






一、DeepSeek 基础知识介绍
1. DeepSeek 是什么?
DeepSeek 是一款基于深度学习技术的大规模语言模型,旨在通过自然语言处理(NLP)技术实现智能问答、文本生成、数据分析等功能。它能够理解和生成自然语言,适用于多种场景,如智能客服、文档生成、代码辅助等。
2. 内网部署 DeepSeek 的作用
·数据安全:内网部署确保敏感数据不外泄,满足企事业单位对数据隐私和安全的高要求。避免内网敏感数据导出到外网后的泄密风险。
·定制化:可根据需求定制模型,优化特定任务的实现。
·高效响应:内网部署减少网络延迟,提升响应速度。不会出现高峰期提示“服务器繁忙,请稍后再试。”的问题。
·合规性:满足行业或地区的合规要求,避免法律风险。
3. 不同模型的区别
·模型规模:不同模型的参数量不同,参数量越大,模型能力通常越强,但计算资源需求也更高。以DeepSeek为例,现在有1.5B、7B、8B、14B、32B、70B、671B这些规模。这里的“B”通常表示“Billion”,即“十亿”。例如,一个7B的模型表示该模型有70亿个参数。参数量是衡量模型复杂度和性能的一个重要指标,通常参数越多,模型能够学习到的数据特征就越复杂,理论上可以提供更精确、更丰富的输出。
·应用场景:不同模型针对不同任务优化,如有的擅长文本生成,有的擅长问答。
·训练数据:不同模型使用的训练数据集不同,影响其表现和适用场景。
·计算资源:大规模模型需要更多计算资源,小规模模型则更适合资源有限的环境。
| 参数量 | 含义 | 特点 |
| 1.5B | 15亿参数 | 适合轻量级任务,如移动端或边缘设备。 |
| 7B | 70亿参数 | 适合复杂对话、代码生成等任务,可在单卡GPU上运行。 |
| 13B | 130亿参数 | 性能更强,适合复杂逻辑推理,需要专业GPU支持。 |
| 70B | 700亿参数 | 接近人类水平的泛化能力,适合专业领域推理,需要多卡或高端服务器级GPU。 |
| 671B | 6710亿参数 | 超大规模模型,适合企业级应用,训练和推理成本极高。 |
选择模型大小时,需要根据具体的硬件条件和应用场景进行权衡。例如,资源有限的环境适合选择小模型(如1.5B),而追求高性能的场景则可以选择中等或大模型。
4. 什么是蒸馏?蒸馏技术和完整模型、量化模型的联系和区别是什么?
蒸馏(Knowledge Distillation)是一种模型压缩技术,通过将大模型(教师模型)的知识传递给小模型(学生模型),使小模型在保持较高性能的同时减少计算资源需求。蒸馏通常通过以下步骤实现:
·训练教师模型:先训练一个复杂的大模型。
·生成软标签:使用教师模型生成软标签(概率分布)。
·训练学生模型:学生模型学习模仿教师模型的输出。
完整模型、量化模型和蒸馏技术在深度学习模型优化中有着紧密的联系,但它们在目标、方法和应用场景上存在显著区别。以下是它们的联系与区别:
联系:
1.目标一致:三者都旨在优化深度学习模型,使其在保持较高性能的同时,减少计算资源和存储需求,以便更好地部署在资源受限的环境中。
2.可结合使用:在实际应用中,量化和蒸馏技术可以结合使用,以实现更高效的模型压缩。例如,先通过蒸馏训练一个较小的学生模型,然后对学生模型进行量化,从而在保持性能的同时进一步减少模型大小。
区别
| 特性 | 完整模型 | 量化模型 | 蒸馏技术 |
| 定义 | 原始的、未经优化的深度学习模型,通常具有高精度但计算和存储成本高。 | 通过降低模型参数和激活值的数值精度(如从32位浮点数转换为8位整数)来减少模型大小和计算需求。 | 将大型教师模型的知识迁移到小型学生模型中,通过软标签指导学生模型的训练,使其在较小规模下接近教师模型的性能。 |
| 优化目标 | 无优化,追求最高精度。 | 减少模型存储空间和计算成本,提高推理速度。 | 在保持较小模型规模的同时,尽可能保留教师模型的性能。 |
| 实现方法 | 直接训练得到的模型,不涉及优化。 | 训练后量化(PTQ)或量化感知训练(QAT)。 | 训练一个大型教师模型,然后用其输出指导小型学生模型的训练。 |
| 精度影响 | 通常具有最高的精度。 | 精度可能因量化而有所损失,但可以通过优化方法尽量减少这种损失。 | 学生模型的精度通常接近教师模型,甚至在某些情况下可以超过教师模型。 |
| 适用场景 | 适用于计算资源充足且对精度要求极高的场景。 | 适用于边缘计算、实时应用和大规模部署等对存储和计算资源要求严格的场景。 | 适用于资源受限的设备,如移动设备和嵌入式系统,以及需要快速推理的场景。 |
5. DeepSeek 相较于其他大模型的优势和特长
·高效性:DeepSeek 在保持高性能的同时,优化了计算资源使用,适合多种部署环境。
·定制化:支持根据企业需求定制模型,提升特定任务的表现。
·数据安全:内网部署确保数据安全,适合对隐私要求高的场景。
·多语言支持:支持多种语言,适合国际化企业。
·易用性:提供友好的API和工具,便于集成到现有系统中。
二、部署资源要求
部署资源要求,可以参看https://apxml.com/posts/gpu-requirements-deepseek-r1
完整模型:(通常指未经量化的原始深度学习模型,其参数和激活值通常以高精度的浮点数(如32位的FP32)表示)
| Model | Parameters (B) | VRAM Requirement (GB) | Recommended GPU |
| DeepSeek-R1-Zero | 671B | ~1,543 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x16) |
| DeepSeek-R1 | 671B | ~1,543 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x16) |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~3.9 GB | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~18 GB | NVIDIA RTX 4090 24GB or higher |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~21 GB | NVIDIA RTX 4090 24GB or higher |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~36 GB | Multi-GPU setup (e.g., NVIDIA RTX 4090 x2) |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~82 GB | Multi-GPU setup (e.g., NVIDIA RTX 4090 x4) |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~181 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x3) |
量化模型:(通过将模型中的参数和激活值从高精度数值(如32位浮点数)转换为低精度数值(如8位整数或更低)来优化模型,以减少存储需求和计算成本)
| Model | Parameters (B) | VRAM Requirement (GB) (4-bit) | Recommended GPU |
| DeepSeek-R1-Zero | 671B | ~436 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x6) |
| DeepSeek-R1 | 671B | ~436 GB | Multi-GPU setup (e.g., NVIDIA A100 80GB x6) |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~1 GB | NVIDIA RTX 3050 8GB or higher |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~4.5 GB | NVIDIA RTX 3060 12GB or higher |
|
|
|
|
|
| DeepSeek-R1-Distill-Llama-8B | 8B | ~5 GB | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~9 GB | NVIDIA RTX 4080 16GB or higher |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~21GB | NVIDIA RTX 4090 24GB or higher |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~46 GB | Multi-GPU setup (e.g. NVIDIA RTX 4090 24GB x2) |
三、安装部署环境
现场安装部署服务器配置:
CPU:Intel Xeno(R)Gold 5318Y CPU @ 2.10GHZ(96核)
GPU:英伟达T4 16G *2
内存:512G
硬盘:300G系统盘+1T数据盘
操作系统:CentOS 7.5
四、安装步骤
所需离线安装文件进行了整合,文件结构如下:
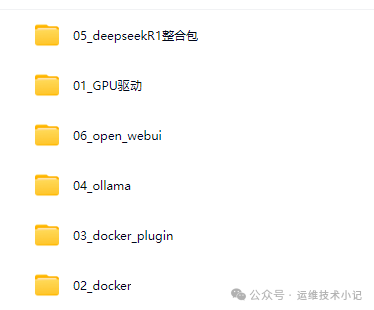
1、安装基础环境-GPU驱动
将“01_驱动/NVIDIA-Linux-x86_64-535.129.03.run”、“01_驱动/cuda_11.8.0_520.61.05_linux.run”这两个文件上传至到 Linux 系统任意目录下,如/home 下。
切换到/home目录
cd /home
执行以下命令给包赋予可执行权限
chmod +x NVIDIA-Linux-x86_64-535.129.03.run
因为安装 GPU 驱动需要关闭图形界面,所以要执行以下命令来切换到命令行终端
init 3
执行以下命令安装
./NVIDIA-Linux-x86_64-535.129.03.run --no-opengl-files
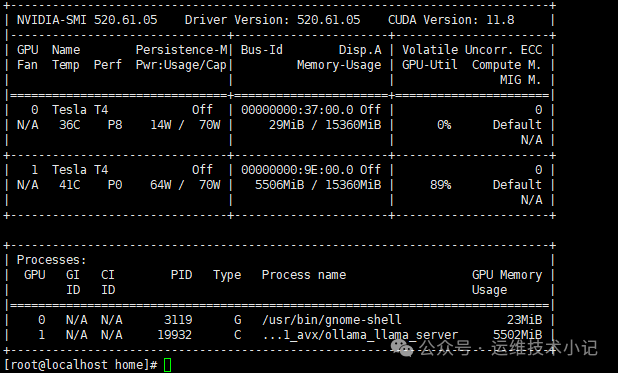
在“Install NVIDIA's 32-bit compatibility libraries?”提示框中选择“Yes”,按 Enter 键,在界面选中“OK”,按 Enter 键,此时 NVIDIA GPU 卡驱动安装完毕。 安装完成执行命令 nvidia-smi 查看显卡信息,如回显中可以显示显卡的型号及相关信息,说明驱动安装正常。
执行命令 init 5 进入图形界面。
init 5
执行以下命令给包赋予可执行权限
chmod +x cuda_11.8.0_520.61.05_linux.run
然后sh cuda_11.8.0_520.61.05_linux.run,根据提示输入accept,后面的提示默认按回车就行。
安装好之后执行nvidia-smi,可以看到cuda的版本号,上面的截图里可以看到。
我们这个环境里是两块显卡,用nvidia-smi命令也是上面的截图,可以看出显卡编号分别是0和1号。
执行命令export CUDA_VISIBLE_DEVICES=0,1
上面的命令作用是设置环境变量,限制 CUDA 程序能够访问的 GPU 设备。具体来说,这条命令表示只允许程序使用编号为 0 和 1 的 GPU 设备。避免多个程序同时占用同一块 GPU,导致资源竞争
2、安装docker
将“02_docker” 包整个目录上传到服务器中
cd 02_docker
yum install *.rpm
若安装过程提示依赖冲突或缺少依赖,可以执行以下命令
cp other/*.rpm ./
yum install *.rpm
若还是缺少依赖,则需要从网站上面下载对应的包了,可以从此地址下载对应的包 http://mirror.centos.org/centos/7/os/x86_64/Packages/
创建自启动服务
systemctl enable docker
3、安装docker插件
将“03_docker_plugin” 文件目录上传到服务器中
cd 03_docker_plugin
yum install *.rpm
nvidia-docker 如果回显正常说明安装成功
重启docker
systemctl restart docker
4、安装ollama
将”04_ollama”文件目录上传到服务器中
cd 04_ollama
chmod +x install.sh
sudo sh install.sh
输入ollama --version查看版本信息
![]()
5、安装deepkeepr1大模型
将“05_deepseekR1整合包”文件目录上传到服务器上
cd 05_deepseekR1整合包
执行ollama create deepseekr1:7b -f ./deepseek-r1-7b.modelfile安装deepseek
其中deepseekr1:7b为模型名称,可以自定义
执行ollama list查看模型

然后执行ollama run deepseekr1:7b
此时可以提问测试模型情况
如果要后台运行,执行nohup ollama run deepseekr1:7b >ollama.log 2>&1 &
6、安装open-webui
将“06_open_webui”文件目录上传到服务器上
cd 06_open_webui
先导入镜像
docker load -i dyrnq-open-webui-main.tar
执行docker images查看镜像

启动open-webui
执行docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always dyrnq/open-webui:main 此时可以客户端访问open-webui
http://服务器ip:8080
需要用较高版本浏览器访问,如果显示空白,请升级浏览器版本,已测试360安全浏览器13.3版本和谷歌Chrome131版本是可以的。
五、Open-WebUI配置说明
首次注册账号为管理员账号,其他用户账号由管理员在设置中创建,也可开启首页注册功能,也可以批量导入账号,其他功能大家可自行研究。
离线安装资源整合包已上传百度网盘。整理收集不易,大家可以请小编喝杯奶茶或者打赏,我给大家发整合包链接,包括1.5B到70B的模型包。安装遇到问题可以留言,我们也有技术交流群,我们都是热爱技术的一群人,欢迎加入一起交流分享。来吧,交个朋友!我们等着你!


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











