






继DeepMind的新设计MoD大幅提升了 Transformer 效率后,谷歌又双叒开始爆改了!
与之前荣登Nature子刊的life2vec不同,谷歌的新成果Infini-attention机制(无限注意力)将压缩内存引入到传统的注意机制中,并在单个Transformer块中构建了掩码局部注意力和长期线性注意力机制。
这让Transformer架构大模型在有限的计算资源里处理无限长的输入,在内存大小上实现114倍压缩比。(相当于一个存放100本书的图书馆,通过新技术能存储11400本书) 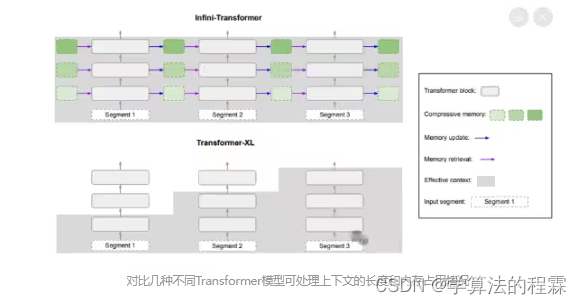
目前,关于 Transformer 的改进非常火爆,是当前学术研究的热点之一,有丰富的研究素材和灵感可供我们参考。除Infini-attention外,还有很多Transformer改进方案效果拔群。
本文整理了22篇Transformer最新的改进方案,都是大佬团队出品,开源的都附上了代码方便复现,希望能给各位的论文加加速。 (看下图自取即可)
【1】Infini-attention
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
方法:论文介绍了一种有效的方法,将基于Transformer的大型语言模型(LLMs)扩展到具有有限内存和计算的无限长输入。该方法的一个关键组成部分是一种名为Infini-attention的新的注意机制。Infini-attention将压缩内存引入到传统的注意机制中,并在单个Transformer块中构建了掩码局部注意力和长期线性注意力机制。 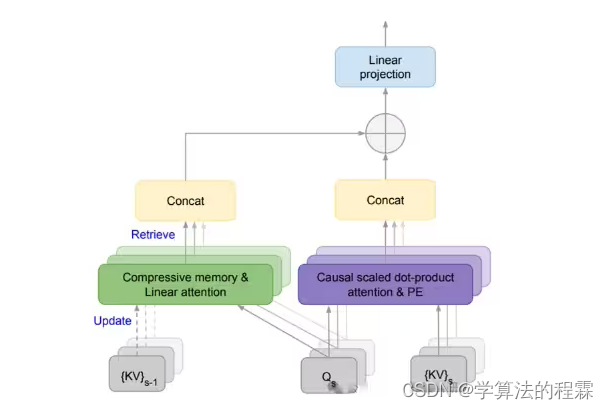
创新点:
Infini-attention:引入了一种实际且强大的注意机制,具有长期压缩记忆和局部因果注意力,有效地建模长距离和短距离的上下文依赖关系。
压缩记忆:在Infini-attention中,通过重用点积注意力计算中的查询、键和值状态(Q、K和V),而不是计算压缩记忆的新记忆条目。这种状态共享和重用使得点积注意力和压缩记忆之间的有效插入式长上下文适应变得可能,并加快了训练和推断速度。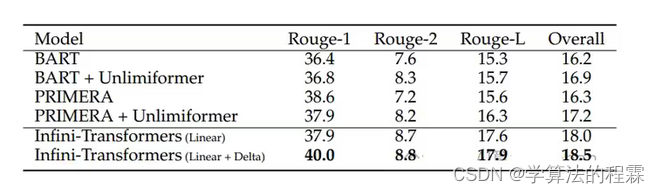
【2】life2vec
Using Sequences of Life-events to Predict Human Lives
DTU
方法:论文使用了一个基于Transformer架构的life2vec模型,通过将个人生活事件序列化并嵌入到向量空间中,来分析和预测人类生活的各种结果,如早逝风险和个性特征。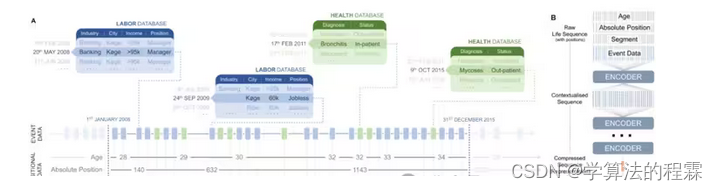
创新点:
论文提出了一种将生命事件编码到单一向量空间的方法,这种方法不仅能够捕捉事件之间的相似性,还能够揭示事件之间的复杂相互作用。
通过使用模型解释性工具,如梯度显著性图和概念激活向量(TCAV),研究者们能够解释模型是如何做出预测的,这增加了模型的透明度和可信度。
life2vec模型能够执行多种预测任务,从早期死亡率到个性细微差别,显示出模型的多功能性和适应性。 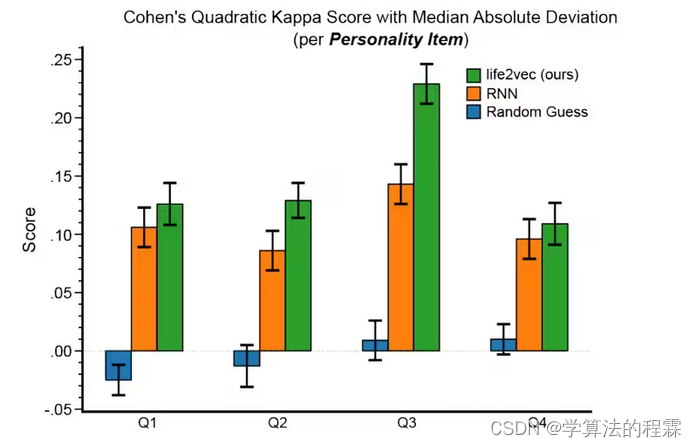
【3】Searchformer
Beyond A∗: Better Planning with Transformers via Search Dynamics Bootstrapping
FAIR at Meta
方法:本文介绍了一种训练Transformer模型解决复杂规划任务的方法,并提出了Searchformer模型,该模型在多步规划任务(如迷宫导航和Sokoban拼图)中比传统的符号规划算法(如A* 搜索)少使用搜索步骤来计算最优解。 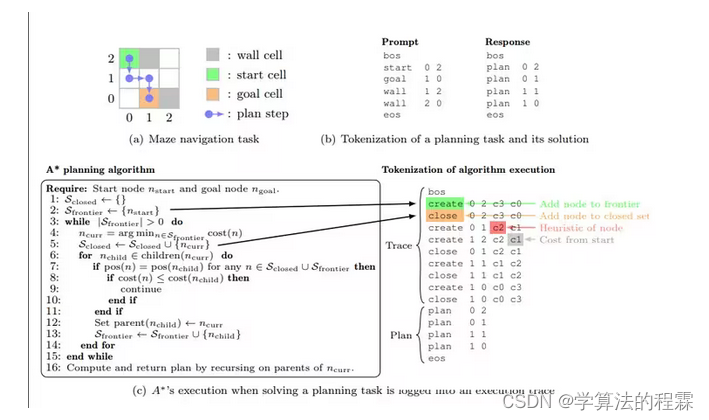
创新点:
基于Transformer架构的Searchformer模型,通过预测A* 搜索的搜索动态来解决复杂的规划任务,实现了比A* 搜索更少的搜索步骤下计算出最优解的能力。
Searchformer模型通过搜索动态引导训练,能够在较小的训练数据集和较小的模型规模下达到比直接预测最优解的模型更好的性能。
在迷宫导航和Sokoban拼图等复杂规划任务上,Searchformer模型表现出较高的准确性和搜索效率,为使用Transformer解决传统符号规划算法无法解决的任务提供了可能性。 
【4】Transformer
ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING
Tsinghua University
方法:iTransformer是一种针对时间序列预测优化的Transformer模型,它通过独立嵌入变量令牌并应用自注意力机制来捕捉多变量相关性,使用前馈网络学习时间序列表示,从而提高了模型在多变量预测任务中的性能和泛化能力。 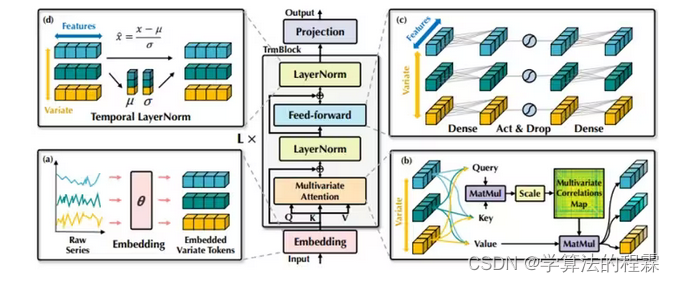
创新点:
(1)Transformer没有修改Transformer的基本组件,而是通过改变架构来提高性能,这表明了现有Transformer组件在多变量时间序列预测中的潜力。
(2)通过在变量维度上应用自注意力机制,iTransformer能够更好地捕捉多变量之间的相关性,这对于时间序列预测尤其重要。
(3)Transformer在未见过的变量上展现出良好的泛化能力,这使得模型可以在训练时使用较少的变量,而在预测时仍然能够准确预测所有变量。
( 4 )提出了一种新的高效训练策略,通过在每个批次中随机选择部分变量进行训练,从而显著减少了内存占用并提高了训练速度。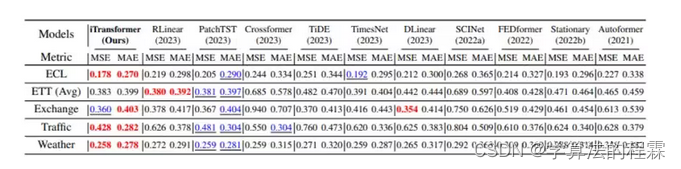
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









