







数据集的预览
数据集的介绍
Pavia University数据集是一个高光谱图像数据集,由一个被称为反射光学系统在意大利帕维亚市(ROSIS-3)的传感器收集。该图像由610×340像素,103个光谱波段组成。该图像被分为9类,共计42,776个标签样本,包括沥青、草地、砾石、树木、金属板、裸土、沥青、砖和阴影。
下图为数据集类别图
可视化图像

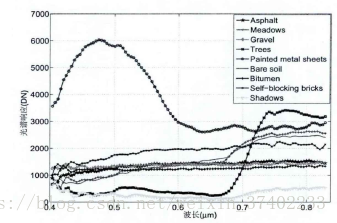
光谱响应曲线
读取数据
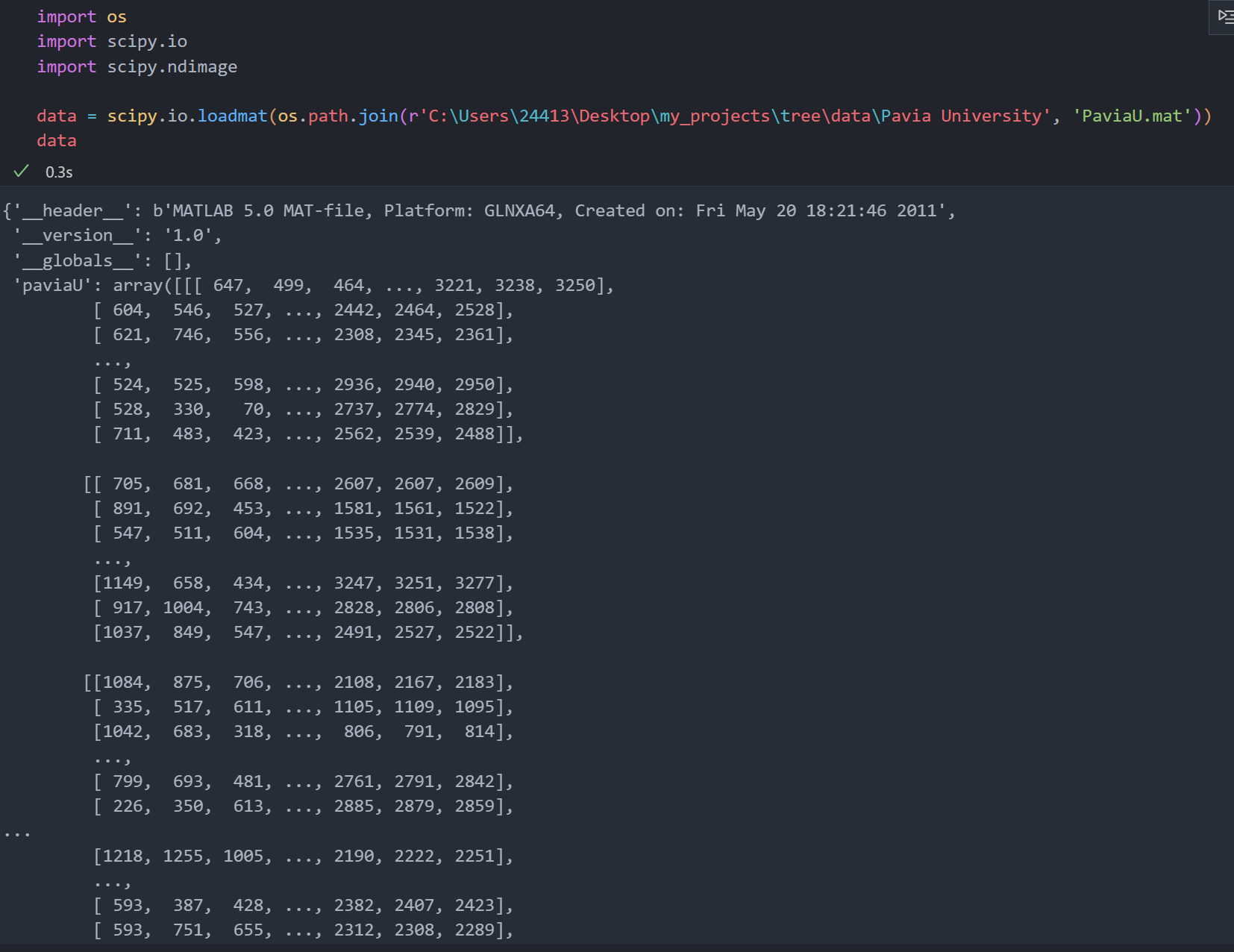
.mat是以键值对的形式存储的,data.key()为([‘header’, ‘version’, ‘globals’, ‘paviaU’])
进行数据处理的时候只需要处理最后一个键里面的数据
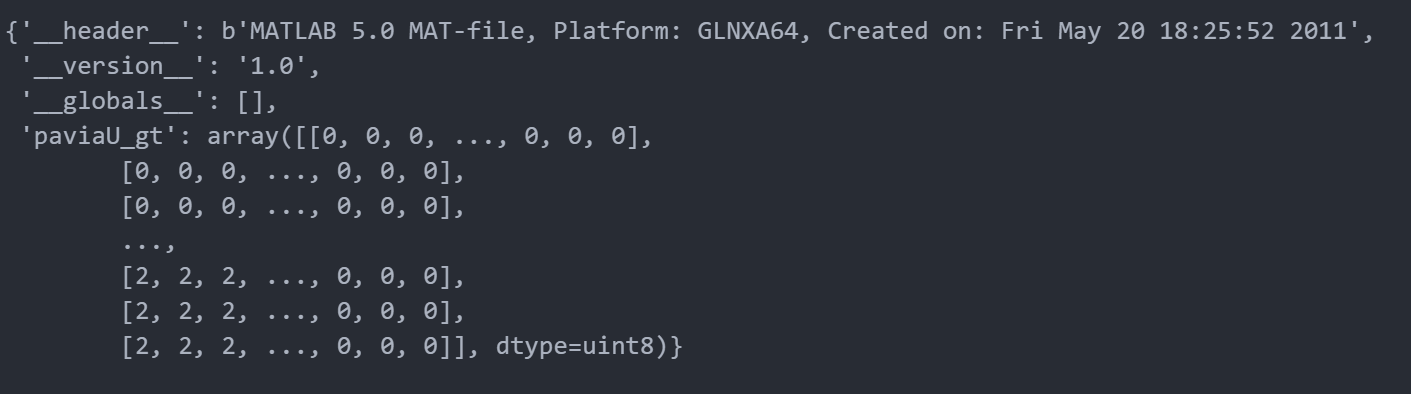
转换后的数据是一个array数组
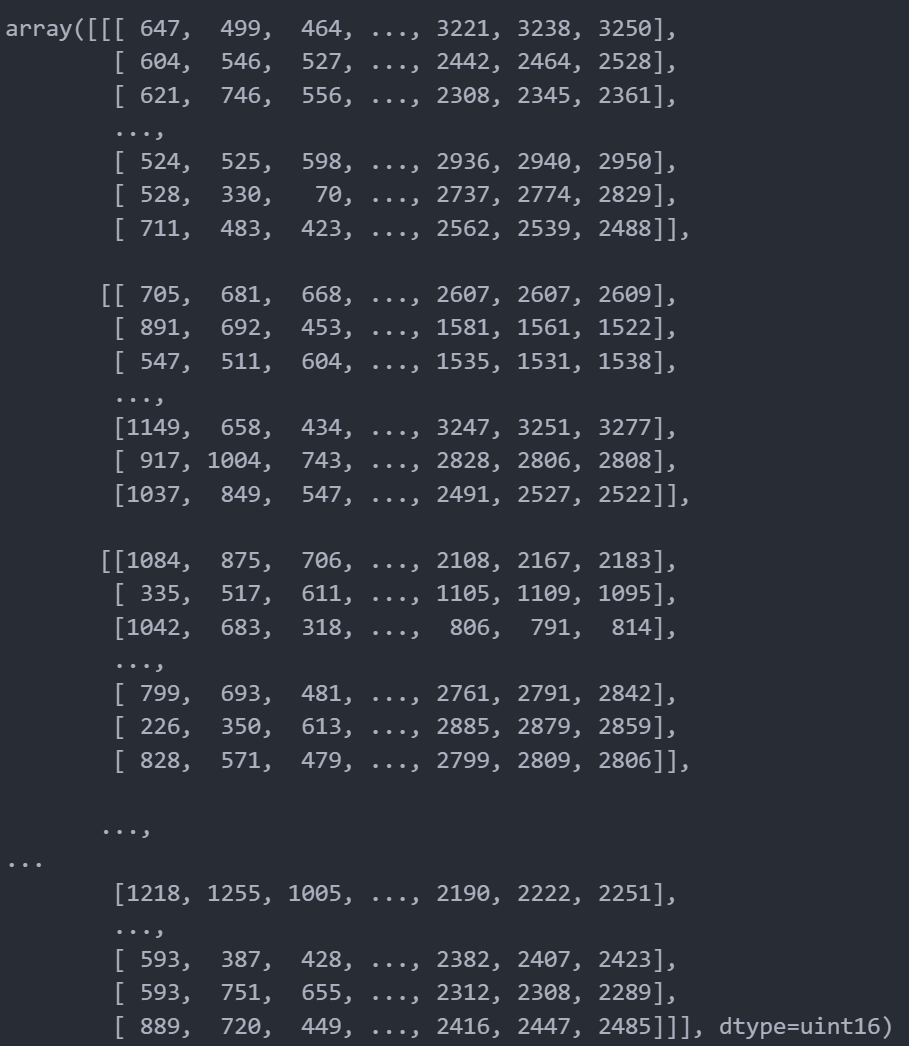
**
data.shape**为(610,340,103),610×340的像素,103个波段,而RGB图像相当于只有3个波段,并且局限于0-255这个范围,但是高光谱图像的范围就广很多了。接下来看看标签数据是什么样的
显然是一个二维数组,也就相当于是一张图像,没有深度
通过以上研究可以发现array中有几个中括号就是几维数组
处理数据
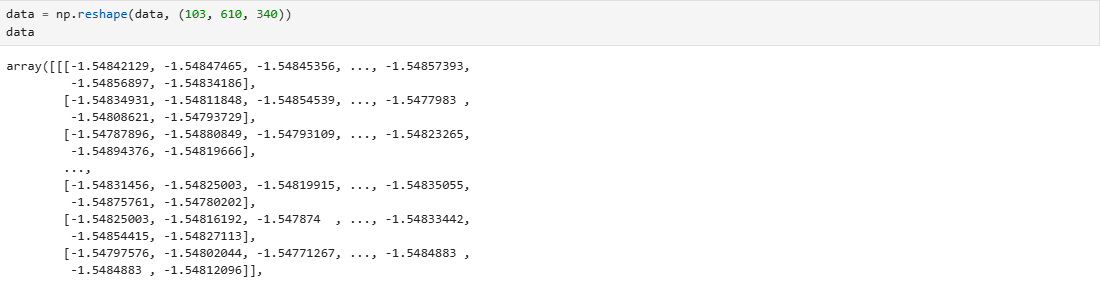
进行标准化
首先进行reshape变成一个列向量

from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(data)
这行代码是使用
sklearn库中的StandardScaler来对数据进行标准化处理,获得均值和标准差储存在scaler中
利用
scaler进行标准化

reshape回原来的形状,不过里面的数据已经被标准化了
取切片
首先制作全零数组
此数组是拓展之后的,都拓展了
margindef pad(X, margin): # 构造全0数组 newX = np.zeros((X.shape[0], X.shape[1]+margin*2, X.shape[2]+margin*2)) # 将全0数组中间部分赋值为X,这样就实现了填充,上下左右都扩展了margin newX[:, margin:X.shape[1]+margin, margin:X.shape[2]+margin] = X return newX data=pad(data,8)
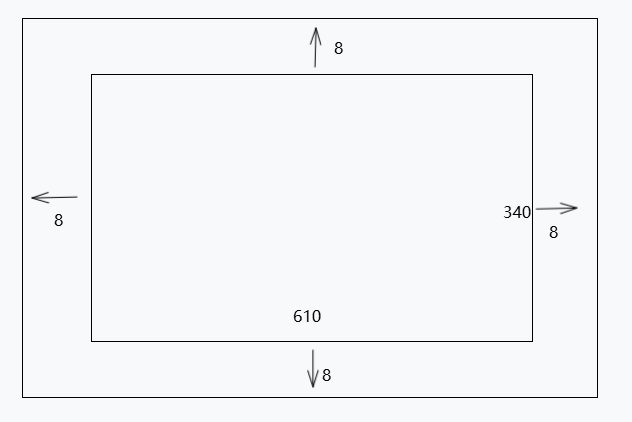
中间的部分将在后续填入原始数据
创建样本
# 生成切片数据并存储
def createdData(X, label):
# 从0,1,2,...,OUTPUT_CLASSES-1开始
for c in range(OUTPUT_CLASSES):
# 创建空数组
PATCH, LABEL, TEST_PATCH, TRAIN_PATCH, TEST_LABEL, TRAIN_LABEL = [], [], [], [], [], []
# 遍历label所有像素点
for h in range(X.shape[1]-PATCH_SIZE+1):
for w in range(X.shape[2]-PATCH_SIZE+1):
gt = label[h, w]
# gt->[1,9]有实际意义,c->[0,8]
if(gt == c+1):
# 根据左上角坐标和切片尺寸创建patch_size*patch_size切片对象
img = patch(X, PATCH_SIZE, h, w)
# 将切片对象添加到PATCH中
PATCH.append(img)
# 将标签添加到LABEL中
LABEL.append(gt-1)
# 打乱切片
shuffle(PATCH)
# 根据每个类别的切片数量,划分训练集和测试集
split_size = int(len(PATCH)*TEST_FRAC)
# PATCH里面存的图片,LABEL里面存的标签(一个数)
TEST_PATCH.extend(PATCH[:split_size])
TRAIN_PATCH.extend(PATCH[split_size:])
TEST_LABEL.extend(LABEL[:split_size])
TRAIN_LABEL.extend(LABEL[split_size:])
# 初始化文件夹
train_dict, test_dict = {}, {}
# 构建键值
train_dict["train_patches"] = TRAIN_PATCH
train_dict["train_labels"] = TRAIN_LABEL
file_name = "Training_class(%d).mat" % c
scipy.io.savemat(os.path.join(NEW_DATA_PATH, file_name), train_dict)
# 构建键值
test_dict["testing_patches"] = TEST_PATCH
test_dict["testing_labels"] = TEST_LABEL
file_name = "Testing_class(%d).mat" % c
scipy.io.savemat(os.path.join(NEW_DATA_PATH, file_name), test_dict)
让我们来看一看patch函数是如何生成样本的
def patch(X, patch_size, height_index, width_index):
# 创建切片对象
height_slice = slice(height_index, height_index + patch_size)
width_slice = slice(width_index, width_index + patch_size)
# 左上角为最开始检测到的那个点,然后把这个点扩充为patch_size*patch_size
patch = X[:, height_slice, width_slice] # patch包含所有波段
# 遍历pacth的每个波段,将每个波段的像素值减去该波段所有像素值的均值(中心化)
for i in range(X.shape[0]):
mean = np.mean(patch[i, :, :])
patch[i] = patch[i]-mean
return patch
在遍历图像每个像素点的那两个循环中,并没有使用拓展后的data,而是使用的没有拓展的label来确定坐标,这样做有利于获取真实的坐标
在获得真实坐标之后,通过
height_slice = slice(height_index, height_index + patch_size)
width_slice = slice(width_index, width_index + patch_size)会使得涵盖地物信息的像素点正好处于切片的中间
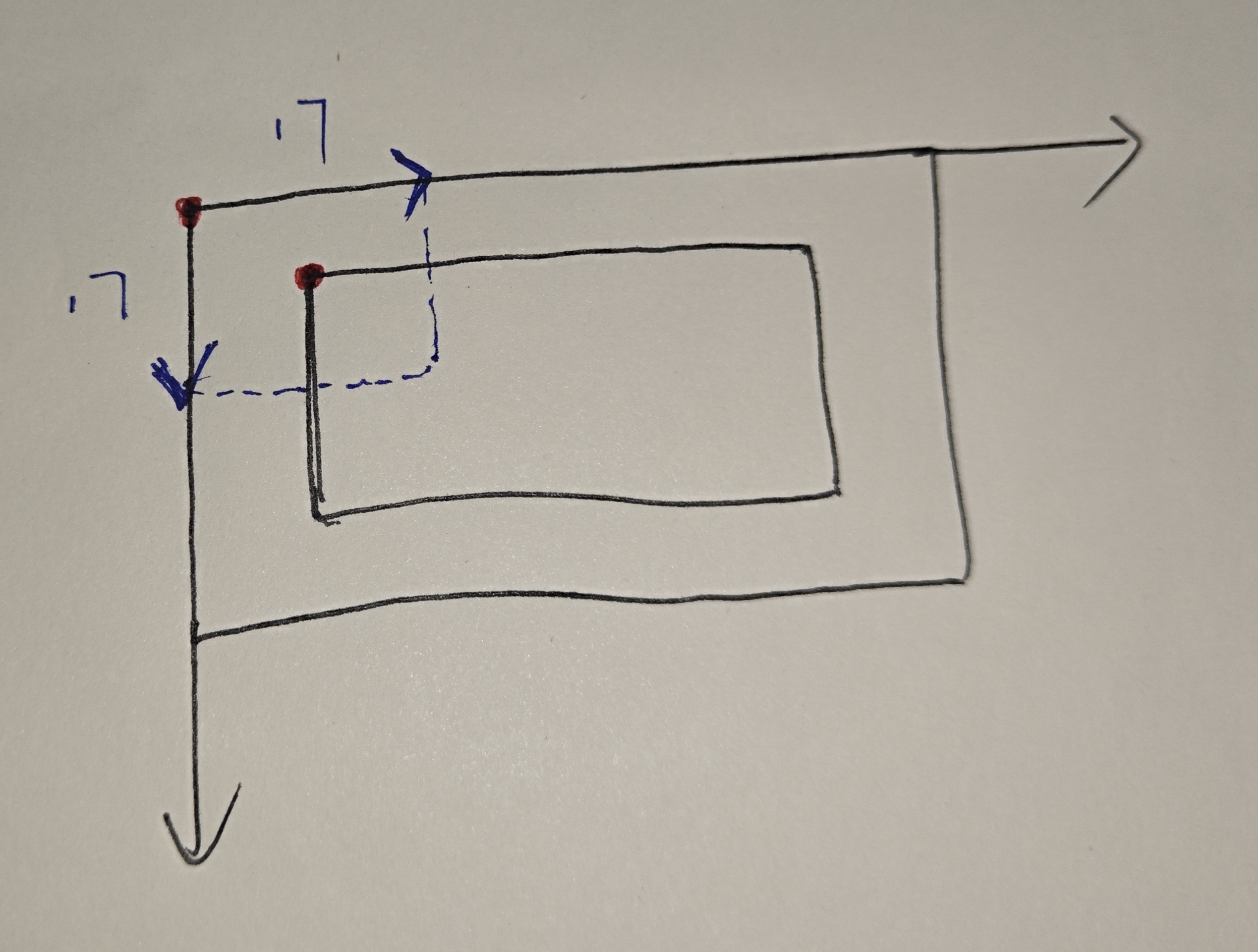
以第一轮循环为例,也就是
c=0,gt=1当这个类别所有切片都生成成功了之后会形成如下一张样式的“数据集”
c=0,gt=1之后会进行打乱,按照比例分配训练集和测试集,然后保存为
.mat文
预览样本
以c=0,gt=1为例
dict_keys(['__header__', '__version__', '__globals__', 'testing_patches', 'testing_labels'])
patch
'testing_patches': array([[[[ 3.88270784e-01, 3.53140402e-01, -1.30573418e-02, ...,
-2.39107608e-01, 2.13386371e-01, 6.67234287e-01],
[ 1.96013121e-01, -1.80449282e-01, 5.40254783e-02, ...,
-3.68331985e-01, -1.21286376e-01, 4.46349571e-01],
[ 1.41840019e-01, -4.60455915e-02, -2.02822307e-01, ...,
-1.50895525e-02, 4.36948830e-01, -3.38887677e-01],
...,
[-6.84765116e-02, -4.40636600e-02, 6.07082591e-01, ...,
5.39916225e-01, 6.42440379e-01, 4.43262279e-01],
[ 1.88737537e-02, 1.91223788e-01, -4.88867996e-02, ...,
7.02152004e-01, 1.49223329e-01, 9.92977382e-01],
[-5.31185927e-02, 4.74204931e-01, -1.14130403e-01, ...,
label
array([[0, 0, 0, ..., 0, 0, 0]])
label.shape
(1, 3315)
patch.shape
(3315, 103, 17, 17)
-01],
[-5.31185927e-02, 4.74204931e-01, -1.14130403e-01, ...,
label
array([[0, 0, 0, ..., 0, 0, 0]])
label.shape
(1, 3315)
patch.shape
(3315, 103, 17, 17)

















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









