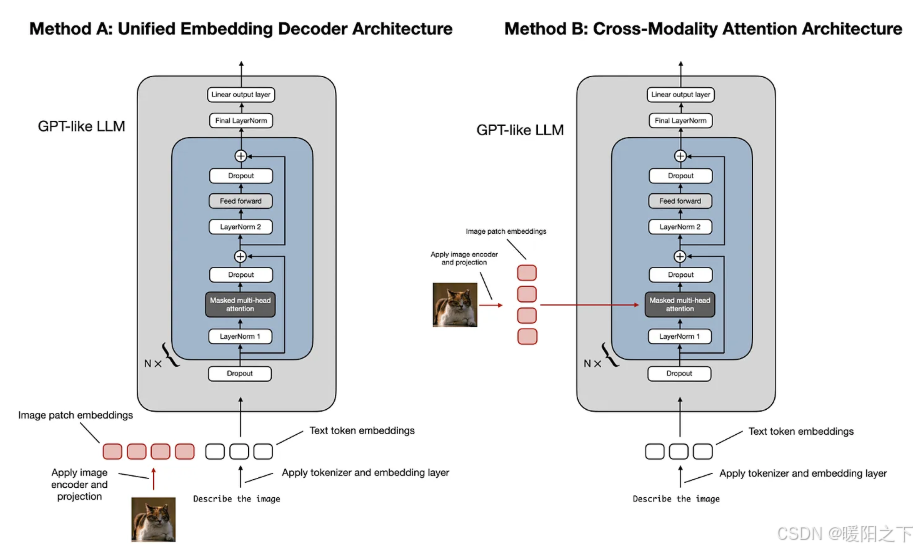
如上图所示,统一嵌入-解码器架构使用单个解码器模型,很像 GPT-2 或 Llama 3.2 等未经修改的 LLM 架构。在这种方法中,图像被转换为与原始文本令牌具有相同嵌入大小的令牌,从而允许 LLM 在连接后同时处理文本和图像输入令牌。而跨模态注意力架构采用交叉注意力机制,将图像和文本嵌入直接集成到注意力层中。
2.2.1 统一嵌入解码器架构
在统一的嵌入-解码器架构中,图像被转换为嵌入向量,类似于在标准纯文本 LLM 中将输入文本转换为嵌入的方式。对于处理文本的典型纯文本 LLM,文本输入通常是标记化的(例如,使用字节对编码),然后通过嵌入层传递,如下图所示。
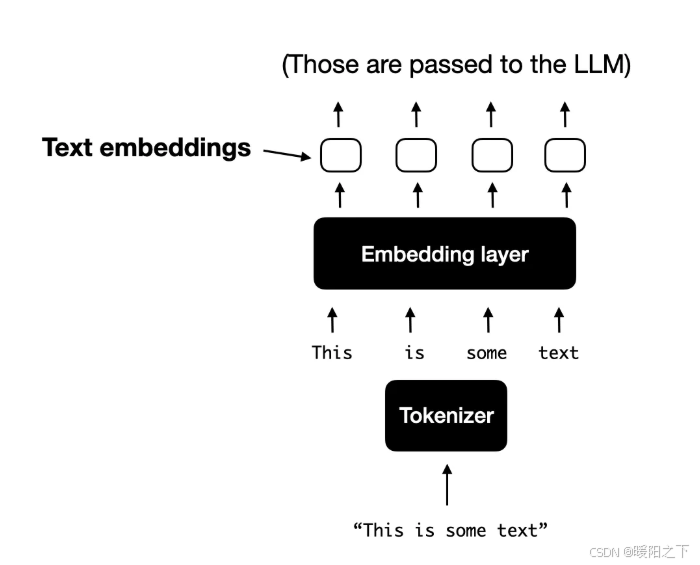
2.2.2 跨模态注意力架构
在跨模态注意力架构方法中,仍然使用我们之前讨论过的相同图像编码器设置。然而,不是将补丁编码为 LLM 的输入,而是通过交叉注意力机制将多头注意力层中的输入补丁连接起来。这个想法可以追溯到 2017 年 Attention Is All You Need 论文中的原始 transformer 架构,如下图所示。
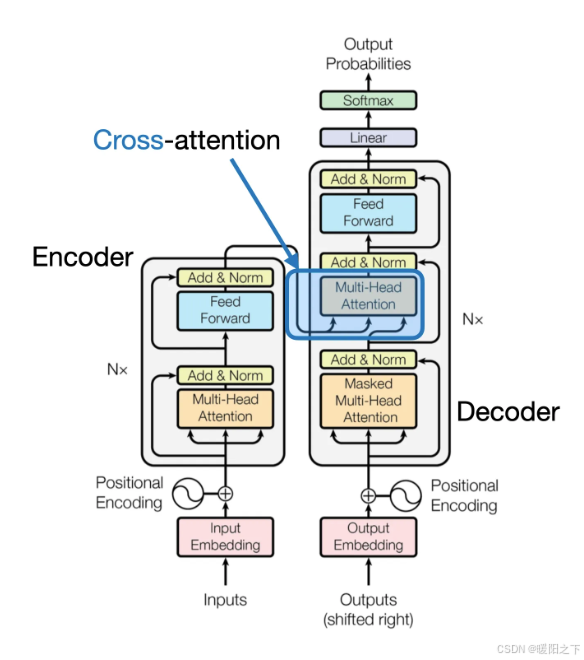
2.2.3 统一解码器和交叉注意力模型训练
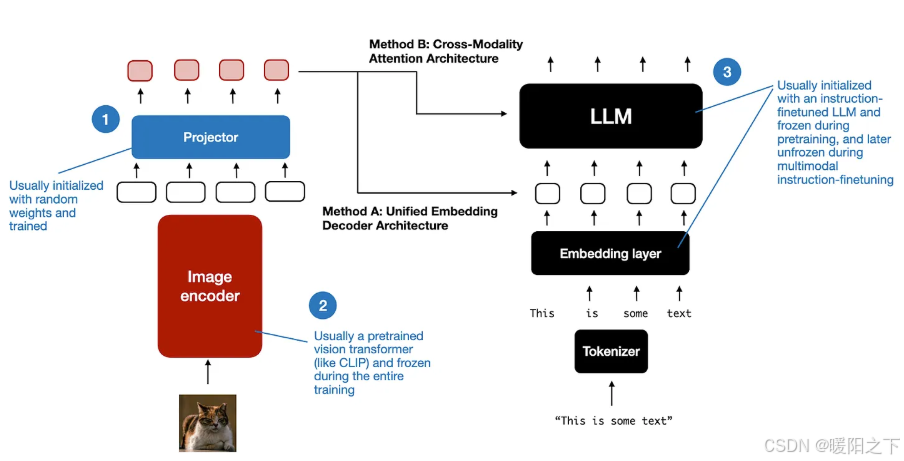
与传统的纯文本 LLM 的开发类似,多模态 LLM 的训练也包括两个阶段:预训练和教学微调。然而,与从头开始不同的是,多模态 LLM 训练通常以预先训练的、指令微调的纯文本 LLM 作为基本模型开始。
对于图像编码器,CLIP 是常用的,并且在整个训练过程中通常保持不变,但也有例外,在预训练阶段保持 LLM 部分冻结也是很常见的,只专注于训练投影仪 - 线性层或小型多层感知器。鉴于投影机的学习能力有限,通常只包含一两层,因此 LLM 通常在多模态教学微调(第 2 阶段)期间解冻,以便进行更全面的更新。但是,请注意,在基于交叉注意力的模型(方法 B)中,交叉注意力层在整个训练过程中都是解冻的。
统一嵌入解码器架构(方法 A)通常更容易实现,因为它不需要对 LLM 架构本身进行任何修改。
跨模态注意力架构(方法 B)通常被认为计算效率更高,因为它不会用额外的图像标记使输入上下文过载,而是稍后将它们引入交叉注意力层。此外,如果 LLM 参数在训练期间保持冻结,则此方法将保持原始 LLM 的纯文本性能。
总结
本周系统梳理了模型优化三大核心技术:量化通过降低权重与激活值精度显著减少计算负载,稀疏化利用矩阵压缩特性提升存储效率,蒸馏则实现了大模型知识向轻量化模型的高效迁移;在多模态LLM领域,重点解析了统一嵌入解码器架构的易实现性与跨模态注意力架构的计算高效性,并阐明其预训练-微调流程的设计要点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









