







MYSQL主从复制
数据库优化

数据量:28080000000
三百多万数据查询慢怎么办

千万/ 亿级的数据如何做优化

用到读写分离一定会用到主从复制
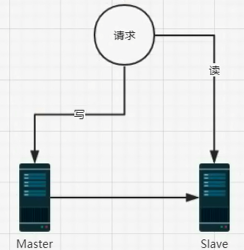
主从复制的目的
目的:分散压力
原因:如果对数据库的读和写都在同一个数据库服务器中操作,业务系统性能会降低。
业界应用总结:

主从复制图解
生活案例


人多时一个咖啡机处理不过来,所以需要增加咖啡机,所以数据量多时,增加服务器,同时要做主从复制,读写分离,为什么呢,最根本目的,分散压力。
如何用架构进行优化
MySQL+Redis应对高并发

实现MYSQL主从复制
主从复制步骤
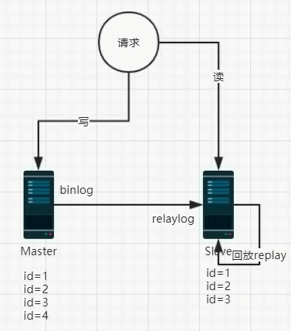
- binlog(二进制日志)和relaylog(中继日志)
- 每个服务器都有id。也就是MYSQL集群每个机器有一个唯一的标识
- 授权(用户、密码、ip地址)
第一,主服务器开通账户,设置权限(同步复制)
第二,从服务器设置访问信息


以上图片是主从机建立连接的过程
Docker仓库/镜像/容器
- master 数据修改先写到binarylog日志中,slave中的I/O
thread线程会读取binarylog日志,再回来,然后写到relaylog中。 - 先关掉同步线程I/O thread:stop slave,因为主机会不停的写数据,先做write操作建立连接再开启线程start
slave。 - 当relaylog拿到数据,SQL thread这个线程回去读,然后用replay方式,把SQL语句在slave丛机上重放一次。

以上为主从复制的原理
经验分享


多master 多slave
高并发分布式:单点故障要解决,单master
一线互联网架构

F5:硬负载
jd.com:负载均衡,动静分离,静态渲染
以上这个框架小编还不太明白,等后续学习了再更新,也欢迎各位找小编交流探讨。














 3251
3251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









