






2.12 向量化的更多例子(More Examples of Vectorization)
从上节视频中,你知道了怎样通过 numpy 内置函数和避开显式的循环(loop)的方式进行向量化,从而有效提高代码速度。
经验提醒我,当我们在写神经网络程序时,或者在写逻辑(logistic)回归,或者其他神经网络模型时,应该避免写循环(loop)语句。虽然有时写循环(loop)是不可避免的,但是我们可以使用比如 numpy 的内置函数或者其他办法去计算。当你这样使用后,程序效率总是快于循环(loop)。
让我们看另外一个例子。如果你想计算向量𝑢 = 𝐴𝑣,这时矩阵乘法定义为,矩阵乘法的定义就是:
u
i
{{u}_{i}}
ui=
∑
j
A
i
j
v
i
\sum\nolimits_{j}{{{A}_{ij}}}{{v}_{i}}
∑jAijvi ,这取决于你怎么定义
u
i
{{u}_{i}}
ui 值。同样使用非向量化实现,𝑢 =𝑛𝑝. 𝑧𝑒𝑟𝑜𝑠(𝑛, 1), 并且通过两层循环𝑓𝑜𝑟(𝑖): 𝑓𝑜𝑟(𝑗):,得到𝑢[𝑖] = 𝑢[𝑖] + 𝐴[𝑖][𝑗] ∗ 𝑣[𝑗] 。现在就有了𝑖 和 𝑗 的两层循环,这就是非向量化。向量化方式就可以用𝑢 = 𝑛𝑝. 𝑑𝑜𝑡(𝐴, 𝑣),右边这种向量化实现方式,消除了两层循环使得代码运行速度更快。

下面通过另一个例子继续了解向量化。如果你已经有一个向量𝑣,并且想要对向量𝑣的每个元素做指数操作,得到向量𝑢等于𝑒的
v
1
{{v}_{1}}
v1,𝑒的
v
2
{{v}_{2}}
v2,一直到𝑒的
v
n
{{v}_{n}}
vn次方。这里是非向量化的实现方式,首先你初始化了向量𝑢 = 𝑛𝑝. 𝑧𝑒𝑟𝑜𝑠(𝑛, 1),并且通过循环依次计算每个元素。但事实证明可以通过 python 的 numpy 内置函数,帮助你计算这样的单个函数。所以我会引入import numpy as np,执行 𝑢 = 𝑛𝑝. 𝑒𝑥𝑝(𝑣) 命令。注意到,在之前有循环的代码中,这里仅用了一行代码,向量𝑣作为输入,𝑢作为输出。你已经知道为什么需要循环,并且通过右边代码实现,效率会明显的快于循环方式。
事实上,numpy 库有很多向量函数。比如 u=np.log 是计算对数函数(𝑙𝑜𝑔)、np.abs()是计算数据的绝对值、 np.maximum() 计算元素 𝑦 中的最大值,你也可以np.maximum(v,0) 、 𝑣 ∗∗ 2 代表获得元素 𝑦 每个值得平方、
1
v
\frac{1}{v}
v1获取元素 𝑦 的倒数等等。所以当你想写循环时候,检查 numpy 是否存在类似的内置函数,从而避免使用循环(loop)方式。

那么,将刚才所学到的内容,运用在逻辑回归的梯度下降上,看看我们是否能简化两个计算过程中的某一步。这是我们逻辑回归的求导代码,有两层循环。在这例子我们有𝑛个特征值。如果你有超过两个特征时,需要循环
d
w
1
d{{w}_{1}}
dw1 、
d
w
2
d{{w}_{2}}
dw2 、
d
w
3
d{{w}_{3}}
dw3等等。所以 𝑗 的实际值是1、2 和
n
x
{{n}_{x}}
nx,就是你想要更新的值。所以我们想要消除第二循环,在这一行,这样我们就不用初始化
d
w
1
d{{w}_{1}}
dw1 ,
d
w
2
d{{w}_{2}}
dw2 都等于 0。去掉这些,而是定义 𝑑𝑤 为一个向量,设置 𝑢 =𝑛𝑝. 𝑧𝑒𝑟𝑜𝑠(𝑛(𝑥),1)。定义了一个𝑥行的一维向量,从而替代循环。我们仅仅使用了一个向量操作 𝑑𝑤 = 𝑑𝑤 +
x
(
i
)
d
z
(
i
)
{{x}^{(i)}}dz(i)
x(i)dz(i) 。最后,我们得到 𝑑𝑤 = 𝑑𝑤/𝑚 。现在我们通过将两层循环转成一层循环,我们仍然还有这个循环训练样本。
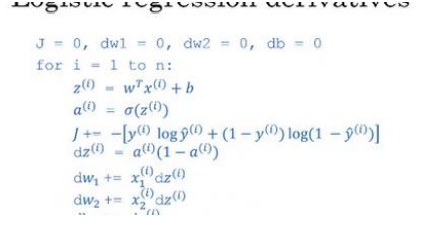

希望这个视频给了你一点向量化感觉,减少一层循环使你代码更快,但事实证明我们能做得更好。所以在下个视频,我们将进一步的讲解逻辑回归,你将会看到更好的监督学习结果。在训练中不需要使用任何 for 循环,你也可以写出代码去运行整个训练集。到此为止一切都好,让我们看下一个视频。

















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包










