







16.数据结构
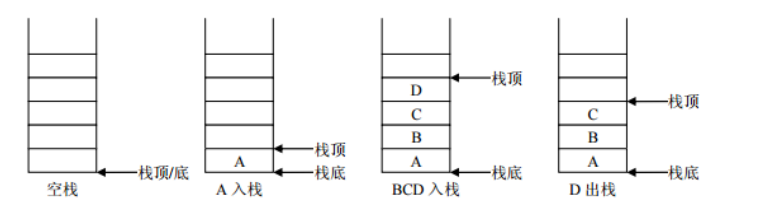
(1)栈
栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
特点:(1)先进后出;(2)栈的入口、出口的都是栈的顶端位置。
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。 弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
(2)队列
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
特点:(1)先进先出;(2)队列的入口、出口各占一侧。

(3)数组
特点:
(1)查找元素快:通过索引,可以快速访问指定位置的元素;
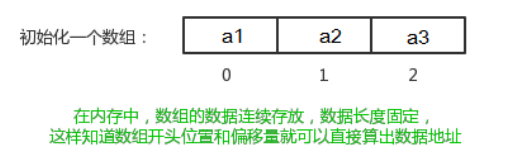
(2)增删元素慢
? 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根 据索引,复制到新数组对应索引的位置。如下图

? 指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图
对象数组
package Day0811;
public class demo1 {
public static void main(String[] args) {
Student s1 = new Student("zhangsan1",65);
Student s2 = new Student("zhangsan2",75);
Student s3 = new Student("zhangsan3",85);
Student[] stus = {s1,s2,s3};
for(int i=0;i<stus.length;i++){
Student s = stus[i];
System.out.println("学生名字"+s.getName()+",学生成绩:"+s.getScore());
}
}
}
package Day0811;
public class Student {
private String name;
private double score;
public Student(String name, double score) {
super();
this.name = name;
this.score = score;
}
public Student() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
}
(4)链表
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。
每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
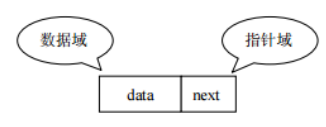
我们常说的链表结构有单向链表与双向链表。
单向链表
特点:
(1)多个结点之间,通过地址进行连接
(2)查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
(3)增删元素快:
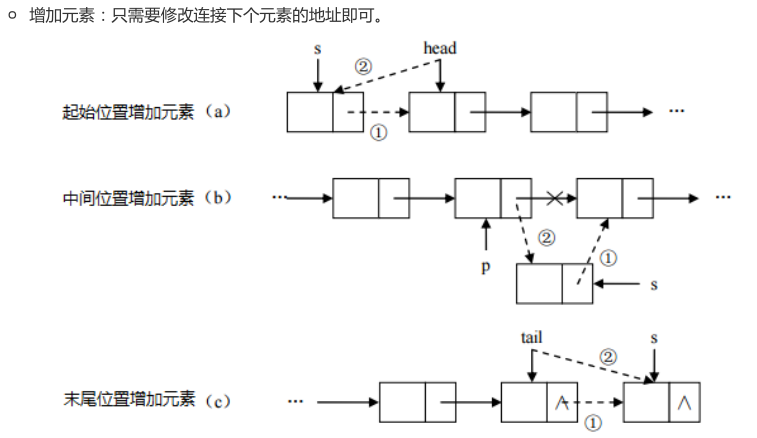
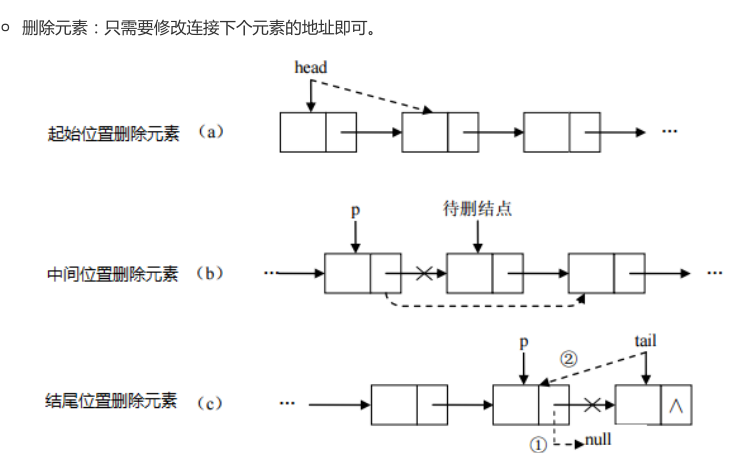
双向链表
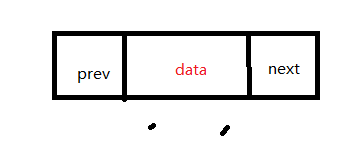
有两个指针域分别指向前一个结点和后一个结点,还有一部分用来保存结点数据,初始化结点时需要将两个指针都指向空
1.增加结点。
增加结点时,需要将最后一个结点的next指针指向新结点,然后将新结点的prev指向最后一个结点
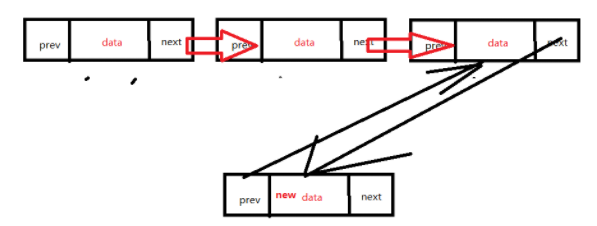
3.删除结点。
删除结点时需要将待删除结点的前一个结点的next指向待删除结点的后一个结点,然后,把后者的prev指针指向前者:

4.插入结点。
插入结点就是将新结点的前一个结点的next指针指向指向新结点,然后把新结点的next指针指向前一个结点原来后面的那个结点,然后把后面的结点的prev指针指向新结点,把新结点的Prev指针指向前一个结点。

(5)红黑树
二叉树
二叉树:binary tree ,是每个结点不超过2的有序树(tree) ,顶上的叫根结点,两边被称作“左子树”和“右子树”。
红黑树的约束:
- 节点可以是红色的或者黑色的
- 根节点是黑色的
- 叶子节点(特指空节点)是黑色的
- 每个红色节点的子节点都是黑色的
- 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点: 速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
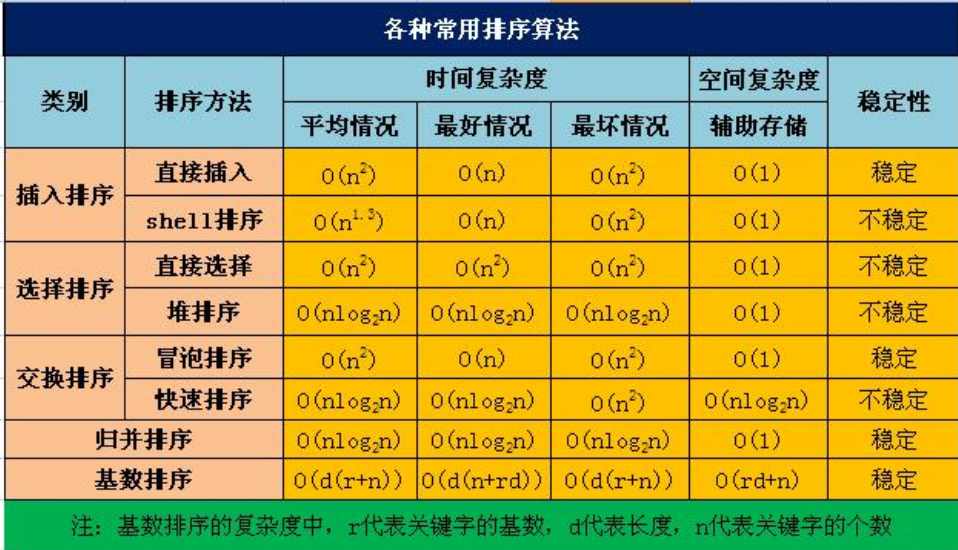
(6)八大排序方法
分类:
- 内部排序:
指将需要处理的所有数据都加载到内部存储器中进行排序。
- 外部排序法:
数据量过大,无法全部加载到内存中,需要借助外部存储进行排序。
性能比较
交换排序
冒泡排序
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向上冒。
俩俩比较,小的换在前,大的换在后面,依次向后循环这个过程
优化
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag判断元素是否进行过交换。从而减少不必要的比较。(这里说的优化,可以在冒泡排序写好后,在进行)
// // 将前面额冒泡排序算法,封装成一个方法
public static void bubbleSort(int[] arr) {
// 冒泡排序 的时间复杂度 O(n^2), 自己写出
int temp = 0; // 临时变量
boolean flag = false; // 标识变量,表示是否进行过交换
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
// 如果前面的数比后面的数大,则交换
if (arr[j] > arr[j + 1]) {
flag = true;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
//System.out.println("第" + (i + 1) + "趟排序后的数组");
//System.out.println(Arrays.toString(arr));
if (!flag) { // 在一趟排序中,一次交换都没有发生过
break;
} else {
flag = false; // 重置flag!!!, 进行下次判断
}
}
}
快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
过程
首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j–-),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。
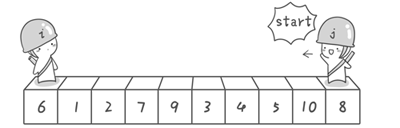
现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下。
6 1 2 5 9 3 4 7 10 8
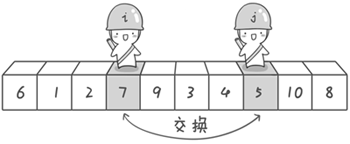
到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下。
6 1 2 5 4 3 9 7 10 8
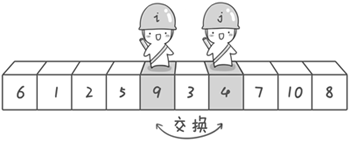
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
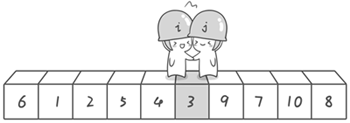
OK,解释完毕。现在基准数6已经归位,它正好处在序列的第6位。此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列。因为6左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。现在先来处理6左边的序列现吧。
左边的序列是“3 1 2 5 4”。请将这个序列以3为基准数进行调整,使得3左边的数都小于等于3,3右边的数都大于等于3。好了开始动笔吧。
如果你模拟的没有错,调整完毕之后的序列的顺序应该是。
2 1 3 5 4
OK,现在3已经归位。接下来需要处理3左边的序列“2 1”和右边的序列“5 4”。对序列“2 1”以2为基准数进行调整,处理完毕之后的序列为“1 2”,到此2已经归位。序列“1”只有一个数,也不需要进行任何处理。至此我们对序列“2 1”已全部处理完毕,得到序列是“1 2”。序列“5 4”的处理也仿照此方法,最后得到的序列如下。
1 2 3 4 5 6 9 7 10 8
对于序列“9 7 10 8”也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列,如下。
1 2 3 4 5 6 7 8 9 10
到此,排序完全结束。细心的同学可能已经发现,快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。描述下整个算法的处理过程。
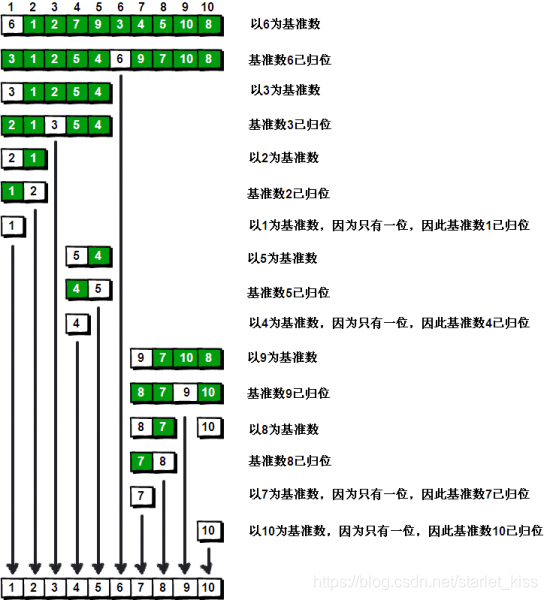
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。
代码
//方法1:便于理解
public static void quickSort2(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;//起始位
j=high;
//temp就是基准位
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准为与i和j相等位置的数字交换
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
public static void quickSort(int[] arr,int left, int right) {
int l = left; //左下标
int r = right; //右下标
//pivot 中轴值
int pivot = arr[(left + right) / 2];
int temp = 0; //临时变量,作为交换时使用
//while循环的目的是让比pivot 值小放到左边
//比pivot 值大放到右边
while( l < r) {
//在pivot的左边一直找,找到大于等于pivot值,才退出
while( arr[l] < pivot) {
l += 1;
}
//在pivot的右边一直找,找到小于等于pivot值,才退出
while(arr[r] > pivot) {
r -= 1;
}
//如果l >= r说明pivot 的左右两的值,已经按照左边全部是
//小于等于pivot值,右边全部是大于等于pivot值
if( l >= r) {
break;
}
//交换
temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
//如果交换完后,发现这个arr[l] == pivot值 相等 r--, 前移
if(arr[l] == pivot) {
r -= 1;
}
//如果交换完后,发现这个arr[r] == pivot值 相等 l++, 后移
if(arr[r] == pivot) {
l += 1;
}
}
// 如果 l == r, 必须l++, r--, 否则为出现栈溢出
if (l == r) {
l += 1;
r -= 1;
}
//向左递归
if(left < r) {
quickSort(arr, left, r);
}
//向右递归
if(right > l) {
quickSort(arr, l, right);
}
}
无 选择排序
简单选择排序
堆排序
无 插入排序
直接插入排序
希尔排序
无 归并排序
无 基数排序
(7)三大查找方法
顺序查找算法
顺序查找的基本思想:
从表的一端开始,顺序扫描表,依次将扫描到的结点关键字和给定值(假定为a)相比较,若当前结点关键字与a相等,则查找成功;若扫描结束后,仍未找到关键字等于a的结点,则查找失败。 说白了就是,从头到尾,一个一个地比,找着相同的就成功,找不到就失败。很明显的缺点就是查找效率低。 适用于线性表的顺序存储结构和链式存储结构。
public static int sequentialSearch(int[] a, int key) {
for ( int i = 0; i < a.length; i++) {
if (a[i] == key)
return i;
}
return - 1;
}
顺序表查找优化
因为每次循环时都需要对i是否越界,即是否小于等于n作判断。事实上,还可以有更好一点的办法,设置一个哨兵,可以解决不需要每次让i与n作比较。看下面的改进后的顺序查找算法代码。
public static int sequentialSearch2(int[] a, int key) {
int index = a.length - 1;
a[ 0] = key; // 将下标为0的数组元素设置为哨兵
while (a[index] != key) {
index--;
}
return index;
}
折半查找
? 折半查找(Binary Search)技术,又称为二分查找。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序) ,线性表必须采用顺序存储。
? 折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上 述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
public static int binarySearch(int[] a, int key) {
int low, mid, high;
low = 0; // 最小下标
high = a.length - 1; // 最大小标
while (low < high) {
mid = (high + low) / 2; // 折半下标
if (key > a[mid]) {
low = mid + 1; // 关键字比 折半值 大,则最小下标 调成 折半下标的下一位
} else if (key < a[mid]) {
high = mid - 1; // 关键字比 折半值 小,则最大下标 调成 折半下标的前一位
} else {
return mid; // 当 key == a[mid] 返回 折半下标
}
}
return -1;
}
最终我们折半算法的时间复杂度为O(logn),它显然远远好于顺序查找的O(n)时间复杂度了。
二分查找特别适用于那种一经建立就很少改动而又经常需要查找的线性表。
分块查找
又称索引顺序查找,这是顺序查找的一种改进方法,用于在分块有序表中进行查找 。
主表:存储数据的表,长度n;
索引表:将主表分块,每块长s,找出每块中的关键字最大值,并且保存该块中所有数据在主表中的索引
(1)分块:将n个数据元素“按块有序”划分为m块。
每一块中的结点不必有序,但块与块之间必须“按块有序”;即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素。每个块中元素不一定是有序的。
(2)根据查找值,和索引表中关键字(每块中的最大关键字)比较,通过对分查找/顺序查找,找到该值所在的块范围;
(3)在相应块中,找到该值在主表中的位置。
平均查找长度ASL<=O(log2(n/s))+s/2 (先对分查找,或顺序查找)

















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











